Download presentation
Presentation is loading. Please wait.

1
Thesis Committee: Craig W. Thompson Dale R. Thompson Amy Apon GRINDEX: Framework and Prototype for a Grid-based Index Jonathan Schisler June 30 th, 2005 A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Engineering

2
Outline Motivation and Objectives Alternative Approaches –Grid Databases –In-Memory Databases GRINDEX Architecture Prototype Tests and Results Future Work

3
Motivation -Began with a clustering algorithm that operated serially on top of a relational dbms -Wanted to execute on a grid to take advantage of parallelism to improve scalability and increase speed -Needed read/write capabilities so that the data structures could grow dynamically -Handle different request types – batch and interactive insertion modes -Noticed the need for an indexing layer

4
GRINDEX Objectives Provide an architecture for a main memory grid- based DBMS Maintain traditional database functionality Explore, research, and recommend methods for distributing data across a grid environment where application data will be dynamically re- partitioned while the application maintains very high throughput. Maintain and provide load-balancing during the dynamic re-partitioning process.

5
Objectives (cont) Give applications complete read/write capability. Hide the details of the underlying storage from the high-level user and any calling applications. Hide the details of re-partitioning and splitting from calling applications. Provide a low cost alternative to large scale databases

6
Objectives (cont) Allow for the addition of other index structures and other storage configurations by viewing disk and main memory as different storage level implementations that are independent of the application layer and could accommodate change through the use of encapsulation. Provide an architectural design that will allow for failover. This includes researching and providing a way to handle failover in the dynamic grid environment and exploring what abilities can be provided in the environment with little or no cost to performance.

7
Objectives (cont) Provide a prototype implementation that proves the feasibility and usefulness of the GRINDEX framework and provides a setup for testing with synthetic data. Suggest further optimizations of the prototype based on performance measurements and analysis. Recommend future work relating to the system

8
Alternative Approaches –Proprietary system Advantages –Performance Disadvantages –Not reusable –Development costs –Maintenance –Spend the Money Advantages –Technical Support –Generic solution – reusable –Performance Disadvantages –Cost –Limited Scalability

9
Relational DBMS Architecture

10
Alternative Approaches Grid-based Solution –Potential Advantages Dynamic allocation and access Reusability and flexibility High throughput Low cost Batch and interactive query response Scalability Low maintenance –Disadvantages Initial development Additional network communications

11
Grid Databases mySQL Cluster –Commodity hardware (inexpensive) –“Shared-nothing” architecture –No single point of failure –Heterogeneous machines –Must be re-configured, re-indexed and re- started to allow for growth
 – Shared-nothing architecture –No single point of failure –Heterogeneous machines –Must be re-configured, re-indexed and re- started to allow for growth")
12
Grid Databases NCR’s Teradata –Central “enterprise-wide” database –“Shared-nothing” architecture –Unconditional parallelism –Scales linearly –Proprietary BYNET (expensive) –Supports up to 1.023 Petabytes (PB) using a 512 node setup –Uses only hash indexes –Orders records via the BYNET
 –Supports up to Petabytes (PB) using a 512 node setup –Uses only hash indexes –Orders records via the BYNET")
13
Grid Databases Oracle 10g –Clustered storage –Utilizes high-speed interconnects such as Infiniband (low latency, high bandwidth) –Scheduler –Resource manager –Supports up to 8 exabytes of data in a single database –Depends on disk
 –Scheduler –Resource manager –Supports up to 8 exabytes of data in a single database –Depends on disk")
14
Alternative Approaches In-Memory Databases –Non-traditional –Use main memory for storage –Example use - embedded systems –Fast response time –Volatile (must provide means of reliability and recovery)
")
15
In-Memory Databases Single User Relational Database Management System Language Facility (SURLY) –Small, powerful RDBMS –Designed for a single PC –Language neutral –Provides a command syntax –Complete relational algebra –Memory management techniques
 –Small, powerful RDBMS –Designed for a single PC –Language neutral –Provides a command syntax –Complete relational algebra –Memory management techniques")
16
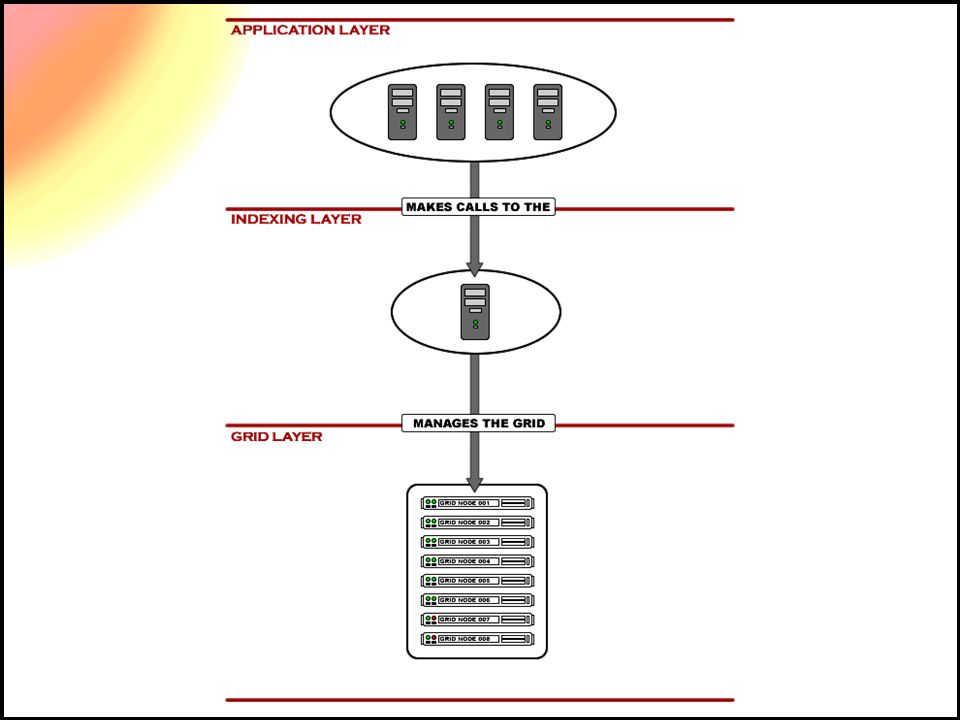
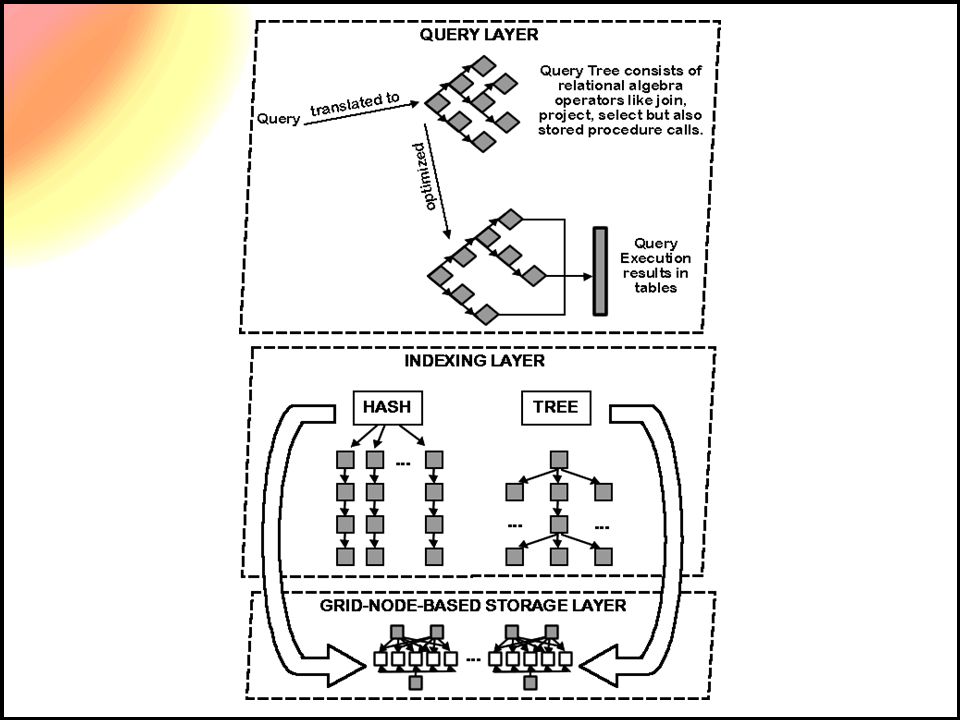
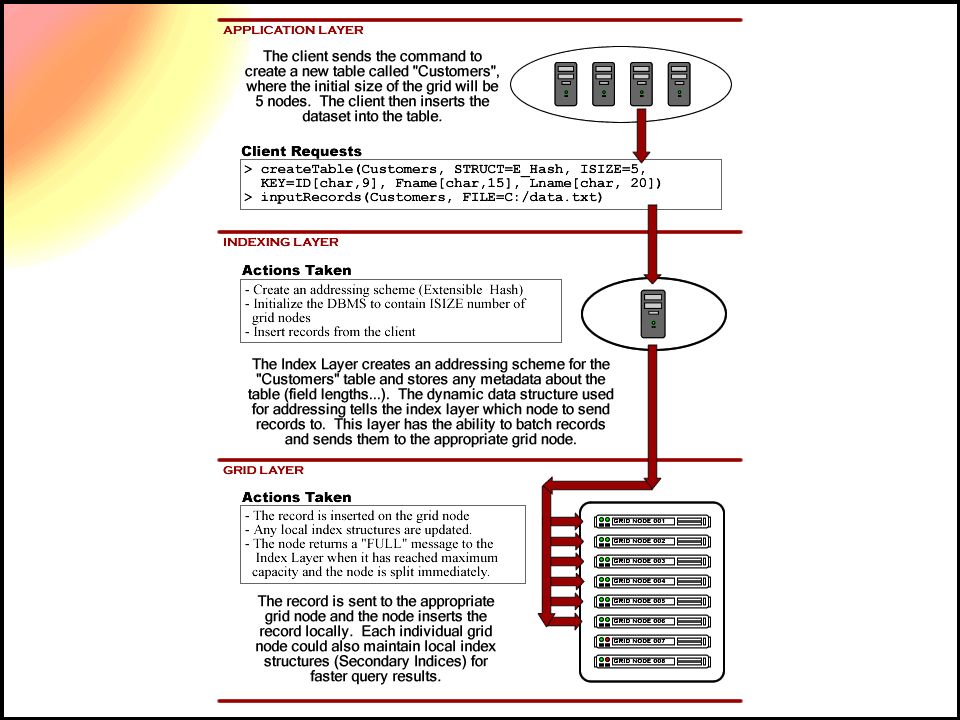
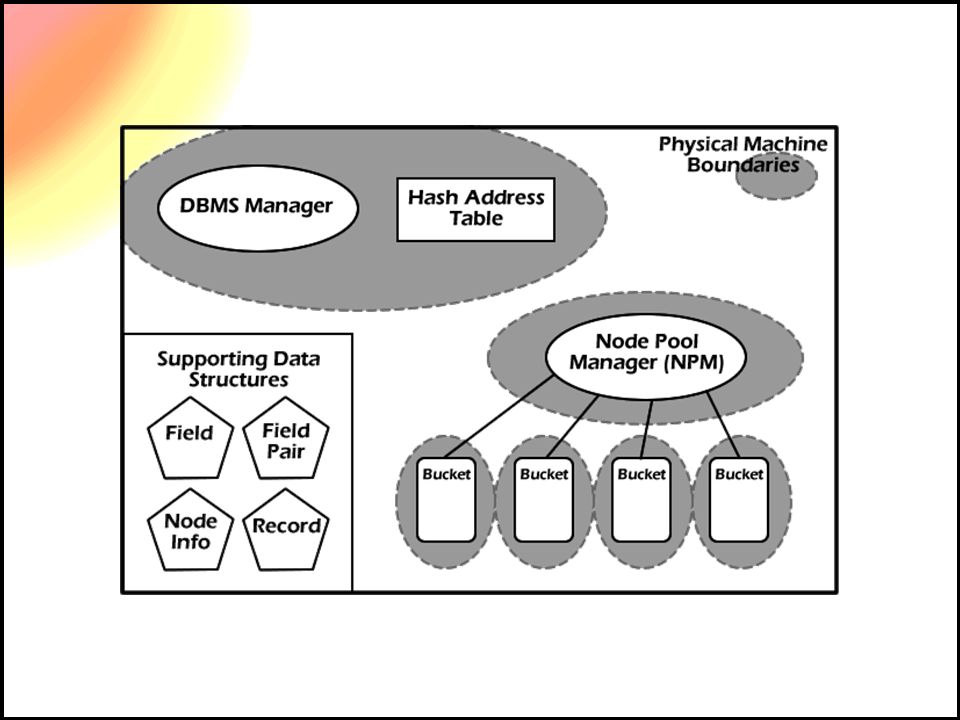
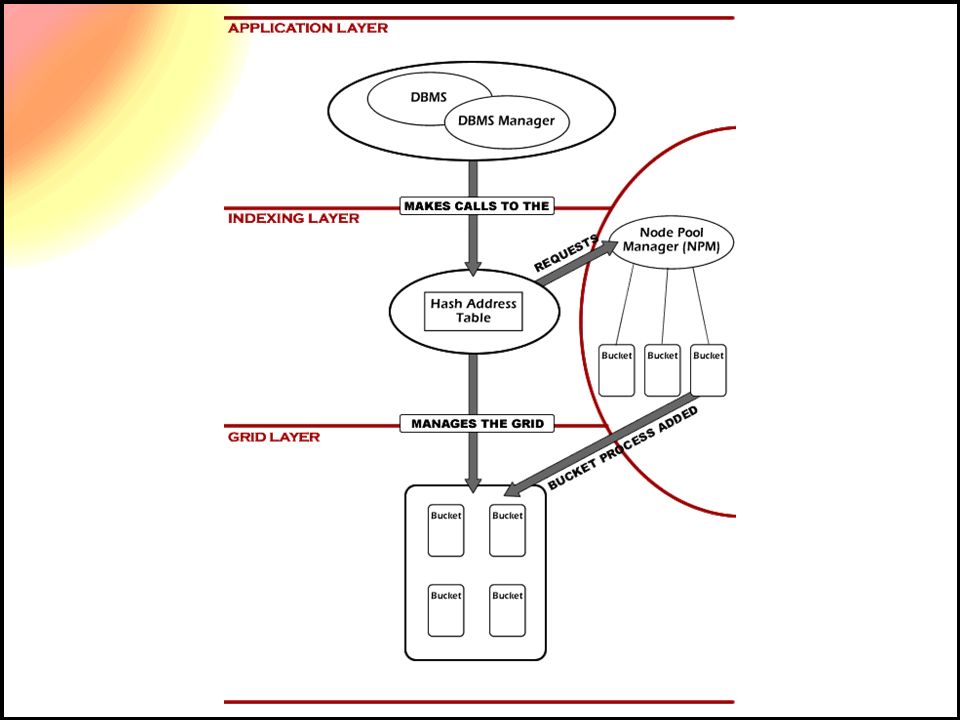
GRINDEX Architecture –Extension of traditional RDBMS –Adds capability of operating over a grid –Adds capability of operating in-memory –Provides high-level application interface –Encapsulates the index layer

19
Commands (API) createTable insertRecord inputRecords printTableInfo printTable SQL Query runFile printNumRecords exit (quit)
 createTable insertRecord inputRecords printTableInfo printTable SQL Query runFile printNumRecords exit (quit)")
21
Hashes Static Hash –Based on a fixed number of Buckets –Must halt and re-partition to accommodate growth Dynamic Hash –Hash function modified dynamically to accommodate growth/shrinking –For unknown amount of growth

22
Dynamic Hash Functions Linear –Complex address calculations –Performance varies cyclically Spiral –Uniform performance –Intentionally distributes records unevenly Extensible (or extendable) –Split and merge buckets as data set size changes –Small performance overhead –Space efficiency is maintained
 –Split and merge buckets as data set size changes –Small performance overhead –Space efficiency is maintained")
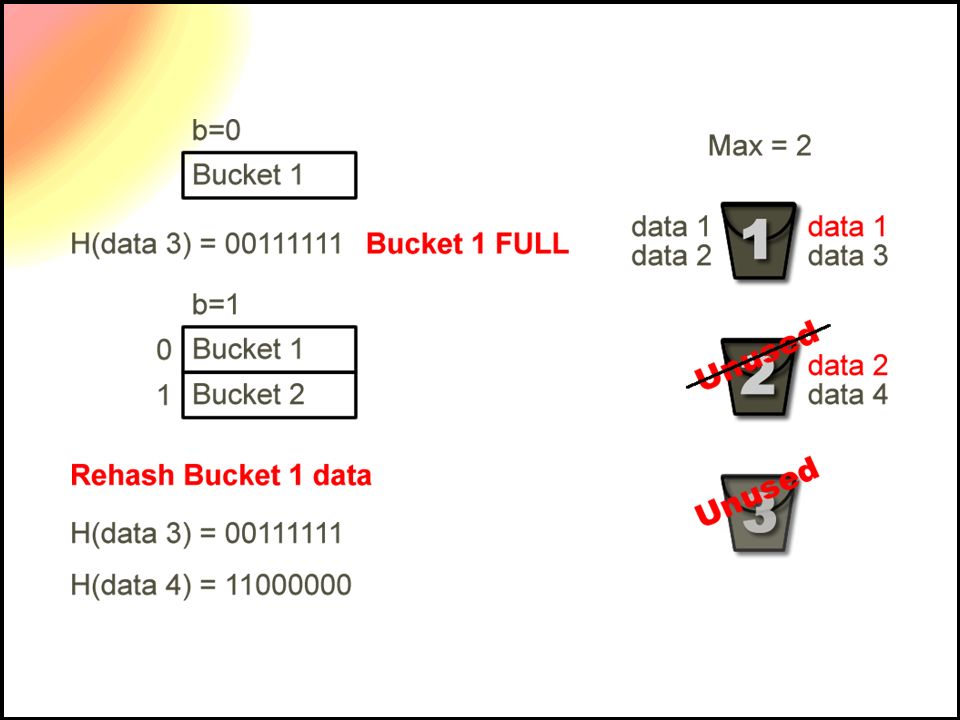
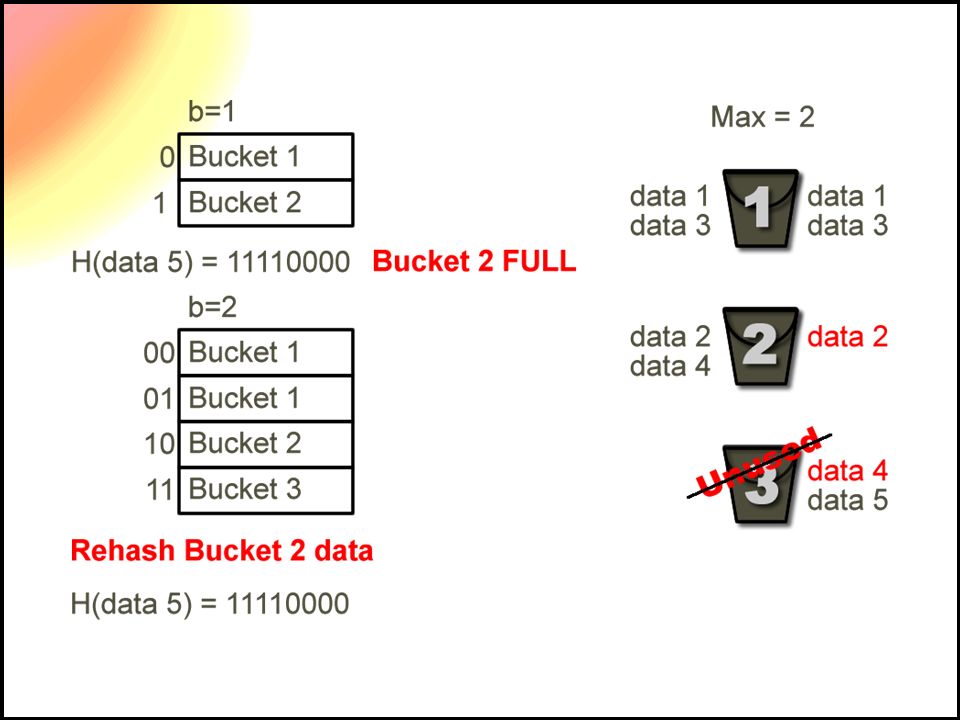
23
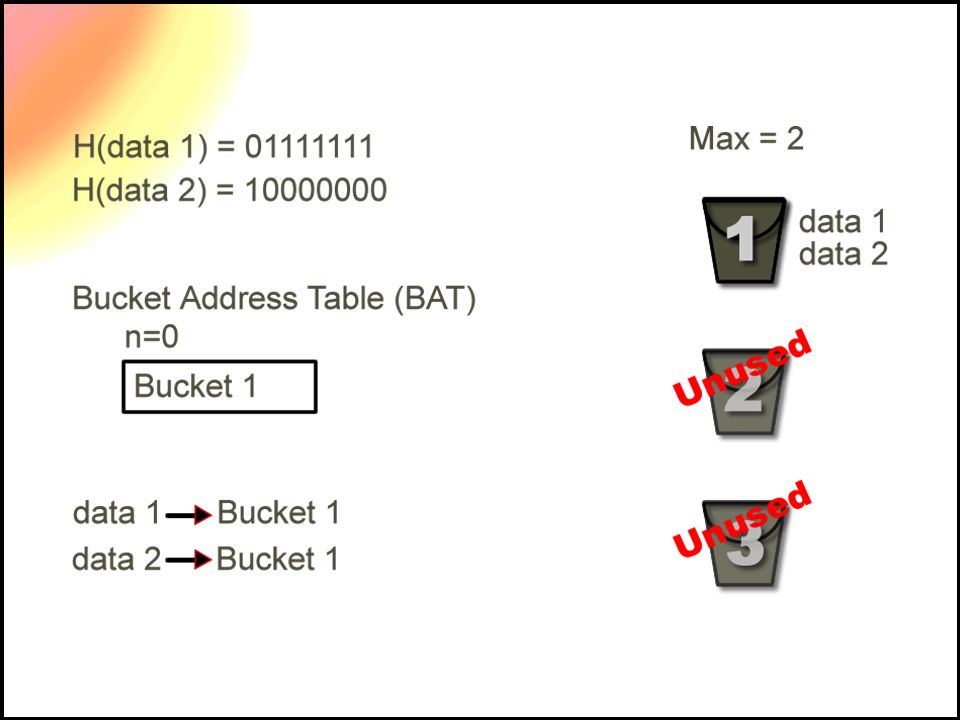
Extensible Hashing Choose a uniform and random hash function Generates a n-bit binary integer 2^n is the maximum number of buckets used A number of bits from the hash value is used as a pointer to a specific bucket In order to add more buckets, more bits of the hash are used

27
Prototype Developed in Java using the NetBeans 3.6 IDE Uses Extensible Hash Supports Batch Transfers Consists of 10 Class Files Supports 9 Commands Approx. 3000 LOC

30
Testing Used a synthetic data set (2 million records) generated from the American Dataset Program (ADP) Recorded the following factors for each execution during testing: –Use of Batch mode (Batch size if used) –Number of physical machines being used –Number of Bucket Process the execution use initially –How many splits occurred –Maximum number of records per Bucket Process
 generated from the American Dataset Program (ADP) Recorded the following factors for each execution during testing: –Use of Batch mode (Batch size if used) –Number of physical machines being used –Number of Bucket Process the execution use initially –How many splits occurred –Maximum number of records per Bucket Process")
31
Hardware Configurations –MACHINE 1: HP Pavilion XL766 Pentium III - 733MHz 640MB RAM OS: WINDOWS XP IDE: NetBeans IDE 3.6 Java 1.4.2_07 –MACHINES 4, 5, 6, 7* (from Hawk): Dual-processor 64-bit Opterons – 1.6GHz 2GB RAM Rocks 3.3.0 Linux Kernel 2.4.21 *Equipment provided by the National Science Foundation through grant #DUE 0410966. –MACHINE 2: Dell Optiplex GX1p Pentium III - 450MHz 128MB RAM OS: WINDOWS XP IDE: NetBeans IDE 3.6 Java 1.4.2_07 –MACHINE 3: Dell Optiplex GX1 Pentium III - 550MHz 128MB RAM OS: WINDOWS XP IDE: NetBeans IDE 3.6 Java 1.4.2_07

32
Results from Hawk 1854.3 records/s for 100,000 records 1873.1 records/s for 500,000 records 1877.3 records/s for 1,000,000 records 2293.6 records/s for 10,000,000 records Indicates that the system scales well 8.26 million records/hr

34
Results (cont) Batch size greatly affected performance Example) Inserting 1000 records using machines 1,2,3 –Batch mode OFF: 694s –Batch mode ON: 30s
 Batch size greatly affected performance Example) Inserting 1000 records using machines 1,2,3 –Batch mode OFF: 694s –Batch mode ON: 30s")
36
Results (cont) Optimal maximum batch size: –Approx. maximum batch size = 1,500 records –Average record size = 55 Bytes –Optimal maximum batch size: 1,500 records x 55B/record = 82,500B Always better to initialize the table with as many buckets as it needs because it is costly to split Average utilization –Predicted: 69% –Measured: 67.6%

37
Future Work Splitting Optimizations Batching optimizations Adding other Dynamic Plug-in Indices Predicting initial number of buckets Index and bucket replication for performance and reliability Grid SURLY Extended SQL support

38
Questions/Discussion

Similar presentations





 K. Maly, and M. Zubair Department.>")

: generated by the CPU Physical: seen by the memory.>")


 File Management & Input/Out Systems 10/14/2008 Yang Song (Prepared.>")








 Dr. Abeer Mahmoud Princess Nora University Faculty of Computer & Information Systems Computer science Department.>")

