Download presentation
Presentation is loading. Please wait.

1
Biological Databases By : Lim Yun Ping E mail : yunping@chitre.net
National University of Singapore

2
Overview Introduction What is a database
What type of databases can we access What roles do they play What type of information can we get from them How do we access these information

3
What is a database ? Convenient method of vast amount of information
Allows for proper storing, searching & retrieving of data. Before analyzing them we need to assemble them into central, shareable resources

4
Why databases ? Means to handle and share large volumes of biological data Support large-scale analysis efforts Make data access easy and updated Link knowledge obtained from various fields of biology and medicine

5
Different Database Types
depends on the nature of information stored (sequences, 2D gel or 3D structure images) manner of storage (flat files, tables in a relational database, etc) In this course we are concerned more about the different types of databases rather than the particular storage
 manner of storage (flat files, tables in a relational database, etc) In this course we are concerned more about the different types of databases rather than the particular storage.")
6
Features Most of the databases have a web-interface to search for data
Common mode to search is by Keywords User can choose to view the data or save to your computer Cross-references help to navigate from one database to another easily

7
Biological Databases

8
Types Of Biological Databases Accessible
There are many different types of database but for routine sequence analysis, the following are initially the most important Primary databases Secondary databases Composite databases

9
Nucleic Acid Databases
Primary databases Contain sequence data such as nucleic acid or protein Example of primary databases include : Nucleic Acid Databases EMBL Genbank DDBJ Protein Databases SWISS-PROT TREMBL PIR

10
Secondary databases Or sometimes known as pattern databases
Contain results from the analysis of the sequences in the primary databases Example of secondary databases include : PROSITE Pfam BLOCKS PRINTS

11
Composite databases Combine different sources of primary databases.
Make querying and searching efficient and without the need to go to each of the primary databases. Example of composite databases include : NRDB – Non-Redundant DataBase OWL

12
Nucleic acid Databases
NCBI : NCBI, at the NIH campus, USA EMBL : European Molecular Biology Laboratory, UK DDBJ DDBJ : DNA Databank of Japan Nucleic acid Databases

13
The International Sequence Database Collaboration
GenBank EMBL DDBJ

14
The International Sequence Database Collaboration
These three databases have collaborated since Each database collects and processes new sequence data and relevant biological information from scientists in their region e.g. EMBL collects from Europe, GenBank from the USA. These databases automatically update each other with the new sequences collected from each region, every 24 hours. The result is that they contain exactly the same information, except for any sequences that have been added in the last 24 hours. This is an important consideration in your choice of database. If you need accurate and up to date information, you must search an up to date database.

15
Amount Of Data Grows Rapidly
As of June 2003, there were bases in sequence

16
How to access them NCBI : http://www.ncbi.nlm.nih.gov/
Main Sites NCBI : EMBL : DDBJ : full release every two months incremental and cumulative updates daily available only through internet ftp://ftp.ncbi.nih.gov/genbank/ 66.3 Gigabytes of data

17
The Internet and WWW

18
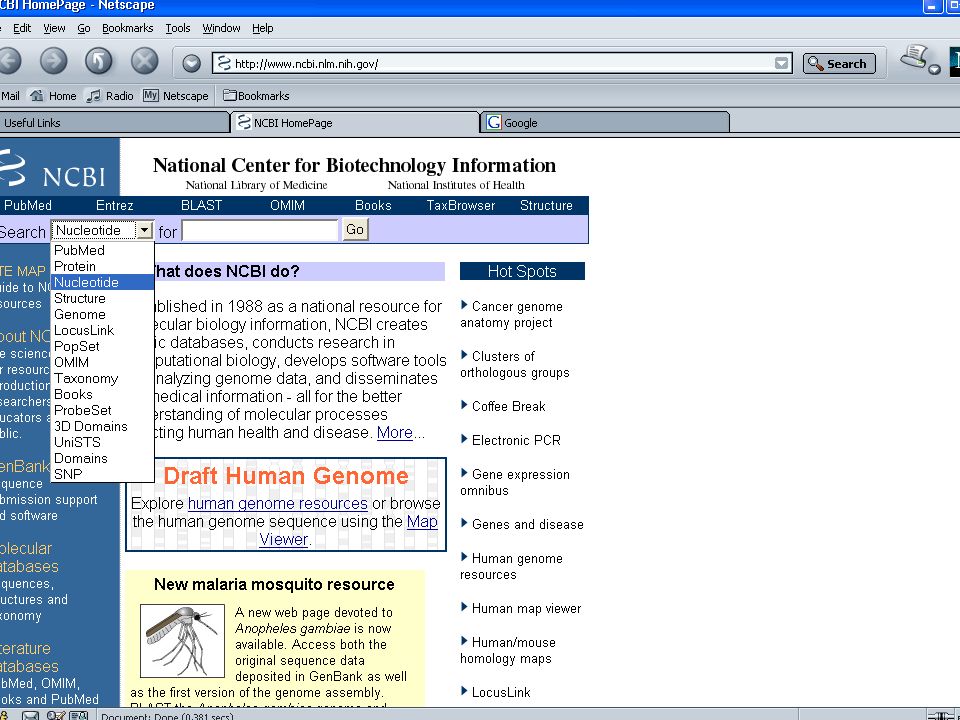
NCBI : http://www.ncbi.nlm.nih.gov/
NCBI, a division of NLM at the NIH campus, USA EXPASY : Swiss Institute of Bioinformatics Kyoto Encyclopedia of Genes and Genomes

19
National Centre for Biotechnology Information
Established in 1988 as a national resource for molecular biology information, NCBI creates public databases, conducts research in computational biology, develops software tools for analyzing genome data, and disseminates biomedical information all for the better understanding of molecular processes affecting human health and disease.

21
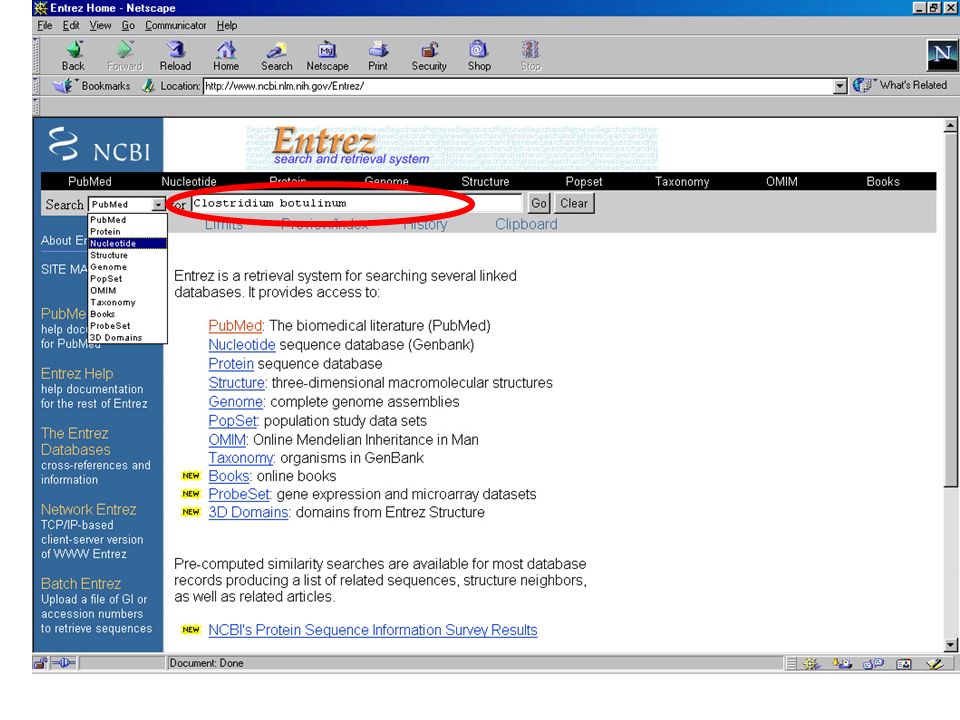
Entrez Entrez is a search and retrieval system that integrates information from databases at NCBI.

23
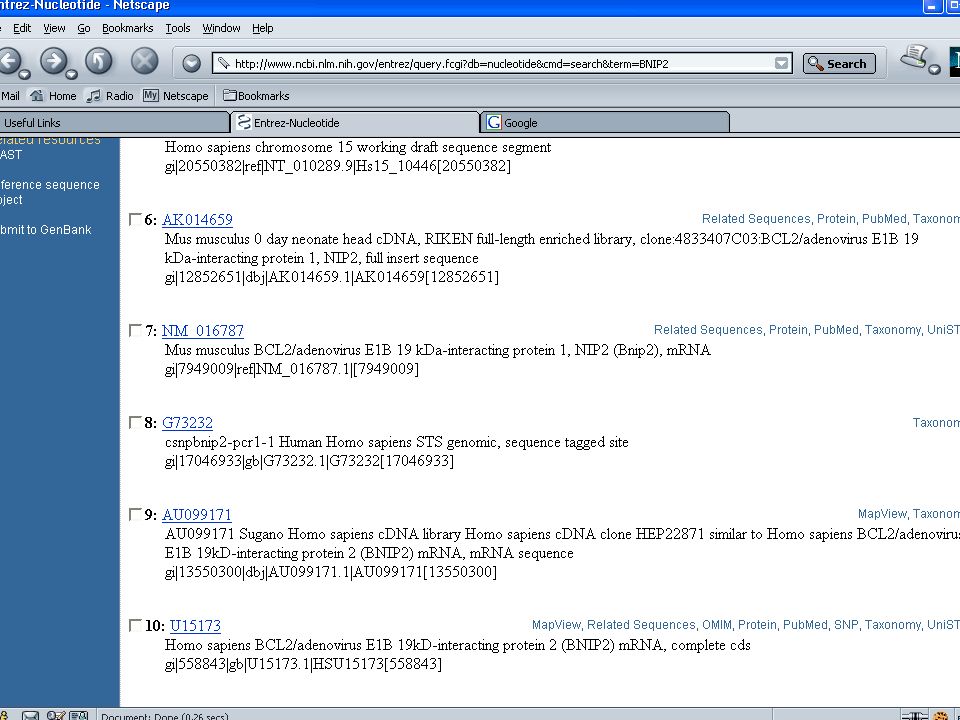
BNIP

25
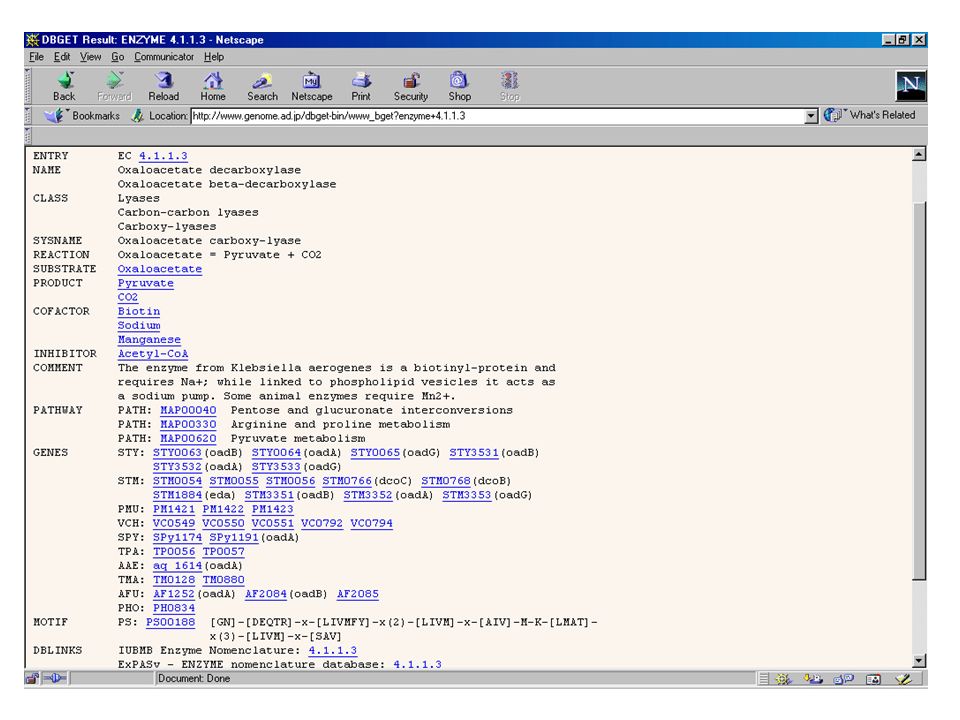
Accession Number : Unique identifier Source : Organism’s common name
Brief description of the sequence. Accession Number : Unique identifier Source : Organism’s common name Formal scientific name Contains information on the publications such as the authors, and topic titles of the journals that discuss the data reported in the record. Contains the contact information of the submitter Contains the information about the genes, gene products and regions of biological significance reported in the sequence & length of sequence scientific name of the source organism Taxon ID number, Map location

26
Coding sequence (region of the nucleotides that correspond to the sequence of amino acid). This is also the location that contains the start and stop codon. Region of biological interest The amino acid translation corresponding to the nucleotide coding sequence

27
How to understand the output
Unique Identifiers : Each entry in a database must have a unique identifier EMBL Identifier (ID) GENBANK Accession Number (AC) Other information is stored along with the sequence. Each piece of information is written on it's own line, with a code defining the line. For example, DE, description; OS, organism species; AC, accession number. Relevant biological information is usually described in the feature table (FT).
 GENBANK Accession Number (AC) Other information is stored along with the sequence. Each piece of information is written on it s own line, with a code defining the line. For example, DE, description; OS, organism species; AC, accession number. Relevant biological information is usually described in the feature table (FT).")
28
Genbank Flat File Format
Refer to Summary Description of the Genbank Flat File Format Or

29
ExPASy Expert Protein Analysis System proteomics server of the Swiss Institute of Bioinformatics (SIB) dedicated to the analysis of protein sequences and structures

30
Databases on the Expasy server
SWISS-PROT and TrEMBL - Protein knowledgebase PROSITE - Protein families and domains SWISS-2DPAGE - Two-dimensional polyacrylamide gel electrophoresis ENZYME - Enzyme nomenclature SWISS-3DIMAGE - 3D images of proteins and other biological macromolecules SWISS-MODEL Repository - Automatically generated protein models

31
SWISS-PROT A curated protein sequence database which strives to provide a high level of annotations (such as the description of the function of a protein, its domains structure, post-translational modifications, variants, etc.), a minimal level of redundancy and high level of integration with other databases
, a minimal level of redundancy and high level of integration with other databases")
32
TrEMBL Computer-annotated supplement to SWISS-PROT

33
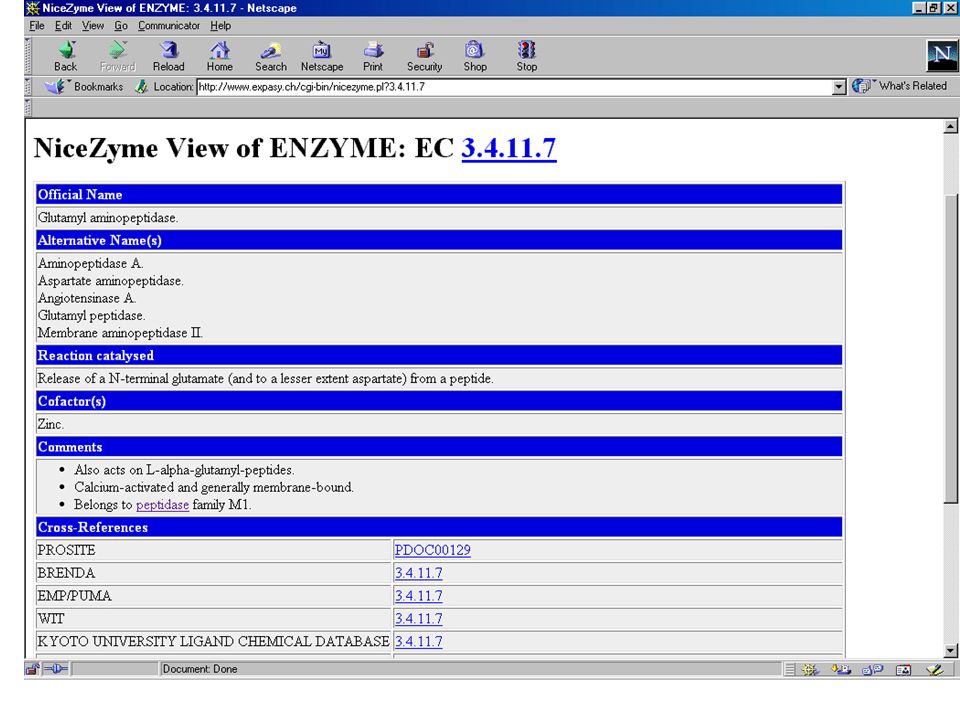
Enzyme nomenclature database http://tw.expasy.org/enzyme/

34
ENZYME Database A repository of information relative to the nomenclature of enzymes Describes each type of characterized enzyme for which an EC (Enzyme Commission) number has been provided
 number has been provided.")
35
Access to ENZYME by EC number by enzyme class
by description (official name) or alternative name(s) by chemical compound by cofactor
 or alternative name(s) by chemical compound. by cofactor.")
38
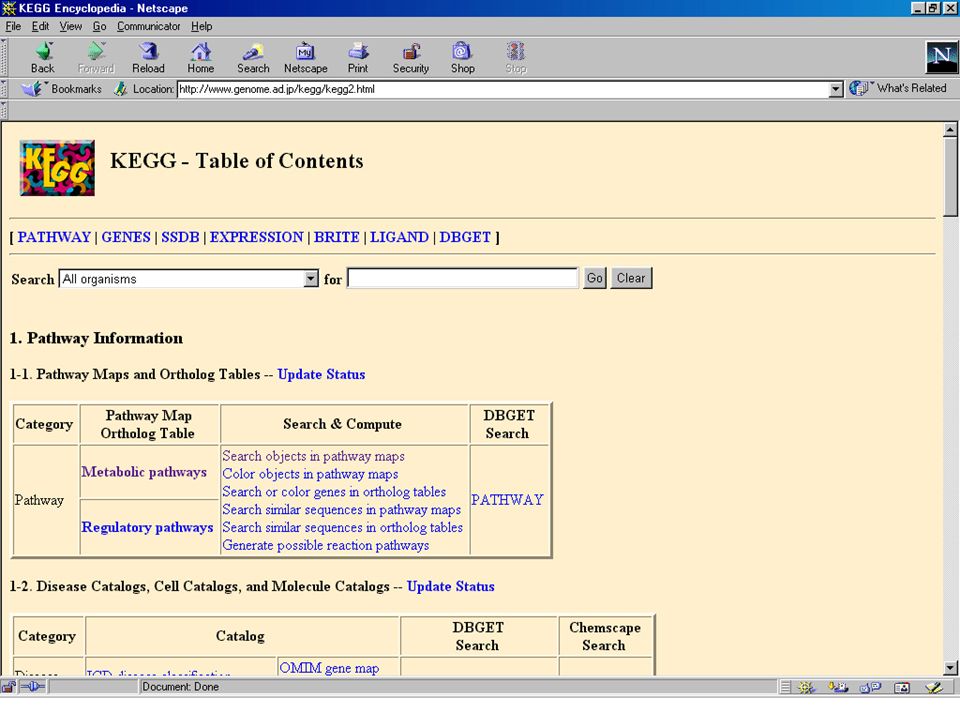
Kyoto Encyclopedia of Genes and Genomes
K E G G Kyoto Encyclopedia of Genes and Genomes

39
A structured database containing information about metabolic pathways in many organisms.

40
KEGG Part of the GenomeNet database system
Linked to all accessible databases by search engines; LIGAND & BRITE

43
Link to other pathways Enzyme Compound

45
Summary Biological databases represent an invaluable resource in support of biological research. We can learn much about a particular molecule by searching databases and using available analysis tools. A large number of databases are available for that task. Some databases are very general while some are very specialised. For best results we often need to access multiple databases.

46
Common database search methods include keyword matching, sequence similarity, motif searching, and class searching The problems with using biological databases include incomplete information, data spread over multiple databases, redundant information, various errors, sometimes incorrect links, and constant change.

47
Database standards, nomenclature, and naming conventions are not clearly defined for many aspects of biological information. This makes information extraction more difficult Retrieval systems help extract rich information from multiple databases. Examples include Entrez and SRS. Formulating queries is a serious issue in biological databases. Often the quality of results depends on the quality of the queries. Access to biological databases is so important that today virtually every molecular biological project starts and ends with querying biological databases.

48
The End

Similar presentations



 Sequence Information Lecture 7.>")
 a primary resource for molecular biology information www.ncbi.nih.gov Database Resources.>")














