Download presentation
Presentation is loading. Please wait.

1
PPAL 6200 Research Methods and Info Systems Class 3: Jan 17-18, 2012

2
Class Outline Some Key Terms and Thinking about “measurement” Describing Data “Distributions” Break Describing Data with Statistics Break A Very Special Distribution: The Normal Distribution

3
Some Key Concepts unless noted source is Moore –Data Numbers with a context (xxiv). The context including how data is collected can alter results. –Variable An empirical property that can take on two or more values (Frankfort-Nachmias & Nachmias 1996:50) Don’t get suckered in by small and rapid changes, look at the big picture (xxvii) –Case An individual, event or other thing for which we have data –Measurement The assignment of numbers to objects, events or variables according to rules (ibid: 156-157)
 Don’t get suckered in by small and rapid changes, look at the big picture (xxvii) –Case An individual, event or other thing for which we have data –Measurement The assignment of numbers to objects, events or variables according to rules (ibid: ).")
4
–Levels of Measurement Nominal, Ordinal, Interval, Ratio –Validity Are you measuring what you thought you are measuring? –Reliability Are you measuring it accurately? –Spuriousness Is there something else involved? Beware the lurking variable (xxvii) –Statistics The science of learning from data (xxiv)
 –Statistics The science of learning from data (xxiv).")
5
The Book Title Says It All… This is a class in the “basic practice of statistics” with a little bit of practical advice thrown in regarding management of information systems Inside the front cover of the book is a wonderful set of flow through figures that show how one can go about statistical thinking in a disciplined manner and three four step plans to guide your work

6
Describing Data Distributions with Graphs As the introductory sections of the book noted, you really cannot go wrong to begin your work by visualizing the individual variables that comprise your data (and on occasion plotting them against another variable such as time). The distribution tells you what values a variable takes and how often it does so

7
Ways we can Visualize and Explore Data Exploratory analysis is not meant to allow us to reach any deep conclusions it is meant to help us better understand the data set and the relationships within it We want to look both for an overall pattern (consistencies) and deviation from it (often called outliers) Tables –Tables are effective tools for visualizing data, provided that we do not have too many variables, nor too many cases At a certain point we need to graphically depict our data to make it understandable as a snapshot
 and deviation from it (often called outliers) Tables –Tables are effective tools for visualizing data, provided that we do not have too many variables, nor too many cases At a certain point we need to graphically depict our data to make it understandable as a snapshot")
8
Which Graph? The graphic depictions we employ are dependent on: –The type of data we have Level of Measurement Whether Stationary or Chronological

9
Some Common Graphs Pie Chart (good for showing percentages when few categories of a nominal or ordinal variable)
")
10
Percentage of Students Picking a Given Major

11
Bar Charts are equally useful for nominal and ordinal variables but have the benefit of allowing more flexibility

12
Foreign Born Population of US States by Percentage

13
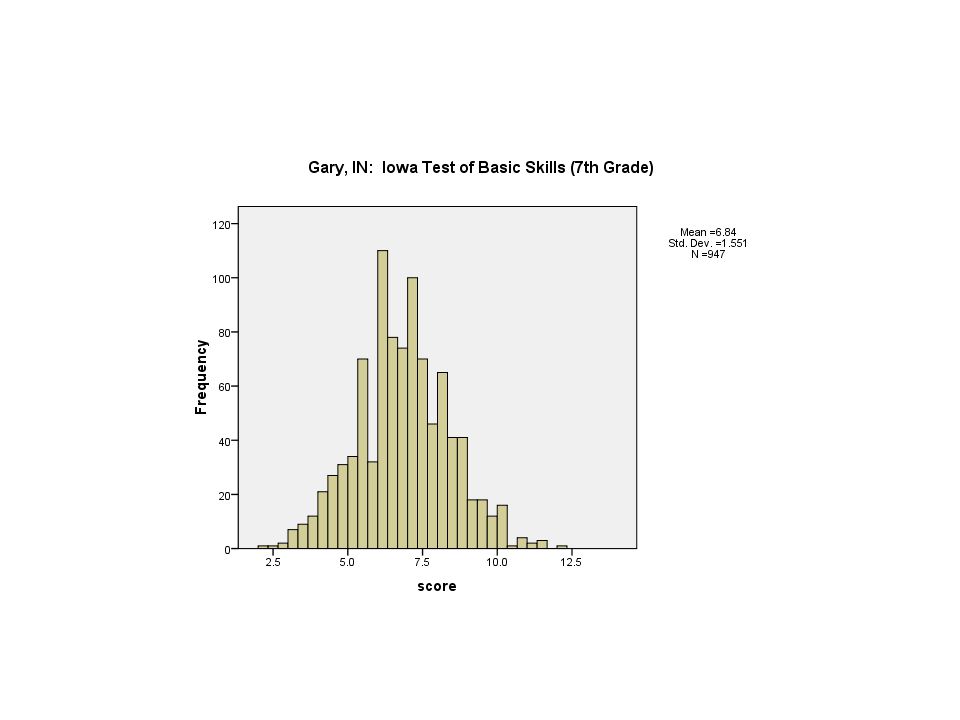
Histograms Histograms can be confusing as they look like Bar Graphs sometimes. In fact you can make them by carefully specifying a Bar Graph. However they are really quite different. They are meant for use with Interval and Ratio data where there is a lot of variability among cases because there are so many possible values for the data

14
Therefore we have to “group the data” to a certain extent to allow us to represent it What a histogram shows is the percentage of cases that have a score within the groups represented by the bars

16
You will notice that this graph looks a bit different from the one in the book. This is because the scaling that my software used is a bit different from that used by the person who did the examples in the book.

18
This brings up a good point Be careful how you manipulate data as you will see in the next section of the talk. these to graphs portray the same information but one will give us a more interesting result.

19
Describing a Distribution Once we get to developing histograms we can start to evaluate the shape of our data in a number of interesting ways (Shape, Centre, Spread) –What is the shape of the plot? Is it single peaked or multi-peaked? –Where is the peak? Is it at the centre or off-centre (skewed)? When the tail of a distribution heads off to one side unevenly we say it is skewed to that side (this is confusing) –What about outliers? Any unusually high or low scores?
. When the tail of a distribution heads off to one side unevenly we say it is skewed to that side (this is confusing) –What about outliers. Any unusually high or low scores .")
20
As you can see below: Regrouping our Data makes one figure more symmetrical

21
A stemplot is not so elegant Granted it is not so elegant but it does allow us to figure out what is happening inside of those bars….

24
Thinking about these Graphs When we look at these graphs we have to keep in mind the questions we have started –Shape –Centre (other than time-series) –Outliers
 –Outliers")
25
Remember… I have posted some tips on how to use Excel to make graphs on the course website and you can also find advice in the technical manuals you will find there as well.

26
Using Descriptive Statistics to Explore your Data We are continuing our exploration of data. In the last chapter we graphically depicted data Now we are going to look at how we can describe data using “summary” statistics We will look at statistics that provide measures of central tendency We will also look at statistics that provide measures of dispersion

27
Sometimes Statistics are So Simple… Sometimes statistics are so simple we have to do something to make them look fancier than they are. Enter “The Mean”. The mean simply means taking the average of something. You all know how to do this. You add up the group, then you divide it by the number of items in the group.

28
But just to make sure you know I know what I am doing I have a formula

29
We may talk about these formulas but… Don’t worry, we may talk about the formulas that mathematically describe statistics so you can get a better understanding of how they work. I might also hand calculate a few to demonstrate this But no one today hand calculates real data Neither should you that is why we have software

30
The Median The Median is the mid point of a distribution. Half the observations have values less than the median, half have values more The formula looks like this Note the formula gives the location of the median (the observation which has a value equal to the median) not its value
 not its value.")
31
Here is where Stem & Leaf Graphs can come in handy (N=20)
")
32
Mean and Median which one? In general the Mean is more susceptible to distortion by –abnormally large cases, in the language of the book a distribution skewed to the right –or abnormally small cases, in the language of the book a distribution skewed to the left. For example, one Bill Gates among a thousand people will seriously distort the “Mean” income of this sample. However, it will have little or no impact on the “Median” Income

33
Level of Measure Matters Also You cannot take the mean of a categorical variable (one measured at the nominal or ordinal level). You can however calculate the median of a variable measured at the ordinal level. This is a good point to stop and remind you about the stupidity of machines. Unless the variables are tagged in the data set as to level of measure, your computer really won’t care and will happily chug along calculating even meaningless statistics such as the mean of your categorical variables.

34
One more The Mode is the measure of central tendency for nominal data. It is simply the category with the largest number of cases.

35
If all we knew was how well the data clumped together… Even though the Median is less susceptible to distortion by an abnormally large or small case, it can still provide a very weak description of your data if the observations are widely dispersed. This is why we are often interested in the Quartiles

36
Just like the Median only smaller Quartiles are just like the Median only on a smaller scale. Instead of defining the mid point of the distribution they define the break-point between: –The first quarter and the second quarter –The break between the second quarter and the third quarter (which is the Median by the way) –The break between the third quarter and the fourth quarter
 –The break between the third quarter and the fourth quarter.")
37
The Five-Number Summary Moore is very big on the use of the five- number summary to summarily describe data. Minimum value Q1 M Q3 Maximum value

38
You can graphically depict this with a box plot Fortunately all the computer programs we are employing can easily generate both the numerical summary and the accompanying box plots SPSS can generate all this and more using its “Frequencies” and “Explore” commands. Excel does the job just as nicely.

39
Here is an example of an SPSS Box plot for before tax income for men and women in Ontario from the Survey of Household Spending

40
Notice on the previous slide how the distance from the first quartile to the median and then to the third quartile is not necessarily symmetrical and then that the whiskers on the box plot are also not symmetrical. This is an indication of skew Unlike the example in the book my whiskers indicate not max and min value but percentiles,

41
Here is the five number summary for Men and Women

42
Spotting outliers Obviously our box plots provide an excellent way to spot outliers. A statistic that can also help is the “interquartile range”. This is just the range between quartile one and three. When an observation lies 1 1/2 times the Interquartile range above quartile three or below quartile 1, it is often considered to be an outlier.

43
While I used ratio level data… While I used ratio level data for my example of the five-number summary, it should be noted that there is nothing here (quartiles, Median, maximum, minimum value) that would not work with data measured at the interval or ordinal level
 that would not work with data measured at the interval or ordinal level")
44
Range Along with quartiles (which works when data is at least measured at the ordinal level) we must also remember to look at “Range” which is the only measure of dispersion that works at the nominal level.
 we must also remember to look at Range which is the only measure of dispersion that works at the nominal level.")
45
Standard Deviation The best way to describe Standard Deviation (notation S) is that it is the square root of Variance (notation S 2 ) So why do you need variance? A bit of math if you look at the formula in your book.

46
The Formula for S 2 Variance is the sum of the squared distances of each observation from the mean over N-1 (N-1 being the degree of freedom).
.")
47
The Formula for S 2 involves a squaring We have to square these distances as, otherwise -- in a symmetrical distribution -- they would cross cancel and there would be no variance. The problem with variance is all that squaring produces numbers that are very large and not too intuitive to read on their own (though you will see later that variance is an important tool and even a building block for other things).
..")
48
Taking the square root produces a much more usable number (S). Quite simply, when you know and S You can go up and down a list of numbers and figure out which list is more concentrated about its mean and which is more diffuse

49
If you want a quick example FrequencyValue 10 11 12 13 14 15 16 17 18 19 110 N= 11∑ = 55 Mean = 5S 2 =11 S= 3.3 FrequencyValue 10 12 14 16 18 110 112 114 116 118 120 N= 11∑ = 110 Mean = 10S 2 = 44 S= 6.6

50
But once again, keep in mind… If the mean is susceptible to distortion from extreme variables, S is doubly so due to all those squarings Source for Graphics: Moore 2009

51
Normal Distributions When Exploring Data –Always start by plotting your individual variables –Look for overall patterns (shape, centre, spread) and for deviations such as outliers –Calculate appropriate summary statistics to identify the centre and spread Source for Graphics: Moore 2009
 and for deviations such as outliers –Calculate appropriate summary statistics to identify the centre and spread Source for Graphics: Moore 2009")
52
Density Curves and Normality Sometimes data takes on a recognizable shape Density Curves are those that: –Are always on or above the (x) axis –Have exactly an area of 1 under the curve Which means any portion of the area can be expressed as a percentage (eg. 0.68). Density curves come in all shapes and sizes and can be centred or skewed. Source for Graphics: Moore 2009
. Density curves come in all shapes and sizes and can be centred or skewed. Source for Graphics: Moore")
54
Describing a density curve Our measures of central tendency and dispersion work just as well on density curves as on actual observations Although these are theoretical constructions we can describe them like real data Source for Graphics: Moore 2009

55
A special set of curves Normal curves are a subset of density curves all are –Symmetrical and single peaked –It is completed described by giving its mean μ and standard deviation Ố –The mean is at the centre of the distribution and is the same as the median –Changing μ without changing Ố moves the graph but does not alter it –The larger Ố is the more spread out the curve is.

56
The Normal Curve and the 68-95-99.7 rule Source for Graphics: Moore 2009

57
The abbreviation of a Normal Distribution In the rest of the book the parameters of a normal distribution are summarized by the notation

58
Why is the normal distribution so important? It is a good description of the distribution of some important real world data It is a good approximation of many chance outcomes Statistical tests with distributions based on normality work just as well with many non- normal but roughly symmetrical distributions. In many statistical inference procedures there is an assumption of normality we test against. If the results we see could be expected to occur, then there is little reason to believe we have found a meaningful result

59
This is handy One reason normality is handy is because it provides us a way to standardize variables so that we can in fact compare apples and oranges (or at least variables measured on two different scales). Suppose you are interested in how educating girls (measured in percent enrolled in schooling) and international trade (measured in dollars) impact economic development How can you clearly state the impact of years of schooling and dollars in the same equation?
 and international trade (measured in dollars) impact economic development How can you clearly state the impact of years of schooling and dollars in the same equation .")
60
What you can do is convert each set of scores so that each observation is expressed as a measure of how far it falls away (either positively or negatively) from the mean for the variable in question. This is called a Z score.

61
And here is the Z formula

62
As a result the two variables will now be on a common scale and you can compare the impact of schooling for girls and international trade on economic development.

63
Finally, as the example in the book shows If you believe your observations are normally distributed and you know the Mean and Standard Deviation, you can work out proportions In the case they show in the book the question was what proportion of first year university students were likely to be eligible to play sports, given the league requirement that they score 820 on the SAT before beginning their first year of university.

64
If we know the total area under a normal curve is = 1 and we subtract the area to the left of 820 we will have an answer. To work out the area you need to: guess, use a calculator or software or the applet on the book website, or convert the information to Z scores and use Table A. Source for Graphics: Moore 2009

65
Guestimation Distribution is normal; Mean = 1026; Std.D.= 209. Therefore the value = 1 st Std. below mean is 817 which is pretty close to 820 (the score you need so as to be eligible) Therefore we have 68% + the rest of the right side = 68 + (100-68)/2 = 68 + 16 = 84% Approximately 84% of students qualify Source for Graphics: Moore 2009
 Therefore we have 68% + the rest of the right side = 68 + (100-68)/2 = = 84% Approximately 84% of students qualify Source for Graphics: Moore")
66
Using software or the applet To do the applet we will go to the website for the book http://courses.bfwpub.com/bps5e.php

67
Using Excel as a software example To use Excel you would go to the stats plugin and select Probability Calculations Normal Distribution

68
Using the Z scores and tables Start by calculating the Z score that would correspond to a score of 820 Therefore we need to find the area under the normal curve which is equal to -0.99

69
To use the table you first find the row that corresponds to the first digit -0.9 then draw your finger across until you find the column for the second in this case “.09) Therefore the answer is.1611
 Therefore the answer is.1611")
70
So now that we have found the area under the normal curve when expressed as Z scores that corresponds to a score of 820 it is the same mathematical problem as before 1 – 0.1611≈ 84% Therefore about 84% of students would qualify to play sports

71
Have a fun week Nikolai Bogdanov-Belsky Counting in their heads (1895) Posted on line by Tamir Khason Khason.net
 Posted on line by Tamir Khason Khason.net")
Similar presentations









 Bani Mallick1 Lecture 2 Stat 651. Copyright (c) Bani Mallick2 Topics in Lecture #2 Population and sample parameters More on populations.>")









 techniques requires gaining.>")



