Download presentation
Presentation is loading. Please wait.

1
Vegetation Science Lecture 4 Non-Linear Inversion Lewis, Disney & Saich UCL

2
Introduction Previously considered forward models –Model reflectance/backscatter as fn of biophysical parameters Now consider model inversion –Infer biophysical parameters from measurements of reflectance/backscatter

3
Linear Model Inversion Dealt with last lecture Define RMSE Minimise wrt model parameters Solve for minimum –MSE is quadratic function –Single (unconstrained) minimum
 minimum")
4
P0 P1 RMSE

5
P0 P1 RMSE

6
Issues Parameter transformation and bounding Weighting of the error function Using additional information Scaling

7
Parameter transformation and bounding Issue of variable sensitivity –E.g. saturation of LAI effects –Reduce by transformation Approximately linearise parameters Need to consider average effects

9
Weighting of the error function Different wavelengths/angles have different sensitivity to parameters Previously, weighted all equally –Equivalent to assuming noise equal for all observations

10
Weighting of the error function Can target sensitivity –E.g. to chlorophyll concentration –Use derivative weighting (Privette 1994)
.")
11
Using additional information Typically, for Veg Sci, use canopy growth model –See Moulin et al. (1998) Provides expectation of (e.g.) LAI –Need: planting date Daily mean temperature Varietal information (?) Use in various ways –Reduce parameter search space –Expectations of coupling between parameters
 Provides expectation of (e.g.) LAI –Need: planting date Daily mean temperature Varietal information ( ) Use in various ways –Reduce parameter search space –Expectations of coupling between parameters.")
12
Scaling Many parameters scale approximately linearly –E.g. cover, albedo, fAPAR Many do not –E.g. LAI Need to (at least) understand impact of scaling
 understand impact of scaling.")
13
Crop Mosaic LAI 1LAI 4LAI 0

14
Crop Mosaic 20% of LAI 0, 40% LAI 4, 40% LAI 1. real total value of LAI: –0.2x0+0.4x4+0.4x1=2.0. LAI1LAI1 LAI4LAI4 LAI0LAI0 visible: NIR

15
canopy reflectance over the pixel is 0.15 and 0.60 for the NIR. If assume the model above, this equates to an LAI of 1.4. real answer LAI 2.0

16
Options for Numerical Inversion Iterative numerical techniques –Quasi-Newton –Powell Knowledge-based systems (KBS) Artificial Neural Networks (ANNs) Genetic Algorithms (GAs) Look-up Tables (LUTs)
 Artificial Neural Networks (ANNs) Genetic Algorithms (GAs) Look-up Tables (LUTs)")
17
Local and Global Minima Need starting point

18
How to go downhill? Bracketing of a minimum

19
How far to go downhill? Golden Mean Fraction =w=0.38197 z=(x-b)/(c-a) w=(b-a)/(c-a) w 1-w Choose: z+w=1-w For symmetry Choose: w=z/(1-w) To keep proportions the same z=w-w 2 =1-2w 0= w 2 -3w+1 Slow, but sure
/(c-a) w=(b-a)/(c-a) w 1-w Choose: z+w=1-w For symmetry Choose: w=z/(1-w) To keep proportions the same z=w-w 2 =1-2w 0= w 2 -3w+1 Slow, but sure.")
20
Parabolic Interpolation Inverse parabolic interpolation More rapid

21
Brents method Require fast but robust inversion Golden mean search –Slow but sure Use in unfavourable areas Use Parabolic method –when get close to minimum

22
Multi-dimensional minimisation Use 1D methods multiple times –In which directions? Some methods for N-D problems –Simplex (amoeba)
.")
23
Downhill Simplex Simplex: –Simplest N-D N+1 vertices Simplex operations: –a reflection away from the high point –a reflection and expansion away from the high point –a contraction along one dimension from the high point –a contraction along all dimensions towards the low point. Find way to minimum

24
Simplex

25
Direction Set (Powell's) Method Multiple 1-D minimsations –Inefficient along axes
 Method Multiple 1-D minimsations –Inefficient along axes")
26
Powell

27
Direction Set (Powell's) Method Use conjugate directions –Update primary & secondary directions Issues –Axis covariance
 Method Use conjugate directions –Update primary & secondary directions Issues –Axis covariance")
28
Powell

29
Simulated Annealing Previous methods: –Define start point –Minimise in some direction(s) –Test & proceed Issue: –Can get trapped in local minima Solution (?) –Need to restart from different point
 –Test & proceed Issue: –Can get trapped in local minima Solution ( ) –Need to restart from different point")
30
Simulated Annealing

31
Annealing –Thermodynamic phenomenon –slow cooling of metals or crystalisation of liquids –Atoms line up & form pure cystal / Stronger (metals) –Slow cooling allows time for atoms to redistribute as they lose energy (cool) –Low energy state Quenching –fast cooling –Polycrystaline state
 –Slow cooling allows time for atoms to redistribute as they lose energy (cool) –Low energy state Quenching –fast cooling –Polycrystaline state")
32
Simulated Annealing Simulate slow cooling Based on Boltzmann probability distribution: k – constant relating energy to temperature System in thermal equilibrium at temperature T has distribution of energy states E All (E) states possible, but some more likely than others Even at low T, small probability that system may be in higher energy state
 states possible, but some more likely than others Even at low T, small probability that system may be in higher energy state")
33
Simulated Annealing Use analogy of energy to RMSE As decrease temperature, move to generally lower energy state Boltzmann gives distribution of E states –So some probability of higher energy state i.e. going uphill –Probability of uphill decreases as T decreases

34
Implementation System changes from E 1 to E 2 with probability exp[-(E 2 -E 1 )/kT] –If(E 2 1 (threshold at 1) System will take this option –If(E 2 > E 1 ), P<1 Generate random number System may take this option Probability of doing so decreases with T
![Implementation System changes from E 1 to E 2 with probability exp[-(E 2 -E 1 )/kT] –If(E 2 1 (threshold at 1) System will take this option –If(E 2 > E 1 ), P<1 Generate random number System may take this option Probability of doing so decreases with T](http://images.slideplayer.com/3/780043/slides/slide_34.jpg "Implementation System changes from E 1 to E 2 with probability exp[-(E 2 -E 1 )/kT] –If(E 2 1 (threshold at 1) System will take this option –If(E 2 > E 1 ), P<1 Generate random number System may take this option Probability of doing so decreases with T")
35
Simulated Annealing T P= exp[-(E 2 -E 1 )/kT] – rand() - OK P= exp[-(E 2 -E 1 )/kT] – rand() - X
![Simulated Annealing T P= exp[-(E 2 -E 1 )/kT] – rand() - OK P= exp[-(E 2 -E 1 )/kT] – rand() - X](http://images.slideplayer.com/3/780043/slides/slide_35.jpg "Simulated Annealing T P= exp[-(E 2 -E 1 )/kT] – rand() - OK P= exp[-(E 2 -E 1 )/kT] – rand() - X")
36
Simulated Annealing Rate of cooling very important Coupled with effects of k –exp[-(E 2 -E 1 )/kT] –So 2xk equivalent to state of T/2 Used in a range of optimisation problems Not much used in Remote Sensing
![Simulated Annealing Rate of cooling very important Coupled with effects of k –exp[-(E 2 -E 1 )/kT] –So 2xk equivalent to state of T/2 Used in a range of optimisation problems Not much used in Remote Sensing](http://images.slideplayer.com/3/780043/slides/slide_36.jpg "Simulated Annealing Rate of cooling very important Coupled with effects of k –exp[-(E 2 -E 1 )/kT] –So 2xk equivalent to state of T/2 Used in a range of optimisation problems Not much used in Remote Sensing")
37
(Artificial) Neural networks (ANN) Another Natural analogy –Biological NNs good at solving complex problems –Do so by training system with experience
 Neural networks (ANN) Another Natural analogy –Biological NNs good at solving complex problems –Do so by training system with experience")
38
(Artificial) Neural networks (ANN) ANN architecture
 Neural networks (ANN) ANN architecture")
39
(Artificial) Neural networks (ANN) Neurons –have 1 output but many inputs –Output is weighted sum of inputs –Threshold can be set Gives non-linear response
 Neural networks (ANN) Neurons –have 1 output but many inputs –Output is weighted sum of inputs –Threshold can be set Gives non-linear response")
40
(Artificial) Neural networks (ANN) Training –Initialise weights for all neurons –Present input layer with e.g. spectral reflectance –Calculate outputs –Compare outputs with e.g. biophysical parameters –Update weights to attempt a match –Repeat until all examples presented

41
(Artificial) Neural networks (ANN) Use in this way for canopy model inversion Train other way around for forward model Also used for classification and spectral unmixing –Again – train with examples ANN has ability to generalise from input examples Definition of architecture and training phases critical –Can over-train – too specific –Similar to fitting polynomial with too high an order Many types of ANN – feedback/forward
 Neural networks (ANN) Use in this way for canopy model inversion Train other way around for forward model Also used for classification and spectral unmixing –Again – train with examples ANN has ability to generalise from input examples Definition of architecture and training phases critical –Can over-train – too specific –Similar to fitting polynomial with too high an order Many types of ANN – feedback/forward")
42
(Artificial) Neural networks (ANN) In essence, trained ANN is just a (essentially) (highly) non-linear response function Training (definition of e.g. inverse model) is performed as separate stage to application of inversion –Can use complex models for training Many examples in remote sensing Issue: –How to train for arbitrary set of viewing/illumination angles? – not solved problem
 is performed as separate stage to application of inversion –Can use complex models for training Many examples in remote sensing Issue: –How to train for arbitrary set of viewing/illumination angles. – not solved problem.")
43
Genetic (or evolutionary) algorithms (GAs) Another Natural analogy Phrase optimisation as fitness for survival Description of state encoded through string (equivalent to genetic pattern) Apply operations to genes –Cross-over, mutation, inversion
 algorithms (GAs) Another Natural analogy Phrase optimisation as fitness for survival Description of state encoded through string (equivalent to genetic pattern) Apply operations to genes –Cross-over, mutation, inversion")
44
Genetic (or evolutionary) algorithms (GAs) E.g. of BRDF model inversion: Encode N-D vector representing current state of biophysical parameters as string Apply operations: –E.g. mutation/mating with another string –See if mutant is fitter to survive (lower RMSE) –If not, can discard (die)
 –If not, can discard (die).")
45
Genetic (or evolutionary) algorithms (GAs) General operation: –Populate set of chromosomes (strings) –Repeat: Determine fitness of each Choose best set Evolve chosen set –Using crossover, mutation or inversion –Until a chromosome found of suitable fitness
 algorithms (GAs) General operation: –Populate set of chromosomes (strings) –Repeat: Determine fitness of each Choose best set Evolve chosen set –Using crossover, mutation or inversion –Until a chromosome found of suitable fitness")
46
Genetic (or evolutionary) algorithms (GAs) Differ from other optimisation methods –Work on coding of parameters, not parameters themselves –Search from population set, not single members (points) –Use payoff information (some objective function for selection) not derivatives or other auxilliary information –Use probabilistic transition rules (as with simulated annealing) not deterministic rules
 algorithms (GAs) Differ from other optimisation methods –Work on coding of parameters, not parameters themselves –Search from population set, not single members (points) –Use payoff information (some objective function for selection) not derivatives or other auxilliary information –Use probabilistic transition rules (as with simulated annealing) not deterministic rules")
47
Genetic (or evolutionary) algorithms (GAs) Example operation: 1.Define genetic representation of state 2.Create initial population, set t=0 3.Compute average fitness of the set -Assign each individual normalised fitness value -Assign probability based on this 4.Using this distribution, select N parents 5.Pair parents at random 6.Apply genetic operations to parent sets -generate offspring -Becomes population at t+1 7. Repeat until termination criterion satisfied

48
Genetic (or evolutionary) algorithms (GAs) –Flexible and powerful method –Can solve problems with many small, ill- defined minima –May take huge number of iterations to solve –Not applied to remote sensing model inversions
 algorithms (GAs) –Flexible and powerful method –Can solve problems with many small, ill- defined minima –May take huge number of iterations to solve –Not applied to remote sensing model inversions")
49
Knowledge-based systems (KBS) Seek to solve problem by incorporation of information external to the problem Only RS inversion e.g. Kimes et al (1990;1991) –VEG model Integrates spectral libraries, information from literature, information from human experts etc Major problems: –Encoding and using the information –1980s/90s fad?
 –VEG model Integrates spectral libraries, information from literature, information from human experts etc Major problems: –Encoding and using the information –1980s/90s fad .")
50
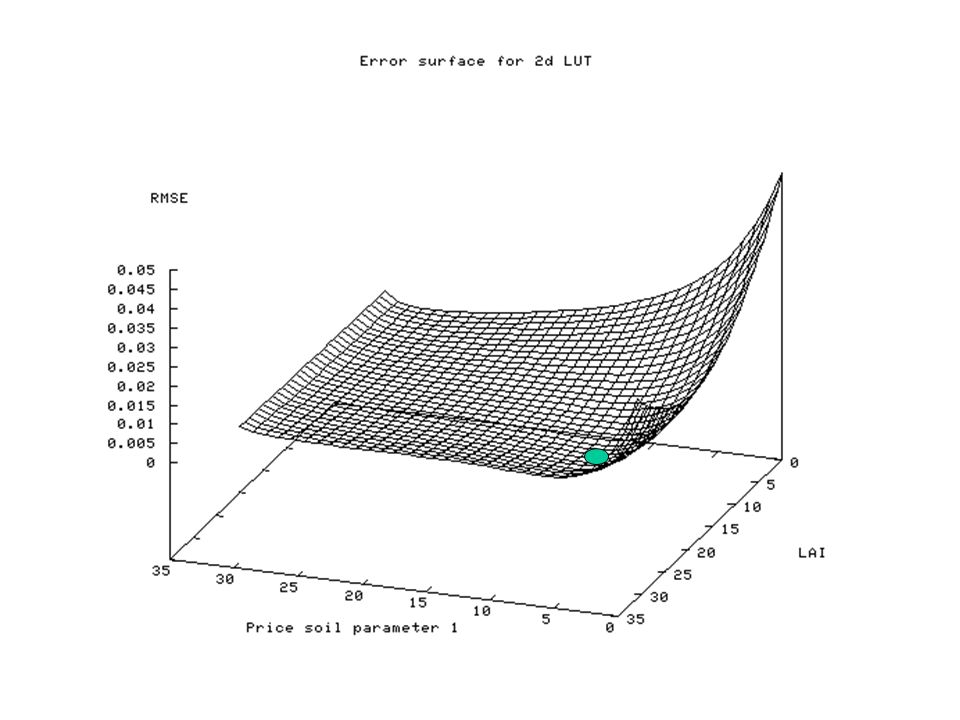
LUT Inversion Sample parameter space Calculate RMSE for each sample point Define best fit as minimum RMSE parameters –Or function of set of points fitting to a certain tolerance Essentially a sampled exhaustive search

51
LUT Inversion Issues: –May require large sample set –Not so if function is well-behaved for many optical EO inversions In some cases, may assume function is locally linear over large (linearised) parameter range Use linear interpolation –Being developed UCL/Swansea for CHRIS-PROBA –May limit search space based on some expectation E.g. some loose VI relationship or canopy growth model or land cover map Approach used for operational MODIS LAI/fAPAR algorithm (Myneni et al)
.")
52
LUT Inversion Issues: –As operating on stored LUT, can pre-calculate model outputs Dont need to calculate model on the fly as in e.g. simplex methods Can use complex models to populate LUT –E.g. of Lewis, Saich & Disney using 3D scattering models (optical and microwave) of forest and crop –Error in inversion may be slightly higher if (non- interpolated) sparse LUT But may still lie within desirable limits –Method is simple to code and easy to understand essentially a sort operation on a table
 of forest and crop –Error in inversion may be slightly higher if (non- interpolated) sparse LUT But may still lie within desirable limits –Method is simple to code and easy to understand essentially a sort operation on a table.")
53
Summary Range of options for non-linear inversion traditional NL methods: –Powell, AMOEBA Complex to code –though library functions available Can easily converge to local minima –Need to start at several points Calculate canopy reflectance on the fly –Need fast models, involving simplifications Not felt to be suitable for operationalisation

54
Summary Simulated Annealing –Can deal with local minima –Slow –Need to define annealing schedule ANNs –Train ANN from model (or measurements) –ANN generalises as non-linear model –Issues of variable input conditions (e.g. VZA) –Can train with complex models –Applied to a variety of EO problems
 –Can train with complex models –Applied to a variety of EO problems.")
55
Summary GAs –Novel approach, suitable for highly complex inversion problems –Can be very slow –Not suitable for operationalisation KBS –Use range of information in inversion –Kimes VEG model –Maximises use of data –Need to decide how to encode and use information

56
Summary LUT –Simple method Sort –Used more and more widely for optical model inversion Suitable for well-behaved non-linear problems –Can operationalise –Can use arbitrarily complex models to populate LUT –Issue of LUT size Can use additional information to limit search space Can use interpolation for sparse LUT for high information content inversion

Similar presentations











>")




 Slides are from RPI Registration Class.>")


