Download presentation
Presentation is loading. Please wait.

1
Facilitating Knowledge Management Infrastructure with XML

2
Knowledge is a critical asset in our information-based economy. When used effectively, it adds significant value to an organization. Every organization has a wealth of intellectual capital and although it is of the highest value, this corporate asset is also the most under- utilized.

3
Knowledge Management is the set of practices and technologies that leverages value-added information, which is mission-critical for organizations. Information is not knowledge until people add value to it, transforming raw data into competitive business advantages. Accessing and sharing information are the beginning of the knowledge transformation process.

4
However, it takes more than an Intranet, a repository, or some search and document management functionality. It takes a complete knowledge management system that addresses all elements of the knowledge process: – Discovery People capable of accessing information easily, – Organization Processes used to manage and maintain information effectively and – Development Tools that allow people to take action and work together effortlessly.

5
XML (eXtensible Mark-up Language) is a tool used to help individuals do their jobs better by automating knowledge access. XML has revolutionized the way data is being exchanged over the Web. Knowledge Management (KM) applications increasingly depend on XML.
 applications increasingly depend on XML..")
6
1. Introduction Knowledge is the most important factor in the long-term success of both an individual and an organization. The only source of competitive advantage in the future will be the knowledge that an organization contains and an organization’s ability to learn faster than the competition. With knowledge taking on increased importance, it makes sense that there is an opportunity to create competitive advantage by effectively managing its storage and use.

7
An effective knowledge management Infrastructure creates competitive advantage by bringing appropriate knowledge to the point of action during the moment of need [3]. Employee turnover is also reduced because a large portion of the knowledge and expertise acquired by the employee is captured in the knowledge base.
![An effective knowledge management Infrastructure creates competitive advantage by bringing appropriate knowledge to the point of action during the moment of need [3].](http://images.slideplayer.com/33/7548828/slides/slide_7.jpg "Employee turnover is also reduced because a large portion of the knowledge and expertise acquired by the employee is captured in the knowledge base..")
8
Those companies that are using knowledge management practices today have identified the following key benefits: – Improved decision-making – Increased responsiveness – Improved efficiency of people and operations – Improved innovation – Improved products/services – Greater flexibility XML is a set of rules for defining data structures.

9
Key elements in a document can be categorized according to meaning, rather than simply how they are presented in a particular browser. Instead of a search engine selecting a document by the metatags listed in its header, a search engine can scan through the entire document for the XML tags that identify individual pieces of text and image.

10
Defining objects that tag or identify details about data is increasingly popular with companies trying to leverage both the structured data in relational databases and the unstructured data found on the Internet and in other sources. KM is trying to bring all this data together, and XML categorizes it.

11
A successful knowledge management architecture must be: – Available (if knowledge exists, it is available for retrieval) – Accurate in retrieval (if available, knowledge is retrieved) – Effective (knowledge retrieved is useful and correct) – Accessible (knowledge is available during the time of need)
 – Accurate in retrieval (if available, knowledge is retrieved) – Effective (knowledge retrieved is useful and correct) – Accessible (knowledge is available during the time of need)")
12
2. Knowledge Management Infrastructure 2.1 Why Knowledge Management? When firms need to know what they know and must use that knowledge effectively, the size and geographic dispersion of many of them make it especially difficult to locate existing knowledge and get it to where it is needed. In a small, localized company, a manager probably knows who has experience in a particular aspect of the business and can walk across the hall and talk to them.

13
The mere existence of knowledge somewhere in the organization is of little benefit; it becomes a corporate asset only if it is accessible. Formalizing networking groups and formulating knowledge maps in and of themselves, however, is not sufficient. Companies need to foster a knowledge culture within their organization.

14
Employees need to be rewarded for sharing their knowledge with others [4]. Respect and trust in each other's knowledge is paramount to successful knowledge transfer and application. Open-minded discussions and a willingness to try new methods need to be encouraged - by their very nature, people resist any innovation that may require them to abandon their signature skills in favor of new ones.
![Employees need to be rewarded for sharing their knowledge with others [4].](http://images.slideplayer.com/33/7548828/slides/slide_14.jpg "Respect and trust in each other s knowledge is paramount to successful knowledge transfer and application. Open-minded discussions and a willingness to try new methods need to be encouraged - by their very nature, people resist any innovation that may require them to abandon their signature skills in favor of new ones..")
15
Knowledge is a corporate asset, and an infrastructure is required to store it, maintain it, archive it, update it, discard it, and present it to the right people in the right format at the right time. Most companies have tapped into the information age with databases, data warehouses, and internet search engines, and are primed to add the extension technologies to bring them into the knowledge age.

16
With a few modern methods and tools and a shift in culture, an infrastructure can be created to manage and preserve Intellectual Capital.

17
2.2 KM Infrastructure If the knowledge an employee needs exists, it should be available. This requirement can be split into two viewpoints: – knowledge that exists external to the organization and – knowledge that exists internal to the organization [4]:

18
External knowledge is an area that falls under the purview of traditional library services. Successful knowledge management infrastructure must leverage these services and their lessons learned. Outside knowledge resources must be evaluated and tapped.

19
Regardless of how external sources are tapped, the vision is to have an easy-to-use search engine that queries all external knowledge sources. The engine search then brings back knowledge from each in an effective, integrated fashion. Technology can help meet this vision by converting legacy information into a digital, searchable form and by providing an integrated, effective search engine.

20
One method of capturing knowledge is to make it easy to share knowledge by making it part of the infrastructure. At the source of where most knowledge is created, the corporate word processing application - replace the standard “Save” command with an applet that automatically prompts the user to see if he/she would like to add the document to the knowledge base.

21
If the employee agrees, the document is saved to both the file locations of his/her choice and the knowledge base with the click of a button. If other knowledge collection opportunities exist, such as slides, log files, or electronic mail, capture routines should be seamlessly built into the infrastructure. Knowledge must be captured at the point of creation.

22
Knowledge workers will not jump through hoops to share their knowledge unless there is a benefit to them. Creating a pervasive sharing infrastructure helps to make the process easy; but without a sharing culture, capturing knowledge will be less than successful. The usual impetus for sharing information is prestige, recognition, and the notion that the individual’s thoughts and ideas might make a difference [6].

23
At the start of a new knowledge base, employees do not want to search the knowledge base because there is very little information to obtain. If no one searches the knowledge base, the impetus for adding knowledge to the knowledge base is decreased because the perception is that no recognition will come from populating the knowledge base. To overcome this chicken-and-egg problem, the vision is to seed the knowledge base with external knowledge sources.

24
The vision for seeding the knowledge base is to create an integrated knowledge query engine that returns information from both the internal knowledge base and external knowledge sources in an easy-to-use and effective split-screen view. The same keywords or phrases used to search the knowledge base are also sent to external knowledge sources. The results are displayed in a hypertext format with a clear demarcation between the links as either internal- or external-based.

25
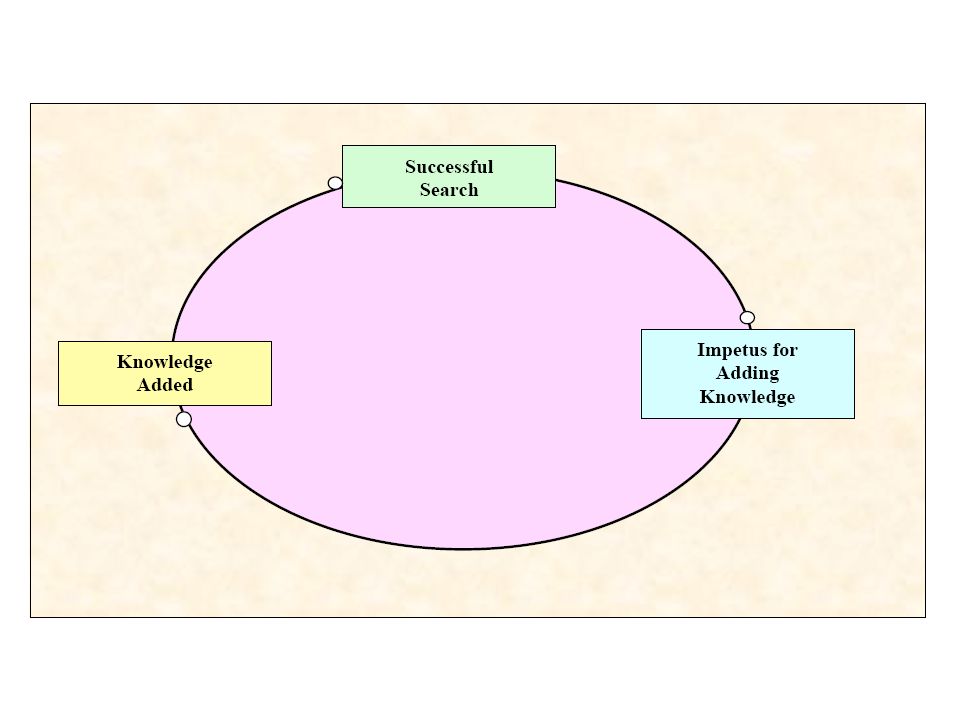
With everyone searching the internal knowledge base, a critical mass of knowledge and perception will develop to create a Virtuous Knowledge Circle [4] as shown in Fig.1. Successful searches of the knowledge base will increase the impetus for adding knowledge. The more knowledge in the knowledge base, the higher the chance for a successful search.
![With everyone searching the internal knowledge base, a critical mass of knowledge and perception will develop to create a Virtuous Knowledge Circle [4] as shown in Fig.1.](http://images.slideplayer.com/33/7548828/slides/slide_25.jpg "Successful searches of the knowledge base will increase the impetus for adding knowledge. The more knowledge in the knowledge base, the higher the chance for a successful search..")
27
After knowledge is read from the knowledge base, the employee is surveyed to determine the probable performance and spreading power of the knowledge he/she has just obtained. The survey results are used to create “metadata” about entries in the knowledge base. From this metadata, the creator of a knowledge entry can check to see how his/her entries are doing in terms of hits, performance, and spreading power.

28
A list of the most active knowledge entries in terms of hits, performance, and spreading power are also available for query from the knowledge base. Entering information into the knowledge base is then not only a way to gain recognition and prestige, but also an automatic method for receiving feedback.

29
Accurate retrieval of documents is critical to the success of any knowledge architecture. If a search for knowledge comes up consistently empty or not relevant, the user will usually look for another method to find information. The vision is to leverage traditional information retrieval techniques (e.g., keyword, relevancy rating) for searching, while adding effective metadata at both the time of knowledge deposit and the time of retrieval to improve accuracy.
 for searching, while adding effective metadata at both the time of knowledge deposit and the time of retrieval to improve accuracy..")
30
The ability to search by keyword and classification would filter out knowledge that just happens to contain the words in the query, but contain no relevance to the intended information. There would be an impetus for the knowledge creator to add the metadata information because it would increase the chance that his/her knowledge object is seen be someone who can use the information.

31
To make adding the metadata an easy process, the knowledge base will make an initial guess at the classification by examining the keywords and other information in the object. This initial guess would take the creator close to the correct classification area, making the addition of the metadata require, at most, a few mouse clicks. Fig.2 shows much of the vision just proposed.

32
An integrated search engine based on open Web technologies allows an employee to search both internal and external knowledge sources with the same query: filtering by quality, classification, performance, and power. The results are returned in a split-screen, hypertext view that provides one- click access to the knowledge.

33
Knowledge deposits to the internal knowledge base are encouraged through a pervasive knowledge infrastructure that captures knowledge at the point of creation. The quality of information in the knowledge base is ensured through a rating process based on the aggregation of opinions of those who have evaluated the object.

35
2.3 Knowledge Portals Portals are large doors or gateways to reach many other places, indicating that the portal itself is not the final destination. A Web portal is a web site, usually with little content, providing links to many other sites that can either be accessed directly by clicking on a designated part of a browser screen, or can be found by following an organized sequence of related categories.

36
A Knowledge Portal is the fundamental building block of a Knowledge Management infrastructure. It provides a robust substrate for building a learning organization by providing all the facilities of – an Information Catalog plus collaborative facilities, expertise management tools, and – a Knowledge Catalog to be used as a repository of institutional memory [4].

37
The Knowledge Catalog is a metadata store that supports multiple ways of organizing and gathering content according to the different taxonomies used in the enterprise practice communities, including an enterprise wide taxonomy when defined. A Knowledge Portal provides two distinct interfaces: – a Knowledge Producer interface, supporting the knowledge mapping needs of the knowledge worker in their job of gathering, analyzing, adding value, and sharing information and knowledge among peers, and – a Knowledge Consumer interface.

38
This interface facilitates the communication of the produce of the knowledge workers and its dissemination through the enterprise to the right people, at the right time, to improve their decision-making.

39
3. Ingredients of XML XML is a markup language like HTML. XML has been designed to describe data and unlike HTML, XML tags are not predefined in XML. XML is self-describing which uses a Document Type Definition (DTD) to formally describe the data.
 to formally describe the data..")
40
XML is a universal language for data on the Web that lets developers deliver content from a wide variety of applications to the desktop. XML promises to standardize the way information is searched for, exchanged, adaptively presented, and personalized.

41
Content authors are freed from defining the style of the XML document as the content has been separated out from the presentation of the document [11]. Extensible Stylesheet language (XSL) is useful in displaying the information in many ways e.g., in the form of a table, a bulleted list, a pie chart, or even in a different language.
![Content authors are freed from defining the style of the XML document as the content has been separated out from the presentation of the document [11].](http://images.slideplayer.com/33/7548828/slides/slide_41.jpg "Extensible Stylesheet language (XSL) is useful in displaying the information in many ways e.g., in the form of a table, a bulleted list, a pie chart, or even in a different language..")
42
3.1 XML Schema A schema is a set of predefined rules that describe a given class of XML document. A schema defines the elements that can appear within a given XML document, along with the attributes that can be associated with a given element.

43
It also defines structural information about the XML document, such as which elements are child elements of others, the sequence in which the child elements can appear, and the number of child elements. It can define whether an element is empty or can include text as well as default values for attributes. Document Type Definitions (DTDs) and XML-Data are both examples of specifications that outline how to describe XML document schemas.
 and XML-Data are both examples of specifications that outline how to describe XML document schemas..")
44
3.2 Document Type Definition (DTD) The DTD language is used to define validation rules for SGML documents. Since XML is a simplified subset of SGML, DTDs can also be used to define XML validation rules. An XML processor can use the DTD at run time to validate a given XML file against the predefined XML schema.

45
DTDs use different syntactical elements, like parenthesis, asterisks, angle brackets etc., to define what elements are required in an XML document, what elements are optional, how many occurrences of a given element are allowed, and so forth [12]. DTDs also describe the relationship between elements and how attributes relate to different elements.
![DTDs use different syntactical elements, like parenthesis, asterisks, angle brackets etc., to define what elements are required in an XML document, what elements are optional, how many occurrences of a given element are allowed, and so forth [12].](http://images.slideplayer.com/33/7548828/slides/slide_45.jpg "DTDs also describe the relationship between elements and how attributes relate to different elements..")
46
A DTD (which contains a set of rules) is a way to ensure that an XML document uses elements correctly. When an XML document is processed, it is compared to its associated DTD to be sure that it is structured correctly and all tags are used in the proper manner. XML provides an application independent way of sharing data.

47
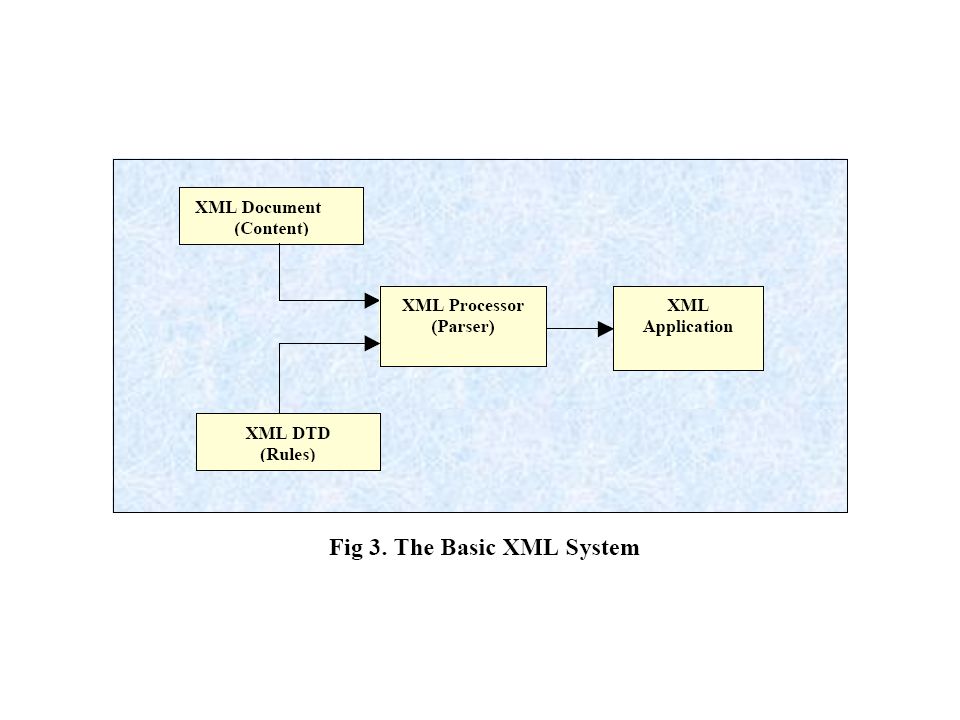
With a DTD, independent groups of people can agree to use a common DTD for interchanging data. The application can use a standard DTD to verify that data received from the outside is valid. DTD describes the structure of the XML document. The main difference between Valid and Well- Formed XML is that Valid XML requires a DTD and Well-Formed XML doesn’t [14]. Fig.3 shows the basic XML system.

49
3.3.XML- Data XML-Data is one proposed implementation of an XML schema language. XML-Data schemas are loosely referred to as XML schemas, which are quite different from DTD schemas. An XML-Data schema is a well-formed XML document.

50
The XML-Data language is based on the XML-Data DTD, which specifies the expected format for the schema definition. As XML-Data schemas are simply XML documents, any tool you use to work with XML documents can also be used to work with XML- Data schema definitions. Elements and attributes are defined in an XML- Data schema by specifying and elements, respectively.

51
These provide the definition and type of the element or attribute. An instance of an element or an attribute is declared using or tags.

52
3.4 XML API A software module capable of reading XML documents and providing access to their content and structure is referred to as an XML processor or an XML API. While developers are free to implement their own XML APIs, it is in their best interests to leverage industry-accepted standard APIs.

53
By accepting an industry standard API, a developer can write code for a given API implementation that should be capable of running under any other compliant implementation of the same API without modification [15]. There are two main API specifications that have gained popularity among developers today and are striving to become industry standards: the Document Object Model (DOM) and the Simple API for XML (SAX).
![By accepting an industry standard API, a developer can write code for a given API implementation that should be capable of running under any other compliant implementation of the same API without modification [15].](http://images.slideplayer.com/33/7548828/slides/slide_53.jpg "There are two main API specifications that have gained popularity among developers today and are striving to become industry standards: the Document Object Model (DOM) and the Simple API for XML (SAX)..")
54
3.5 Extensible Style Language (XSL) Patterns A pattern is a string, which selects a set of nodes in an XML tree. The selection is relative to the current node that the pattern is applied to. The simplest pattern is an element name; it selects all the child elements of the current node with that element name [10]. When a pattern is applied to a given node, it simply returns a list of nodes that match the given pattern.

55
3.6 Extensible Style Language (XSL) XSL Patterns help identify certain nodes within a given XML document, but it's still up to the developer to do something interesting with those matching nodes. XSL helps simplify the process of performing one of the most common XML tasks: transforming nodes from an XML format into another format. The need for this originated on the Web, as developers wanted to take their XML data and transform it into HTML for the user to view.

56
But XSL goes far beyond that. XSL is very useful for defining transformations from a given XML format to another distinct XML format. This makes interoperability much more feasible [10].

57
If someone sends you an XML document that doesn't use the exact XML vocabulary that your system expects, simply perform an XSL transformation to produce the desired vocabulary. Each template defines exactly how you wish to transform a given node from the source document to a node or some other type of data in the output document. XSL Patterns are used within a template to define which portions of the document the template applies to.

58
3.7 Extensible Linking Language (XLL) XML has been developed to overcome HTML's lack of extensibility. Besides lacking extensibility, HTML is also limited in its hyperlinking functionality.

59
Two complementary languages comprise XLL: XPointer and XLink to address these limitations. The three types of XLinks are Simple links, Extended links and Group links. An XML link is the specification of an explicit relationship between resources or portions of resources, as well as XLink-defined descriptive information.

60
The specific identification methods that locate various types of data (such as URIs, XPointers, and graphical coordinates) are outside the scope of XLink. XPointer specifies constructs for addressing the internal structures of XML documents. In particular, it provides for specific reference to elements, character strings, and other parts of XML documents, whether or not they bear an explicit ID attribute.

61
A XPointer consists of a series of location terms, each of which specifies a location, usually relative to the location specified by the prior location term [9]. Each location term has a keyword (such as id, child, ancestor, and so on) and can have arguments, such as an instance number, element type, or attribute.
![A XPointer consists of a series of location terms, each of which specifies a location, usually relative to the location specified by the prior location term [9].](http://images.slideplayer.com/33/7548828/slides/slide_61.jpg "Each location term has a keyword (such as id, child, ancestor, and so on) and can have arguments, such as an instance number, element type, or attribute..")
62
3.8 Resource Description Framework (RDF) The World Wide Web was originally built for human consumption, and although everything on it is machine-readable, this data is not machine-understandable. It is very hard to automate anything on the Web, and because of the volume of information the Web contains, it is not possible to manage it manually.

63
The solution proposed here is to use metadata to describe the data contained on the Web. Metadata is "data about data" (for example, a library catalog is metadata, since it describes publications) or specifically in the context of this specification "data describing Web resources". The distinction between "data" and "metadata" is not an absolute one; it is a distinction created primarily by a particular application, and many times the same resource will be interpreted in both ways simultaneously.
 or specifically in the context of this specification data describing Web resources . The distinction between data and metadata is not an absolute one; it is a distinction created primarily by a particular application, and many times the same resource will be interpreted in both ways simultaneously..")
64
3.9 Extensible Query Language (XQL) XQL (XML Query Language) provides a natural extension to the XSL pattern language. It builds upon the capabilities which XSL provides for identifying classes of nodes, by adding Boolean logic, filters, indexing into collections of nodes, and more. XQL is designed specifically for XML documents. It is a general-purpose query language, providing a single syntax that can be used for queries, addressing, and patterns.

65
4. Applying XML to KM Infrastructure 4.1 XML – an indispensable weapon for KM Knowledge management (KM) tools are used to capture, maintain, and exploit strategic information of an organization. This information might consist of data describing best practices followed, highly crucial marketing results such as assessment of a competitor’s market share [2]. Hence preserving the data’s context is essential when acquiring, processing, or storing the information.
 tools are used to capture, maintain, and exploit strategic information of an organization. This information might consist of data describing best practices followed, highly crucial marketing results such as assessment of a competitor’s market share [2]. Hence preserving the data’s context is essential when acquiring, processing, or storing the information..")
66
XML is used to build an index for a knowledge management repository that holds documents on all the products of a company. Each piece of content gets an XML tag that identifies the source of the content. Other pieces of information in the tag can identify who the product is sold to, which business unit within the company is responsible for the product, and on which operating systems the product runs.

67
Scheduled scans of the company's repository look for any changes that have taken place in the documents housed there. If changes are found, a new index is created. The XML-based index can be searched easily and contains the most up-to-date information on the company's products.

68
Once a community agrees to use a common DTD to publish all its XML-tagged data, writing the software to create data-management tools is far easier. XML tools exploiting code encapsulation and reuse, can then provide the standard services to make that community’s data set available to the software [2]. This approach makes the data set’s context (the data model) readily available as a standardized object model that eases the process of developing software applications.
 readily available as a standardized object model that eases the process of developing software applications..")
69
The value of XML or XQL (the Query language of XML) is realized when a company categorizes and enables the searching of documents using metadata that the product captures in an XML- compatible format. Administrators can specify custom meta attributes [5]. End users viz., publishers can then categorize documents based on attributes such as project name, author department, and other custom keyword fields.

70
Once the document is published, this XML- based document information allows for quicker and more efficient searching, saving a significant amount of time for Intranet end- users.

71
With more increasingly available Knowledge Portals, aggregating huge amounts of information from inside and outside the company – it becomes important that users should locate that information as quickly as possible. The portal strategy adopted by many knowledge management vendors thus depends on XML. XML provides the context to transform a data set into information and KM provides the tools for managing this information.

72
4.2 Context takes the Lead A clear understanding of how context turns data into information is portrayed by XML’s role in a KM infrastructure. Context refers to the identity of, and relationships between, a data set’s entities. Information exists when data and context combine to associate data with specific concepts. Information is meaningful data; data without context is meaningless.

73
Implementing a database’s schema by specifying the table structures provides the data context. Populating the database brings the data and context together to make information. Customers entering data into a Web form’s text boxes have a conceptual model of the data they are using in their minds. They associate a particular meaning to terms such as “name,” “age,” “address,” “email id,” etc., and they expect these data entities to be associated with individuals.

74
The data entry Web form acts as an interface filter to make sure that the data and context are being translated properly from the customers’ mental model to the XML schema’s data model with the help of the hypertext transfer protocol. Customers see the data as information because it is in a context they can associate with a mental data model. The database entry process preserves that context, passing the information from the mental data model to the XML schema data model [13].

75
Designers of Web forms and server database input processes must ensure that this translation is accurate so that the two models are equivalent. Data processing’s role is to control the movement of data from one context to another so that it continues to represent information. If it ever gets out of control and loses its context, the data no longer represents information, because it loses its meaning.

76
Just as information is the union of data and context, knowledge is the union of information and specific issues. Therefore, we can define knowledge management as aggregating data with context for a specific purpose.

77
4.3 DTD – the backbone of XML in KM Infrastructure The conventional approach to knowledge management keeps data in a database, relying on the database schema to provide the context. However, this approach is becoming awkward as the KM domains scale to potentially thousands of databases. Writing an IT application that uses data requires having knowledge of that particular database’s schema.

78
An application that interacts with N databases must interface with up to N different schemas. Open standard protocols such as Open Database Connectivity standardize only the connection to the databases. The programmer must still deal with each particular database’s schema [13].

79
Information transfer depends on the programmer’s ability to create a descriptive data context presentation and the user’s ability to properly interpret it. This process is extremely inefficient and error prone. Tools and definitions are the two major factors for successfully incorporating XML into a corporate KM infrastructure.

80
The Community members need to understand and properly use the part of the data model that impacts their activities. This requires creating the initial data model. The data model design needs to provide an efficient means for incorporating future developments in the KM infrastructure.

81
Data modelers produce an XML DTD, which represents this domain data model [13]. Programmers, then provide the KM tools with reusable XML parser code so that the community members can easily interact with the model. The KM tools are being used to pass information to one another or to move it between knowledge repositories.
![Data modelers produce an XML DTD, which represents this domain data model [13].](http://images.slideplayer.com/33/7548828/slides/slide_81.jpg "Programmers, then provide the KM tools with reusable XML parser code so that the community members can easily interact with the model. The KM tools are being used to pass information to one another or to move it between knowledge repositories..")
82
The KM tools have data and context together by tagging the exported data with XML syntax or by interpreting the imported-tagged data according to the already created domain DTD. Knowledge repositories store the data either as marked-up flat files or in databases with schemas that are consistent with the domain DTD. The data is never separated from its context, and the context always accurately represents the domain data model as shown in fig 4.

84
The data analysts and programmers directly involved in maintaining the DTD data model have to understand XML and DTD syntax. The programmers creating the KM tools don’t have to know XML syntax.

85
It is sufficient for them to know how to interface with the available XML parsers, which make that data model available to the software. The whole process is very similar to HTML tagging, which is the current presentation standard.

86
4.4 RDF – the XML solution to KM Resource Description Framework (RDF) as described in section 3.8 is a foundation for processing metadata. It provides interoperability between applications that exchange machine- understandable information on the Web. RDF emphasizes facilities to enable automated processing of Web resources.

87
RDF describes the Resources, Named Properties and values, which narrows down the search thus offering larger support to the KM Infrastructure. RDF helps in resource discovery to provide better search engine capabilities, in cataloging for describing the content and content relationships available at a particular Web site, page, or digital library and by intelligent software agents to facilitate knowledge sharing and exchange [7].

88
4.5 XML Namespaces – optimize “context” based “search” It is common for applications to access data from multiple sources. If XML documents are used to supply data for an application, it is likely that an element in one XML document could have the same name as an element in another, causing a conflict. For example, two XML documents could have an element named.

89
Namespaces let you eliminate duplicates by attaching a namespace prefix to uniquely qualify element names [8]. Element type names and attribute names are unstructured strings using a restricted set of characters. They are similar to identifiers in programming languages referred to as local names.
![Namespaces let you eliminate duplicates by attaching a namespace prefix to uniquely qualify element names [8].](http://images.slideplayer.com/33/7548828/slides/slide_89.jpg "Element type names and attribute names are unstructured strings using a restricted set of characters. They are similar to identifiers in programming languages referred to as local names..")
90
These are problematic in a distributed environment like the Web. The combination of a local name and a qualifying Universal Resource Indicator (URI) is known as an Universal name. The concept of Namespaces with the help of the Namespace prefix used with local names allows us to restrict the search only to that keyword which is searched for in a given context.
 is known as an Universal name. The concept of Namespaces with the help of the Namespace prefix used with local names allows us to restrict the search only to that keyword which is searched for in a given context..")
91
4.6 XLink / XPointer – “Document references” in KM Infrastructure XLink links together any number of resources, resulting in multiple targets instead of a simple one-to-one relationship as in HTML. Extended links can link to and from resources that cannot contain the links themselves. This includes such things as graphics file, sound files, read-only documents, and so on, whose coding doesn’t allow us to modify them to embed links.

92
Extended links enable the dynamic filtering, addition, and modification of links. XPointers allow us to point into XML resources in multiple ways as to make full use of the structure of the document that is identified by means of XML elements and attributes [9]. These features of XLinks and XPointers facilitate the community members of the KM Infrastructure with the right choice of documents at right time without delay and denial.

93
Case Study 1: XML applied to KM for the Pharmaceutical Industry Assuming that a company has completed recently a merger with another pharmaceutical organization, and the compatibility among the IT departments, helped to achieve smooth integration of the information systems that supported the operations of both companies.

94
However, the different departments that are starting to get consolidated are facing new challenges they did not encounter within the separate, regionally based, organizations. The sharing of information, best practices, and experiences, at different levels, is becoming more than ever a critical factor for the success of the merger.

95
Does XML facilitate Knowledge Management Infrastructure to provide a solution so as to apply it to the different departments and their disparate problems?

96
Solution to Case Study 1: The pharmaceutical industry is knowledge intensive, and therefore Knowledge Management is critical to improve R&D productivity and reduce product cycle time. To achieve these goals, the trend in drug development is to work in multidisciplinary project teams due to the multiple skill requirements.

97
The success of this approach depends on the availability of information from multiple sources, presented to the team members properly organized around the research topics, and personalized to each researcher's needs. R&D professionals need to share their findings and conclusions with a geographical disperse team. Although the discovery phase tends to be localized in centers of excellence, knowledge sharing becomes a critical success factor for clinical improvement.

98
To move quickly in a rapidly changing competitive environment, pharmaceutical companies have performed bold strategic moves, such as outsourcing elements of their R&D value chain through collaborative relationships with a widening field of players, such as – dedicated biotechnology firms, – contract research organizations, – university laboratories, and – other pharmaceutical companies.

99
This portfolio of collaborative relationships needs to be managed, which includes source selection and monitoring based on internal knowledge and efficient transfer of knowledge from the external sources to the internal team. Knowledge must also be transferred within each team, and "lessons learned" need to be shared among the teams.

100
Companies must learn from their experiences in collaborative relationships to strike better deals in the future. They must also be able to gauge their own knowledge capital when evaluating possible mergers or acquisitions.

101
The suggested Domain data Model helps to organize and categorize the “Information” obtained through these collaborative relationships with different Organizations, Laboratories etc. which is being taken care by the Data Modelers in the XML DTDs supported by RDF for the customized Knowledge Management Infrastructure defined to achieve the Industry’s pre-defined goals.

102
Case Study 2: XML applied to KM for Competitive Intelligence The senior management of a company establishes the long-term business strategies of the company, and deciding on some tactical investments to support these strategies. At the next board meeting, the following issues will be analyzed: How does the company compare to its competitors? Which companies are most active in the company's area of business?

103
What are the most promising new technologies related to the company? What is going on in related areas of research? The company CEO needs to provide actionable knowledge for executive decisions. How can XML applied to the Knowledge Management infrastructure help the CEO to address these questions?

104
Solution to Case study 2: Assume that major part of the competitive information is publicly available in the form of XML documents. Related patents, reports and web pages provide potentially useful material that is very hard to digest. A global company in the electronics industry that planned to establish manufacturing operations wanted to understand the trends discovered in the research done by the local companies to determine which areas were likely to be subsidized by the government.

105
A preliminary survey indicated that around 10000 patents were granted to the companies in the electronic industries the previous year. To read these reports and obtain meaningful conclusions in the required time frame is out of question.

106
If the reports are generated as XML documents, the company could make a keyword search using a search engine on the XML documents and draw meaningful conclusions at a faster rate as searching keywords becomes easier with context based search in XML with the support of XML namespaces.

107
Knowledge mapping is another key competitive analysis technique. A knowledge map used for competitive intelligence provides a clear and easy-to- understand view of a competitor's organization.

108
The knowledge map could be built with the DOM capability of XML, which could be series of nodes and links (XLinks and XPointers). The nodes (elements and attributes in XML documents supported by XML DOM) could be key business elements of the competitor organization, gathered from the press releases and reports available as XML documents available on the Internet.
 could be key business elements of the competitor organization, gathered from the press releases and reports available as XML documents available on the Internet..")
109
The links represent relationships among the objects representing the business elements, with each object playing a defined role in the relationship. Each object can have an associated behavior: when clicking on the hyperlink (could be either XLink or XPointer) representing a document, may open the document using a word processor, or link to the web address (URI) where the document is stored.
 representing a document, may open the document using a word processor, or link to the web address (URI) where the document is stored..")
110
People are important business elements and can be represented on a knowledge map based on the XML DOM. We can therefore build maps describing the boards of directors of several competitors, associated businesses and holdings. A keyword search on the XML documents allows us to discover "who are the directors of our sister company that are also seated on the boards of subsidiaries of our competitors," as XML supports “context” based search with the support from XML Namespaces.

111
Competitive Intelligence is therefore another aspect of business knowledge, where presenting the right information in the proper context, distilled and related to other sources of information and knowledge, thus helps the CEO to get the insights to define the adequate market strategy or to act with the appropriate tactics. A solid XML based knowledge management infrastructure supporting the organizational learning process allows a company to leverage what it has learned and be a winner in the marketplace.

112
5. Conclusion XML DTD instructs the search engine to search for text in a specific part of a document. A XML based search query interprets words based on their location within a document and relationship to each other. Search results are grouped by subject rather than by random mix.

113
A key ingredient to the success of using XML for searching is the development of DTD templates by the Data Modelers based on the Domain data model proposed in the Knowledge Management Infrastructure. Most of the document management solutions will follow suit with XML integration soon. As more knowledge management solutions try to become portals – aggregating huge amount of information from inside and outside the company – it becomes important that users can locate information quickly.

Similar presentations












 is a process that helps organizations identify, select, organize, disseminate, and transfer important.>")








