Download presentation
Presentation is loading. Please wait.

1
Acoustic Analysis of Speech Robert A. Prosek, Ph.D. CSD 301 Robert A. Prosek, Ph.D. CSD 301

2
Acoustic Analysis Instrumental acoustical analyses have been used for over 100 years Analog techniques dominated the first 60 of these years More recently, digital techniques have dominated the field We will begin by introducing a few of the important analog methods, then turn to the digital Instrumental acoustical analyses have been used for over 100 years Analog techniques dominated the first 60 of these years More recently, digital techniques have dominated the field We will begin by introducing a few of the important analog methods, then turn to the digital

3
Oscillograph/Oscillogram Any device that can display a waveform is an oscillograph The output (display or hardcopy) is an oscillogram There is limited information available in a waveform silence burst noise periodicity Any device that can display a waveform is an oscillograph The output (display or hardcopy) is an oscillogram There is limited information available in a waveform silence burst noise periodicity
 is an oscillogram There is limited information available in a waveform silence burst noise periodicity Any device that can display a waveform is an oscillograph The output (display or hardcopy) is an oscillogram There is limited information available in a waveform silence burst noise periodicity")
4
Filter Bank Analysis In this procedure, a filter bank or a single filter is used to divide the signal energy into frequency bands The output energy is displayed for each band This is a form of spectral analysis The output typically is displayed in the form of an histogram The technique is very common in audiology and hearing applications In this procedure, a filter bank or a single filter is used to divide the signal energy into frequency bands The output energy is displayed for each band This is a form of spectral analysis The output typically is displayed in the form of an histogram The technique is very common in audiology and hearing applications

5
Sound Spectrograph/Spectrogram The instrument is called a spectrograph The output (usually a hardcopy) is a spectrogram This is the most commonly used device in speech research The spectrograph can capture the dynamics of speech Acoustic signals vary only in frequency, amplitude and time The sound spectrograph captures all of these The instrument is called a spectrograph The output (usually a hardcopy) is a spectrogram This is the most commonly used device in speech research The spectrograph can capture the dynamics of speech Acoustic signals vary only in frequency, amplitude and time The sound spectrograph captures all of these
 is a spectrogram This is the most commonly used device in speech research The spectrograph can capture the dynamics of speech Acoustic signals vary only in frequency, amplitude and time The sound spectrograph captures all of these The instrument is called a spectrograph The output (usually a hardcopy) is a spectrogram This is the most commonly used device in speech research The spectrograph can capture the dynamics of speech Acoustic signals vary only in frequency, amplitude and time The sound spectrograph captures all of these")
6
Sound Spectrogram Abscissa is time Ordinate is frequency Intensity is shown as shades of gray Black areas indicate the highest amplitudes White areas indicate the noise floor Amplitudes between these extremes are shown in varying shades of grey the more intense the signal is at a particular frequency and time, the darker the trace Abscissa is time Ordinate is frequency Intensity is shown as shades of gray Black areas indicate the highest amplitudes White areas indicate the noise floor Amplitudes between these extremes are shown in varying shades of grey the more intense the signal is at a particular frequency and time, the darker the trace

9
Digital Signal Processing (1) In the late 1960’s general purpose digital computers made it possible to analyze acoustic signals on the computer These techniques are necissarily discrete as well as digital Once in discrete form, the signal can be stored conveniently and analyzed in many way that were not possible with analog techniques In the late 1960’s general purpose digital computers made it possible to analyze acoustic signals on the computer These techniques are necissarily discrete as well as digital Once in discrete form, the signal can be stored conveniently and analyzed in many way that were not possible with analog techniques
 In the late 1960’s general purpose digital computers made it possible to analyze acoustic signals on the computer These techniques are necissarily discrete as well as digital Once in discrete form, the signal can be stored conveniently and analyzed in many way that were not possible with analog techniques In the late 1960’s general purpose digital computers made it possible to analyze acoustic signals on the computer These techniques are necissarily discrete as well as digital Once in discrete form, the signal can be stored conveniently and analyzed in many way that were not possible with analog techniques")
10
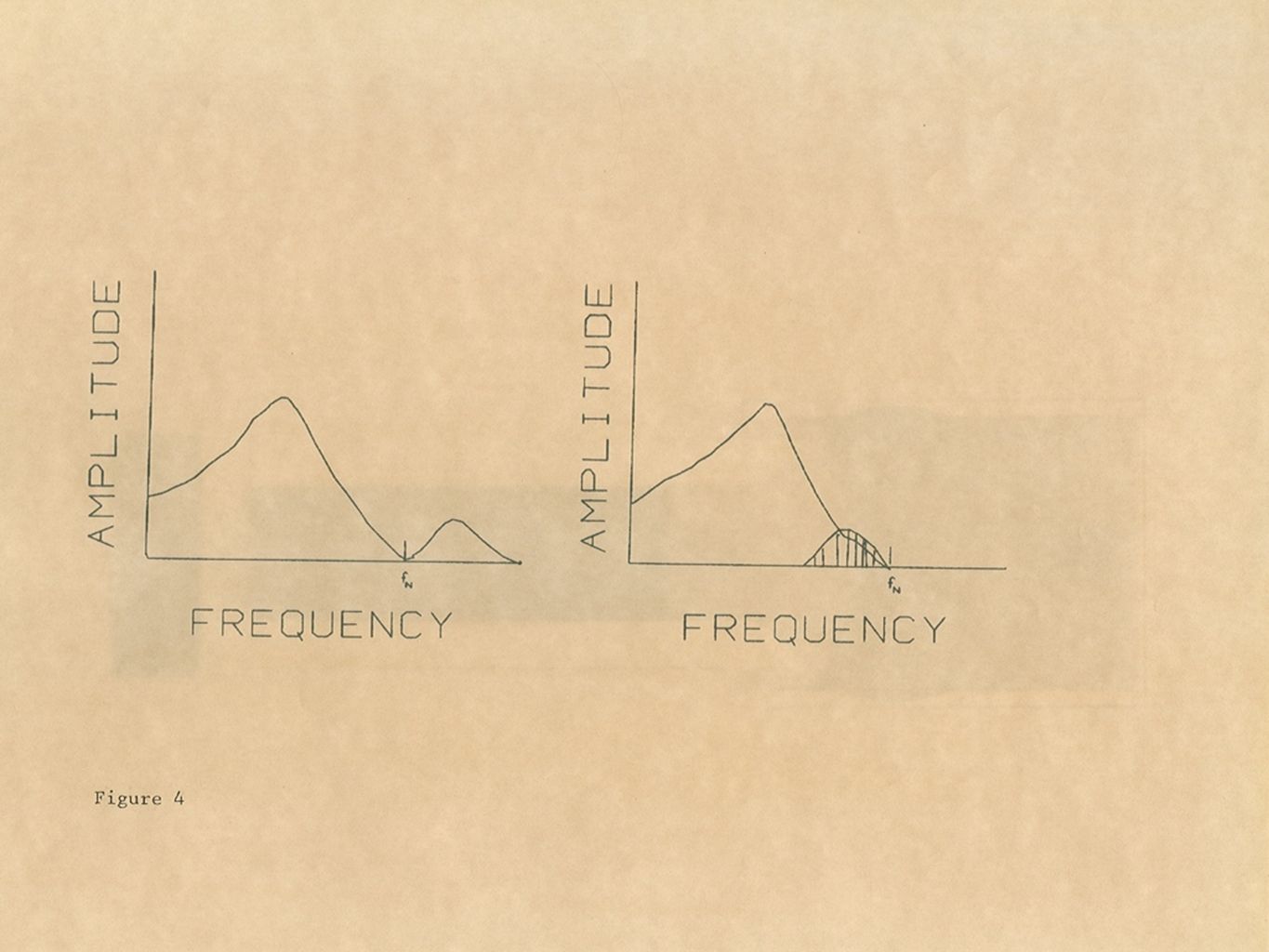
Digital Signal Processing (2) Presampling or brickwall filtering Nyquist Theorum In order to represent a signal faithfully, it must be sampled at a rate equal to twice its highest frequency The brickwall filter removes all of the energy above the Nyquist frequency The clinician/researcher determines the Nyquist frequency Some knowledge of speech and speech and language disorders is required Presampling or brickwall filtering Nyquist Theorum In order to represent a signal faithfully, it must be sampled at a rate equal to twice its highest frequency The brickwall filter removes all of the energy above the Nyquist frequency The clinician/researcher determines the Nyquist frequency Some knowledge of speech and speech and language disorders is required
 Presampling or brickwall filtering Nyquist Theorum In order to represent a signal faithfully, it must be sampled at a rate equal to twice its highest frequency The brickwall filter removes all of the energy above the Nyquist frequency The clinician/researcher determines the Nyquist frequency Some knowledge of speech and speech and language disorders is required Presampling or brickwall filtering Nyquist Theorum In order to represent a signal faithfully, it must be sampled at a rate equal to twice its highest frequency The brickwall filter removes all of the energy above the Nyquist frequency The clinician/researcher determines the Nyquist frequency Some knowledge of speech and speech and language disorders is required")
12
Digital Signal Processing (3) Sampling Analog-to-digital conversion Signal must be sampled at the Nyquist rate Sampling decides the times at which the signal will be Sampling converts the acoustic signal into a series of numbers Instead of amplitudes at all instances of time, no matter how small the time interval, amplitudes in the digital world exist only at the sampling interval Aliasing Sampling Analog-to-digital conversion Signal must be sampled at the Nyquist rate Sampling decides the times at which the signal will be Sampling converts the acoustic signal into a series of numbers Instead of amplitudes at all instances of time, no matter how small the time interval, amplitudes in the digital world exist only at the sampling interval Aliasing
 Sampling Analog-to-digital conversion Signal must be sampled at the Nyquist rate Sampling decides the times at which the signal will be Sampling converts the acoustic signal into a series of numbers Instead of amplitudes at all instances of time, no matter how small the time interval, amplitudes in the digital world exist only at the sampling interval Aliasing Sampling Analog-to-digital conversion Signal must be sampled at the Nyquist rate Sampling decides the times at which the signal will be Sampling converts the acoustic signal into a series of numbers Instead of amplitudes at all instances of time, no matter how small the time interval, amplitudes in the digital world exist only at the sampling interval Aliasing")
14
Digital Signal Processing (4) Quantization Discrete number of amplitude levels The more quantizer levels available, the more the discrete signal represents the original analog signal In our applications, 16 -bit quantizers over a 20-volt range are typical This yields an amplitude resolution of 300 μvolts and a signal to noise ratio of 96 dB Quantization Discrete number of amplitude levels The more quantizer levels available, the more the discrete signal represents the original analog signal In our applications, 16 -bit quantizers over a 20-volt range are typical This yields an amplitude resolution of 300 μvolts and a signal to noise ratio of 96 dB
 Quantization Discrete number of amplitude levels The more quantizer levels available, the more the discrete signal represents the original analog signal In our applications, 16 -bit quantizers over a 20-volt range are typical This yields an amplitude resolution of 300 μvolts and a signal to noise ratio of 96 dB Quantization Discrete number of amplitude levels The more quantizer levels available, the more the discrete signal represents the original analog signal In our applications, 16 -bit quantizers over a 20-volt range are typical This yields an amplitude resolution of 300 μvolts and a signal to noise ratio of 96 dB")
15
Digital Signal Processing (5) After A/D conversion the signal is stored as a stream of numbers time is related by the index to the sampling rate the amplitude is the stored number in this form, many operations can be performed After A/D conversion the signal is stored as a stream of numbers time is related by the index to the sampling rate the amplitude is the stored number in this form, many operations can be performed
 After A/D conversion the signal is stored as a stream of numbers time is related by the index to the sampling rate the amplitude is the stored number in this form, many operations can be performed After A/D conversion the signal is stored as a stream of numbers time is related by the index to the sampling rate the amplitude is the stored number in this form, many operations can be performed")
16
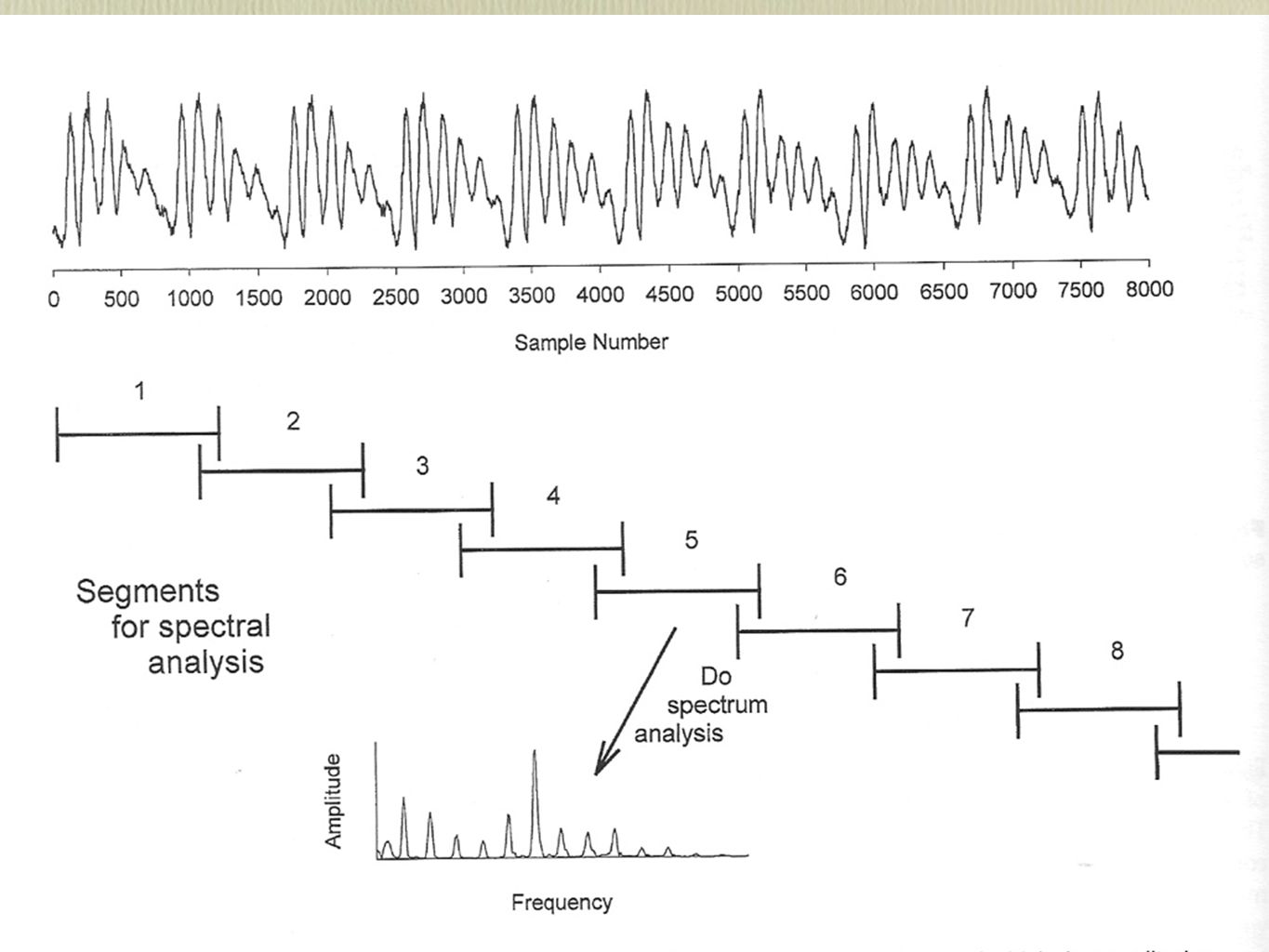
Waveform Display Duration measurements speech changes gradually some consistent rules need to be adopted Signal editing again, some consistent rules need to be adopted Amplitude measurements rms is the most common vocal fundamental frequency Duration measurements speech changes gradually some consistent rules need to be adopted Signal editing again, some consistent rules need to be adopted Amplitude measurements rms is the most common vocal fundamental frequency

17
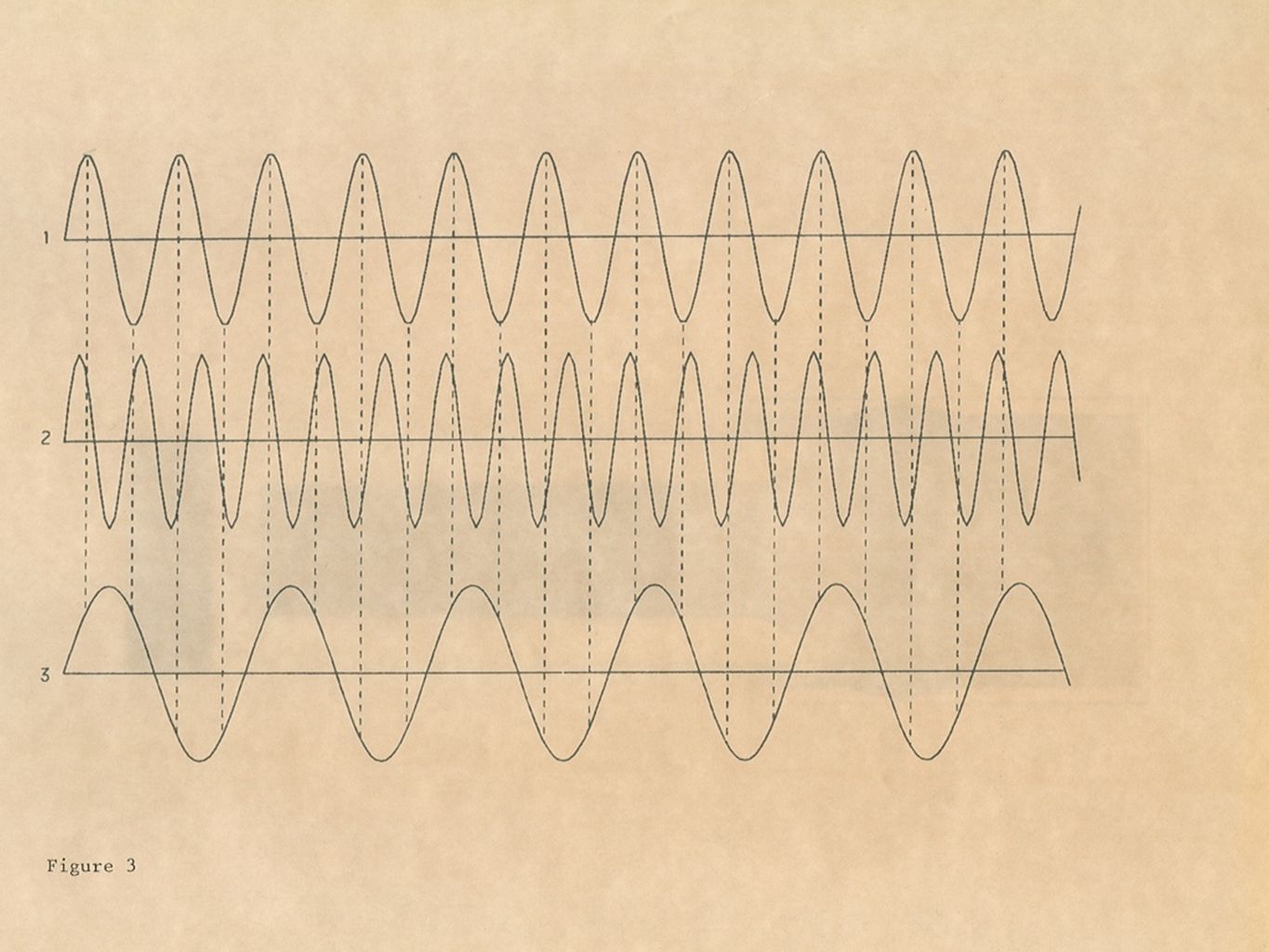
Digital Spectrum Analysis The Fourier Transform revisited (FFT) Periodic waveforms can be thought of as a series of sinusoids amplitude and phase The Fourier Transform and the Inverse Fourier transform allow powerful analysis-by-synthesis techniques The Fourier Transform revisited (FFT) Periodic waveforms can be thought of as a series of sinusoids amplitude and phase The Fourier Transform and the Inverse Fourier transform allow powerful analysis-by-synthesis techniques
 Periodic waveforms can be thought of as a series of sinusoids amplitude and phase The Fourier Transform and the Inverse Fourier transform allow powerful analysis-by-synthesis techniques The Fourier Transform revisited (FFT) Periodic waveforms can be thought of as a series of sinusoids amplitude and phase The Fourier Transform and the Inverse Fourier transform allow powerful analysis-by-synthesis techniques")
18
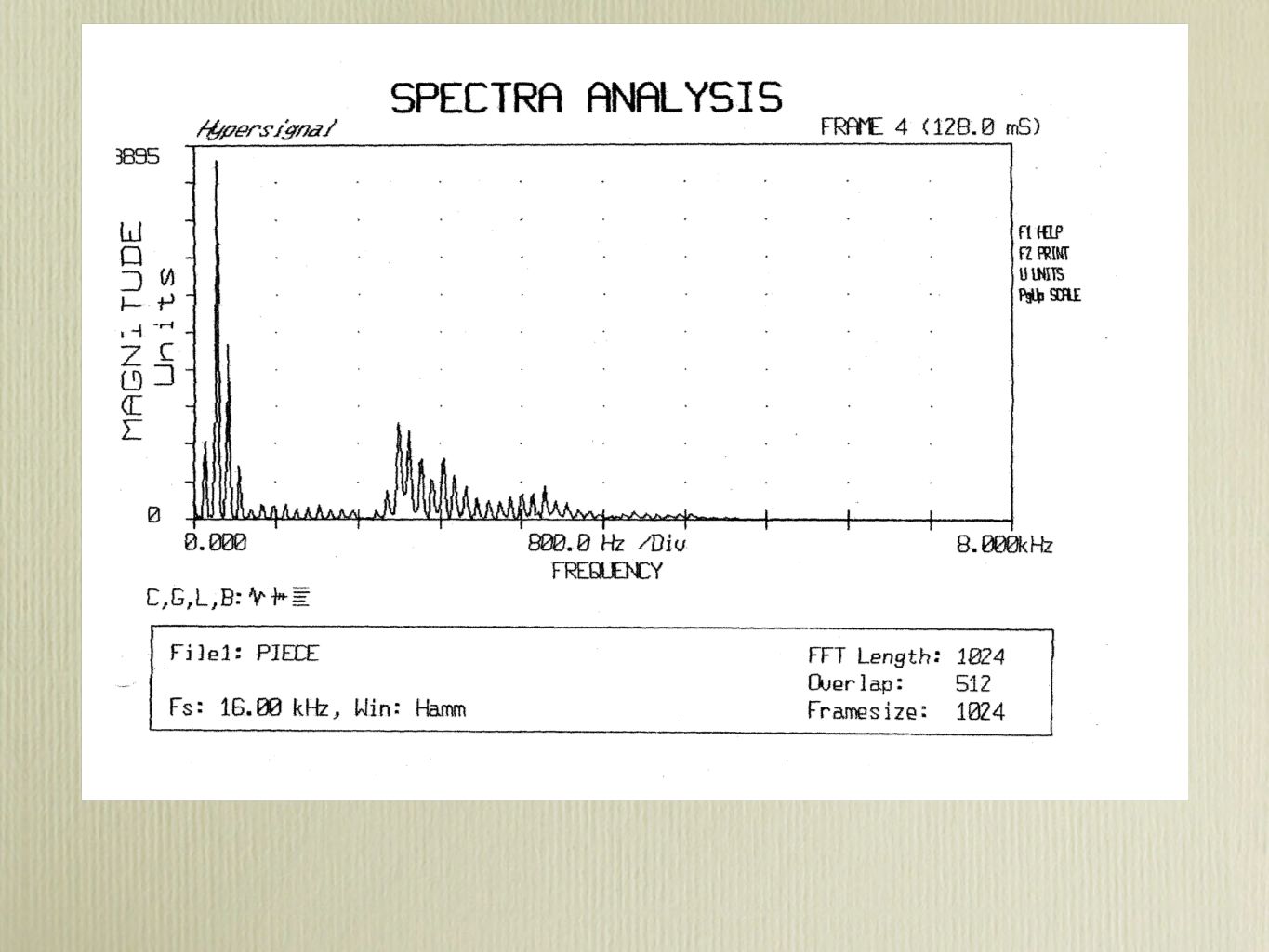
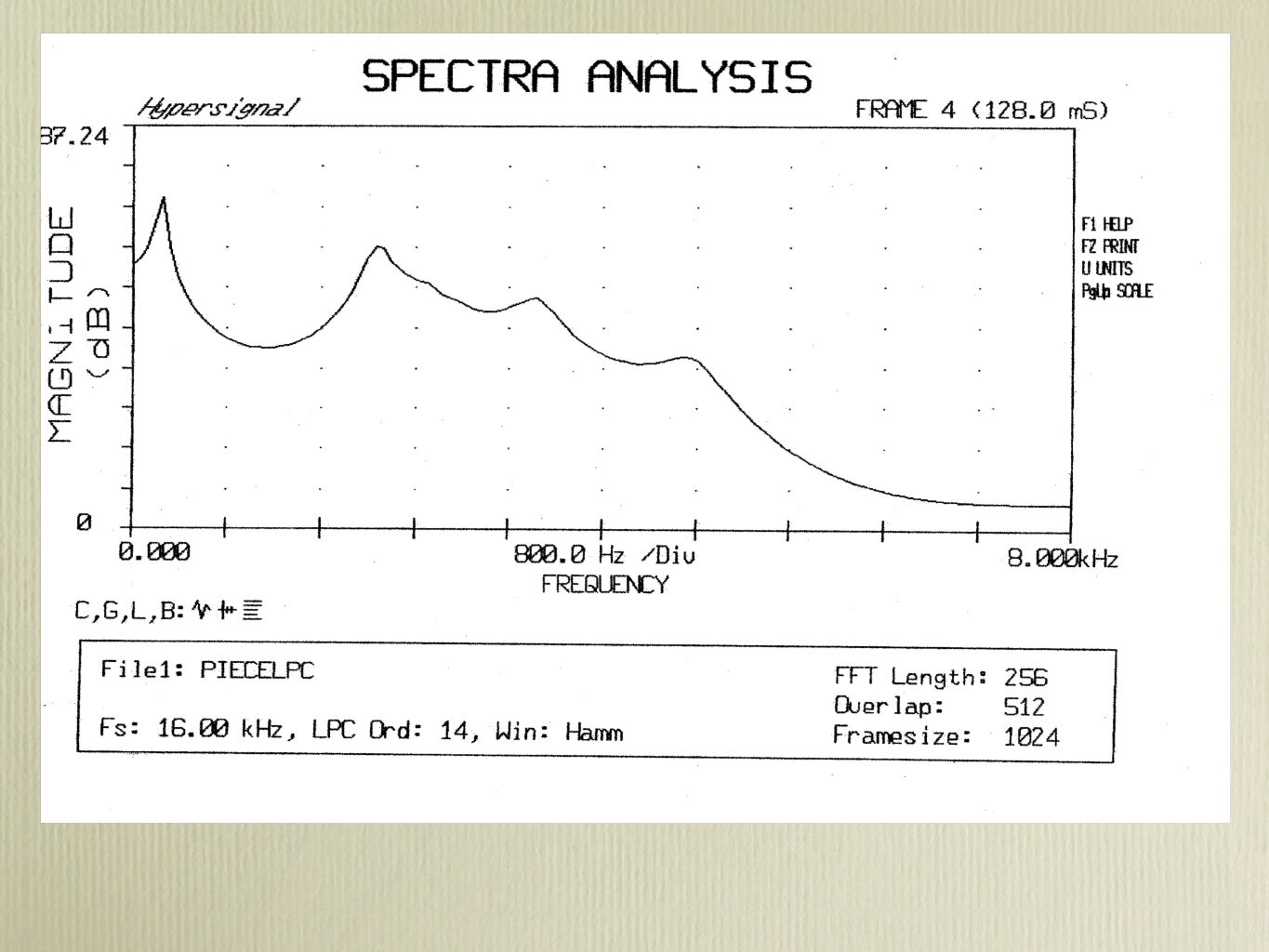
Digital Spectrograph This is a series of spectra based on the FFT or LPC (see below) The amplitude is depicted as shades of gray PRAAT is an example of a digital spectrograph Speech Filing System, Speech Station 2, Wavesurfer, and many other free or commercially spectrographs are available This is a series of spectra based on the FFT or LPC (see below) The amplitude is depicted as shades of gray PRAAT is an example of a digital spectrograph Speech Filing System, Speech Station 2, Wavesurfer, and many other free or commercially spectrographs are available
 The amplitude is depicted as shades of gray PRAAT is an example of a digital spectrograph Speech Filing System, Speech Station 2, Wavesurfer, and many other free or commercially spectrographs are available This is a series of spectra based on the FFT or LPC (see below) The amplitude is depicted as shades of gray PRAAT is an example of a digital spectrograph Speech Filing System, Speech Station 2, Wavesurfer, and many other free or commercially spectrographs are available")
19
Linear Predictive Coding (1) Speech is highly predictable over the short term It is not hard to predict the amplitude of the next time sample of the speech waveform from a knowledge of the previous amplitudes As few as 10 to 15 previous samples is all that is required Speech is highly predictable over the short term It is not hard to predict the amplitude of the next time sample of the speech waveform from a knowledge of the previous amplitudes As few as 10 to 15 previous samples is all that is required
 Speech is highly predictable over the short term It is not hard to predict the amplitude of the next time sample of the speech waveform from a knowledge of the previous amplitudes As few as 10 to 15 previous samples is all that is required Speech is highly predictable over the short term It is not hard to predict the amplitude of the next time sample of the speech waveform from a knowledge of the previous amplitudes As few as 10 to 15 previous samples is all that is required")
20
LPC (2) From statistics, we know that: y= a0+a1(x-1)+a2(x-2)+...+an(x-n) where y is the amplitude of the next sample and x is one of the previous samples This is linear prediction From statistics, we know that: y= a0+a1(x-1)+a2(x-2)+...+an(x-n) where y is the amplitude of the next sample and x is one of the previous samples This is linear prediction
 From statistics, we know that: y= a0+a1(x-1)+a2(x-2)+...+an(x-n) where y is the amplitude of the next sample and x is one of the previous samples This is linear prediction From statistics, we know that: y= a0+a1(x-1)+a2(x-2)+...+an(x-n) where y is the amplitude of the next sample and x is one of the previous samples This is linear prediction")
21
LPC (3) Linear Predictive Coding (LPC) is one of the most powerful techniques in speech analysis The a’s in the previous equation can be used as estimates of the resonances of the vocal tract. They can represent sections of the vocal tract Linear Predictive Coding (LPC) is one of the most powerful techniques in speech analysis The a’s in the previous equation can be used as estimates of the resonances of the vocal tract. They can represent sections of the vocal tract
 is one of the most powerful techniques in speech analysis The a’s in the previous equation can be used as estimates of the resonances of the vocal tract. They can represent sections of the vocal tract.")
24
Wideband versus Narrowband Spectrograms Wideband (0.005, 0.007, 0.009) Short time window Good for measuring formant frequencies Narrowband (0.1, 0.05) Long time window Good for showing and measuring harmonics Wideband (0.005, 0.007, 0.009) Short time window Good for measuring formant frequencies Narrowband (0.1, 0.05) Long time window Good for showing and measuring harmonics
 Short time window Good for measuring formant frequencies Narrowband (0.1, 0.05) Long time window Good for showing and measuring harmonics Wideband (0.005, 0.007, 0.009) Short time window Good for measuring formant frequencies Narrowband (0.1, 0.05) Long time window Good for showing and measuring harmonics")
Similar presentations









 2 ©Paul Godin Created April 2008.>")







 Source-Filter Theory of Speech Production Capturing Speech Dynamics The Vowels The Diphthongs.>")


