Download presentation
Presentation is loading. Please wait.

1
Activity Detection Seminar Sivan Edri

3
This capability of the human vision system argues for recognition of movement directly from the motion itself, as opposed to first reconstructing a three-dimensional model of a person and then recognizing the motion of the model

4
First, I will present the construction of a binary motion-energy image (MEI) which represents where motion has occurred in an image sequence – where there is motion. Next, we generate a motion-history image (MHI) which is a scalar-valued image where intensity is a function of recency of motion – how the motion is moving.
 which is a scalar-valued image where intensity is a function of recency of motion – how the motion is moving..")
5
Taken together, the MEI and MHI can be considered as a two component version of a temporal template, a vector-valued image where each component of each pixel is some function of the motion at that pixel location. These templates are matched against the stored models of views of known movements.

6
Example of someone sitting. Top row contains key frames. The bottom row is cumulative motion images starting from Frame 0.

7
Let be an image sequence and let be a binary image sequence indicating regions of motion. For many applications image differencing is adequate to generate D. Then, the binary MEI is defined

8
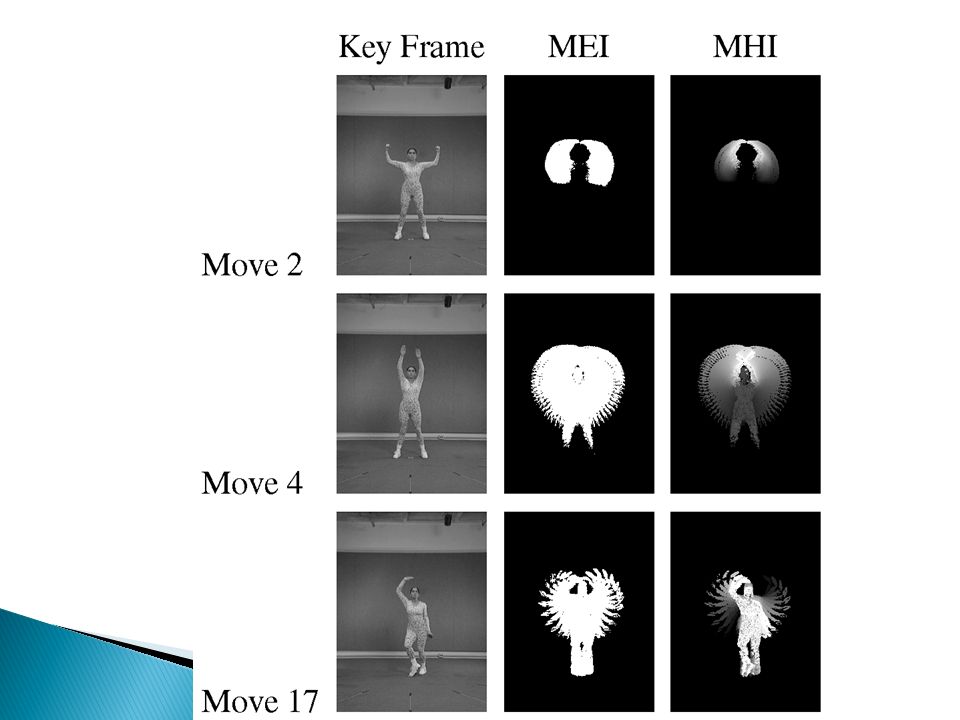
MEIs of sitting movement over 90 viewing angle. The smooth change implies only a coarse sampling of viewing direction is necessary to recognize the movement from all angles.

10
To represent how (as opposed to where) the image motion is moving, we form a motion- history image (MHI). In an MHI, pixel intensity is a function of the temporal history of motion at that point. The result is a scalar-valued image where more recently moving pixels are brighter.

12
Note that the MEI can be generated by thresholding the MHI above zero. Given this situation, one might consider why not use the MHI alone for recognition?

13
The computation is recursive. The MHI at time t is computed from the MHI at time t-1 and the current motion image, and the current MEI is computed by thresholding the MHI. The recursive definition implies that no history of the previous images or their motion fields need to be stored nor manipulated, making the computation both fast and space efficient.

14
There is no consideration of optic flow, the direction of image motion. Note the relation between the construction of the MHI and direction of motion. Consider the waving example where the arms fan upwards.

18
To evaluate the power of the temporal template representation, 18 video sequences of aerobic exercises were recorded, performed several times by an experienced aerobics instructor. Seven views of the movement -90 o to +90 o in 30 o increments in the horizontal plane were recorded.

19
The only preprocessing done on the data was to reduce the image resolution to 320 x 240 from the captured 640 x 480. This step had the effect of not only reducing the data set size, but also of providing some limited blurring which enhances the stability of the global statistics.

20
The Mahalanobis distance is a measure of the distance between a point P and a distribution D. It is a multi-dimensional generalization of the idea of measuring how many standard deviations away P is from the mean of D. This distance is zero if P is at the mean of D, and grows as P moves away from the mean.

21
The Mahalanobis distance of an observation from a group of observations with mean and covariance matrix S is defined as:

22
S = IS != I P(x) decreases fast P(x) decreases slow µ µ P(x) decreases
 decreases fast P(x) decreases slow µ µ P(x) decreases")
23
Intuitively, for one random variable Mahalanobis distance is computed: Lets say we have the next samples: 1, 1, 9, 9 What is the mean? What is the variance? What is the standard deviation? Lets compute the Mahalanobis distance of sample 9:

24
Collect training examples of each movement from a variety of viewing angles. Compute statistical descriptions of the MEIs & MHIs using moment-based features. Our choice is 7 Hu moments. To recognize an input movement, a Mahalanobis distance is calculated between the moment description of the input and each of the known movements.

27
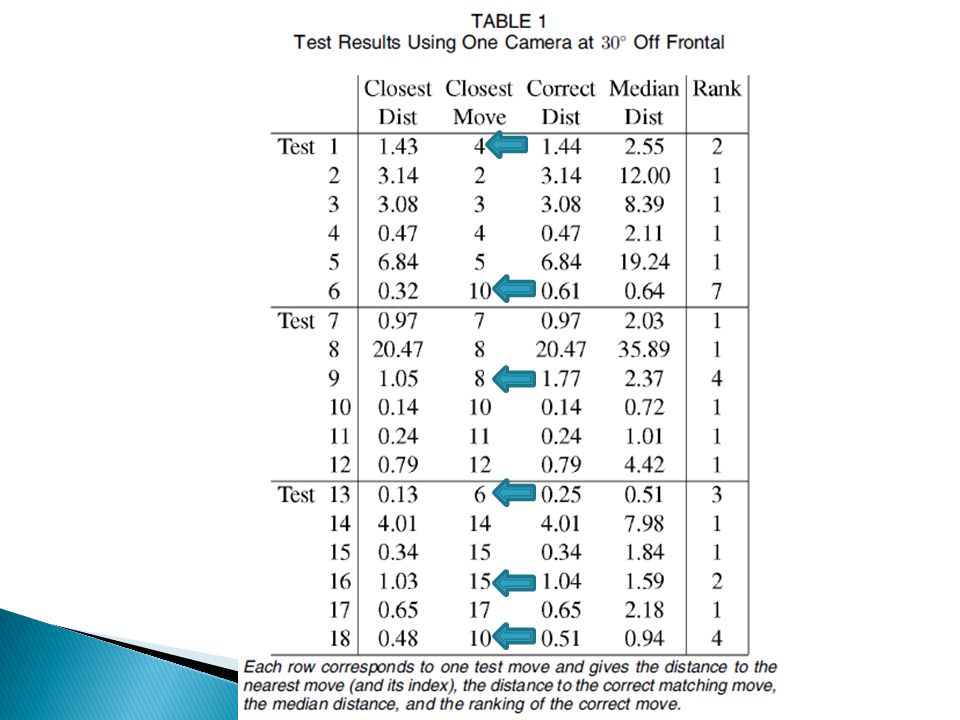
An example of MHIs with similar statistics. (a) Test input of move 13 at 30 o. (b) Closest match which is move 6 at 0 o. (c) Correct match.
 Closest match which is move 6 at 0 o. (c) Correct match..")
29
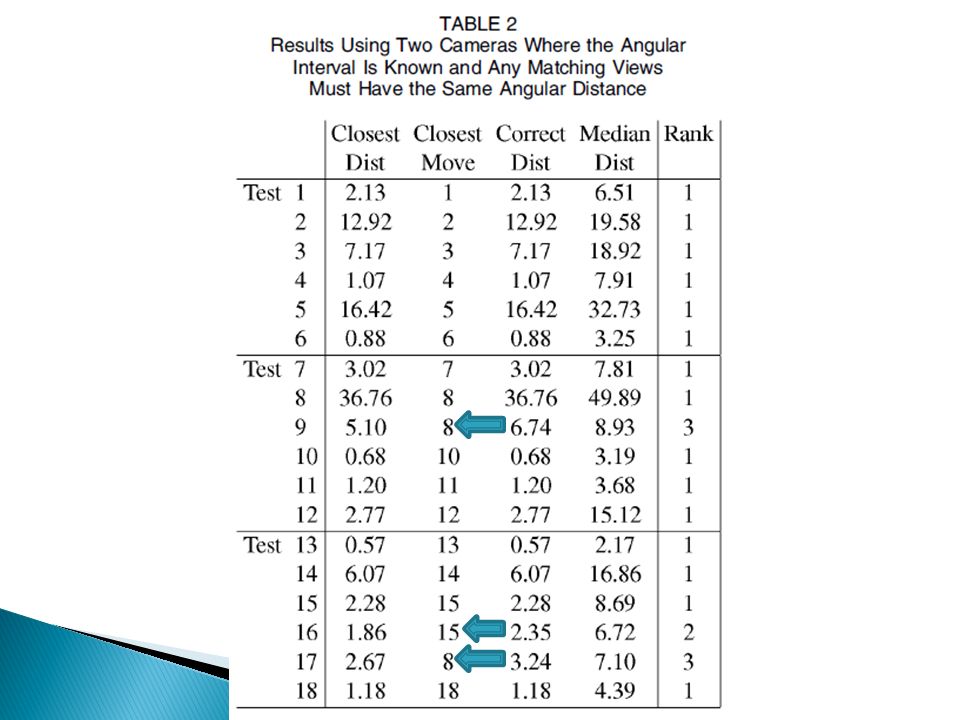
For this experiment, two cameras are used, placed such that they have orthogonal views of the subject. The recognition system now finds the minimum sum of Mahalanobis distances between the two input templates and two stored views of a movement that have the correct angular difference between them, in this case 90 o.

31
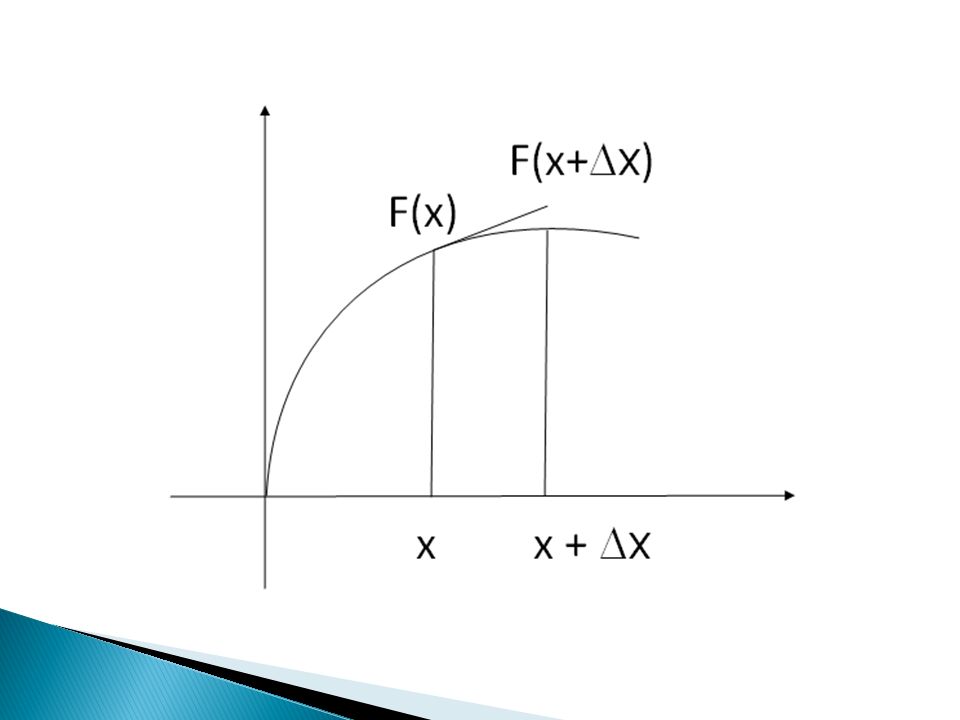
During the training phase, we measure the minimum and maximum duration that a movement may take, T min and T max. If the test motions are performed at varying speeds, we need to choose the right T for the computation of the MEI and the MHI.

32
At each time step, a new MHI is computed setting, where is the longest time window we want the system to consider. We choose where n is the number of temporal integration windows to be considered.

33
A simple thresholding of MHI values less than generates from :

34
T-∆T ∆T T = 20 ∆T = 5 T- ∆T = 15 20 4 10 15 0 5

35
To compute the shape moments, we scale by. This scale factor causes all the MHIs to range from 0 to 1 and provides invariance with respect to the speed of the movement. Iterating, we compute all n MHIs, thresholding of the MHIs yields the corresponding MEIs.

36
Compute the various scaled MHIs and MEIs. Compute the Hu moments for each image. Check the Mahalanobis distance of the MEI parameters against the known view/movement pairs. Any movement found to be within a threshold distance of the input is tested for agreement of the MHI. If more than one movement is matched, we select the movement with the smallest distance.

39
People can easily track individual players and recognize actions such as running, kicking, jumping etc. This is possible in spite of the fact that the resolution is not high – each player might be, say, just 30 pixels tall. How do we develop computer programs that can replicate this impressive human ability?

40
Data flow for the algorithm. Starting with a stabilized figure- centric motion sequence, we compute the spatio-temporal motion descriptor centered at each frame. The descriptors are then matched to a database of pre-classiffied actions using the k-nearest-neighbor framework. The retrieved matches can be used to obtain the correct classification label, as well as other associated information.

41
Optical flow is the pattern of apparent motion of objects, surfaces, and edges in a visual scene caused by the relative motion between an observer (an eye or a camera) and the scene.
 and the scene.")
42
https://www.youtube.com/watch?v=JlLkkom6 tWw https://www.youtube.com/watch?v=JlLkkom6 tWw

43
Constant Brightness Assumption - 2D Case: Take the Taylor series expansion of I : using brightness assumption: * Taken from optical flow presentation by Hagit Hel-Or

45
Optical Flow Equation- Intuition The change in value I t at a pixel P is dependent on: The distance moved (u). * Taken from optical flow presentation by Hagit Hel-Or

46
Optical Flow Equation Only the component of the flow in the gradient direction can be determined. The component of the flow parallel to an edge is unknown. * Taken from optical flow presentation by Hagit Hel-Or

47
Optical Flow Equation Shoot! One equation, two velocity unknowns (u,v) Solving for u,v: * Taken from optical flow presentation by Hagit Hel-Or
 Solving for u,v: * Taken from optical flow presentation by Hagit Hel-Or.")
48
Impose additional constraints ◦ Assume the pixel’s neighbors have the same (u,v) AN2AN2 x21x21 bN1bN1 p1p1 pNpN p2p2 * Taken from optical flow presentation by Hagit Hel-Or
 AN2AN2 x21x21 bN1bN1 p1p1 pNpN p2p2 * Taken from optical flow presentation by Hagit Hel-Or")
49
Equivalent to Solving least squares: ATAATAATbATb The summations are over all pixels in the K x K window This technique was first proposed by Lukas & Kanade (1981) x * Taken from optical flow presentation by Hagit Hel-Or
 x * Taken from optical flow presentation by Hagit Hel-Or")
50
When can we solve LK Eq ? Optimal (u, v) satisfies Lucas-Kanade equation A T A should be invertible The eigen values of A T A should not be too small (noise) A T A should be well-conditioned: 1 / 2 should not be too large ( 1 = larger eigen value) * Taken from optical flow presentation by Hagit Hel-Or
 satisfies Lucas-Kanade equation A T A should be invertible The eigen values of A T A should not be too small (noise) A T A should be well-conditioned: 1 / 2 should not be too large ( 1 = larger eigen value) * Taken from optical flow presentation by Hagit Hel-Or.")
51
Hessian Matrix I x = 0 I y = 0 M = 0 Non Invertable I x = 0 I y = k M = 0 0 k 2 Non Invertable I x = k I y = 0 M = k 2 0 0 Non Invertable I x = k 1 I y = k 2 RM = k 2 0 0 Non Invertable k 1, k 2 correlated (R = rotation) I x = k 1 I y = k 2 M = k 1 2 0 0 k 2 2 Invertable k 1 * k 2 = 0
 I x = k 1 I y = k 2 M = k k 2 2 Invertable k 1 * k 2 = 0")
52
Different motions – classified as similar source: Ran Eshel * Taken from optical flow presentation by Hagit Hel-Or

53
The algorithm starts by computing a figure- centric spatio-temporal volume for each person. Such a representation can be obtained by tracking the human figure and then constructing a window in each frame centered at the figure.

54
Track each player and recover a stabilized spatiotemporal volume, which is the only data used by the algorithm.

55
Finding similarity between different motions requires both spatial and temporal information. This leads to the notion of the spatio-temporal motion descriptor, an aggregate set of features sampled in space and time, that describe the motion over a local time period.

56
The features are based on pixel-wise optical flow as the most natural technique for capturing motion independent of appearance. We think of the spatial arrangement of optical flow vectors as a template that is to be matched in a robust way.

57
Given a stabilized figure-centric sequence, we first compute optical flow at each frame using the Lucas-Kanade algorithm. (a) original image (b) optical flow F x,y
 original image (b) optical flow F x,y.")
58
(c) Separating the x and y components of optical flow vectors (d) Half-wave rectification of each component to produce 4 separate channels (e) Final blurry motion channels
 Separating the x and y components of optical flow vectors (d) Half-wave rectification of each component to produce 4 separate channels (e) Final blurry motion channels")
59
If the four motion channels for frame i of sequence A are a i 1, a i 2, a i 3, a i 4, and similarly for frame j of sequence B then the similarity between motion descriptors centered at frames i and j is: where T and I are the temporal and spatial extents of the motion descriptor respectively.

60
To compare two sequences A and B, the similarity computation will need to be done for every frame of A and B.

61
Ballet: choreographed actions, stationary camera. Clips of motions were digitized from an instructional video for ballet showing professional dancers, two men and two women, performing mostly standard ballet moves. The motion descriptors were computed with 51 frames of temporal extent.

62
(a) Ballet dataset (24800 frames). Video of the male dancers was used to classify the video of the female dancers and vice versa. Classification used 5-nearest- neighbors. The main diagonal shows the fraction of frames correctly classified for each class and is as follows: [.94.97.88.88.97.91 1.74.92.82.99.62.71.76.92.96].

63
Tennis: real actions, stationary camera. For this experiment, footage of two amateur tennis players outdoors were shot. Each player was video-taped on different days in different locations with slightly different camera positions. Motion descriptors were computed with 7 frames of temporal extent.

64
(b) Tennis dataset. The video was sub-sampled by a factor of four, rendering the figures approximately 50 pixels tall. Actions were hand-labeled with six labels. Video of the female tennis player (4610 frames) was used to classify the video of the male player (1805 frames). Classification used 5- nearest-neighbors. The main diagonal is: [.46.64.7.76.88.42].
 was used to classify the video of the male player (1805 frames). Classification used 5- nearest-neighbors. The main diagonal is: [ ]..")
65
The visual quality of the motion descriptor matching suggests that the method could be used in graphics for action synthesis, creating a novel video sequence of an actor by assembling frames of existing Footage. The ultimate goal would be to collect a large database of, say, Charlie Chaplin footage and then be able to “direct” him in a new movie.

66
Given a “target” actor database T, and a “driver” actor sequence D, the goal is to create a synthetic sequence S, that contains the actor from T performing actions described by D. In practice, the synthesized motion sequence S must satisfy two criteria: ◦ The actions in S must match the actions in the “driver” sequence D. ◦ The “target” actor must appear natural when performing the sequence S.

67
“Do as I Do” Action Synthesis. The top row is a sequence of a “driver” actor, the bottom row is the synthesized sequence of the “target” actor (one of the authors) performing the action of the “driver”.
 performing the action of the driver ..")
68
We can also synthesize a novel “target” actor sequence by simply issuing commands, or action labels, instead of using the “driver” actor. For example, one can imagine a video game where pressing the control buttons will make the real-life actor on the screen move in the appropriate way.

70
We use the power of our data to correct imperfections in each individual sample. The input frames (top row) are automatically corrected to produce cleaned up figures (bottom row).
 are automatically corrected to produce cleaned up figures (bottom row)..")
71
The Recognition of Human Movement Using Temporal Templates Aaron F. Bobick, Member, IEEE Computer Society, and James W. Davis, Member, IEEE Computer Society Recognizing Action at a Distance Alexei A. Efros, Alexander C. Berg, Greg Mori, Jitendra Malik Computer Science Division, UC Berkeley Berkeley, CA 94720, USA http://en.wikipedia.org/wiki/Mahalanobis_distance http://en.wikipedia.org/wiki/Mahalanobis_distance http://en.wikipedia.org/wiki/Optical_flow http://en.wikipedia.org/wiki/Optical_flow Optical flow presentation by Hagit Hel-Or

Similar presentations












:747-757, Aug 2000.>")






 15-463: Computational Photography Alexei Efros, CMU, Fall 2006 with a lot of slides stolen from Steve Seitz and Rick.>")





 grading session next Thursday 2:30-5pm –10 minute slot to.>")


 Key issue: How do we represent texture? Topics: –Texture segmentation –Texture-based matching –Texture synthesis.>")
 Automatic Perception 16>")