Download presentation
Presentation is loading. Please wait.

3
GENOME SEQUENCING AND ASSEMBLY Mayo/UIUC Summer Course in Computational Biology

4
Session Outline Planning a genome sequencing projectAssembly strategies and algorithmsAssessing the quality of the assemblyAssessing the quality of the assemblersGenome annotation

5
Genome sequencing

6
Schematic overview of genome assembly. (a) DNA is collected from the biological sample and sequenced. (b) The output from the sequencer consists of many billions of short, unordered DNA fragments from random positions in the genome. (c) The short fragments are compared with each other to discover how they overlap. (d) The overlap relationships are captured in a large assembly graph shown as nodes representing kmers or reads, with edges drawn between overlapping kmers or reads. (e) The assembly graph is refined to correct errors and simplify into the initial set of contigs, shown as large ovals connected by edges. (f) Finally, mates, markers and other long-range information are used to order and orient the initial contigs into large scaffolds, as shown as thin black lines connecting the initial contigs. Schatz et al. Genome Biology 2012 13:243
 DNA is collected from the biological sample and sequenced. (b) The output from the sequencer consists of many billions of short, unordered DNA fragments from random positions in the genome. (c) The short fragments are compared with each other to discover how they overlap. (d) The overlap relationships are captured in a large assembly graph shown as nodes representing kmers or reads, with edges drawn between overlapping kmers or reads. (e) The assembly graph is refined to correct errors and simplify into the initial set of contigs, shown as large ovals connected by edges. (f) Finally, mates, markers and other long-range information are used to order and orient the initial contigs into large scaffolds, as shown as thin black lines connecting the initial contigs. Schatz et al. Genome Biology :243.")
7
Planning a genome sequencing project How large is my genome? How much of it is repetitive, and what is the repeat size distribution? Is a good quality genome of a related species available? What will be my strategy for performing the assembly?

8
How large is my genome? The size of the genome can be estimated from the ploidy of the organism and the DNA content per cell This will affect: »How many reads will be required to attain sufficient coverage (typically 10x to 100x) »What sequencing technology to use »What computational resources will be needed
 »What sequencing technology to use »What computational resources will be needed.")
9
Repetitive sequences Most common source of assembly errors If sequencing technology produces reads > repeat size, impact is much smaller Most common solution: generate reads or mate pairs with spacing > largest known repeat

11
Assemblies can collapse around repetitive sequences. Salzberg S L, and Yorke J A Bioinformatics 2005;21:4320- 4321 © The Author 2005. Published by Oxford University Press. All rights reserved. For Permissions, please email: journals.permissions@oxfordjournals.org

14
Genome(s) from related species Preferably of good quality, with large reliable scaffolds Help guiding the assembly of the target species Help verifying the completeness of the assembly Can themselves be improved in some cases But to be used with caution – can cause errors when architectures are different!
 from related species Preferably of good quality, with large reliable scaffolds Help guiding the assembly of the target species Help verifying the completeness of the assembly Can themselves be improved in some cases But to be used with caution – can cause errors when architectures are different!")
15
Strategies for assembly The sequencing approaches and assembly strategies are interdependent! »E.g., for bacterial genome assembly, can generate PacBio reads and assemble with Celera Assembler, or generate Illumina reads and assemble with Velvet or SPAdes »Optimal sequencing strategies very different for a SOAPdenovo or an ALLPATHS-LG assembly

16
Typical sequencing strategies Bacterial genome: »2x300 overlapping paired-end reads from Illumina MiSeq machine, assembly with SPAdes »PacBio CLR sequences at 200x coverage, self-correction and/or hybrid correction and assembly using Celera Assembler or PBJelly Vertebrate genome: »Combination paired-end (2x250 nt overlapping fragments) and mate- pair (1, 3 and 10 kb libraries) 100 nt reads from Illumina machine at 100x coverage (~1B reads for 1 GB genome), assembly with ALLPATHS-LG
 and mate- pair (1, 3 and 10 kb libraries) 100 nt reads from Illumina machine at 100x coverage (~1B reads for 1 GB genome), assembly with ALLPATHS-LG")
18
Illumina paired end and mate pair sequencing

19
Additional useful data Fosmid libraries »End sequencing adds long-range contiguity information »Pooled fosmids (~5000) can often be assembled more efficiently Moleculo (Illumina TSLR) libraries »Technology acquired by Illumina, allows generation of fully assembled 10 kb sequences Pacbio reads »Provide 5-8 kb reads, but in most cases need parallel coverage by Illumina data for error correction
 can often be assembled more efficiently Moleculo (Illumina TSLR) libraries »Technology acquired by Illumina, allows generation of fully assembled 10 kb sequences Pacbio reads »Provide 5-8 kb reads, but in most cases need parallel coverage by Illumina data for error correction")
20
Assembly strategies and algorithms In all cases, start with cleanup and error correction of raw reads For long reads (>500 nt), Overlap/Layout/Consensus (OLC) algorithms work best For short reads, De Bruijn graph-based assemblers are most widely used
, Overlap/Layout/Consensus (OLC) algorithms work best For short reads, De Bruijn graph-based assemblers are most widely used")
21
Cleaning up the data Trim reads with low quality calls Remove short reads Correct errors: »Find all distinct k-mers (typically k=15) in input data »Plot coverage distribution »Correct low-coverage k-mers to match high- coverage »Part of several assemblers, also stand- alone Quake or khmer programs
 in input data »Plot coverage distribution »Correct low-coverage k-mers to match high- coverage »Part of several assemblers, also stand- alone Quake or khmer programs")
23
Overlap-layout-consensus 23

26
OLC assembly steps Calculate overlays »Can use BLAST-like method, but finding common k- mers more efficient Assemble layout graph, try to simplify graph and remove nodes (reads) – find Hamiltonian path Generate consensus from the alignments between reads (overlays)
 – find Hamiltonian path Generate consensus from the alignments between reads (overlays)")
27
Some OLC-based assemblers Celera Assembler with the Best Overlap Graph (CABOG) »Designed for Sanger sequences, but works with 454 and PacBio reads (with or without error correction) Newbler, a.k.a. GS de novo Assembler »Designed for 454 sequences, but works with Sanger reads

28
De Bruijn graphs - concept

29
Converting reads to a De Bruijn graph Reads are 7 nt long Graph with k=3 Deduced sequence (main branch)
")
30
DBG implementation in the Velvet assembler

32
Examples of DBG-based assemblers EULER (P. Pevzner), the first assembler to use DBG Velvet (D. Zerbino), a popular choice for small genomes SOAPdenovo (BGI), widely used by BGI, best for relatively unstructured assemblies ALLPATHS-LG, probably the most reliable assembler for large genomes (but with strict input requirements)
, a popular choice for small genomes SOAPdenovo (BGI), widely used by BGI, best for relatively unstructured assemblies ALLPATHS-LG, probably the most reliable assembler for large genomes (but with strict input requirements).")
34
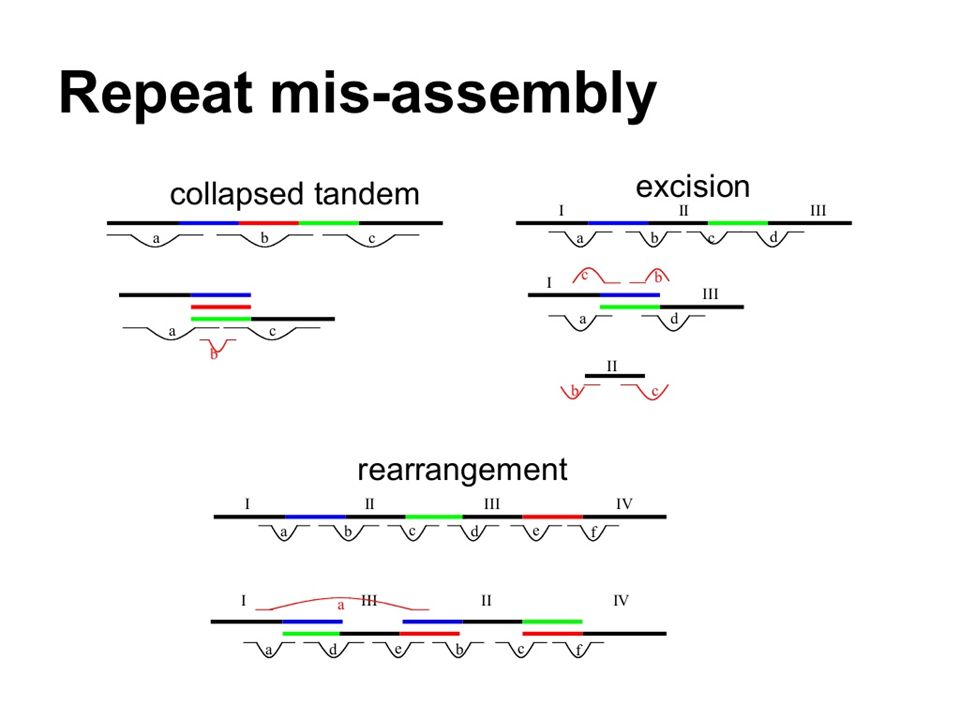
Repeats often split genome into contigs Contig derived from unique sequences Reads from multiple repeats collapse into artefactual contig

35
Consensus (15- 30Kbp) Reads Contig Assembly without pairs results in contigs whose order and orientation are not known. ? Pairs, especially groups of corroborating ones, link the contigs into scaffolds where the size of gaps is well characterized. 2-pair Mean & Std.Dev. is known Scaffold Pairs Give Order & Orientation

36
ChromosomeSTS STS-mapped Scaffolds Contig Gap (mean & std. dev. Known) Read pair (mates) Consensus Reads (of several haplotypes) SNPs External “Reads” Anatomy of a WGS Assembly
 Read pair (mates) Consensus Reads (of several haplotypes) SNPs External Reads Anatomy of a WGS Assembly.")
37
Assembly gaps 37 sequencing gap - we know the order and orientation of the contigs and have at least one clone spanning the gap physical gap - no information known about the adjacent contigs, nor about the DNA spanning the gap Sequencing gaps Physical gaps

38
38 Handling repeats 1.Repeat detection » pre-assembly: find fragments that belong to repeats statistically (most existing assemblers) repeat database ( RepeatMasker ) » during assembly: detect "tangles" indicative of repeats (Pevzner, Tang, Waterman 2001) » post-assembly: find repetitive regions and potential mis- assemblies. Reputer, RepeatMasker "unhappy" mate-pairs (too close, too far, mis-oriented) 2.Repeat resolution »find DNA fragments belonging to the repeat »determine correct tiling across the repeat »Obtain long reads spanning repeats
 2.Repeat resolution »find DNA fragments belonging to the repeat »determine correct tiling across the repeat »Obtain long reads spanning repeats.")
39
How good is my assembly? How much total sequence is in the assembly relative to estimated genome size? How many pieces, and what is their size distribution? Are the contigs assembled correctly? Are the scaffolds connected in the right order / orientation? How were the repeats handled? Are all the genes I expected in the assembly?

40
N50: the most common measure of assembly quality N50 = length of the shortest contig in a set making up 50% of the total assembly length

42
Order and orientation of contigs – more errors in one assembly than in another

43
REAPR overview

44
REAPR Summary REAPR is a toolkit that assesses the quality of a genome assembly independently of the assembler, and without needing a “gold” reference assembly REAPR is not a variant calling tool; it examines the consistency of a genome assembly with the same data that were used to assemble it REAPR output can be visualized in many ways, and helps genome finishing projects Every genome assembly project should use REAPR or a similar toolkit to perform quality checks on the assemblies being produced

45
BUSCO and CEGMA: conserved gene sets From Ian Korf’s group, UC Davis Mapping Core Eukaryotic Genes From Evgeny Zdobnov’s group, University of Geneva Coverage is indicative of quality and completeness of assembly

46
Even the best genomes are not perfect

47
There is no such thing as a “perfect” assembler (results from GAGE competition)
")
48
The computational demands and effectiveness of assemblers are very different

49
Assessing assembly strategies Assemblathon (UC Davis and UC Santa Cruz) »Provide challenging datasets to assemble in open competition (synthetic for edition 1, real for edition 2) »Assess competitor assemblies by many different metrics »Publish extensive reports GAGE (U. of Maryland and Johns Hopkins) »Select datasets associated with known high-quality genomes »Run a set of open source assemblers with parameter sweeps on these datasets »Compare the results, publish in scholarly Journals with complete documentation of parameters
 »Select datasets associated with known high-quality genomes »Run a set of open source assemblers with parameter sweeps on these datasets »Compare the results, publish in scholarly Journals with complete documentation of parameters.")
50
Some advice on running assemblies Perform parameter sweeps »Use many different values of key parameters, especially k-mer size for DBG assemblers, and evaluate the output (some assemblers can do this automatically) Try different subsets of the data »Sometimes libraries are of poor quality and degrade the quality of the assembly »Artefacts in the data (e.g. PCR duplicates, homopolymer runs, …) can also badly affect output quality Try more than one assembler »There is no such thing as “the best” assembler
 can also badly affect output quality Try more than one assembler »There is no such thing as the best assembler.")
51
Genome annotation A genome sequence is useless without annotation Three steps in genome annotation: »Find features not associated with protein-coding genes (e.g. tRNA, rRNA, snRNA, SINE/LINE, miRNA precursors) »Build models for protein-coding genes, including exons, coding regions, regulatory regions »Associate biologically relevant information with the genome features and genes
 »Build models for protein-coding genes, including exons, coding regions, regulatory regions »Associate biologically relevant information with the genome features and genes.")
52
Methods for genome annotation Ab initio, i.e. based on sequence alone »INFERNAL/rFAM (RNA genes), miRBase (miRNAs), RepeatMasker (repeat families), many gene prediction algorithms (e.g. AUGUSTUS, Glimmer, GeneMark, …) Evidence-based »Require transcriptome data for the target organism (the more the better) »Align cDNA sequences to assembled genome and generate gene models: TopHat/Cufflinks, Scripture
, miRBase (miRNAs), RepeatMasker (repeat families), many gene prediction algorithms (e.g. AUGUSTUS, Glimmer, GeneMark, …) Evidence-based »Require transcriptome data for the target organism (the more the better) »Align cDNA sequences to assembled genome and generate gene models: TopHat/Cufflinks, Scripture.")
53
Methods for biological annotation BLAST of gene models against protein databases »Sequence similarity to known proteins InterProScan of predicted proteins against databases of protein domains (Pfam, Prosite, HAMAP, PANTHER, …) Mapping against Gene Ontology terms (BLAST2GO)
 Mapping against Gene Ontology terms (BLAST2GO)")
54
MAKER, integration framework for genome annotation MAKER runs many software tools on the assembled genome and collates the outputs See http://gmod.org/wiki/MAKER http://gmod.org/wiki/MAKER

55
Acknowledgements For this slide deck I “borrowed” figures and slides from many publications, Web pages and presentations by »M. Schatz, S. Salzberg, K. Bradnam, K. Krampis, D. Zerbino, J. J. Cook, M. Pop, G. Sutton, T. Seemann Thank you!

Similar presentations























 Global Ocean Sampling project (GOS) CAMERA CAMERA METAREP.>")




