Download presentation
Presentation is loading. Please wait.

1
17th EPIET introductory course Lazareto, Menorca, Spain
Sampling 17th EPIET introductory course Lazareto, Menorca, Spain Ioannis Karagiannis & Biagio Pedalino Based on previous EPIET intro courses

2
Objectives: sampling To understand: Why we use sampling
Definitions in sampling Concept of representativity Main methods of sampling Sampling errors

3
Definition of sampling
Procedure by which some members of a given population are selected as representatives of the entire population in terms of the desired characteristics Sampling is the use of a subset of the population to represent the whole population, in order to extrapolate the study results to the population from which the sample is drawn.

4
Why bother in the first place?
Get information from large populations with: Reduced costs Reduced field time Increased accuracy Why do we use sampling? We want to obtain information from large populations at: Reduced costs Reduced field time Increased accuracy

5
Definition of sampling terms
Sampling unit (element) Subject under observation on which information is collected Example: children <5 years, hospital discharges, health events… Sampling fraction Ratio between sample size and population size Example: 100 out of 2000 (5%) There are several terms used in sampling which are important to understand: First the sampling unit or element of sampling: The sampling unit is the subject under observation on which information is collected, for example: children <5 years, hospital discharges, health events… Secondly, the sampling fraction is the ratio between sample size and population size, for example: 100 out of 2000 (5%)
 Subject under observation on which information is collected. Example: children <5 years, hospital discharges, health events… Sampling fraction. Ratio between sample size and population size. Example: 100 out of 2000 (5%) There are several terms used in sampling which are important to understand: First the sampling unit or element of sampling: The sampling unit is the subject under observation on which information is collected, for example: children <5 years, hospital discharges, health events… Secondly, the sampling fraction is the ratio between sample size and population size, for example: 100 out of 2000 (5%)")
6
Definition of sampling terms
Sampling frame List of all the sampling units from which sample is drawn Lists: e.g. all children < 5 years of age, households, health care units… Sampling scheme Method of selecting sampling units from sampling frame Randomly, convenience sample… To choose the sampling units you will need a sampling frame, which is a list of all the sampling units from which sample is drawn, for example all children < 5 years of age, households, health care units… And finally the sampling scheme is the method of selecting sampling units from sampling frame, for example randomly, convenience sample…

7
Survey errors Systematic error (or bias) Sampling error (random error)
Representativeness (validity) Information bias Sampling error (random error) Precision Before I will present the different sampling schemes or methods, I would like to mention some of the survey errors. First of all, your study can have a systematic error (or bias). This would be the case when your sample is not typical of the population you are looking at. This could happen through obtaining inaccurate response (information bias) or selecting people not representative of the population you are studying. A Sampling error or random error could also be possible.
 Information bias. Sampling error (random error) Precision. Before I will present the different sampling schemes or methods, I would like to mention some of the survey errors. First of all, your study can have a systematic error (or bias). This would be the case when your sample is not typical of the population you are looking at. This could happen through obtaining inaccurate response (information bias) or selecting people not representative of the population you are studying. A Sampling error or random error could also be possible.")
8
Validity Sample should accurately reflect the distribution of relevant variable in population Person (age, sex) Place (urban vs. rural) Time (seasonality) Representativeness essential to generalise Ensure representativeness before starting Confirm once completed Our sample should accurately reflect the distribution of relevant variables in the population, regarding person (age, sex), place e.g. urban vs. rural and time e.g. seasonality. Is this the case for my example? The representativeness is essential to be able to generalise our results. We should ensure that our sample is representative before starting and confirm once completed the sampling
 Time (seasonality) Representativeness essential to generalise. Ensure representativeness before starting. Confirm once completed. Our sample should accurately reflect the distribution of relevant variables in the population, regarding person (age, sex), place e.g. urban vs. rural and time e.g. seasonality. Is this the case for my example The representativeness is essential to be able to generalise our results. We should ensure that our sample is representative before starting and confirm once completed the sampling.")
9
Information bias Systematic problem in collecting information
Inaccurate measuring Scales (weight), ultrasound, lab tests (dubious results) Badly asked questions Ambiguous, not offering right options… Systematic problem in collecting information Inaccurate measuring Scales, ultrasound, lab tests… Badly asked questions Ambiguous, not offering right options…
, ultrasound, lab tests (dubious results) Badly asked questions. Ambiguous, not offering right options… Systematic problem in collecting information. Inaccurate measuring. Scales, ultrasound, lab tests… Badly asked questions. Ambiguous, not offering right options…")
10
Sampling error (random error)
No sample is an exact mirror image of the population Standard error depends on size of the sample distribution of character of interest in population Size of error can be measured in probability samples standard error Even if we have made sure that we have a representative sample, we can have a sampling error. Was does this mean? We should not forget that our sample is just a gross reflection of the reality. There will always be a random difference between our sample and the population from which the sample was drawn. This is also what we mean with precision. So the five persons I have chosen as my sample might not completely reflect all participants. Even if I have about the same age and gender distribution, it will not be exactly the same. We can measure the size of the sampling error in probability samples, and this is expressed by standard error of mean, proportion, differences, etc The size of the sampling error depends on the sample size (the bigger the sample, the smaller the error). Also the sampling error depends upon how often a characteristic is present in the population. For very rare characteristics we might need to aim for a better sample error or precision.
. Also the sampling error depends upon how often a characteristic is present in the population. For very rare characteristics we might need to aim for a better sample error or precision.")
11
Survey errors: example
Measuring height: Measuring tape held differently by different investigators → loss of precision → large standard error Tape too short → systematic error → bias (cannot be corrected retrospectively) Just to illustrate this by an example: We would like to measure the height of all participants of this course. We have one tape which we would use. All facilitators will be asked to measure the height of the participants in their group. Some facilitators will hold the tape to the right, the others to the left, so that even when they take the height of the same person, they would end up having different numbers. This would correspond to the standard error. However, if some of us are using an incorrect tape, which is actually not 2 m but only 1,98 m we will have a systematic error and our results will be biased in one direction. We will not be able to correct this after we took the measurements. Is that clear?
 Just to illustrate this by an example: We would like to measure the height of all participants of this course. We have one tape which we would use. All facilitators will be asked to measure the height of the participants in their group. Some facilitators will hold the tape to the right, the others to the left, so that even when they take the height of the same person, they would end up having different numbers. This would correspond to the standard error. However, if some of us are using an incorrect tape, which is actually not 2 m but only 1,98 m we will have a systematic error and our results will be biased in one direction. We will not be able to correct this after we took the measurements. Is that clear")
12
Types of sampling Non-probability samples Probability samples
Convenience samples Biased Subjective samples Based on knowledge In the presence of time/resource constraints Probability samples Random only method that allows valid conclusions about population and measurements of sampling error There are two types of sampling, the non-probability samples and the probability samples which ensures each sampling unit has the same chance to be selected. In this presentation, we will focus on probability sampling techniques. 12

13
Non-probability samples
Convenience samples (ease of access) Snowball sampling (friend of friend….etc.) Purposive sampling (judgemental) You chose who you think should be in the study Normally sample should reflect the population structure. A convenience sample does not! In a convenience sample some persons have a higher chance of being sampled than others. For example, if we choose people on the main shopping street as a sample for a city ward, those who are frequently doing their shopping there are at higher risk of being chosen than those working during the day, bedridden Nonprobability sampling techniques cannot be used to infer from the sample to the general population. Any generalizations obtained from a nonprobability sample must be filtered through one's knowledge of the topic being studied. Performing nonprobability sampling is considerably less expensive than doing probability sampling, but the results are of limited value. Examples of nonprobability sampling include: Convenience sampling - members of the population are chosen based on their relative ease of access. To sample friends, co-workers, or shoppers at a single mall, are all examples of convenience sampling. Snowball sampling - The first respondent refers a friend. The friend also referes a friend, etc. Judgmental sampling or Purposive sampling - The researcher chooses the sample based on who they think would be appropriate for the study. This is used primarily when there is a limited number of people that have expertise in the area being researched. Case study - The research is limited to one group, often with a similar characteristic or of small size. ad hoc quotas - A quota is established (say 65% women) and researchers are free to choose any respondent they wish as long as the quota is met Even studies intended to be probability studies sometimes end up being non-probability studies due to unintentional or unavoidable characteristics of the sampling method. In public opinion polling by private companies (or organizations unable to require response), the sample can be self-selected rather than random. This often introduces an important type of error: self-selection error. This error sometimes makes it unlikely that the sample will accurately represent the broader population. Volunteering for the sample may be determined by characteristics such as submissiveness or availability. The samples in such surveys should be treated as non-probability samples of the population, and the validity of the estimates of parameters based on them unknown Probability of being chosen is unknown Cheaper- but unable to generalise, potential for bias
 Snowball sampling (friend of friend….etc.) Purposive sampling (judgemental) You chose who you think should be in the study. Normally sample should reflect the population structure. A convenience sample does not! In a convenience sample some persons have a higher chance of being sampled than others. For example, if we choose people on the main shopping street as a sample for a city ward, those who are frequently doing their shopping there are at higher risk of being chosen than those working during the day, bedridden. Nonprobability sampling techniques cannot be used to infer from the sample to the general population. Any generalizations obtained from a nonprobability sample must be filtered through one s knowledge of the topic being studied. Performing nonprobability sampling is considerably less expensive than doing probability sampling, but the results are of limited value. Examples of nonprobability sampling include: Convenience sampling - members of the population are chosen based on their relative ease of access. To sample friends, co-workers, or shoppers at a single mall, are all examples of convenience sampling. Snowball sampling - The first respondent refers a friend. The friend also referes a friend, etc. Judgmental sampling or Purposive sampling - The researcher chooses the sample based on who they think would be appropriate for the study. This is used primarily when there is a limited number of people that have expertise in the area being researched. Case study - The research is limited to one group, often with a similar characteristic or of small size. ad hoc quotas - A quota is established (say 65% women) and researchers are free to choose any respondent they wish as long as the quota is met. Even studies intended to be probability studies sometimes end up being non-probability studies due to unintentional or unavoidable characteristics of the sampling method. In public opinion polling by private companies (or organizations unable to require response), the sample can be self-selected rather than random. This often introduces an important type of error: self-selection error. This error sometimes makes it unlikely that the sample will accurately represent the broader population. Volunteering for the sample may be determined by characteristics such as submissiveness or availability. The samples in such surveys should be treated as non-probability samples of the population, and the validity of the estimates of parameters based on them unknown. Probability of being chosen is unknown. Cheaper- but unable to generalise, potential for bias.")
14
Example of a non-probability sample
Take a sample of the population of a Greek island to ask about possible exposures following a gastroenteritis outbreak Sampling frame: people walking around the port at high noon on a Monday

15
…we ended up interviewing only two locals!

16
Probability samples Random sampling
Each unit has a known probability of being selected Allows application of statistical sampling theory to results in order to: Generalise Test hypotheses Let’s look at the probability samples Random sampling Each subject has a known probability of being selected Allows application of statistical sampling theory to results to: Generalise Test hypotheses

17
Methods used in probability samples
Simple random sampling Systematic sampling Stratified sampling Multi-stage sampling Cluster sampling There are several ways of performing random sampling and I will present you the following: Simple random sampling Systematic sampling Stratified sampling Multi-stage sampling Cluster sampling

18
Simple random sampling
Principle Equal chance/probability of each unit being drawn Procedure Take sampling population Need listing of all sampling units (“sampling frame”) Number all units Randomly draw units Simple random sampling In a simple random sampling, there is an equal chance/probability of drawing each unit. X has the same probability as y to be chosen. The Procedure is simple: Take the sampling population, establish a listing of all sampling units (“sampling frame”), number all units and randomly draw units
 Number all units. Randomly draw units. Simple random sampling. In a simple random sampling, there is an equal chance/probability of drawing each unit. X has the same probability as y to be chosen. The Procedure is simple: Take the sampling population, establish a listing of all sampling units ( sampling frame ), number all units and randomly draw units.")
19
Simple random sampling
Advantages Simple Sampling error easily measured Disadvantages Need complete list of units Units may be scattered and poorly accessible Heterogeneous population important minorities might not be taken into account The advantages are that the method is simple and the sampling error easily measured. The disadvantages are that you need complete list of units. This can be a problem. Here in the course we have the total list, but what when you need to sample from a larger population? Where do you get the listing from? Also, this method does not always achieve the best representativeness, e.g telephone numbers- is everyone in the telephone book? Are there people without phones? Or non-functioning phones… Or the population registry. Is it up to date? If we are not using telephones but door-to-door interviews: The units may be scattered and poorly accessible. Because units may be scattered may be more time consuming to perform the study.

20
Systematic sampling Principle Procedure
Select sampling units at regular intervals (e.g. every 20th unit) Procedure Arrange the units in some kind of sequence Divide total sampling population by the designated sample size (eg 1200/60=20) Choose a random starting point (for 20, the starting point will be a random number between 1 and 20) Select units at regular intervals (in this case, every 20th unit), i.e. 4th, 24th, 44th etc. For convenience, selection from the sampling frame is sometimes carried out systematically rather than randomly, by taking individuals at regular intervals down the list. The principle of systematic sampling is to select sampling units at regular intervals. The process for drawing a systematic sample is as follows: You arrange the units in some kind of sequence Divide the total sampling population by the sample size (say 1200/60=20) Choose a random starting point (e.g. for 20 the starting point will be chosen randomly from 1 to 20) Select units at regular intervals (for 20 this will be every 20th unit). The advantages are that it is simple to do and the sampling error can be easily measured. The disadvantages are that you need a complete list of units. If this list of units is not well mixed and there may be an underlying pattern in the sampling frame, eg. if we choose every second person in this room and men-women are always seated in the same order, the second person will be only eg. women. So if the sampling units are grouped such that particular characteristics occur at regular intervals, bias can occur. 20
 Procedure. Arrange the units in some kind of sequence. Divide total sampling population by the designated sample size (eg 1200/60=20) Choose a random starting point (for 20, the starting point will be a random number between 1 and 20) Select units at regular intervals (in this case, every 20th unit), i.e. 4th, 24th, 44th etc. For convenience, selection from the sampling frame is sometimes carried out systematically rather than randomly, by taking individuals at regular intervals down the list. The principle of systematic sampling is to select sampling units at regular intervals. The process for drawing a systematic sample is as follows: You arrange the units in some kind of sequence. Divide the total sampling population by the sample size (say 1200/60=20) Choose a random starting point (e.g. for 20 the starting point will be chosen randomly from 1 to 20) Select units at regular intervals (for 20 this will be every 20th unit). The advantages are that it is simple to do and the sampling error can be easily measured. The disadvantages are that you need a complete list of units. If this list of units is not well mixed and there may be an underlying pattern in the sampling frame, eg. if we choose every second person in this room and men-women are always seated in the same order, the second person will be only eg. women. So if the sampling units are grouped such that particular characteristics occur at regular intervals, bias can occur. 20.")
21
Systematic sampling Advantages Disadvantages
Ensures representativity across list Easy to implement Disadvantages Need complete list of units Periodicity-underlying pattern may be a problem (characteristics occurring at regular intervals) The advantages are that the method is simple and the sampling error easily measured. -The disadvantages are that you need complete list of units. This can be a problem eg in a country with no census data or central population register. -The population may be widely dispersed and so a simple random sample would be impractical, time-consuming and costly (e.g. in an Afriacan country with remote villages and bad roads, a simple random sample would require much travelling to sample a few individuals from many remote villages). -If the population is made up of different types of groups (eg small minorities, a simple random will not be representative of the population- unless you have a very large number) Also, this method does not always achieve the best representativeness, e.g telephone numbers- is everyone in the telephone book? Are there people without phones? Or non-functioning phones… Or the population registry. Is it up to date? 21
 The advantages are that the method is simple and the sampling error easily measured. -The disadvantages are that you need complete list of units. This can be a problem eg in a country with no census data or central population register. -The population may be widely dispersed and so a simple random sample would be impractical, time-consuming and costly (e.g. in an Afriacan country with remote villages and bad roads, a simple random sample would require much travelling to sample a few individuals from many remote villages). -If the population is made up of different types of groups (eg small minorities, a simple random will not be representative of the population- unless you have a very large number) Also, this method does not always achieve the best representativeness, e.g telephone numbers- is everyone in the telephone book Are there people without phones Or non-functioning phones… Or the population registry. Is it up to date 21.")
22
More complex sampling methods

23
Stratified sampling When to use Procedure
Population with distinct subgroups Procedure Divide (stratify) sampling frame into homogeneous subgroups (strata) e.g. age-group, urban/rural areas, regions, occupations Draw random sample within each stratum Stratified sampling is used when the population is made up of groups with different characteristics and expected big differences in the feature under study (eg minorities, urban/rural areas). Simple random sample will not be representative of the population, unless you have a very large sample.This is because the big differences that may occur between the separate groups will cause more variation in the overal estimate and it will be less precise. Eg. to estimate the prevalence of nosocomial infections, I can stratify by wards which have different levels of risk for hospital-acquired infections. We divide the sampling frame into homogeneous subgroups (strata) that have common characteristics e.g. age-group, occupation, area of residence; We draw a random sample in each stratum. In most situations, the number of people in each subgroup will not be the same. To ensure that all subjects have the same chance of being selected, the same proportion of subjects should be sampled from each group. In other words, the same sampling fraction is used in each stratum. 23
 sampling frame into homogeneous subgroups (strata) e.g. age-group, urban/rural areas, regions, occupations. Draw random sample within each stratum. Stratified sampling is used when the population is made up of groups with different characteristics and expected big differences in the feature under study (eg minorities, urban/rural areas). Simple random sample will not be representative of the population, unless you have a very large sample.This is because the big differences that may occur between the separate groups will cause more variation in the overal estimate and it will be less precise. Eg. to estimate the prevalence of nosocomial infections, I can stratify by wards which have different levels of risk for hospital-acquired infections. We divide the sampling frame into homogeneous subgroups (strata) that have common characteristics e.g. age-group, occupation, area of residence; We draw a random sample in each stratum. In most situations, the number of people in each subgroup will not be the same. To ensure that all subjects have the same chance of being selected, the same proportion of subjects should be sampled from each group. In other words, the same sampling fraction is used in each stratum. 23.")
24
Selecting a sample with probability proportional to size
Stratified sampling Selecting a sample with probability proportional to size Area Population Proportion Sample size Sampling size fraction Urban % 1000 x 0.7 = 700 10 % Rural % 1000 x 0.3 = 300 10 % 1000 Total 24

25
Stratified sampling Advantages Disadvantages
Can acquire information about whole population and individual strata Precision increased if variability within strata is smaller (homogenous) than between strata Disadvantages Sampling error is difficult to measure Different strata can be difficult to identify Loss of precision if small numbers in individual strata (resolved by sampling proportional to stratum population) The advantages of stratified sampling are that you can acquire information about whole population and individual strata. The precision will increase if variability within strata is less (homogenous) than between strata Disadvantages Can be difficult to identify strata Loss of precision if small numbers in individual strata resolve by sampling proportionate to stratum population 25
 than between strata. Disadvantages. Sampling error is difficult to measure. Different strata can be difficult to identify. Loss of precision if small numbers in individual strata (resolved by sampling proportional to stratum population) The advantages of stratified sampling are that you can acquire information about whole population and individual strata. The precision will increase if variability within strata is less (homogenous) than between strata. Disadvantages. Can be difficult to identify strata. Loss of precision if small numbers in individual strata. resolve by sampling proportionate to stratum population. 25.")
27
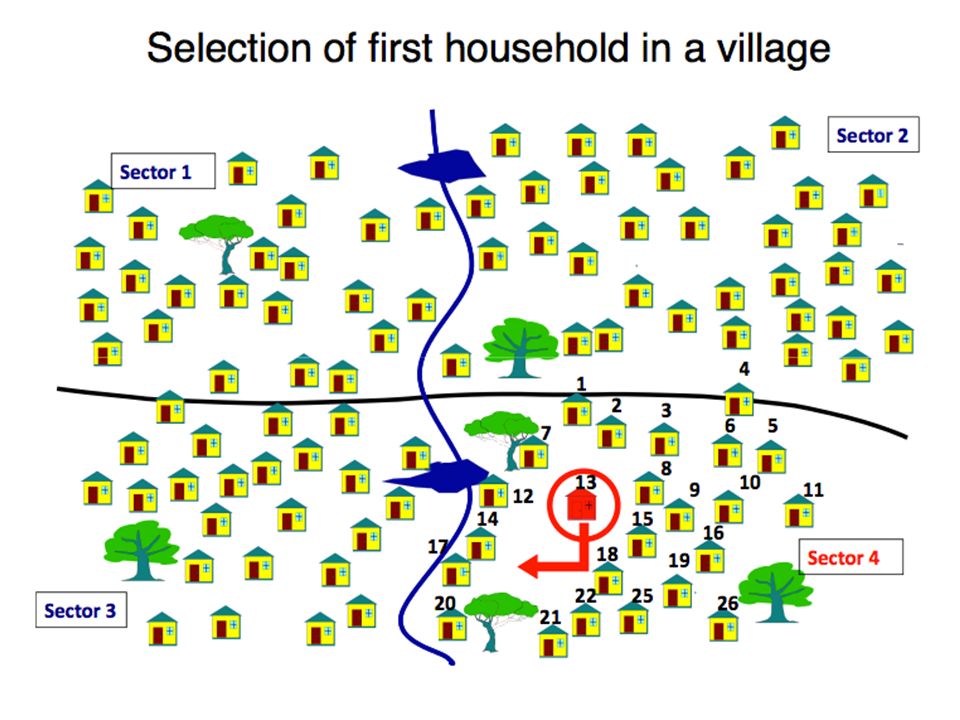
Multiple stage sampling
Principle: Consecutive sampling Example : sampling unit = household 1st stage: draw neighbourhoods 2nd stage: draw buildings 3rd stage: draw households Principle: consecutive sampling example : sampling unit = household 1st stage: draw neighborhoods 2nd stage: draw buildings 3rd stage: draw households 8

28
Cluster sampling Principle
Whole population divided into groups e.g. neighbourhoods A type of multi-stage sampling where all units at the lower level are included in the sample Random sample taken of these groups (“clusters”) Within selected clusters, all units e.g. households included (or random sample of these units) Provides logistical advantage Principle Whole population divided into groups e.g. neighbourhoods Random sample taken of these groups (“clusters”) Within selected clusters, all units e.g. households included (or random sample of these units)
 Within selected clusters, all units e.g. households included (or random sample of these units) Provides logistical advantage. Principle. Whole population divided into groups e.g. neighbourhoods. Random sample taken of these groups ( clusters ) Within selected clusters, all units e.g. households included (or random sample of these units)")
34
Stage 3: Selection of the sampling unit
Second-stage units => Households Third-stage unit => Individuals 34

35
All third-stage units might be included in the sample
Stage 3: Selection of the sampling unit All third-stage units might be included in the sample 35

36
Cluster sampling Advantages
Simple as complete list of sampling units within population not required Less travel/resources required Disadvantages Cluster members may be more alike than those in another cluster (homogeneous) this “dependence” needs to be taken into account in the sample size and in the analysis (“design effect”) Advantages Simple as complete list of sampling units within population not required Less travel/resources required Disadvantages Potential problem is that cluster members are more likely to be alike, than those in another cluster (homogeneous)…. This “dependence” needs to be taken into account in the sample size….and the analysis (“design effect”)
 this dependence needs to be taken into account in the sample size and in the analysis ( design effect ) Advantages. Simple as complete list of sampling units within population not required. Less travel/resources required. Disadvantages. Potential problem is that cluster members are more likely to be alike, than those in another cluster (homogeneous)…. This dependence needs to be taken into account in the sample size….and the analysis ( design effect )")
37
Selecting a sampling method
Population to be studied Size/geographical distribution Heterogeneity with respect to variable Availability of list of sampling units Level of precision required Resources available Which one is the right sampling method? This depends first on the population to be studied: How large is the target population? Small population you can use a simple random sampling, for a large population you mkight need more sophisticated methods. Also, a population scattered in remote areas will require a different sampling method that the population of a large city. If you expect a large heterogeneity regarding your variable of interest, you may have to choose a stratified sample. It also depends on the availability of a list of sampling units, the level of precision required and last but not least the resources available.

38
Conclusions Probability samples are the best Ensure
Validity Precision …..within available constraints

39
Conclusions If in doubt… Call a statistician !!!!

40
Acknowledgements Thomas Grein Denis Coulombier Philippe Sudre
Mike Catchpole Denise Antona Brigitte Helynck Philippe Malfait Previous presenters

Similar presentations









 Chapter 7, Part B Sampling and Sampling Distributions Other Sampling Methods Other.>")









 RTI, JAIPUR1 STATISTICAL SAMPLING Presented By RTI, JAIPUR.>")




