Download presentation
Presentation is loading. Please wait.

1
EECE 571R (Spring 2009) Massively parallel/distributed platforms Matei Ripeanu matei at ece.ubc.ca
 Massively parallel/distributed platforms Matei Ripeanu matei at ece.ubc.ca")
2
Contact Info Email: matei @ ece.ubc.ca Office: KAIS 4033 Office hours: by appointment (email me) Course page: http://www.ece.ubc.ca/~matei/EECE571/
 Course page:")
3
EECE 571R: Course Goals Primary –Gain understanding of fundamental issues that affect design of: Large-scale systems – massively parallel / massively distributed –Survey main current research themes –Gain experience with distributed systems research Research on: federated system, networks Secondary –By studying a set of outstanding papers, build knowledge of how to do & present research –Learn how to read papers & evaluate ideas

4
What I’ll Assume You Know Basic Internet architecture –IP, TCP, DNS, HTTP Basic principles of distributed computing –Asynchrony (cannot distinguish between communication failures and latency) –Incomplete & inconsistent global state knowledge (cannot know everything correctly) –Failures happen (in large systems, even rare failures of individual components, aggregate to high failure rates) If there are things that don’t make sense, ask!
 –Incomplete & inconsistent global state knowledge (cannot know everything correctly) –Failures happen (in large systems, even rare failures of individual components, aggregate to high failure rates) If there are things that don’t make sense, ask!")
5
Outline Case study (and project ideas): –Amdahl’s Law in the Multi-core Era Administrative: course schedule/organization
: –Amdahl’s Law in the Multi-core Era Administrative: course schedule/organization")
6
Amdahl’s Law in the Multicore Era Acknowledgement:: some slides borrowed form Mark D. Hill, David Patterson, Jim Larus, Saman Amarasinghe, Richard Brunner, Luddy Harrison presentations

9
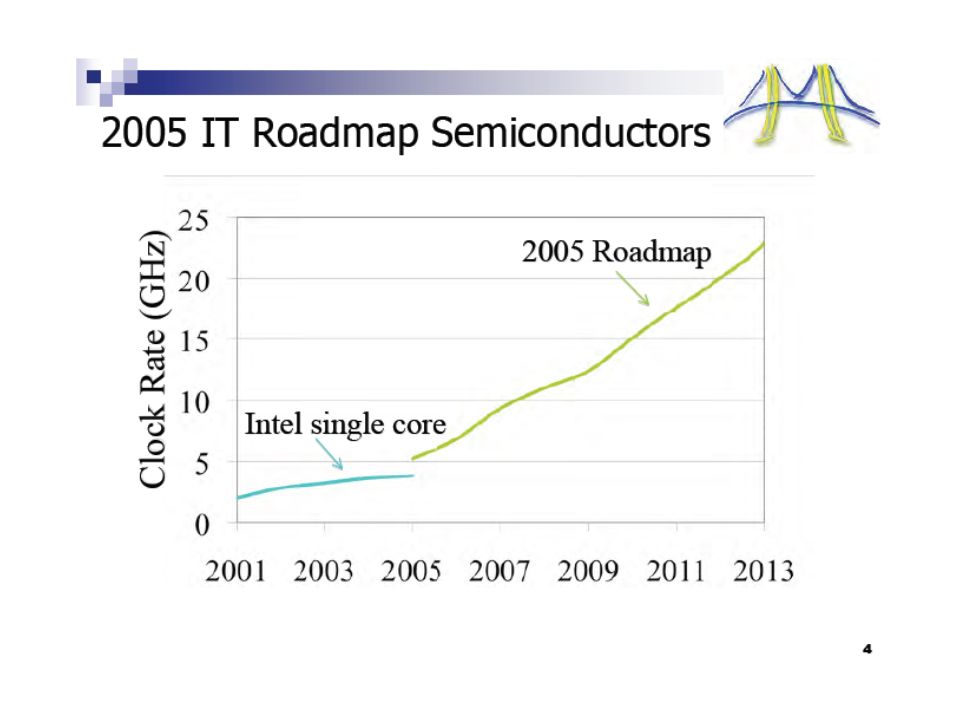
Moore’s Laws

10
Technology & Moore’s Law Transistor 1947 Integrated Circuit 1958 (a.k.a. Chip) Moore’s Law 1964: # Transistors per Chip doubles every two years (or 18 months)
 Moore’s Law 1964: # Transistors per Chip doubles every two years (or 18 months).")
11
Architects & Another Moore’s Law Microprocessor 1971 50M transistors ~2000 Popular Moore’s Law: Processor (core) performance doubles every two years
 performance doubles every two years")
12
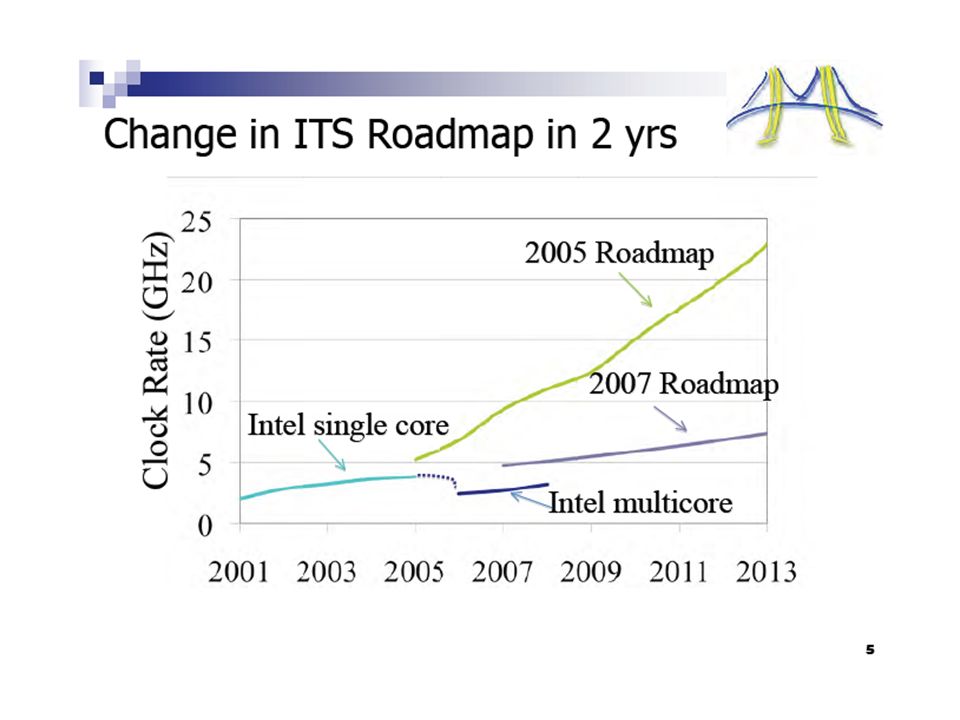
Multicore Chip (a.k.a. Chip Multiprocesors) Why Multicore? Power simpler structures Memory Concurrent accesses to tolerate off-chip latency Wires intra-core wires shorter Complexity divide & conquer But more cores; NOT faster cores Will effective chip performance keep doubling every two years? Eight 4-way cores 2006

13
Virtuous Cycle, circa 1950 – 2005 World-Wide Software Market (per IDC): $212b (2005) $310b (2010) Increased processor performance Larger, more feature-full software Larger development teams Higher-level languages & abstractions Slower programs
: $212b (2005) $310b (2010) Increased processor performance Larger, more feature-full software Larger development teams Higher-level languages & abstractions Slower programs")
14
Increased processor performance Larger, more feature-full software Larger development teams Higher-level languages & abstractions Slower programs Virtuous Cycle, 2005 – ??? World-Wide Software Market $212b (2005) ? X GAME OVER — NEXT LEVEL? Thread Level Parallelism & Multicore Chips
 . X GAME OVER — NEXT LEVEL. Thread Level Parallelism & Multicore Chips.")
15
Summary: A Corollary to Amdahl’s Law Develop Simple Model of Multicore Hardware –Complements Amdahl’s software model –Fixed chip resources for cores –Core performance improves sub-linearly with resources Shows Need For Research To –Increase parallelism (Are you surprised?) –Increase core performance (especially for larger chips) –Refine asymmetric designs (e.g., one core enhanced) –Refine dynamically harnessing cores for serial performance
 –Increase core performance (especially for larger chips) –Refine asymmetric designs (e.g., one core enhanced) –Refine dynamically harnessing cores for serial performance")
16
Outline Recall Amdahl’s Law A Model of Multicore Hardware Symmetric Multicore Chips Asymmetric Multicore Chips Dynamic Multicore Chips Caveats & Wrap Up

17
Amdahl’s Law Begins with Simple Software Assumption (Limit Arg.) –Fraction F of execution time perfectly parallelizable –No Overhead for –Scheduling –Synchronization –Communication, etc. –Fraction 1 – F Completely Serial Time on 1 core = (1 – F) / 1 + F / 1 = 1 Time on N cores = (1 – F) / 1 + F / N
 / 1 + F / 1 = 1 Time on N cores = (1 – F) / 1 + F / N.")
18
Amdahl’s Law [1967] Implications: –Attack the common case when introducing paralelizations: When f is small, optimizations will have little effect. –The aspects you ignore also limit speedup: As N approaches infinity, speedup is bound by 1/(1 – f ). Amdahl’s Speedup = 1 + 1 - F 1 F N
![Amdahl’s Law [1967] Implications: –Attack the common case when introducing paralelizations: When f is small, optimizations will have little effect.](http://images.slideplayer.com/24/7553408/slides/slide_18.jpg "–The aspects you ignore also limit speedup: As N approaches infinity, speedup is bound by 1/(1 – f ). Amdahl’s Speedup = F 1 F N.")
19
Amdahl’s Law [1967] Discussion: –Can you ever obtain super-linear speedups? Amdahl’s Speedup = 1 + 1 - F 1 F N
![Amdahl’s Law [1967] Discussion: –Can you ever obtain super-linear speedups.](http://images.slideplayer.com/24/7553408/slides/slide_19.jpg "Amdahl’s Speedup = F 1 F N.")
20
Amdahl’s Law [1967] For mainframes, Amdahl expected 1 - F = 35% –For a 4-processor speedup = 2 –For infinite-processor speedup < 3 –Therefore, stay with mainframes with one/few processors Q: Does it make sense to design massively multicore chips? What kind? Amdahl’s Speedup = 1 + 1 - F 1 F N
![Amdahl’s Law [1967] For mainframes, Amdahl expected 1 - F = 35% –For a 4-processor speedup = 2 –For infinite-processor speedup < 3 –Therefore, stay with mainframes with one/few processors Q: Does it make sense to design massively multicore chips.](http://images.slideplayer.com/24/7553408/slides/slide_20.jpg "What kind. Amdahl’s Speedup = F 1 F N.")
21
Designing Multicore Chips Hard Designers must confront single-core design options –Instruction fetch, wakeup, select –Execution unit configuation & operand bypass –Load/queue(s) & data cache –Checkpoint, log, runahead, commit. As well as additional design degrees of freedom –How many cores? How big each? –Shared caches: levels? How many banks? –Memory interface: How many banks? –On-chip interconnect: bus, switched?

22
Want Simple Multicore Hardware Model To Complement Amdahl’s Simple Software Model (1) Chip Hardware Roughly Partitioned into –(I) Multiple Cores (with L1 caches) –(II) The Rest (L2/L3 cache banks, interconnect, pads, etc.) –Assume: Changing Core Size/Number does NOT change The Rest (2) Resources for Multiple Cores Bounded –Bound of N resources per chip for cores –Due to area, power, cost ($$$), or multiple factors –Bound = Power? (but pictures here use Area)
.")
23
Want Simple Multicore Hardware Model, cont. (3) Architects can improve single-core performance using more of the bounded resource A Simple Base Core –Consumes 1 Base Core Equivalent (BCE) resources –Provides performance normalized to 1 An Enhanced Core (in same process generation) –Consumes R x BCEs –Performance as a function Perf(R) What does function Perf(R) look like?
 Architects can improve single-core performance using more of the bounded resource A Simple Base Core –Consumes 1 Base Core Equivalent (BCE) resources –Provides performance normalized to 1 An Enhanced Core (in same process generation) –Consumes R x BCEs –Performance as a function Perf(R) What does function Perf(R) look like .")
24
More on Enhanced Cores (Performance Perf(R) consuming R BCEs resources) If Perf(R) > R Always enhance core Cost-effectively speedups both sequential & parallel Therefore, equations assume Perf(R) < R Graphs Assume Perf(R) = square root of R –2x performance for 4 BCEs, 3x for 9 BCEs, etc. –Why? Models diminishing returns with “no coefficients” How to speedup enhanced core? –

25
Outline Recall Amdahl’s Law A Model of Multicore Hardware Symmetric Multicore Chips Asymmetric Multicore Chips Dynamic Multicore Chips Caveats & Wrap Up

26
How Many (Symmetric) Cores per Chip? Each Chip Bounded to N BCEs (for all cores) Each Core consumes R BCEs Assume Symmetric Multicore = All Cores Identical Therefore, N/R Cores per Chip — (N/R)*R = N For an N = 16 BCE Chip: Sixteen 1-BCE coresFour 4-BCE cores One 16-BCE core
 Each Core consumes R BCEs Assume Symmetric Multicore = All Cores Identical Therefore, N/R Cores per Chip — (N/R)*R = N For an N = 16 BCE Chip: Sixteen 1-BCE coresFour 4-BCE cores One 16-BCE core.")
27
Performance of Symmetric Multicore Chips Serial Fraction 1-F uses 1 core at rate Perf(R) Serial time = (1 – F) / Perf(R) Parallel Fraction uses N/R cores at rate Perf(R) each Parallel time = F / (Perf(R) * (N/R)) = F*R / Perf(R)*N Therefore, w.r.t. one base core: Implications? Symmetric Speedup = 1 + 1 - F Perf(R) F * R Perf(R)*N Enhanced Cores speed Serial & Parallel
 F * R Perf(R)*N Enhanced Cores speed Serial & Parallel.")
28
Symmetric Multicore Chip, N = 16 BCEs F=0.5, Opt. Speedup S = 4 = 1/(0.5/4 + 0.5*16/(4*16)) Need to increase parallelism to make multicore optimal! (16 cores)(8 cores)(2 cores)(1 core) F=0.5 R=16, Cores=1, Speedup=4 (4 cores)
) Need to increase parallelism to make multicore optimal. (16 cores)(8 cores)(2 cores)(1 core) F=0.5 R=16, Cores=1, Speedup=4 (4 cores).")
29
Symmetric Multicore Chip, N = 16 BCEs At F=0.9, Multicore optimal, but speedup limited Need to obtain even more parallelism! F=0.5 R=16, Cores=1, Speedup=4 F=0.9, R=2, Cores=8, Speedup=6.7

30
Symmetric Multicore Chip, N = 16 BCEs F matters: Amdahl’s Law applies to multicore chips Researchers should target parallelism F first F 1, R=1, Cores=16, Speedup 16

31
Symmetric Multicore Chip, N = 16 BCEs As Moore’s Law enables N to go from 16 to 256 BCEs, More core enhancements? More cores? Or both? Recall F=0.9, R=2, Cores=8, Speedup=6.7

32
Symmetric Multicore Chip, N = 256 BCEs As Moore’s Law increases N, often need enhanced core designs Researcher should target single-core performance too F=0.9 R=28 (vs. 2) Cores=9 (vs. 8) Speedup=26.7 (vs. 6.7) CORE ENHANCEMENTS! F 1 R=1 (vs. 1) Cores=256 (vs. 16) Speedup=204 (vs. 16) MORE CORES! F=0.99 R=3 (vs. 1) Cores=85 (vs. 16) Speedup=80 (vs. 13.9) CORE ENHANCEMENTS & MORE CORES!
 Cores=9 (vs. 8) Speedup=26.7 (vs. 6.7) CORE ENHANCEMENTS. F 1 R=1 (vs. 1) Cores=256 (vs. 16) Speedup=204 (vs. 16) MORE CORES. F=0.99 R=3 (vs. 1) Cores=85 (vs. 16) Speedup=80 (vs. 13.9) CORE ENHANCEMENTS & MORE CORES!.")
33
Outline Recall Amdahl’s Law A Model of Multicore Hardware Symmetric Multicore Chips Asymmetric Multicore Chips Dynamic Multicore Chips Caveats & Wrap Up

34
Asymmetric (Heterogeneous) Multicore Chips Symmetric Multicore Required All Cores Equal Why Not Enhance Some (But Not All) Cores? For Amdahl’s Simple Software Assumptions –One Enhanced Core –Others are Base Cores How? – –Model ignores design cost of asymmetric design How does this effect our hardware model?

35
How Many Cores per Asymmetric Chip? Each Chip Bounded to N BCEs (for all cores) One R-BCE Core leaves N-R BCEs Use N-R BCEs for N-R Base Cores Therefore, 1 + N - R Cores per Chip For an N = 16 BCE Chip: Symmetric: Four 4-BCE cores Asymmetric: One 4-BCE core & Twelve 1-BCE base cores
 One R-BCE Core leaves N-R BCEs Use N-R BCEs for N-R Base Cores Therefore, 1 + N - R Cores per Chip For an N = 16 BCE Chip: Symmetric: Four 4-BCE cores Asymmetric: One 4-BCE core & Twelve 1-BCE base cores.")
36
Performance of Asymmetric Multicore Chips Serial Fraction 1-F same, so time = (1 – F) / Perf(R) Parallel Fraction F –One core at rate Perf(R) –N-R cores at rate 1 –Parallel time = F / (Perf(R) + N - R) Therefore, w.r.t. one base core: Asymmetric Speedup = 1 + 1 - F Perf(R) F Perf(R) + N - R
 F Perf(R) + N - R.")
37
Asymmetric Multicore Chip, N = 256 BCEs Number of Cores = 1 (Enhanced) + 256 – R (Base) How do Asymmetric & Symmetric speedups compare? (256 cores)(253 cores)(193 cores)(1 core) (241 cores)
(253 cores)(193 cores)(1 core) (241 cores).")
38
Recall Symmetric Multicore Chip, N = 256 BCEs Recall F=0.9, R=28, Cores=9, Speedup=26.7

39
Asymmetric Multicore Chip, N = 256 BCEs Asymmetric offers greater speedups potential than Symmetric As Moore’s Law increases N, Asymmetric gets better Some researchers should target developing asymmetric multicores F=0.9 R=118 (vs. 28) Cores= 139 (vs. 9) Speedup=65.6 (vs. 26.7) F=0.99 R=41 (vs. 3) Cores=216 (vs. 85) Speedup=166 (vs. 80)
 Cores= 139 (vs. 9) Speedup=65.6 (vs. 26.7) F=0.99 R=41 (vs. 3) Cores=216 (vs. 85) Speedup=166 (vs. 80).")
40
Outline Recall Amdahl’s Law A Model of Multicore Hardware Symmetric Multicore Chips Asymmetric Multicore Chips Dynamic Multicore Chips Caveats & Wrap Up

41
Dynamic Multicore Chips Why NOT Have Your Cake and Eat It Too? N Base Cores for Best Parallel Performance Harness R Cores Together for Serial Performance How? DYNAMICALLY Harness Cores Together – parallel mode sequential mode How would one model this chip?

42
Performance of Dynamic Multicore Chips N Base Cores Where R Can Be Harnessed Serial Fraction 1-F uses R BCEs at rate Perf(R) Serial time = (1 – F) / Perf(R) Parallel Fraction F uses N base cores at rate 1 each Parallel time = F / N Therefore, w.r.t. one base core: Dynamic Speedup = 1 + 1 - F Perf(R) F N
 F N.")
43
Recall Asymmetric Multicore Chip, N = 256 BCEs What happens with a dynamic chip? Recall F=0.99 R=41 Cores=216 Speedup=166

44
Dynamic Multicore Chip, N = 256 BCEs Dynamic offers greater speedup potential than Asymmetric Researchers should target dynamically harnessing cores F=0.99 R=256 (vs. 41) Cores=256 (vs. 216) Speedup=223 (vs. 166) Note: #Cores always N=256
 Cores=256 (vs. 216) Speedup=223 (vs. 166) Note: #Cores always N=256.")
45
Outline Recall Amdahl’s Law A Model of Multicore Hardware Symmetric Multicore Chips Asymmetric Multicore Chips Dynamic Multicore Chips Caveats & Wrap Up

46
Three Multicore Amdahl’s Law Symmetric Speedup = 1 + 1 - F Perf(R) F * R Perf(R)*N Asymmetric Speedup = 1 + 1 - F Perf(R) F Perf(R) + N - R Dynamic Speedup = 1 + 1 - F Perf(R) F N N/R Enhanced Cores Parallel Section N Base Cores 1 Enhanced & N-R Base Cores Sequential Section 1 Enhanced Core
 F * R Perf(R)*N Asymmetric Speedup = F Perf(R) F Perf(R) + N - R Dynamic Speedup = F Perf(R) F N N/R Enhanced Cores Parallel Section N Base Cores 1 Enhanced & N-R Base Cores Sequential Section 1 Enhanced Core")
47
Software Model Charges 1 of 2 Serial fraction not totally serial Can extend software model to tree algorithms, etc. Parallel fraction not totally parallel Can extend for varying or bounded parallelism Serial/Parallel fraction may change Can extend for Weak Scaling [Gustafson, CACM’88] Run larger, more parallel problem in constant time

48
Software Model Charges 2 of 2 Synchronization, communication, scheduling effects? Can extend for overheads and imbalance Software challenges for asymmetric multicore worse Can extend for asymmetric scheduling, etc. Software challenges for dynamic multicore greater Can extend to model overheads to facilitate

49
Hardware Model Charges Naïve to consider total resources for cores fixed Can extend hardware model to how core changes effect ‘The Rest’ Naïve to bound Cores by one resource (esp. area) Can extend for Pareto optimal mix of area, power, complexity, reliability, … Naïve to ignore challenges due to off-chip bandwidth limits & benefits of last-level caching Can extend for modeling these Naïve to use performance = square root of resources Can extend as equations can use any function
 Can extend for Pareto optimal mix of area, power, complexity, reliability, … Naïve to ignore challenges due to off-chip bandwidth limits & benefits of last-level caching Can extend for modeling these Naïve to use performance = square root of resources Can extend as equations can use any function.")
50
Just because the model is simple Does NOT mean the conclusions are wrong Prediction –While the truth is more complex –These basic observations will hold

51
Dynamic Multicore Chip, N = 1024 BCEs F 1 R 1024 Cores 1024 Speedup 1024! NOT Possible Today NOT Possible EVER Unless We Dream & Act

52
Summary so far: A Corollary to Amdahl’s Law Developed Simple Model of Multicore Hardware –Complements Amdahl’s software model –Fixed chip resources for cores –Core performance improves sub-linearly with resources Show Need For Research To –Increase parallelism (Are you surprised?) –Increase core performance (especially for larger chips) –Refine asymmetric design (e.g., one core enhanced) –Refine dynamically harnessing cores for serial performance
 –Increase core performance (especially for larger chips) –Refine asymmetric design (e.g., one core enhanced) –Refine dynamically harnessing cores for serial performance")
54
What about clusters / clouds / massively distributed platforms?

55
Amdahl’s Law – for multi-processor/distributed Begins with Simple Software Assumption (Limit Arg.) –Fraction F of execution time perfectly parallelizable –No Overhead for –Scheduling –Synchronization –Communication, etc. –Fraction 1 – F Completely Serial Amdahl’s Speedup = 1 + 1 - F 1 F N

56
Clusters / Distributed systems

57
This class Weekly schedule (tentative)
")
58
Course Organization/Syllabus/etc.

59
Administravia: Course structure Paper discussion ( most classes ) & lectures Student projects –Aim high! Have fun! It’s a class project, not your PhD! –Teams of up to 3 students –Project presentations at the end of the term

60
Administravia: Grading Paper reviews:35% Class participation 10% Discussion leading: 10% Project: 45%

61
Administravia:Paper Reviewing (1) Goals: –Think of what you read –Expand your knowledge beyond the papers that are assigned –Get used to writing paper reviews Reviews due by midnight the day before the class Be professional in your writing Have an eye on the writing style: –Clarity –Beware of traps: learn to use them in writing and detect them in reading –Detect (and stay away from) trivial claims. E.g., 1 st sentence in the Introduction: “The tremendous/unprecedented/phenomenal growth/scale/ubiquity of the Internet…”

62
Administravia: Paper Reviewing (2) Follow the form provided when relevant. State the main contribution of the paper Critique the main contribution: Rate the significance of the paper on a scale of 5 (breakthrough), 4 (significant contribution), 3 (modest contribution), 2 (incremental contribution), 1 (no contribution or negative contribution). Explain your rating in a sentence or two. Rate how convincing the methodology is. Do the claims and conclusions follow from the experiments? Are the assumptions realistic? Are the experiments well designed? Are there different experiments that would be more convincing? Are there other alternatives the authors should have considered? (And, of course, is the paper free of methodological errors?)
, 4 (significant contribution), 3 (modest contribution), 2 (incremental contribution), 1 (no contribution or negative contribution). Explain your rating in a sentence or two. Rate how convincing the methodology is. Do the claims and conclusions follow from the experiments. Are the assumptions realistic. Are the experiments well designed. Are there different experiments that would be more convincing. Are there other alternatives the authors should have considered. (And, of course, is the paper free of methodological errors ).")
63
Administravia: Paper Reviewing (3) What is the most important limitation of the approach? What are the three strongest and/or most interesting ideas in the paper? What are the three most striking weaknesses in the paper? Name three questions that you would like to ask the authors. Detail an interesting extension to the work not mentioned in the future work section. Optional comments on the paper that you’d like to see discussed in class.

64
Administravia: Discussion leading Come prepared! –Prepare discussion outline –Prepare questions: “What if”s Unclear aspects of the solution proposed … –Similar ideas in different contexts –Initiate short brainstorming sessions Leaders do NOT need to submit paper reviews Main goals: –Keep discussion flowing –Keep discussion relevant –Engage everybody (I’ll have an eye on this, too)
.")
65
Administravia: Projects Combine with your research if relevant to the class Get approval from all instructors if you overlap final projects: –Don’t sell the same piece of work twice –You can get more than twice as many results with less than twice as much work Aim high! –Put one extra month and get a publication out of it –It is doable! Try ideas that you postponed out of fear: it’s just a class, not your PhD.

66
Administravia: Project deadlines (tentative) 2 nd week – 3 slides idea presentation: “What is the research question you aim to answer” 4 th week: 2-page project proposal 6 th week: 3-page related work survey –Know relevant work in your problem area –If implementation project, list tools, similar projects –Expand proposal 8 th week: 4-page Midterm project due –Have a clear image of what’s possible/doable –Report preliminary results [see schedule] In-class project presentation –Demo, if appropriate Last week of exam session: –10-page write-up
![Administravia: Project deadlines (tentative) 2 nd week – 3 slides idea presentation: What is the research question you aim to answer 4 th week: 2-page project proposal 6 th week: 3-page related work survey –Know relevant work in your problem area –If implementation project, list tools, similar projects –Expand proposal 8 th week: 4-page Midterm project due –Have a clear image of what’s possible/doable –Report preliminary results [see schedule] In-class project presentation –Demo, if appropriate Last week of exam session: –10-page write-up](http://images.slideplayer.com/24/7553408/slides/slide_66.jpg "Administravia: Project deadlines (tentative) 2 nd week – 3 slides idea presentation: What is the research question you aim to answer 4 th week: 2-page project proposal 6 th week: 3-page related work survey –Know relevant work in your problem area –If implementation project, list tools, similar projects –Expand proposal 8 th week: 4-page Midterm project due –Have a clear image of what’s possible/doable –Report preliminary results [see schedule] In-class project presentation –Demo, if appropriate Last week of exam session: –10-page write-up")
67
Next Class (Mon, 19/01) Note room change: KAIS Discussion of –Project ideas –Papers To do: Subscribe to mailing list Volunteers for discussion leaders for class next week
 Note room change: KAIS Discussion of –Project ideas –Papers To do: Subscribe to mailing list Volunteers for discussion leaders for class next week")
68
Questions?

69
Backup Slides

70
Cost-Effective Parallel Computing Isn’t Speedup(P) < P inefficient? (P = processors) If only throughput matters, use P computers instead? But much of a computer’s cost is NOT in the processor [Wood & Hill, IEEE Computer 2/95] Let Costup(P) = Cost(P)/Cost(1) Parallel computing cost-effective: Speedup(P) > Costup(P) E.g. for SGI PowerChallenge w/ 500MB: Costup(32) = 8.6
 If only throughput matters, use P computers instead. But much of a computer’s cost is NOT in the processor [Wood & Hill, IEEE Computer 2/95] Let Costup(P) = Cost(P)/Cost(1) Parallel computing cost-effective: Speedup(P) > Costup(P) E.g. for SGI PowerChallenge w/ 500MB: Costup(32) = 8.6.")
71
Symmetric Multicore Chip, N = 16 BCEs

72
Symmetric Multicore Chip, N = 256 BCEs

73
Symmetric Multicore Chip, N = 1024 BCEs

74
Asymmetric Multicore Chip, N = 16 BCEs

75
Asymmetric Multicore Chip, N = 256 BCEs

76
Asymmetric Multicore Chip, N = 1024 BCEs

77
Dynamic Multicore Chip, N = 16 BCEs

78
Dynamic Multicore Chip, N = 256 BCEs

79
Dynamic Multicore Chip, N = 1024 BCEs

Similar presentations

















 Autonomic Computing (Building Self* Systems) Matei Ripeanu matei at ece.ubc.ca.>")



 Access through.>")