Download presentation
Presentation is loading. Please wait.

1
UNIT - I Data Mining 1 1 1

2
UNIT - I Introduction : Fundamentals of data mining, Data Mining Functionalities, Classification of Data Mining systems, Major issues in Data Mining Data Preprocessing : Needs Preprocessing the Data, Data Cleaning, Data Integration and Transformation, Data Reduction, Discretization and Concept Hierarchy Generation. Data Mining Primitives, Data Mining Query Languages, Architectures of Data Mining Systems. Applications : Medical / Pharmacy, Insurance and Health Care.

3
3 3 3

4
4 4 4

5
We are in data rich situation Most of the data never analyzed at all
5 5 5
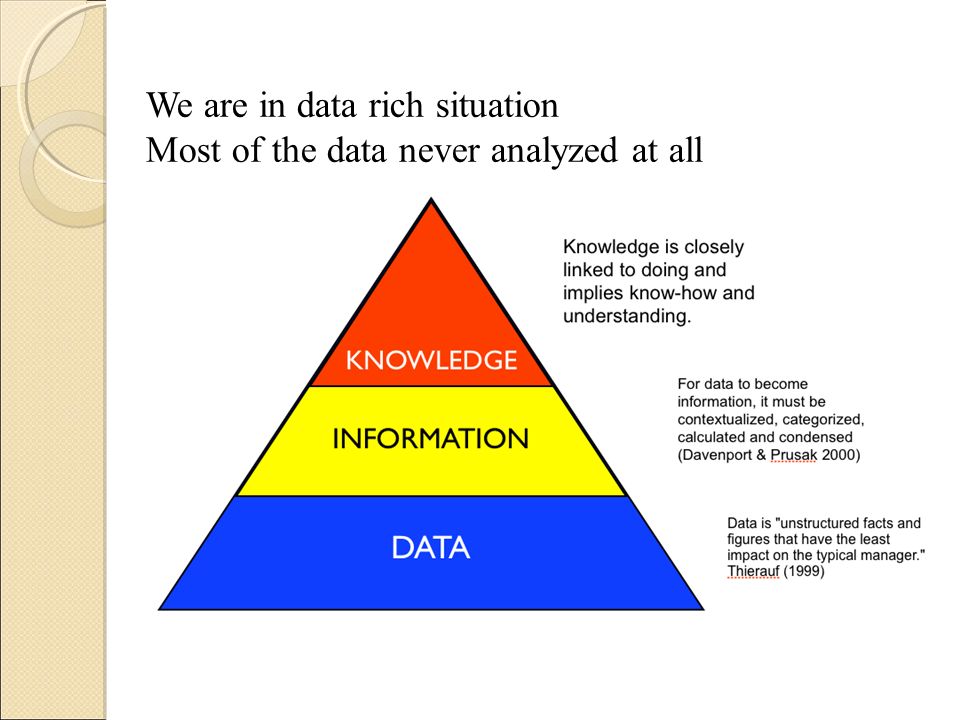
6
There is a gap between the generation of data & our understanding.
But potentially useful knowledge may lie hidden in the data. We need to use computers to automate extraction of the knowledge from the data. 6 6 6

7
Need of Mining? Lots of data is being collected and warehoused
Web data, e-commerce purchases at department/grocery stores Bank/Credit Card transactions 7 7 7

8
Data Data are raw facts and figures that on their own have no meaning
These can be any alphanumeric characters i.e. text, numbers, symbols Eg. Yes, Yes, No, Yes, No, Yes, No, Yes 42, 63, 96, 74, 56, 86 None of the above data sets have any meaning until they are given a CONTEXT and PROCESSED into a useable form Data must be processed in a context in order to give it meaning 8 8 8

9
Yes, Yes, No, Yes, No, Yes, No, Yes, No, Yes, Yes
Information Data that has been processed into a form that gives it meaning In next example we will see What information can then be derived from the data? Raw Data Yes, Yes, No, Yes, No, Yes, No, Yes, No, Yes, Yes Responses to the market research question – “Would you buy brand x at price y?” Context Processing Information ??? 9 9 9

10
Jayne’s scores in the six AS/A2 ICT modules
Example II Raw Data 42, 63, 96, 74, 56, 86 Jayne’s scores in the six AS/A2 ICT modules Context Processing Information ??? 10 10 10

11
11 11 11
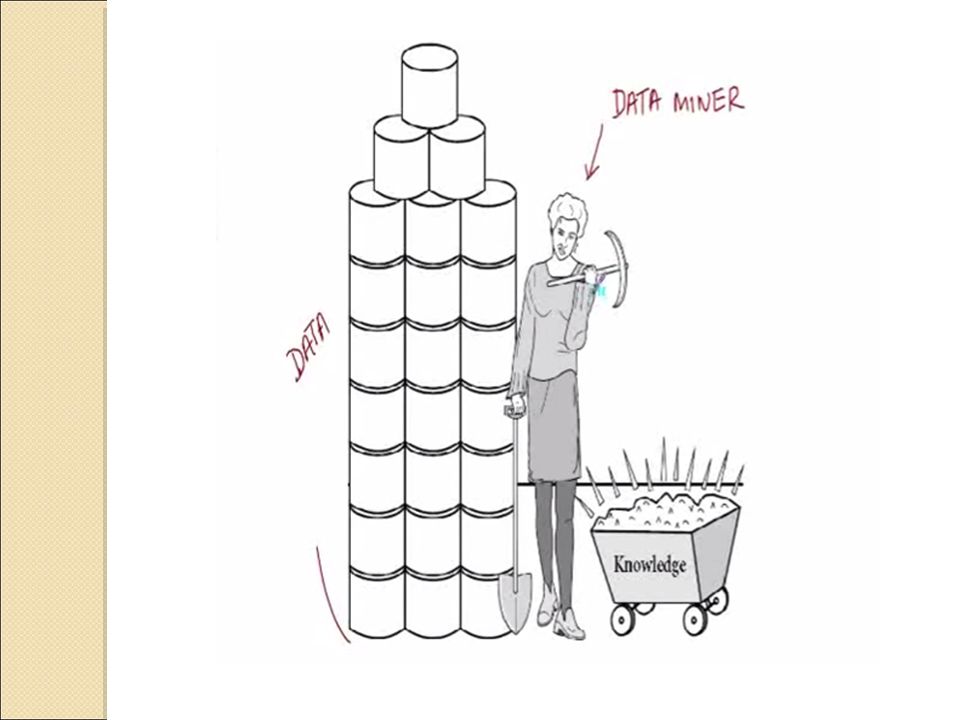
12
What is Data Mining ? Extracting(“mining”) knowledge from large amount of data. (KDD: Knowledge discovery from data). Data mining is the process of automatically discovering useful information in large data repositories We need computational techniques to extract knowledge out of data. 12 12 12

13
This information can be used for any of the following applications:
Market Analysis Fraud Detection Customer Retention Production Control Science Exploration 13 13 13

14
Need of Data Mining In field of Information technology we have huge amount of data available that need to be turned into useful information. It is nothing but extraction of data from large databases for some specialized work. This information further can be used for various applications such as consumer research marketing, product analysis, demand and supply analysis, e-commerce, investment trend in stocks & real estates, telecommunications and so on. 14 14 14

15
Data Mining Applications
Market Analysis and Management Corporate Analysis & Risk Management Fraud Detection Other Applications 15 15 15

16
Market Analysis and Management
Following are the various fields of market where data mining is used: Customer Profiling - Data Mining helps to determine what kind of people buy what kind of products. Identifying Customer Requirements - Data Mining helps in identifying the best products for different customers. It uses prediction to find the factors that may attract new customers. Cross Market Analysis - Data Mining performs Association/correlations between product sales. Target Marketing - Data Mining helps to find clusters of model customers who share the same characteristics such as interest, spending habits, income etc. Determining Customer purchasing pattern - Data mining helps in determining customer purchasing pattern. Providing Summary Information - Data Mining provide us various multidimensional summary reports 16 16 16

17
Corporate Analysis & Risk Management
Following are the various fields of Corporate Sector where data mining is used: Finance Planning and Asset Evaluation - It involves cash flow analysis and prediction, contingent claim analysis to evaluate assets. Resource Planning - It involves summarizing and comparing the resources and spending. Competition - It involves monitoring competitors and market directions. 17 17 17

18
Fraud Detection Other Applications
Data Mining is also used in fields of credit card services and telecommunication to detect fraud. In fraud telephone call it helps to find destination of call, duration of call, time of day or week. It also analyze the patterns that deviate from an expected norms. Other Applications Data Mining also used in other fields such as sports, astrology and Internet Web Surf-Aid. 18 18 18

19
What is Not a Data Mining?
Data Mining isn’t …. Looking up a phone number in a directory Issuing a search engine query for “amazon” Query processing Experts systems or statistical programs Data Mining is…. Certain names are more prevalent in certain India locations eg. Mumbai, Bangalore, Hyderabad… Group together similar documents returned by a search engine eg. Google.com 19 19 19

20
Examples of Data Mining
Safeway: Your purchase data -> relevant coupns Amazon: Your browse history -> times you may like State Farm: Your likelihood of filing claim based on people like you Neuroscience: Find functionally connected brain regions from functional MRI data. Many more… 20 20 20

21
Origins of Data Mining Draw ideas from machine learning / AI, Pattern recognition and databases. Traditional techniques may be unsuitable due to Enormity of data Dimensionality of data Distributed nature of data. 21 21 21

22
Data mining overlaps with many disciplines
Statistics Machine Learning Information Retrieval (Web mining) Distributed Computing Database Systems 22 22
 Distributed Computing. Database Systems")
23
Let me try to briefly define each:
We can say that they are all related, but they are all different things. Although you can have things in common among them, such as that in statistics and data mining you use clustering methods. Let me try to briefly define each: Statistics is a very old discipline mainly based on classical mathematical methods, which can be used for the same purpose that data mining sometimes is which is classifying and grouping things. Data mining consists of building models in order to detect the patterns that allow us to classify or predict situations given an amount of facts or factors. Artificial intelligence (check Marvin Minsky*) is the discipline that tries to emulate how the brain works with programming methods, for example building a program that plays chess. Machine learning is the task of building knowledge and storing it in some form in the computer; that form can be of mathematical models, algorithms, etc... Anything that can help detect patterns. 23 23
 is the discipline that tries to emulate how the brain works with programming methods, for example building a program that plays chess. Machine learning is the task of building knowledge and storing it in some form in the computer; that form can be of mathematical models, algorithms, etc... Anything that can help detect patterns")
24
Why Not Traditional Data Analysis?
Tremendous amount of data Algorithms must be highly scalable to handle such as tera-bytes of data High-dimensionality of data Micro-array may have tens of thousands of dimensions High complexity of data Data streams and sensor data Time-series data, temporal data, sequence data Structure data, graphs, social networks and multi-linked data Heterogeneous databases and legacy databases Spatial, spatiotemporal, multimedia, text and Web data Software programs, scientific simulations New and sophisticated applications 24 24 24

25
Definition of Knowledge Discovery in Data
”KDD Process is the process of using data mining methods (algorithms) to extract (identify) what is deemed knowledge according to the specifications of measures and thresholds, using database F along with any required preprocessing, subsampling, and transformation of F.” ”The nontrivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data” Goals (e.g., Fayyad et al. 1996): Verification of user’s hypothesis (this against the EDA principle…) Autonomous discovery of new patterns and models Prediction of future behavior of some entities Description of interesting patterns and models 25 25 25
 to extract (identify) what is deemed knowledge according to the specifications of measures and thresholds, using database F along with any required preprocessing, subsampling, and transformation of F. The nontrivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data Goals (e.g., Fayyad et al. 1996): Verification of user’s hypothesis (this against the EDA principle…) Autonomous discovery of new patterns and models. Prediction of future behavior of some entities. Description of interesting patterns and models")
26
KDD Process Data mining plays an essential role in the knowledge discovery process Interpretation Data Mining Transformation Preprocessing Knowledge Selection Patterns Transformed Data Preprocessed Data Original Data Target Data 26 26 26

27
KDD versus DM DM is a component of the KDD process that is mainly concerned with means by which patterns and models are extracted and enumerated from the data DM is quite technical Knowledge discovery involves evaluation and interpretation of the patterns and models to make the decision of what constitutes knowledge and what does not KDD requires a lot of domain understanding It also includes, e.g., the choice of encoding schemes, preprocessing, sampling, and projections of the data prior to the data mining step The DM and KDD are often used intergchangebly Perhaps DM is a more common term in business world, and KDD in academic world 27 27 27

28
The main steps of the KDD process
28 28 28
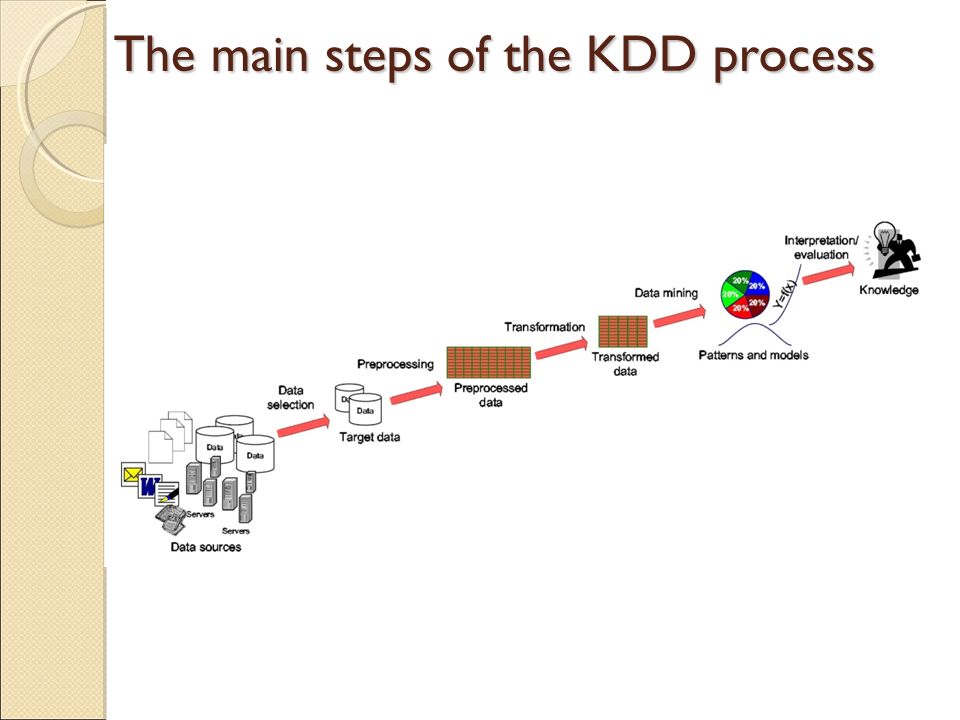
29
7 steps in KDD process 1. Data Cleaning:
to remove noise and inconsistent data 2. Data integration : where multiple data sources may be combined 3. Data selection: where data relevant to the analysis task are retrieved from the data base. 4. Data transformation: where data are transformed and consolidated into forms appropriate for mining by performing summary or aggregation operations. 5. Data mining: an essential process where intelligent methods are applied to extract data patterns 6. Pattern evaluation: to identify the truly interesting patterns representing knowledge based on interestingness measures. 7. Knowledge presentation: where visualization and knowledge representation techniques are used to present mined knowledge to users 29 29 29

30
30 30 30
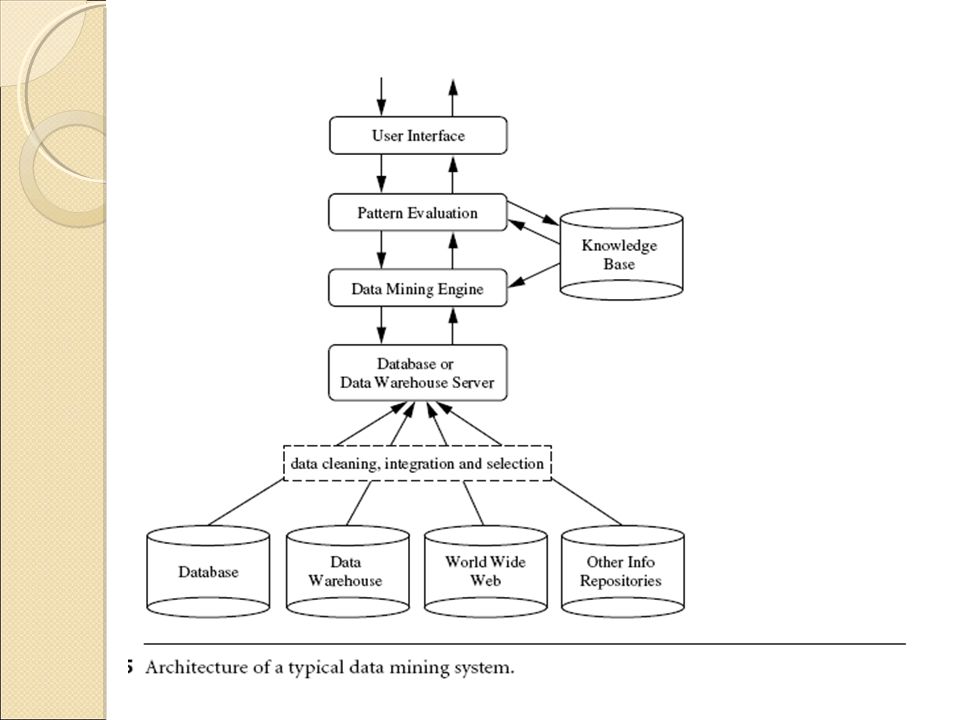
31
Typical Data Mining System Architecture
Database, data warehouse, World Wide Web, or other information repository: This is one or a set of databases, data warehouses, spreadsheets, or other kinds of information repositories. Data cleaning and data integration techniques may be performed on the data. Database or data warehouse server: The database or data warehouse server is responsible for fetching the relevant data, based on the user’s data mining request. 31 31 31

32
Knowledge base: This is the domain knowledge that is used to guide the search or evaluate the interestingness of resulting patterns. Such knowledge can include concept hierarchies, used to organize attributes or attribute values into different levels of abstraction. Data mining engine: This is essential to the data mining system and ideally consists of a set of functional modules for tasks such a characterization, association and correlation analysis, classification, prediction, cluster analysis, outlier analysis, and evolution analysis. 32 32 32

33
Pattern evaluation module:
This component typically employs interestingness measures and interacts with the data mining modules so as to focus the search toward interesting patterns. User interface: This module communicates between users and the data mining system, allowing the user to interact with the system by specifying a data mining query or task, providing information to help focus the search, and performing exploratory data mining based on the intermediate data mining results. 33 33 33

34
Data Mining and Business Intelligence
Increasing potential to support business decisions End User Decision Making Data Presentation Business Analyst Visualization Techniques Data Mining Data Analyst Information Discovery Data Exploration Statistical Summary, Querying, and Reporting Data Preprocessing/Integration, Data Warehouses DBA Data Sources Paper, Files, Web documents, Scientific experiments, Database Systems 34 34 34

35
Data Mining: On What Kinds of Data?
Database-oriented data sets and applications Relational database, data warehouse, transactional database Advanced data sets and advanced applications Data streams and sensor data Time-series data, temporal data, sequence data (incl. bio-sequences) Structure data, graphs, social networks and multi-linked data Heterogeneous databases and legacy databases Spatial data and spatiotemporal data Multimedia database Text databases The World-Wide Web 35 35 35
 Structure data, graphs, social networks and multi-linked data. Heterogeneous databases and legacy databases. Spatial data and spatiotemporal data. Multimedia database. Text databases. The World-Wide Web")
36
Database-oriented data sets
Relational Database: A relational database is a collection of tables, each of which is assigned a unique name. Each table consists of a set of attributes (columns or fields) and usually stores a large set of tuples (records or rows). Each tuple in a relational table represents an object identified by a unique key and described by a set of attribute values. A semantic data model, such as an entity- relationship is often constructed for relational databases. Data Warehouse: A data warehouse is usually modeled by a multidimensional database structure, where each dimension corresponds to an attribute or a set of attributes in the schema, and each cell stores the value of some aggregate measure, such as count or sales amount. The actual physical structure of a data warehouse may be a relational data store or a multidimensional data cube. A data cube provides a multidimensional view of data and allows the pre computation and fast accessing of summarized data. Transactional Database: A transactional database consists of a file where each record represents a transaction. A transaction typically includes a unique transaction identity number (trans ID) and a list of the items making up the transaction (such as items purchased in a store). The transactional database may have additional tables associated with it, which contain other information regarding the sale, such as the date of the transaction, the customer ID number, the ID number of the salesperson and of the branch at which the sale occurred, and so on. 36 36
 and usually stores a large set of tuples (records or rows). Each tuple in a relational table represents an object identified by a unique key and described by a set of attribute values. A semantic data model, such as an entity- relationship is often constructed for relational databases. Data Warehouse: A data warehouse is usually modeled by a multidimensional database structure, where each dimension corresponds to an attribute or a set of attributes in the schema, and each cell stores the value of some aggregate measure, such as count or sales amount. The actual physical structure of a data warehouse may be a relational data store or a multidimensional data cube. A data cube provides a multidimensional view of data and allows the pre computation and fast accessing of summarized data. Transactional Database: A transactional database consists of a file where each record represents a transaction. A transaction typically includes a unique transaction identity number (trans ID) and a list of the items making up the transaction (such as items purchased in a store). The transactional database may have additional tables associated with it, which contain other information regarding the sale, such as the date of the transaction, the customer ID number, the ID number of the salesperson and of the branch at which the sale occurred, and so on")
37
Advanced data sets Object-Relational Databases: Temporal Databases:
Object-relational databases are constructed based on an object-relational data model. This model extends the relational model by providing a rich data type for handling complex objects and object orientation. Because most sophisticated database applications need to handle complex objects and structures, object-relational databases are becoming increasingly popular in industry and applications. Temporal Databases: A temporal database typically stores relational data that include time-related attributes. These attributes may involve several timestamps, each having different semantics. Sequence Databases: A sequence database stores sequences of ordered events, with or without a concrete notion of time. Examples include customer shopping sequences , Web click streams, and biological sequences. 37 37

38
Advanced data sets Time Series Databases: Spatial Databases:
A time-series database stores sequences of values or events obtained over repeated measurements of time (e.g., hourly, daily, weekly). Examples include data collected from the stock exchange, inventory control, and the observation of natural phenomena (like temperature and wind). Spatial Databases: Spatial databases contain spatial-related information. Examples include geographic (map) databases, very large-scale integration (VLSI) or computed-aided design databases, and medical and satellite image databases. Spatial data may be represented in raster format, consisting of n-dimensional bit maps or pixel maps. Spatialtemporal Databases: A spatial database that stores spatial objects that change with time is called a spatiotemporal database, from which interesting information can be mined. 38 38
. Examples include data collected from the stock exchange, inventory control, and the observation of natural phenomena (like temperature and wind). Spatial Databases: Spatial databases contain spatial-related information. Examples include geographic (map) databases, very large-scale integration (VLSI) or computed-aided design databases, and medical and satellite image databases. Spatial data may be represented in raster format, consisting of n-dimensional bit maps or pixel maps. Spatialtemporal Databases: A spatial database that stores spatial objects that change with time is called a spatiotemporal database, from which interesting information can be mined")
39
Advanced data sets Text Databases: Multimedia Databases:
Text databases are databases that contain word descriptions for objects. These word descriptions are usually not simple keywords but rather long sentences or paragraphs, such as product specifications, error or bug reports, warning messages, summary reports, notes, or other documents. Text databases may be highly unstructured (such as some Web pages on the World Wide Web). Multimedia Databases: Multimedia databases store image, audio, and video data. They are used in applications such as picture content-based retrieval, voic systems, video-on-demand systems, the World Wide Web, and speech-based user interfaces that recognize spoken commands. Heterogeneous Databases: A heterogeneous database consists of a set of interconnected, autonomous component databases. The components communicate in order to exchange information and answer queries. Legacy Databases: A legacy database is a group of heterogeneous databases that combines different kinds of data systems, such as relational or object-oriented databases, hierarchical databases, network databases, spreadsheets, multimedia databases, or file systems. The heterogeneous databases in a legacy database may be connected by intra- or inter-computer networks. 39 39
. Multimedia Databases: Multimedia databases store image, audio, and video data. They are used in applications such as picture content-based retrieval, voic systems, video-on-demand systems, the World Wide Web, and speech-based user interfaces that recognize spoken commands. Heterogeneous Databases: A heterogeneous database consists of a set of interconnected, autonomous component databases. The components communicate in order to exchange information and answer queries. Legacy Databases: A legacy database is a group of heterogeneous databases that combines different kinds of data systems, such as relational or object-oriented databases, hierarchical databases, network databases, spreadsheets, multimedia databases, or file systems. The heterogeneous databases in a legacy database may be connected by intra- or inter-computer networks")
40
Advanced data sets Data Streams: World Wide Web:
Many applications involve the generation and analysis of a new kind of data, called stream data, where data flow in and out of an observation platform (or window) dynamically. Such data streams have the following unique features: huge or possibly infinite volume, dynamically changing, flowing in and out in a fixed order, allowing only one or a small number of scans, and demanding fast (often real-time) response time. Typical examples of data streams include various kinds of scientific and engineering data, time- series data, and data produced in other dynamic environments, such as power supply, network traffic, stock exchange, telecommunications, Web click streams, video surveillance, and weather or environment monitoring. World Wide Web: The World Wide Web and its associated distributed information services, such as Yahoo!, Google, America Online, and AltaVista, provide rich, worldwide, on-line information services, where data objects are linked together to facilitate interactive access. For example, understanding user access patterns will not only help improve system design (by providing efficient access between highly correlated objects), but also leads to better marketing decisions (e.g., by placing advertisements in frequently visited documents, or by providing better customer/user classification and behavior analysis). Capturing user access patterns in such distributed information environments is called Web usage mining (or Weblog mining). 40 40
 dynamically. Such data streams have the following unique features: huge or possibly infinite volume, dynamically changing, flowing in and out in a fixed order, allowing only one or a small number of scans, and demanding fast (often real-time) response time. Typical examples of data streams include various kinds of scientific and engineering data, time- series data, and data produced in other dynamic environments, such as power supply, network traffic, stock exchange, telecommunications, Web click streams, video surveillance, and weather or environment monitoring. World Wide Web: The World Wide Web and its associated distributed information services, such as Yahoo!, Google, America Online, and AltaVista, provide rich, worldwide, on-line information services, where data objects are linked together to facilitate interactive access. For example, understanding user access patterns will not only help improve system design (by providing efficient access between highly correlated objects), but also leads to better marketing decisions (e.g., by placing advertisements in frequently visited documents, or by providing better customer/user classification and behavior analysis). Capturing user access patterns in such distributed information environments is called Web usage mining (or Weblog mining)")
41
Data Mining Functionalities – What kind of patterns Can be mined?
Descriptive Mining: Descriptive mining tasks characterize the general properties of the data in the database. Example : Identifying web pages that are accessed together. (human interpretable pattern) Predictive Mining: Predictive mining tasks perform inference on the current data in order to make predictions. Example: Judge if a patient has specific disease based on his/her medical tests results. 41 41 41
 Predictive Mining: Predictive mining tasks perform inference on the current data in order to make predictions. Example: Judge if a patient has specific disease based on his/her medical tests results")
42
Data Mining Functionalities – What kind of patterns Can be mined?
Characterization and Discrimination Mining Frequent Patterns Classification and Prediction Cluster Analysis Outlier Analysis Evolution Analysis 42 42 42

43
Data Mining Functionalities: Characterization and Discrimination
Data can be associated with classes or concepts, it can be useful to describe individual classes or concepts in summarized, concise, and yet precise terms. For example, in the AllElectronics store, classes of items for sale include computers and printers, and concepts of customers include bigSpenders and budgetSpenders. Such descriptions of a concept or class are called class/concept descriptions. These descriptions can be derived via Data Characterization Data Discrimination 43 43 43

44
Data characterization
Data characterization is a summarization of the general characteristics or features of a target class of data. The data corresponding to the user-specified class are typically collected by a query. Ex: For example, to study the characteristics of software products whose sales increased by 10% in the last year, the data related to such products can be collected by executing an SQL query. The output of data characterization can be presented in pie charts, bar charts, multidimensional data cubes, and multidimensional tables. They can also be presented as generalized relations or in rule form (called characteristic rules). 44 44 44
")
45
Data discrimination Data discrimination is a comparison of the target class data objects against the objects from one or multiple contrasting classes with respect to customers that share specified generalized feature(s). A data mining system should be able to compare two groups of AllElectronics customers, such as those who shop for computer products regularly (more than two times a month) versus those who rarely shop for such products (i.e., less than three times a year). The resulting description provides a general comparative profile of the customers, such as 80% of the customers who frequently purchase computer products are between 20 and 40 years old and have a university education, whereas 60% of the customers who infrequently buy such products are either seniors or youths, and have no university degree. 45 45 45
. A data mining system should be able to compare two groups of AllElectronics customers, such as. those who shop for computer products regularly (more than two times a month) versus those who rarely shop for such products (i.e., less than three times a year). The resulting description provides a general comparative profile of the customers, such as 80% of the customers who frequently purchase computer products are between 20 and 40 years old and have a university education, whereas 60% of the customers who infrequently buy such products are either seniors or youths, and have no university degree")
46
Data discrimination The forms of output presentation are similar to those for characteristic descriptions, although discrimination descriptions should include comparative measures that help to distinguish between the target and contrasting classes. Drilling down on a dimension, such as occupation, or adding new dimensions, such as income level, may help in finding even more discriminative features between the two classes. 46 46 46

47
Data Mining Functionalities: Mining Frequent Patterns, Association & Correlations
Frequent patterns, as the name suggests, are patterns that occur frequently in data. There are many kinds of frequent patterns, including itemsets, subsequences, and substructures. A frequent itemset typically refers to a set of items that frequently appear together in a transactional data set, such as milk and bread. Mining frequent patterns leads to the discovery of interesting associations and correlations within data. 47 47 47

48
A data mining system may find association rules like
age(X, “20:::29”)^income(X, “20K:::29K”))buys(X, “CD player”) [support = 2%, confidence = 60%] The rule indicates that of the AllElectronics customers under study, 2% are 20 to 29 years of age with an income of 20,000 to 29,000 and have purchased a CD player at AllElectronics. There is a 60% probability that a customer in this age and income group will purchase a CD player. The above rule can be referred to as a multidimensional association rule. 48 48 48
^income(X, 20K:::29K ))buys(X, CD player ) [support = 2%, confidence = 60%] The rule indicates that of the AllElectronics customers under study, 2% are 20 to 29 years of age with an income of 20,000 to 29,000 and have purchased a CD player at AllElectronics. There is a 60% probability that a customer in this age and income group will purchase a CD player. The above rule can be referred to as a multidimensional association rule")
49
Single dimensional association rule
Marketing manager wants to know which items are Frequently purchased together i.e, within the same transaction . Example mined from the AllElectronics transactional database, is buys(T, “computer”) ^ buys(T, “software”) [support = 1%; confidence = 50%] Where; T is a Transaction . A confidence, or certainty, of 50% means that if a customer buys a computer, there is a 50% chance that she/he will buy software as well. 1% says he will buy both. 49 49 49
 ^ buys(T, software ) [support = 1%; confidence = 50%] Where; T is a Transaction . A confidence, or certainty, of 50% means that if a customer buys a computer, there is a 50% chance that she/he will buy software as well. 1% says he will buy both")
50
50 50 50

51
Data Mining Functionalities: Classification & Prediction
Classification is the process of finding a model (or function) that describes and distinguishes data classes or concepts, for the purpose of being able to use the model to predict the class of objects whose class label is unknown. The derived model is based on the analysis of a set of training data (i.e., data objects whose class label is known). Prediction: Prediction models continuous-valued functions. That is, it is used to predict missing or unavailable numerical data values rather than class labels. 51 51 51
 that describes and distinguishes data classes or concepts, for the purpose of being able to use the model to predict the class of objects whose class label is unknown. The derived model is based on the analysis of a set of training data (i.e., data objects whose class label is known). Prediction: Prediction models continuous-valued functions. That is, it is used to predict missing or unavailable numerical data values rather than class labels")
52
Representation of the data
52 52 52

53
53 53 53
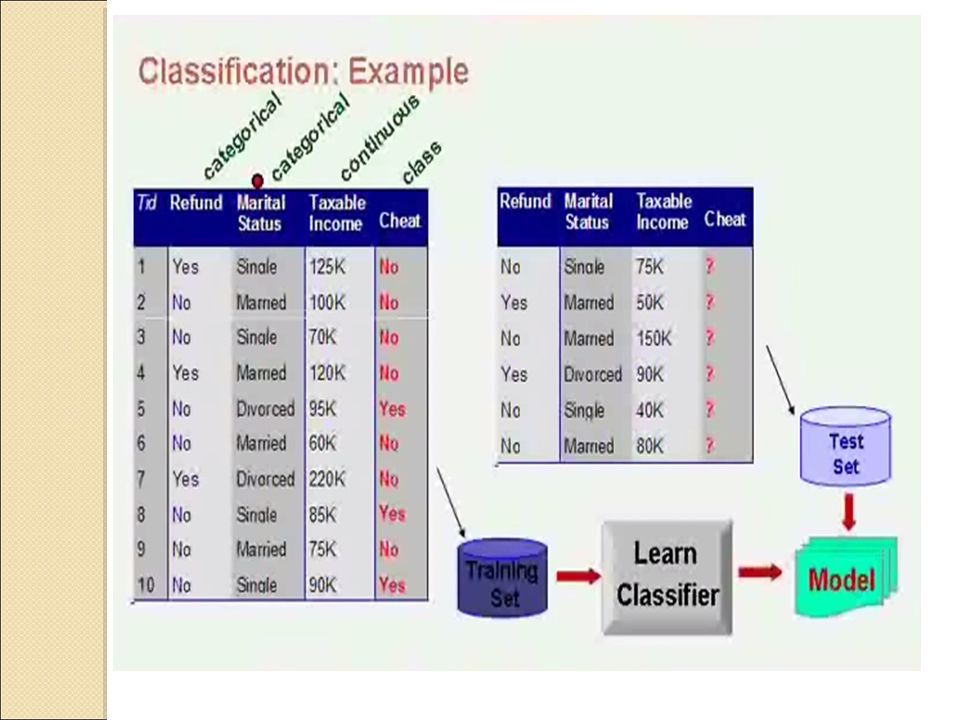
54
Data Mining Functionalities: Cluster Analysis
Unlike classification and prediction, which analyze class-labeled data objects, clustering analyzes data objects without consulting a known class label. The class labels are not present in the training data simply because they are not known to begin with. Clustering can be used to generate such labels. The objects are clustered or grouped based on the principle of maximizing the intraclass similarity and minimizing the interclass similarity. That is, clusters of objects are formed so that objects within a cluster have high similarity in comparison to one another, but are very dissimilar to objects in other clusters 54 54 54

55
55 55 55
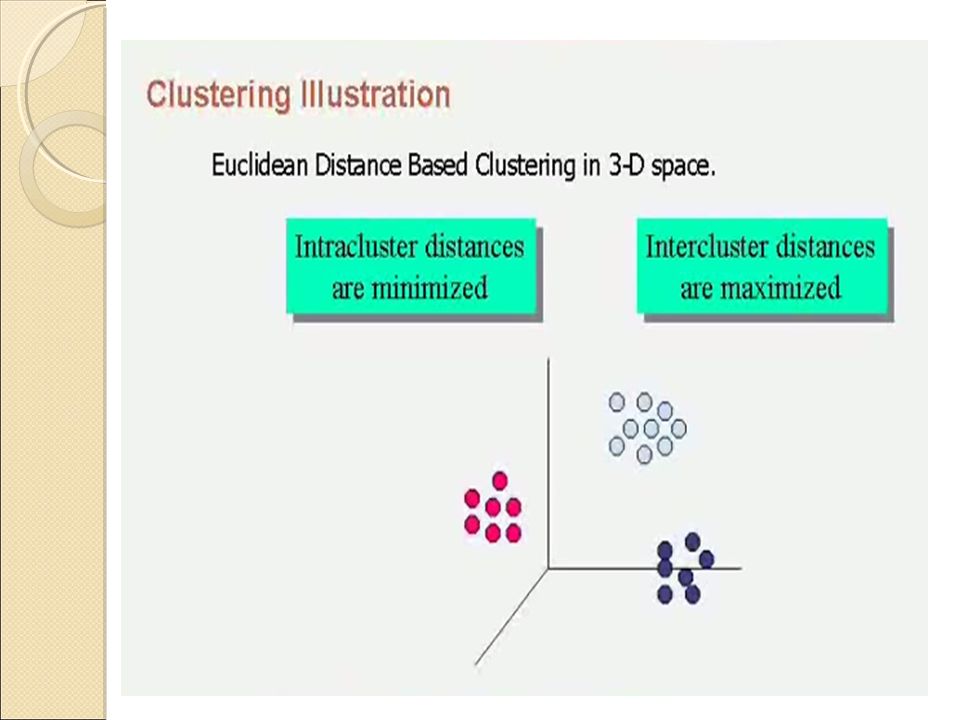
56
Data Mining Functionalities: Outlier Analysis
A database may contain data objects that do not comply with the general behavior or model of the data. These data objects are outliers. Most data mining methods discard outliers as noise or exceptions. However, in some applications such as fraud detection, the rare events can be more interesting than the more regularly occurring ones. The analysis of outlier data is referred to as outlier mining. Outlier analysis may uncover fraudulent usage of credit cards by detecting purchases of extremely large amounts for a given account number in comparison to regular charges incurred by the same account. Outlier values may also be detected with respect to the location and type of purchase, or the purchase frequency. 56 56 56

57
Data Mining Functionalities: Evolution Analysis
Data evolution analysis describes and models regularities or trends for objects whose behavior changes over time. Although this may include characterization, discrimination, association and correlation analysis, classification, prediction, or clustering of time related data, distinct features of such an analysis include time-series data analysis, sequence or periodicity pattern matching, and similarity-based data analysis. 57 57 57

58
Are all Patterns Interesting?
What makes a pattern is interesting? Novel, Potentially useful or desired, understandable and valid 16 Not known before validates a hypothesis that user sought to confirm Easily understood by humans Valid on new set of data with a degree of certainty 58 58 58

59
Are all Patterns Interesting?
Objective measures of interestingness are (measurable): Support: The percentage of transactions from transaction database that the given rule satisfies Confidence: The degree of certainty of given transaction 17 support(X=>Y) = P(XUY) Confidence(X=>Y)=P(Y|X) 59 59 59
: Support: The percentage of transactions from transaction database that the given rule satisfies. Confidence: The degree of certainty of given transaction. 17. support(X=>Y) = P(XUY) Confidence(X=>Y)=P(Y|X)")
60
Are all Patterns Interesting?
Many patterns that are interesting by objective standards may represent common sense and, therefore, are actually un-interesting. So Objective measures are coupled with subjective measures that reflects users needs and interests. Subjective interestingness measures are based on user beliefs in the data. These measures find patterns interesting if the patterns are unexpected (contradicting user’s belief), actionable (offer strategic information on which the user can act) or expected (confirm a hypothesis) 60 60 60
, actionable (offer strategic information on which the user can act) or expected (confirm a hypothesis)")
61
Are all Patterns Interesting?
Can a data mining system generate all of the interesting patterns? A data mining algorithm is complete if it mines all interesting patterns. It is often unrealistic and inefficient for data mining systems to generate all possible patterns. Instead, user-provided constraints and interestingness measures should be used to focus the search. For some mining tasks, such as association, this is often sufficient to ensure the completeness of the algorithm. 61 61 61

62
Are all Patterns Interesting?
Can a data mining system generate only interesting patterns? A data mining algorithm is consistent if it mines only interesting patterns. It is an optimization problem. It is highly desirable for data mining systems to generate only interesting patterns. This would be efficient for users and data mining systems because neither would have to search through the patterns generated to identify the truly interesting ones. Sufficient progress has been made in this direction, but it still a challenging issue in data mining. 62 62 62

63
Data Mining Softwares Angoss Software JDA Intellect CART and MARS
Clementine Data Miner Software kit DBMiner Technologies Enterprise Miner GhostMiner Intelligent Miner JDA Intellect Mantas MCubiX from Diagnos MineSet Mining Mart Oracle Weka 3 63 63

64
Classification of Data Mining Systems
Data mining is interdisciplinary field it is necessary to provide a clear classification of data mining systems, which may help potential users distinguish between such systems and identify those that best match their needs. Data Mining Database Technology Statistics Machine Learning Pattern Recognition Algorithm Other Disciplines Visualization 64 64 64

65
Data mining systems can be categorized according to various criteria, as follows:
Classification according to the kinds of databases mined Classification according to the kinds of knowledge mined Classification according to the kinds of techniques utilized Classification according to the applications adapted 65 65 65

66
Multiple/integrated functions and mining at multiple levels
Data to be mined Relational, data warehouse, transactional, stream, object- oriented/relational, active, spatial, time-series, text, multi-media, heterogeneous, legacy, WWW Knowledge to be mined Characterization, discrimination, association, classification, clustering, trend/deviation, outlier analysis, etc. Multiple/integrated functions and mining at multiple levels Techniques utilized Database-oriented, data warehouse (OLAP), machine learning, statistics, visualization, etc. Applications adapted Retail, telecommunication, banking, fraud analysis, bio-data mining, stock market analysis, text mining, Web mining, etc. 66 66 66
, machine learning, statistics, visualization, etc. Applications adapted. Retail, telecommunication, banking, fraud analysis, bio-data mining, stock market analysis, text mining, Web mining, etc")
67
Data Mining Task Primitives
Task-relevant data Database or data warehouse name Database tables or data warehouse cubes Condition for data selection Relevant attributes or dimensions Data grouping criteria Type of knowledge to be mined Characterization, discrimination, association, classification, prediction, clustering, outlier analysis, other data mining tasks Background knowledge Pattern interestingness measurements Visualization/presentation of discovered patterns 67 67 67

68
Major Issues in Data Mining
Mining methodology and user interaction issues: Mining different kinds of knowledge in databases Interactive mining of knowledge at multiple levels of abstraction Incorporation of background knowledge Data mining query languages and ad hoc data mining Presentation and visualization of data mining results Handling noisy or incomplete data Pattern evaluation—the interestingness problem 68 68 68

69
Performance issues These include efficiency, scalability, and parallelization of data mining algorithms. Efficiency and scalability of data mining algorithms Parallel, distributed, and incremental mining algorithms 69 69 69

70
Issues relating to the diversity of database types
Handling of relational and complex types of data Mining information from heterogeneous databases and global information systems 70 70 70

71
71 71 71

72
Integrating a Data Mining System with a DB/DW System
If a data mining system is not integrated with a database or a data warehouse system, then there will be no system to communicate with. This scheme is known as the no-coupling scheme. In this scheme, the main focus is on data mining design and on developing efficient and effective algorithms; for mining the available data sets.

73
Integrating a Data Mining System with a DB/DW System
Data mining systems, DBMS, Data warehouse systems coupling No coupling, loose-coupling, semi-tight-coupling, tight-coupling On-line analytical mining data integration of mining and OLAP technologies Interactive mining multi-level knowledge Necessity of mining knowledge and patterns at different levels of abstraction by drilling/rolling, pivoting, slicing/dicing, etc. Integration of multiple mining functions Characterized classification, first clustering and then association

74
Coupling Data Mining with DB/DW Systems
No coupling—flat file processing, not recommended Loose coupling Fetching data from DB/DW Semi-tight coupling—enhanced DM performance Provide efficient implement a few data mining primitives in a DB/DW system, e.g., sorting, indexing, aggregation, histogram analysis, multiway join, precomputation of some stat functions Tight coupling—A uniform information processing environment DM is smoothly integrated into a DB/DW system, mining query is optimized based on mining query, indexing, query processing methods, etc.

75
Different coupling schemes:
With this analysis, it is easy to see that a data mining system should be coupled with a DB/DW system. Loose coupling, though not efficient, is better than no coupling because it uses both data and system facilities of a DB/DW system. Tight coupling is highly desirable, but its implementation is nontrivial and more research is needed in this area. Semi tight coupling is a compromise between loose and tight coupling. It is important to identify commonly used data mining primitives and provide efficient implementations of such primitives in DB or DW systems.

76
DBMS, OLAP, and Data Mining

77
Summary Data mining: Discovering interesting patterns from large amounts of data A natural evolution of database technology, in great demand, with wide applications A KDD process includes data cleaning, data integration, data selection, transformation, data mining, pattern evaluation, and knowledge presentation Mining can be performed in a variety of information repositories Data mining functionalities: characterization, discrimination, association, classification, clustering, outlier and trend analysis, etc. Data mining systems and architectures Major issues in data mining 77 77 77

78
UNIT – I Data Mining: Concepts and Techniques — Chapter 2 — Data Preprocessing
78

79
Data Preprocessing Why preprocess the data?
Descriptive data summarization Data cleaning Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary 79 79

80
Why Data Preprocessing?
Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data e.g., occupation=“ ” noisy: containing errors or outliers e.g., Salary=“-10” inconsistent: containing discrepancies in codes or names e.g., Age=“42” Birthday=“03/07/1997” e.g., Was rating “1,2,3”, now rating “A, B, C” e.g., discrepancy between duplicate records 80

81
Why Is Data Dirty? “Not applicable” data value when collected
Incomplete data may come from “Not applicable” data value when collected Different considerations between the time when the data was collected and when it is analyzed. Human/hardware/software problems Noisy data (incorrect values) may come from Faulty data collection instruments Human or computer error at data entry Errors in data transmission Inconsistent data may come from Different data sources Functional dependency violation (e.g., modify some linked data) Duplicate records also need data cleaning 81 81
 may come from. Faulty data collection instruments. Human or computer error at data entry. Errors in data transmission. Inconsistent data may come from. Different data sources. Functional dependency violation (e.g., modify some linked data) Duplicate records also need data cleaning")
82
Why Is Data Preprocessing Important?
No quality data, no quality mining results! Quality decisions must be based on quality data e.g., duplicate or missing data may cause incorrect or even misleading statistics. Data warehouse needs consistent integration of quality data Data extraction, cleaning, and transformation comprises the majority of the work of building a data warehouse 82

83
Multi-Dimensional Measure of Data Quality
A well-accepted multidimensional view: Accuracy Completeness Consistency Timeliness Believability Value added Interpretability Accessibility Broad categories: Intrinsic, contextual, representational, and accessibility 83 83

84
Major Tasks in Data Preprocessing
Data cleaning Fill in missing values, smooth noisy data, identify or remove outliers, and resolve inconsistencies Data integration Integration of multiple databases, data cubes, or files Data transformation Normalization and aggregation Data reduction Obtains reduced representation in volume but produces the same or similar analytical results Data discretization Part of data reduction but with particular importance, especially for numerical data 84 84

85
Forms of Data Preprocessing
85 85

86
Data Pre-processing Why preprocess the data? Descriptive data summarization Descriptive data summarization techniques can be used to identify the typical properties of your data and highlight which data values should be treated as noise or outliers. Need to study central tendency and dispersion of the data. Measures of central tendency include mean, median, mode, and midrange Measures of data dispersion include quartiles, interquartile range (IQR), and variance. These descriptive statistics are of great help in understanding the distribution of the data. 86 86
, and variance. These descriptive statistics are of great help in understanding the distribution of the data")
87
Measuring the Central Tendency
Mean (algebraic measure) (sample vs. population): Distributive measure: sum() and count () Algebric Measure : avg() Weighted arithmetic mean / weighted avg: Trimmed mean: which is the mean obtained after chopping off values at the high and low extremes. For example, we can sort the values observed for salary and remove the top and bottom 2% before computing the mean. We should avoid trimming too large a portion (such as 20%) at both ends as this can result in the loss of valuable information. Problem : Mean is sensitive to extreme values 87 87
 (sample vs. population): Distributive measure: sum() and count () Algebric Measure : avg() Weighted arithmetic mean / weighted avg: Trimmed mean: which is the mean obtained after chopping off values at the high and low extremes. For example, we can sort the values observed for salary and remove the top and bottom 2% before computing the mean. We should avoid trimming too large a portion (such as 20%) at both ends as this can result in the loss of valuable information. Problem : Mean is sensitive to extreme values")
88
Measuring the Central Tendency
Median: Middle value if odd number of values, or average of the middle two values otherwise A holistic measure : is a measure that must be computed on the entire data set as a whole. Holistic measures are much more expensive to compute than distributive measures Estimated by interpolation (for grouped data): 88 88
:")
89
Measuring the Central Tendency
Mode Value that occurs most frequently in the data set Unimodal, bimodal, trimodal Empirical formula: for unimodel frequency ; The midrange can also be used to assess the central tendency of a data set. It is the average of the largest and smallest values in the set. This algebraic measure is easy to compute using the SQL aggregate functions, max() and min(). 89 89
 and min()")
90
Symmetric vs. Skewed Data
Median, mean and mode of symmetric, positively and negatively skewed data 90 February 19, 2008 90 90 90

91
Measuring the Dispersion of Data
Quartiles, Range, outliers and boxplots : Quartiles: Q1 (25th percentile), Q3 (75th percentile) Range : The range of the set is the difference between the largest (max()) and smallest (min()) values. Inter-quartile range: IQR = Q3 – Q1 Distance between the first and third quartiles is a simple measure of spread that gives the range covered by the middle half of the data. Five number summary: min, Q1, M, Q3, max Boxplot: ends of the box are the quartiles, median is marked, whiskers, and plot outlier individually Outlier: usually, a value higher/lower than 1.5 x IQR 91 91
, Q3 (75th percentile) Range : The range of the set is the difference between the largest (max()) and smallest (min()) values. Inter-quartile range: IQR = Q3 – Q1. Distance between the first and third quartiles is a simple measure of spread that gives the range covered by the middle half of the data. Five number summary: min, Q1, M, Q3, max. Boxplot: ends of the box are the quartiles, median is marked, whiskers, and plot outlier individually. Outlier: usually, a value higher/lower than 1.5 x IQR")
92
Box plot example Where; Q1 = 60 Q3 = 100 Median = 80 IQR = 1.5*(40) = 60 Outliers : 175 & 202
 = 60 Outliers : 175 & 202")
93
Measuring the Dispersion of Data
Variance and standard deviation (sample: s, population: σ) Variance: (algebraic, scalable computation) Standard deviation s (or σ) is the square root of variance s2 (or σ2) The computation of the variance and standard deviation is scalable in large databases. 93 93
 Variance: (algebraic, scalable computation) Standard deviation s (or σ) is the square root of variance s2 (or σ2) The computation of the variance and standard deviation is scalable in large databases")
94
Visualization of Data Dispersion: Boxplot Analysis
94 February 19, 2008 94 94 94

95
Graphic Displays of Basic Descriptive Data Summaries
Aside from the bar charts, pie charts, and line graphs used in most statistical or graphical data presentation software packages, there are other popular types of graphs for the display of data summaries and distributions. These include histograms, quantile plots, q-q plots, scatter plots, and loess curves. Such graphs are very helpful for the visual inspection of your data.

99
Data Preprocessing Why preprocess the data?
Descriptive data summarization Data cleaning Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary 99 99

100
Chapter 2: Data Preprocessing
Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary 100

101
Data Cleaning Fill in missing values
Importance “Data cleaning is one of the three biggest problems in data warehousing”—Ralph Kimball “Data cleaning is the number one problem in data warehousing”— DCI survey Data cleaning tasks Fill in missing values Identify outliers and smooth out noisy data Correct inconsistent data Resolve redundancy caused by data integration 101 101

102
Missing Data Data is not always available E.g., many tuples have no recorded value for several attributes, such as Customer Income in sales data Missing data may be due to equipment malfunction inconsistent with other recorded data and thus deleted data not entered due to misunderstanding certain data may not be considered imp. at the time of entry not register history or changes of the data Missing data may need to be inferred. 102

103
How to Handle Missing Data?
Ignore the tuple: usually done when class label is missing (assuming the tasks in classification) not effective when the percentage of missing values per attribute varies considerably. Fill in the missing value manually: time-consuming + infeasible in large data sets? Fill in it automatically with a global constant : e.g., “unknown”, a new class? (if so, the mining prog may mistakenly think that they form an interesting concept, since they all have a value in common as “unknown”- it Is simple but foolproof. the attribute mean or median the attribute mean for all samples belonging to the same class: smarter ( ex: if classifying custmoers acc. To credit-risk, we may replace the missing value with the mean income value for customers in the same credit risk category as that of the given tuple. the most probable value: inference-based such as Bayesian formula or decision tree 103
 not effective when the percentage of missing values per attribute varies considerably. Fill in the missing value manually: time-consuming + infeasible in large data sets 3. Fill in it automatically with. a global constant : e.g., unknown , a new class (if so, the mining prog may mistakenly think that they form an interesting concept, since they all have a value in common as unknown - it Is simple but foolproof. the attribute mean or median. the attribute mean for all samples belonging to the same class: smarter. ( ex: if classifying custmoers acc. To credit-risk, we may replace the missing value with the mean income value for customers in the same credit risk category as that of the given tuple. the most probable value: inference-based such as Bayesian formula or decision tree")
104
Noisy Data Noise: random error or variance in a measured variable
Incorrect attribute values may due to faulty data collection instruments data entry problems data transmission problems technology limitation inconsistency in naming convention Other data problems which requires data cleaning duplicate records incomplete data inconsistent data 104

105
How to Handle Noisy Data?
Binning first sort data and partition into (equal-frequency) bins then one can smooth by bin means, smooth by bin median, smooth by bin boundaries, etc. Regression smooth by fitting the data into regression functions Clustering detect and remove outliers Semi-automated method: combined computer and human inspection detect suspicious values and check manually 105 105
 bins. then one can smooth by bin means, smooth by bin median, smooth by bin boundaries, etc. Regression. smooth by fitting the data into regression functions. Clustering. detect and remove outliers. Semi-automated method: combined computer and human inspection. detect suspicious values and check manually")
106
Simple Discretization Methods: Binning
Equal-width (distance) partitioning Divides the range into N intervals of equal size: uniform grid if A and B are the lowest and highest values of the attribute, the width of intervals will be: W = (B –A)/N. The most straightforward, but outliers may dominate presentation Skewed data is not handled well Equal-depth (frequency) partitioning Divides the range into N intervals, each containing approximately same number of samples Good data scaling Managing categorical attributes can be tricky 106
 partitioning. Divides the range into N intervals of equal size: uniform grid. if A and B are the lowest and highest values of the attribute, the width of intervals will be: W = (B –A)/N. The most straightforward, but outliers may dominate presentation. Skewed data is not handled well. Equal-depth (frequency) partitioning. Divides the range into N intervals, each containing approximately same number of samples. Good data scaling. Managing categorical attributes can be tricky")
107
Binning Methods for Data Smoothing
Sorted data for price (in dollars): 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34 * Partition into equal-frequency (equi-depth) bins: - Bin 1: 4, 8, 9, 15 - Bin 2: 21, 21, 24, 25 - Bin 3: 26, 28, 29, 34 * Smoothing by bin means: - Bin 1: 9, 9, 9, 9 - Bin 2: 23, 23, 23, 23 - Bin 3: 29, 29, 29, 29 * Smoothing by bin boundaries: - Bin 1: 4, 4, 4, 15 - Bin 2: 21, 21, 25, 25 - Bin 3: 26, 26, 26, 34 107
: 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34. * Partition into equal-frequency (equi-depth) bins: - Bin 1: 4, 8, 9, Bin 2: 21, 21, 24, Bin 3: 26, 28, 29, 34. * Smoothing by bin means: - Bin 1: 9, 9, 9, 9. - Bin 2: 23, 23, 23, Bin 3: 29, 29, 29, 29. * Smoothing by bin boundaries: - Bin 1: 4, 4, 4, Bin 2: 21, 21, 25, Bin 3: 26, 26, 26,")
108
Regression Linear regression – find the best line to fit two variables and use regression function to smooth data Data can be smoothed by fitting the data to a function, such as with regression. y Y1 Y1’ y = x + 1 X1 x Linear regression (best line to fit two variables) Multiple linear regression (more than two variables), fit to a multidimensional surface 108 108
 Multiple linear regression (more. than two variables), fit to a. multidimensional surface")
109
Cluster Analysis detect and remove outliers, Where similar values are organized into groups or “clusters” 109

110
How to Handle Inconsistent Data?
Manual correction using external references Semi-automatic using various tools To detect violation of known functional dependencies and data constraints To correct redundant data 110 110 110

111
Data Preprocessing Why preprocess the data? Data cleaning
Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary 111

112
Data Integration Data integration: Combines data from multiple sources into a coherent store Issues to be considered Schema integration: e.g., “cust-id” & “cust-no” Integrate metadata from different sources Entity identification problem: Identify real world entities from multiple data sources, e.g., Bill Clinton = William Clinton Detecting and resolving data value conflicts For the same real world entity, attribute values from different sources are different Possible reasons: different representations, different scales, e.g., metric vs. British units 112

113
Handling Redundancy in Data Integration
Redundant data occur often when integration of multiple databases is done. Object identification: The same attribute or object may have different names in different databases Derivable data: One attribute may be a “derived” attribute in another table, e.g., annual revenue, age Redundant attributes can be detected by correlation analysis Careful integration of the data from multiple sources may help reduce/avoid redundancies and inconsistencies and improve mining speed and quality. 113

114
Correlation Analysis (Numerical Data)
Correlation coefficient (also called Pearson’s product moment coefficient) Where; n is the number of tuples are the respective means of A and B, σA and σB are the respective standard deviation of A and B, Σ(AB) is the sum of the AB cross-product. If rA,B > 0, A and B are positively correlated (A’s values increase as B’s). The higher, the stronger correlation. rA,B = 0: independent; rA,B < 0: negatively correlated 114
 Where; n is the number of tuples. are the respective means of A and B, σA and σB are the respective standard deviation of A and B, Σ(AB) is the sum of the AB cross-product. If rA,B > 0, A and B are positively correlated (A’s values increase as B’s). The higher, the stronger correlation. rA,B = 0: independent; rA,B < 0: negatively correlated")
115
Correlation analysis of categorical (discrete) attributes using chi square.
For given example expected frequency for the cell ( male , Fiction) is: Chi square computation is : For 1 degree of freedom, the chi square value needed to reject hypothesis at the significance level is Our value is above this so we can reject the hypothesis that gender and prefered_reading are independent.
 is: Chi square computation is : For 1 degree of freedom, the chi square value needed to reject hypothesis at the significance level is Our value is above this so we can reject the hypothesis that gender and prefered_reading are independent.")
116
Data Transformation Smoothing: remove noise from data using smoothing techniques Aggregation: summarization, data cube construction Generalization: concept hierarchy climbing Normalization: scaled to fall within a small, specified range min-max normalization z-score normalization normalization by decimal scaling Attribute/feature construction: New attributes constructed from the given ones 116 116

117
Data Transformation: Normalization
Min-max normalization: For Linear Transformation; to [new_minA, new_maxA] Ex. Let income range $12,000 to $98,000 normalized to [0.0, 1.0]. Then $73,600 is mapped to Z-score normalization (μ: mean, σ: standard deviation): Ex. Let μ (mean) = 54,000, σ (std. dev)= 16,000. Then Normalization by decimal scaling Where j is the smallest integer such that, Max(|ν’|) < 1 117
: Ex. Let μ (mean) = 54,000, σ (std. dev)= 16,000. Then. Normalization by decimal scaling. Where j is the smallest integer such that, Max(|ν’|) <")
118
Data Preprocessing Why preprocess the data? Data cleaning
Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary 118

119
Data Reduction Problem: Data Warehouse may store terabytes of data
Complex data analysis/mining may take a very long time to run on the complete data set Solution? Data reduction… 119 119

120
Data Reduction Obtains a reduced representation of the data set that is much smaller in volume but yet produces the same (or almost the same) analytical results Data reduction strategies Data cube aggregation : Dimensionality reduction: e.g., remove unimportant attributes Data compression : Numerosity reduction: e.g., fit data into models Discretization and concept hierarchy generation : 120 120
 analytical results. Data reduction strategies. Data cube aggregation : Dimensionality reduction: e.g., remove unimportant attributes. Data compression : Numerosity reduction: e.g., fit data into models. Discretization and concept hierarchy generation :")
121
2- Dimensional Aggregation
Imagine that you have collected the data for your analysis. These data consist of the AllElectronics sales per quarter, for the years 2002 to You are, however, interested in the annual sales (total per year), rather than the total per quarter. Thus the data can be aggregated so that the resulting data summarize the total sales per year instead of per quarter. 121
, rather than the total per quarter. Thus the data can be aggregated so that the resulting data summarize the total sales per year instead of per quarter")
122
Data cube Data cubes store multidimensional aggregated information.
Each cell holds an aggregate data value, corresponding to the data point in multidimensional space. Data cubes provide fast access to precomputed, summarized data, thereby benefiting OLAP as well as data mining. 122

123
Data Cube Aggregation The lowest level of a data cube (base cuboid)
The cube created at the lowest level of abstraction is referred to as the base cuboid. The aggregated data for an individual entity of interest E.g., a customer in a phone calling data warehouse A cube at the highest level of abstraction is the apex cuboid. Multiple levels of aggregation in data cubes Further reduce the size of data to deal with Queries regarding aggregated information should be answered using data cube, when possible 123

124
Dimensionality reduction: Attribute Subset Selection
Feature selection (i.e., attribute subset selection): Select a minimum set of features such that the probability distribution of different classes given the values for those features is as close as possible to the original distribution given the values of all features reduce number of patterns in the patterns, easier to understand Heuristic methods (due to exponential # of choices): Step-wise forward selection Step-wise backward elimination Combining forward selection and backward elimination Decision-tree induction 124
: Select a minimum set of features such that the probability distribution of different classes given the values for those features is as close as possible to the original distribution given the values of all features. reduce number of patterns in the patterns, easier to understand. Heuristic methods (due to exponential # of choices): Step-wise forward selection. Step-wise backward elimination. Combining forward selection and backward elimination. Decision-tree induction")
125
“How can we find a ‘good’ subset of the original attributes?”
For n attributes, there are 2n possible subsets. An exhaustive search for the optimal subset of attributes can be prohibitively expensive, especially as n and the number of data classes increase. Therefore, heuristic methods that explore a reduced search space are commonly used for attribute subset selection. These methods are typically greedy in that, while searching through attribute space, they always make what looks to be the best choice at the time. Their strategy is to make a locally optimal choice in the hope that this will lead to a globally optimal solution. Such greedy methods are effective in practice and may come close to estimating an optimal solution. The “best” (and “worst”) attributes are typically determined using tests of statistical significance, which assume that the attributes are independent of one another. 125
 attributes are typically determined using tests of statistical significance, which assume that the attributes are independent of one another")
126
Heuristic Feature Selection Methods
Several heuristic feature selection methods: Best single features under the feature independence assumption: choose by significance tests Best step-wise forward selection: The best single-feature is picked first Then next best feature condition to the first, ... Step-wise backward elimination: Repeatedly eliminate the worst feature Best combined forward selection and backward elimination Optimal branch and bound: Use feature elimination and backtracking 126

127
127

128
Example of Decision Tree Induction
Initial attribute set: {A1, A2, A3, A4, A5, A6} A4 ? Y N A1? A6? N Y N Y Class 2 Class 2 Class 1 Class 1 Reduced attribute set: {A1, A4, A6} > 128

129
Dimensionality Reduction
Data transformations are applied so as to obtain a reduced or compressed representation of the original data. If the original data can be reconstructed from the compressed data without any loss of information is called lossless. If we can construct only an approximation of the original data, then the data reduction is called lossy. 129

130
Data Compression String compression There are extensive theories and well-tuned algorithms Typically lossless But only limited manipulation is possible without expansion Audio/video compression Typically lossy compression, with progressive refinement Sometimes small fragments of signal can be reconstructed without reconstructing the whole Time sequence is not audio Typically short and vary slowly with time 130

131
Data Compression lossless Original Data Compressed Data Original Data
Approximated lossy 131

132
How to handle Dimensionality Reduction
DWT (Discrete Wavelet Transform) Principal Components Analysis Numerosity Reduction 132
 Principal Components Analysis. Numerosity Reduction")
133
Wavelet transforms DWT (Discrete Wavelet Transform):
Haar2 Daubechie4 DWT (Discrete Wavelet Transform): is a linear signal processing technique. The data vector X transforms it to a numerically different vector X’ of Wavelet coefficients. The two vector of same length. A compressed approximation of the data can be retained by storing only a small fraction of the strongest of the wavelet coefficients. Similar to discrete Fourier transform (DFT), but better lossy compression, localized in space 133
: is a linear signal processing technique. The data vector X transforms it to a numerically different vector X’ of Wavelet coefficients. The two vector of same length. A compressed approximation of the data can be retained by storing only a small fraction of the strongest of the wavelet coefficients. Similar to discrete Fourier transform (DFT), but better lossy compression, localized in space")
134
Implementing 2D-DWT Decomposition COLUMN j ROW i 134134 134

135
2-D DWT ON MATLAB Load Image Choose (must be wavelet type .mat file)
Hit Analyze Choose display options 135

136
Data Compression: Principal Component Analysis (PCA)
Given N data vectors from n-dimensions, find k ≤ n orthogonal vectors (principal components) that can be best used to represent data Steps: Normalize input data: Each attribute falls within the same range Compute k orthonormal (unit) vectors, i.e., principal components Each input data (vector) is a linear combination of the k principal component vectors The principal components are sorted in order of decreasing “significance” or strength Since the components are sorted, the size of the data can be reduced by eliminating the weak components, i.e., those with low variance. (i.e., using the strongest principal components, it is possible to reconstruct a good approximation of the original data Works for numeric data only Used when the number of dimensions is large 136
 that can be best used to represent data. Steps: Normalize input data: Each attribute falls within the same range. Compute k orthonormal (unit) vectors, i.e., principal components. Each input data (vector) is a linear combination of the k principal component vectors. The principal components are sorted in order of decreasing significance or strength. Since the components are sorted, the size of the data can be reduced by eliminating the weak components, i.e., those with low variance. (i.e., using the strongest principal components, it is possible to reconstruct a good approximation of the original data. Works for numeric data only. Used when the number of dimensions is large")
137
Principal Component Analysis
Y1 & Y2 are the first principal components for the given data X2 Y1 Y2 X1 137 137

138
Numerosity Reduction Reduce data volume by choosing alternative, smaller forms of data representation Parametric methods Assume the data fits some model, estimate model parameters, store only the parameters, and discard the data (except possible outliers) Example: Log-linear models—obtain value at a point in m-D space as the product on appropriate marginal subspaces Non-parametric methods Do not assume models Major families: histograms, clustering, sampling 138
 Example: Log-linear models—obtain value at a point in m-D space as the product on appropriate marginal subspaces. Non-parametric methods. Do not assume models. Major families: histograms, clustering, sampling")
139
Parametric methods Regression
Linear regression: Data are modeled to fit a .....straight line Often uses the least-square method to fit the line Linear regression: Two parameters , w and b specify the line and are to be estimated by using the data at hand. using the least squares criterion to the known values of Y1, Y2, … , X1, X2, …. 139

140
Data Reduction Method (1): Regression and Log-Linear Models
Linear regression: Data are modeled to fit a straight line Often uses the least-square method to fit the line Multiple regression: allows a response variable Y to be modeled as a linear function of multidimensional feature vector Log-linear model: approximates discrete multidimensional probability distributions 140

141
Regress Analysis and Log-Linear Models
Linear regression: Y = w X + b Two regression coefficients, w and b, specify the line and are to be estimated by using the data at hand Using the least squares criterion to the known values of Y1, Y2, …, X1, X2, …. Multiple regression: Y = b0 + b1 X1 + b2 X2. Many nonlinear functions can be transformed into the above Log-linear models: The multi-way table of joint probabilities is approximated by a product of lower-order tables Probability: p(a, b, c, d) 141 141
")
142
Data Reduction Method (2): Histograms
Divide data into buckets and store average (sum) for each bucket Partitioning rules: Equal-width: equal bucket range Equal-frequency (or equal-depth) V-optimal: with the least histogram variance (weighted sum of the original values that each bucket represents) MaxDiff: set bucket boundary between each pair for pairs have the β–1 largest differences 142
 for each bucket. Partitioning rules: Equal-width: equal bucket range. Equal-frequency (or equal-depth) V-optimal: with the least histogram variance (weighted sum of the original values that each bucket represents) MaxDiff: set bucket boundary between each pair for pairs have the β–1 largest differences")
143
Data Reduction Method (3): Clustering
Partition data set into clusters based on similarity, and store cluster representation (e.g., centroid and diameter) only Can be very effective if data is clustered but not if data is “smeared” Can have hierarchical clustering and be stored in multi-dimensional index tree structures There are many choices of clustering definitions and clustering algorithms Cluster analysis will be studied in depth in Chapter 7 143
 only. Can be very effective if data is clustered but not if data is smeared Can have hierarchical clustering and be stored in multi-dimensional index tree structures. There are many choices of clustering definitions and clustering algorithms. Cluster analysis will be studied in depth in Chapter")
144
Clustering Raw Data 144

145
Data Reduction Method (4): Sampling
Sampling: obtaining a small sample s to represent the whole data set N Allow a mining algorithm to run in complexity that is potentially sub- linear to the size of the data Choose a representative subset of the data Simple random sampling may have very poor performance in the presence of skew Develop adaptive sampling methods Stratified sampling: Approximate the percentage of each class (or subpopulation of interest) in the overall database Used in conjunction with skewed data Note: Sampling may not reduce database I/Os (page at a time) 145
 in the overall database. Used in conjunction with skewed data. Note: Sampling may not reduce database I/Os (page at a time) 145.")
146
Sampling: with or without Replacement
Raw Data SRSWOR (simple random sample without replacement) SRSWR 146
 SRSWR")
147
Sampling: Cluster or Stratified Sampling
Cluster/Stratified Sample Raw Data 147

148
Chapter 3: Data Preprocessing
Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary 148

149
Discretization Three types of attributes:
Nominal — values from an unordered set, e.g., color, profession Ordinal — values from an ordered set, e.g., military or academic rank Continuous — real numbers, e.g., integer or real numbers Discretization: Divide the range of a continuous attribute into intervals Some classification algorithms only accept categorical attributes. Reduce data size by discretization Prepare for further analysis 149

150
Discretization and Concept Hierarchy
Reduce the number of values for a given continuous attribute by dividing the range of the attribute into intervals Interval labels can then be used to replace actual data values Supervised vs. unsupervised If Discretization process Used class information then we say Supervised. Split (top-down) vs. merge (bottom-up) If the process starts by first finding one or a few points (called split points or cut points) to split the entire attribute range, and then repeats this recursively on the resulting intervals, it is called top-down discretization or splitting. In contrast bottom-up starts by considering all of the continuous values as potential split- points, removes some by merging neighborhood values to form intervals, and then recursively applies this process to the resulting intervals. Discretization can be performed recursively on an attribute 150
 vs. merge (bottom-up) If the process starts by first finding one or a few points (called split points or cut points) to split the entire attribute range, and then repeats this recursively on the resulting intervals, it is called top-down discretization or splitting. In contrast bottom-up starts by considering all of the continuous values as potential split- points, removes some by merging neighborhood values to form intervals, and. then recursively applies this process to the resulting intervals. Discretization can be performed recursively on an attribute")
151
Concept hierarchy formation
Recursively reduce the data by collecting and replacing low level concepts (such as numeric values for age) by higher level concepts (such as young, middle-aged, or senior)
 by higher level concepts (such as young, middle-aged, or senior)")
152
Discretization and Concept Hierarchy Generation for Numeric Data
Typical methods: All the methods can be applied recursively Binning (covered above) Top-down split, unsupervised, Histogram analysis (covered above) Top-down split, unsupervised Clustering analysis (covered above) Either top-down split or bottom-up merge, unsupervised Entropy-based discretization: supervised, top-down split Interval merging by X2 Analysis: unsupervised, bottom-up merge Segmentation by natural partitioning: top-down split, unsupervised 152
 Top-down split, unsupervised, Histogram analysis (covered above) Top-down split, unsupervised. Clustering analysis (covered above) Either top-down split or bottom-up merge, unsupervised. Entropy-based discretization: supervised, top-down split. Interval merging by X2 Analysis: unsupervised, bottom-up merge. Segmentation by natural partitioning: top-down split, unsupervised")
153
Entropy-Based Discretization
Given a set of samples S, if S is partitioned into two intervals S1 and S2 using boundary T, the information gain after partitioning is Entropy is calculated based on class distribution of the samples in the set. Given m classes, the entropy of S1 is where pi is the probability of class i in S1 The boundary that minimizes the entropy function over all possible boundaries is selected as a binary discretization The process is recursively applied to partitions obtained until some stopping criterion is met Such a boundary may reduce data size and improve classification accuracy 153 153

154
Segmentation by Natural Partitioning
A simply rule can be used to segment numeric data into relatively uniform, “natural” intervals. If an interval covers 3, 6, 7 or 9 distinct values at the most significant digit, partition the range into 3 equi-width intervals If it covers 2, 4, or 8 distinct values at the most significant digit, partition the range into 4 intervals If it covers 1, 5, or 10 distinct values at the most significant digit, partition the range into 5 intervals 154

155
Concept Hierarchy Generation for Categorical Data
Specification of a partial/total ordering of attributes explicitly at the schema level by users or experts street < city < state < country Specification of a hierarchy for a set of values by explicit data grouping {Urbana, Champaign, Chicago} < Illinois Specification of only a partial set of attributes E.g., only street < city, not others Automatic generation of hierarchies (or attribute levels) by the analysis of the number of distinct values E.g., for a set of attributes: {street, city, state, country} 155
 by the analysis of the number of distinct values. E.g., for a set of attributes: {street, city, state, country} 155.")
156
Automatic Concept Hierarchy Generation
Some hierarchies can be automatically generated based on the analysis of the number of distinct values per attribute in the data set The attribute with the most distinct values is placed at the lowest level of the hierarchy Exceptions, e.g., weekday, month, quarter, year country province_or_ state city street 15 distinct values 365 distinct values 3567 distinct values 674,339 distinct values 156

157
Chapter : Data Preprocessing
Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary 157

158
Summary Data preparation or preprocessing is a big issue for both data warehousing and data mining Discriptive data summarization is need for quality data preprocessing Data preparation includes Data cleaning and data integration Data reduction and feature selection Discretization A lot a methods have been developed but data preprocessing still an active area of research 158

Similar presentations
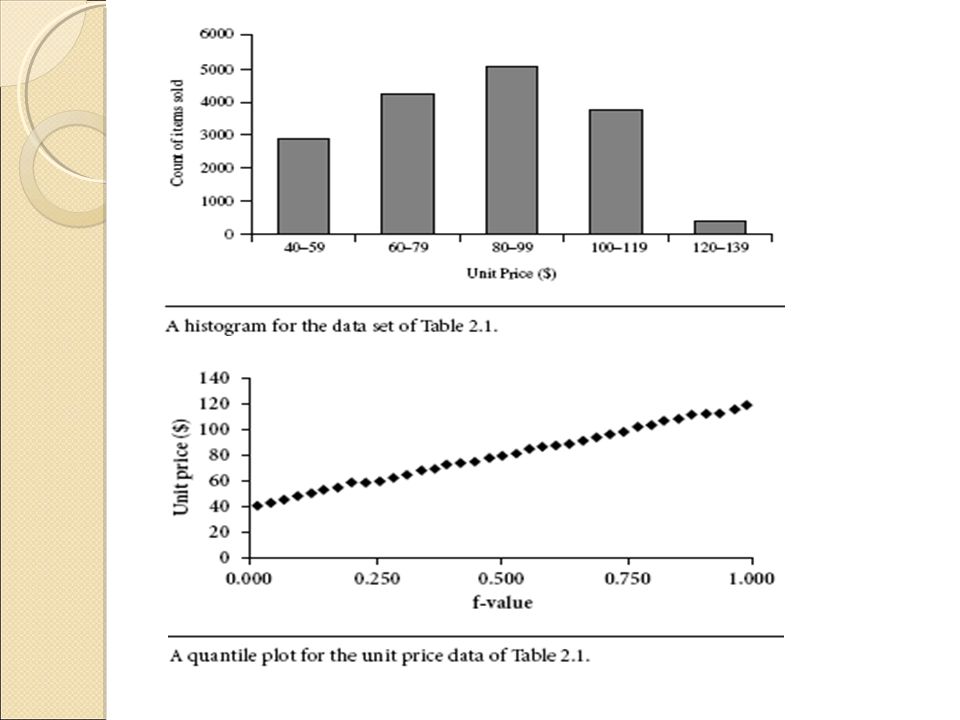
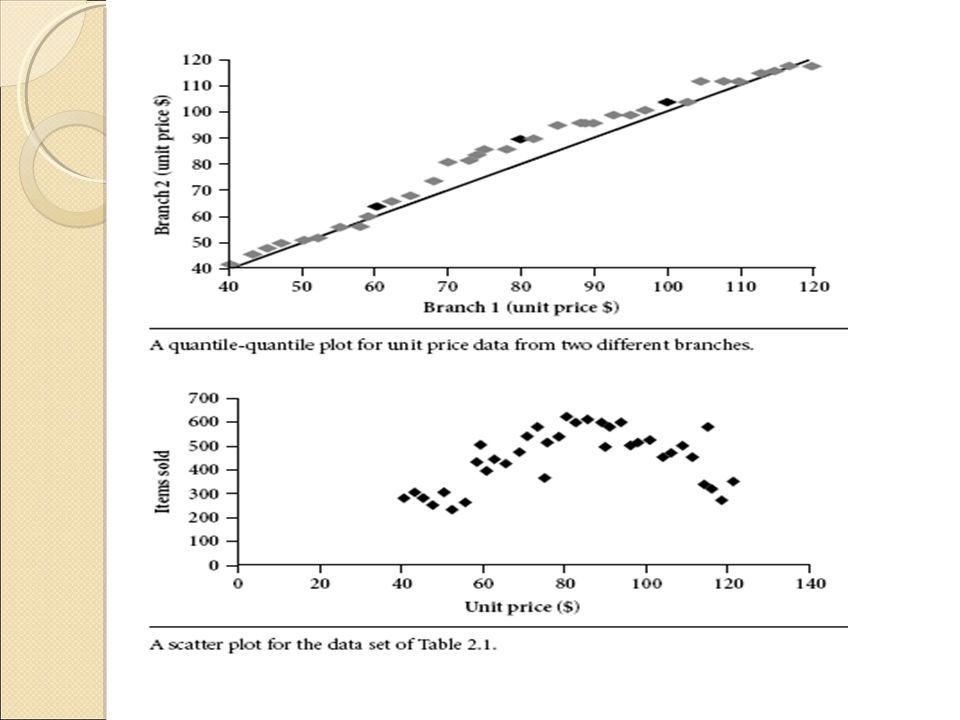
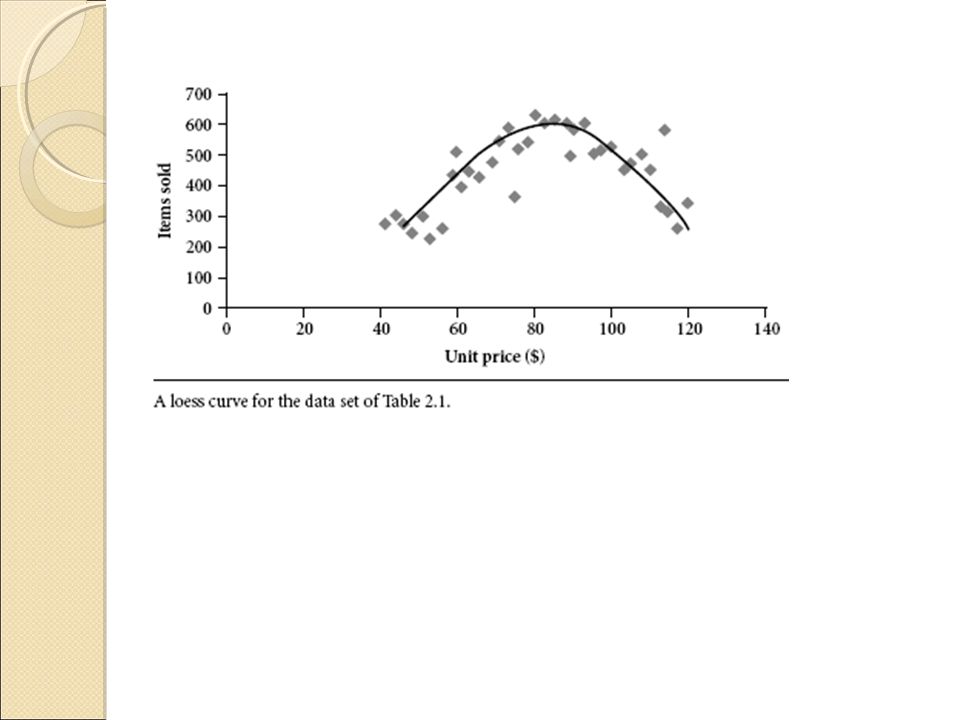















 By Prof. Muhammad Amir Alam.>")



