Download presentation
Presentation is loading. Please wait.

1
Evolutionary and Agent-based Search / Exploration in Chemical Library and De Novo Design Ian Parmee Advanced ComputationalTechnologies (ACT) and Bristol UWE
 and Bristol UWE")
2
Early design characterised by: human-centric concept formulation and development ; uncertainty due to lack of data / information / knowledge and poor problem definition; correspondingly low-fidelity computational representation (if any, initially); Design activity extends across multiple domains and disciplines. Current CAD characterised by: low-level, inflexible user interaction; need for high product definition; high-fidelity design representation; CAD is domain-specific – does not exploit cross-domain experience.

3
Interdisciplinary knowledge and expertise can help us understand highly complex, multi- layered generic relationships inherent within decision-making processes Degree of human-based subjective evaluation required during early design and decision-making process where uncertainty and associated risk are prime characteristics. - INHERENTLY PEOPLE-CENTRED PROCESSES -

4
Fundamentally human-based activities but small increases in problem complexity result in numbers of possible alternatives rapidly moving beyond our cognitive capabilities. Advanced generic computational environments required that support comparative assessment whilst user maintains an integral, significant role. Such systems may, for instance, capture and utilise human knowledge and experience to better define machine-based problem representation. Over-automation, human exclusion and associated loss of valuable and essential information must be avoided

5
Interactive Intelligent Systems for Design Major potential – one aspect - use of EC algorithms as gatherers of optimal / high-quality design information Info can be collated and integrated with human- based decision-making processes. Approach can capture designer experiential knowledge and intuition within further evolutionary search – knowledge discovery. Supports exploration outside of initial constraint, objective and variable bounds

6
Iterative designer/machine-based refinement of design space. Provide succinct graphical representation of complex relationships from various perspectives. Immersive system? - designer part of iterative loop

7
Preliminary military airframe – BAE Systems Characterised by uncertain requirements and fuzzy objectives Long gestation periods between initial design brief and realisation of product. Changes in operational requirements + technological advances Demand for responsive, highly flexible strategy - design change / compromise inherent features.

8
Cluster-oriented Genetic Algorithms COGAs identify high performance regions of complex preliminary / conceptual design spaces Approach can be utilised to generate highly relevant design information relating to single, multi-objective and constrained problem domains

9
Cluster Oriented genetic Algorithm Initially built for multimodal continuous spaces Stochastic Evolutionary approach Inspired by identifying multiple high performing regions Adaptive filtering for continuous extraction of high performing regions FCS

10
Good solution set cover of identified regions supports extraction of relevant design information Information mined, processed and presented to the designer in succinct graphics. Info relates to: Solution robustness, revision of variable ranges, conversion from variable to fixed parameters, degree of objective conflict, sensitivity of objectives to each variable Solutions describing HP regions can be projected onto any 2D variable hyperplane:

12
Single objectiveMultiple objectives Projection of COGA single and multi-objective output on 2D variable hyperplanes ( data from nine variable problem ) Not feasible to search through all 2D hyperplanes – single graphic required.
 Not feasible to search through all 2D hyperplanes – single graphic required.")
13
Combination of Box Plot representation and Parallel Co-ordinates relating to all objectives contains several layers of design information Developed Parallel Co-ordinate Box Plot –PCBP [Parmee and Johnson, 2004] provides all information in single graphic:
![Combination of Box Plot representation and Parallel Co-ordinates relating to all objectives contains several layers of design information Developed Parallel Co-ordinate Box Plot –PCBP [Parmee and Johnson, 2004] provides all information in single graphic:](http://images.slideplayer.com/24/7378337/slides/slide_13.jpg "Combination of Box Plot representation and Parallel Co-ordinates relating to all objectives contains several layers of design information Developed Parallel Co-ordinate Box Plot –PCBP [Parmee and Johnson, 2004] provides all information in single graphic:")
14
PCBP of solution distribution of each objective across each variable

16
Utilising PCBP Information Using information available within the PCBP designer can: i)Identify variables least affecting solution performance across full set of objectives (i.e. variables where full axes relating to each objective overlap e.g. 1, 2, 3, 6, & 9). ii) Further identify minimum objective conflict i.e. where box plots relating to each objective largely overlap iii) Identify conflicting objectives - evident from diverse distribution of box plots along some axes
. ii) Further identify minimum objective conflict i.e. where box plots relating to each objective largely overlap iii) Identify conflicting objectives - evident from diverse distribution of box plots along some axes.")
17
iv) View related variable hyperplane projections for a different perspective of spatial distribution of objectives’ high-performance regions Access to such hyperplanes driven by simple clicking operations on selected variable axes v) View projections of high-performance regions on objective space – direct mapping between variable and objective space
 View related variable hyperplane projections for a different perspective of spatial distribution of objectives’ high-performance regions Access to such hyperplanes driven by simple clicking operations on selected variable axes v) View projections of high-performance regions on objective space – direct mapping between variable and objective space")
18
Projection of ATR / FR regions on objective space

19
vi) View approximate Pareto frontiers generated from the non- dominated sorting of HP region solutions Distribution of solutions for objective ATR1 and FR against SPEA-II Pareto front Distribution of solutions for objective ATR1 and SEP1 against SPEA-II Pareto front.
 View approximate Pareto frontiers generated from the non- dominated sorting of HP region solutions Distribution of solutions for objective ATR1 and FR against SPEA-II Pareto front Distribution of solutions for objective ATR1 and SEP1 against SPEA-II Pareto front.")
20
Approximate Pareto frontiers generated through non-dominated solution sorting within the objectives’ HP regions Pareto approximations are all that are required during conceptual design COGA potentially offers more information than standard Pareto based methods

21
Relaxing the COGA adaptive filter allows lower performance solutions into the HP regions and ‘closes the gap’ in the approximate Ferry Range / Specific Excess Power Pareto front – also results in mutually inclusive region between all three objectives

22
Off-line analysis of search data supports iterative designer/machine-based refinement of design space. Immersive system? - designer part of iterative loop Effect upon emerging solutions identified during iterative development of design space.

23
Transferring this Technology into Drug Design Processes Drug design involves synthesis of small subset of compounds (focussed libraries) from many possibilities assembled from available reagents In collaboration with Evotec OAI We have developed COGA approaches to aid the selection of compounds for synthesis using in silico models for specific drug characteristics
 from many possibilities assembled from available reagents In collaboration with Evotec OAI We have developed COGA approaches to aid the selection of compounds for synthesis using in silico models for specific drug characteristics")
24
Motivation Accelerate the process of finding potential drug candidate molecules (leads) Finding such leads will improve hit rate during actual assaying (HTS) A desktop tool will facilitate knowledge discovery through mining of high quality information related to i) complex reagent interaction & ii) Objective sensitivities
 Finding such leads will improve hit rate during actual assaying (HTS) A desktop tool will facilitate knowledge discovery through mining of high quality information related to i) complex reagent interaction & ii) Objective sensitivities")
25
Initial Project Aims To assess utility of evolutionary engineering design techniques and strategies within a drug design environment. To appropriately modify and develop those techniques and strategies offering best potential. To integrate developed techniques with multiparameter medicinal chemistry optimisation.

26
Methodology Cluster Oriented Genetic Algorithm (Search and exploratory tool) Experimentations with SIMILARITY, QSAR-SOL, QSAR-LOGP, Docking etc Constraint Handling Preference Based Multi-Objective approach
 Experimentations with SIMILARITY, QSAR-SOL, QSAR-LOGP, Docking etc Constraint Handling Preference Based Multi-Objective approach")
27
Experimental Set Up Target molecule Aromatic Acid (R1) + Primary Amine (R2) Amino Acids CN(Cc1cnc2nc(N)nc(N)c2n1)c3ccc(cc3)C(=O)NC(CCC(O)=O)C(O)=O * Independent variables = 2 * Search Space size = 400 x 400
 + Primary Amine (R2) Amino Acids CN(Cc1cnc2nc(N)nc(N)c2n1)c3ccc(cc3)C(=O)NC(CCC(O)=O)C(O)=O * Independent variables = 2 * Search Space size = 400 x 400")
28
Now necessary to search across extensive, highly discrete spaces described by reagent combinations. COGA concepts have been introduced - major modification in terms of basic representation and genetic operators that further promote exploration. Range of in-silico objective functions have been utilised (e.g. similarity, QSAR, docking etc)
.")
29
Two deliverables required from the developed software: i) Identification of individual best-performing reagent combinations across range of objectives and in terms of a pre-defined target – Optimisation. ii) Identification of those reagents that offer best potential in terms of a range of objectives and a pre-defined target leading to development of focussed libraries - Search and Exploration
 Identification of those reagents that offer best potential in terms of a range of objectives and a pre-defined target leading to development of focussed libraries - Search and Exploration.")
30
Generation of Focussed Libraries Development of additional search heuristics to ensure that COGA identifies as many high-performance reactants as possible in a robust manner whilst minimising the number of evaluations required. Test set comprising fully enumerated 400x400 Library (Primary Amines + Aromatic Acids) used as benchmark in studies. 160,000 possible molecules. Fitness function = Tanimoto Similarity
 used as benchmark in studies. 160,000 possible molecules. Fitness function = Tanimoto Similarity.")
31
Characteristic Landscape SIMILARITY (400 x 400) …(top 0.05% solutions) Contour of top 0.05% solutionslandscape
 …(top 0.05% solutions) Contour of top 0.05% solutionslandscape")
32
Top 0.05% solutions in 400x400 library identified by exhaustive search and enumeration – emergence of high performance (HP) axes relating to particular reactants
 axes relating to particular reactants")
33
Plot of FCS solutions of a typical COGA search of the test library. On average COGA identified ~200 solutions out of the best 800 (top 0.05% )
.")
34
Developed heuristics to improve exploratory capabilities include various tabu lists that monitor number of visits to high perfomance axis and reassign solutions when cover of a particular high performance axis is considered adequate in terms of number and distribution of solutions. Various strategies for the replacement of ‘tabu’ solutions to promote further sampling / exploration of the reagent space. Extensive experimentation.

35
Results from fifty runs of COGA with developed heuristics – very significant increase in number of HP axes and top end solutions identified. Relatively robust performance – significant improvement.

36
Increasing Dimension: Moving away from initial test set - COGA (with heuristics) applied to 3 reagent library comprising primary amines, aromatic acids and aldehydes. Total size = 400 x 400 x 400 (64 x 10 6 ) reactant combinations. Focussed library approach again using chemical similarity against methotraxate as a criteria was introduced.
 reactant combinations. Focussed library approach again using chemical similarity against methotraxate as a criteria was introduced..")
37
COGA output for identifying high-performance Reagents for inclusion in focussed libraries (3 Reagents):
:")
38
Constraint Satisfaction Number of constraints have been included: molecular weight hydrogen bond donors hydrogen bond acceptors rotational bonds reaction energy polar surface area etc) via Initial focussed libraries comprising feasible solutions can be generated by introducing standard EC constraint handling techniques and further filtering out of non-desirables during the COGA processing
 via Initial focussed libraries comprising feasible solutions can be generated by introducing standard EC constraint handling techniques and further filtering out of non-desirables during the COGA processing")
39
Multi-objective Satisfaction Transferring COGA multi-objective approaches from engineering application to drug design has resulted in a capability to generate focussed libraries of solutions that best satisfy criteria relating to: Similarity QSAR (solubility) QSAR (log p) Docking Fuzzy preference components have been integrated to facilitate user-interaction
 QSAR (log p) Docking Fuzzy preference components have been integrated to facilitate user-interaction")
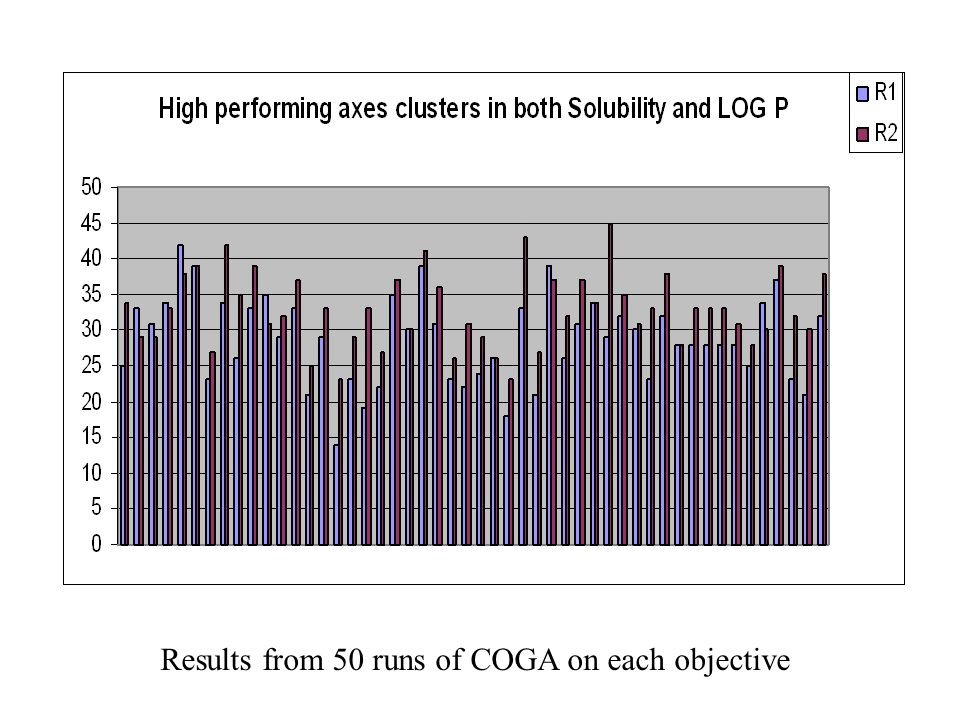
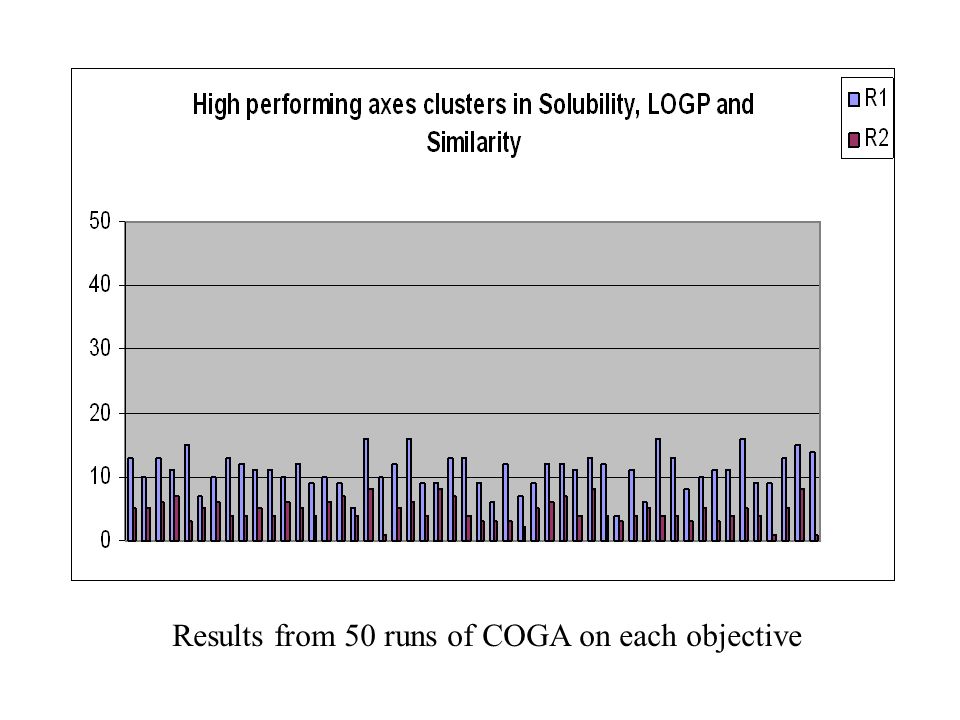
40
Results from 50 runs of COGA on each objective

43
Projection of COGA output onto objective space

44
User Preferences 1.Similarity QSAR (LOGP) = > >> < << Preference Questions 2. QSAR (LOGP) QSAR (SOL) 3. Similarity QSAR (LOGP )
 QSAR (SOL) 3. Similarity QSAR (LOGP ).")
45
Similar linguistic fuzzy preferences (Fodor and Reubens) previously used in BAE Airframe Design work (Cvetkovic & Parmee) Library focussing preference selection directly affects the settings of the COGA Adaptive Filter
 previously used in BAE Airframe Design work (Cvetkovic & Parmee) Library focussing preference selection directly affects the settings of the COGA Adaptive Filter")
46
User- Preferences SIM ~ QSARSIM >> QSAR A significant overlap of solutions signify presence of common axes clusters Preference change improves this overlap

47
Denovo Design Other collaborative work involves more direct evolutionary de novo molecule design utilising classified known chemical reactions along with a database of available reagents as mutation operators. Non-evolutionary programs tend to add and remove atoms or fragments to get a better fitness i.e. they grow molecules in a simulated environment. GA approaches tend to use splicing approach i.e. “ripping” two molecules apart, swapping fragments over and forcing them back together.

48
Current approaches unnatural – bench chemist modifies molecules via a reaction carried out in a flask – appropriate simulation required. Evotec OAI has a Corporate Chemical Database (CCD) of reactions to enumerate virtual combinatorial libraries. Developed Evolutionary Programming (EP) approach utilises combination of this CCD and an internal database of commercially available compounds (Evotec Supplier Database (ESD)) Similarity, QSAR or Docking criteria provide fitness evaluation functions Integration of EP results in evolution of high- performance de novo molecule designs.
 of reactions to enumerate virtual combinatorial libraries. Developed Evolutionary Programming (EP) approach utilises combination of this CCD and an internal database of commercially available compounds (Evotec Supplier Database (ESD)) Similarity, QSAR or Docking criteria provide fitness evaluation functions Integration of EP results in evolution of high- performance de novo molecule designs..")
49
Molecule Mutations / Modifications Fitness-proportionate selection (Roulette Wheel) provides a population member to be mutated Appropriate reaction selected from CCD and applied to population member Mutation types – addition, cleavage and transformation Fitness of mutated compound then calculated and individual then placed in appropriate position within a fitness-ranked population
 provides a population member to be mutated Appropriate reaction selected from CCD and applied to population member Mutation types – addition, cleavage and transformation Fitness of mutated compound then calculated and individual then placed in appropriate position within a fitness-ranked population")
50
Main difficulties relate to: unacceptable growth of molecules - can be overcome by control of frequency of mutation type and introduction of penalty functions. complex nature of search space – discontinuous search space with possible disjoint regions. Some known solutions difficult to reach extensive tuning did not greatly improve the search and exploration

51
Overall feelings: Need to better understand chemical space characteristics EP not providing much information re solution characteristics nor nature of chemical space Really require an approach that will better support knowledge discovery An approach where the journey is as important as arriving at the destination Decided to adopt an agent-based approach

52
Agent based search of chemical space Consider a single reaction: –Start molecule ID =1 –Reaction ID = 1 –Reagent ID = 2 –Product molecule ID = 3 The start reagent and end product are considered as nodes, the reaction and reagents are considered as an edge. The overall reaction is considered as a ‘move’ by an agent

53
Random walk agent An agent will randomly select a reaction that can be used for a given start molecule For the selected reaction, random reagents are selected If no reactions or reagents are available or the product exceeds an AMW threshold then the agent will ‘backtrack’ to a previous node. This can be represented as a directional graph

54
Create pre-defined search space Initial search space too large for meaningful data analysis at this stage Fully enumerated space around a known P38α Map kinase inhibitor –10 reagents –4 reactions –Set a 500 MW upper limit –Total space is 58,660 molecules and 91,082 reaction paths –Docked all results –Confirmed that known inhibitor has the highest score

55
Random Search 100 agents –10 agents each starting at the 10 start nodes 1000 moves per agent We can now use this data to compare other agent performance

56
Random Walk Agent Leaving this agent to run it randomly generates molecules In the depiction below the nodes are coloured by similarity to a known Thrombin inhibitor Removing the edges shows that ‘good’ nodes are distributed throughout the search space as expected

58
Weighted Reaction Agent Based on data from random walk, reaction weightings can be calculated Instead of an agent selected a random reaction, it uses a roulette wheel selection Based on docking scores, weighted reaction agents have shown a 5-7% increase in score

59
Weighting Sets Weighting Set 1 –Weight an individual reaction Weighting Set 2 –Weight a reaction–reagent combination Weighting Set 3 –Weight reaction paths Weighting Set 4 –Weight reaction-reagent path

60
Weighting set 1 - Results

61
Results Not much better than random Is the search space too small ? –In total Evotec chemical space, we are trying to identify the good reactions whereas in the test space we already have them Alternative weighting methods –Should we weight on the top result it produces or another way ?

62
Larger search space Defined larger search space –27 Reactions –200 Reagents –This includes known reactions and reagents for known thrombin and P38α MAP kinase inhibitors Ran a baseline experiment using Random walk agent

63
Weighting set 2 - Weight a reaction – reagent combination As with previous experiment: –Carried out 50 experiments Different weightings and start nodes per experiment 10 agents per experiment 1000 moves each –Weightings based on average fitness of product

64
Weighting set 2 - Results

65
Weighting set 3 - Weight reaction paths Carried out 50 experiments –Different weightings and start nodes per experiment –10 agents per experiment –1000 moves each

66
Initial Results

67
Local Search Agent Start points derived from random walk data –Start nodes were the start nodes from the top 10 solutions (7 nodes) Path length set to 3 i.e. agents cannot travel more than 3 edges from start Run with 500 and 5000 moves P38 – no better than random walk Thrombin – alternative good solutions were found (equal fitness to best)
.")
68
Bioster agent Uses transformations from Bioster database Based on local search agent In the Thrombin case, solutions found that are better than random Nothing better found in P38 case Note that this is still based on similarity

69
Tabu function for agents Aim is to increase efficiency (and thus exploration) of agent Modified current agents to log attempted moves that failed and dead end nodes Devised tabu agent, tabu meaning: –A node that has been completely exhausted (i.e. all paths are tabu) –A path (reaction and reagent) that is known to lead to a tabu node –A path that is known to lead to a dead end (i.e. null reaction or node outside pass criteria)
 –A path (reaction and reagent) that is known to lead to a tabu node –A path that is known to lead to a dead end (i.e. null reaction or node outside pass criteria).")
70
Tabu function results P38 – worse than random – surprising – need to identify why Thrombin – Better than random, 2 nd best result so far Need to carry out further data analysis

71
Agent Parameters Initial investigation into number of agents –30 agents with 5000 moves –60 agents with 2500 moves P38 – More agents with less moves didn’t do as well Thrombin - More agents with less moves did equally well, with the best result yet using a tabu agent

72
Types of Agent Random Agents – have no pre-defined knowledge of search space - carry out random search. Tabu agents use information from other agents regarding areas of space already visited, but still considered random as not guided by previous fitness value. Knowledge Agents – require information from previously run agents i.e. what reactions and/or reagents, or which reaction pathways have given rise to positive results for a particular fitness function Local agents – These agents require information about a suitable starting point in the search space and then carry out a local search

73
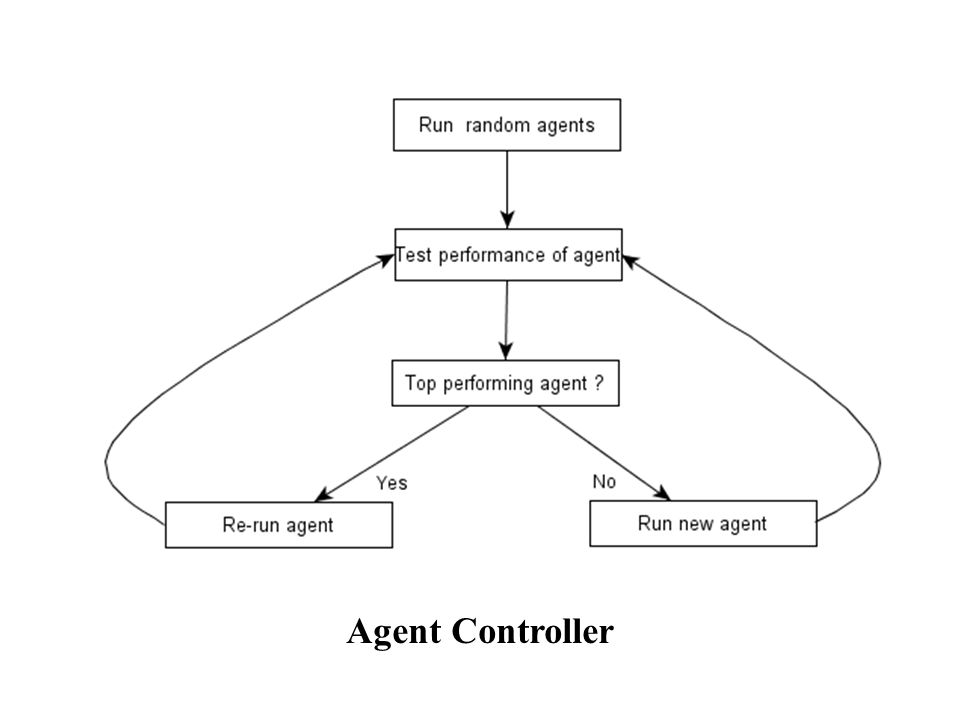
Controller first runs a set of random agents to initially explore space. Then continues running best performing agent whilst removing ‘poor’ agents and replacing with randomly created new agents of any type / parameter Agent strategy evolves over time - dependant on fitness function. Controller also considers where agents start points - high performing local agent will continue in same space whereas a high performing knowledge agent may move elsewhere. Agent Controller

76
Results summary Weighted Agents often perform better than random search –Target specific –Weighting strategy specific Local search agents perform well –Target specific –Only when already located in a high performing area of the space Tabu agents also performed well –Target specific –Long and short term memory functions performed the best

77
Further Agent Development Further Tabu development True multi-agent system with communication Agent data logging capability GA to run agent system and parameters Establishment of Chemist as ‘External Agent’ Machine-learning capability to identify primary issues Develop as a continuous ‘background’ process

78
Conclusions Currently satisfied with library optimiser / focusing - now working software within Evotec - much opportunity for further development. Much further work required re Agent-based De Novo design – probably a further PhD. Complete interactive system very ambitious. Some aspects can be integrated with current practice and iteratively developed.

81
The final high-level people-centred computational design environment Level-0 architecture

82
Evolution of the Structural View from Level-0 architecture

83
High-level structural view of the PCCDE starting from Level-0 architecture

84
Rings represent higher level processes that support conceptual design. Any conceptual design effort requires: Search and Exploration – to produce different design alternatives. Knowledge Extraction and Capture – to extract and store knowledge related to design and the design process. Co-operation and Collaboration – to support collaborative design effort. Above three processes require some kind of Representation as well as an Enabling Environment which allows, for instance, Human-machine Interaction. Therefore, supporting core for high-level processes contains Enabling Environment and Representation key-factors.

85
We need to understand the human designer and the machine requirements as well as their limitations. Therefore Enabling Environment and Representation key-factors themselves rely upon Understanding Humans and Understanding Machines. Furthermore common Understanding Humans and Understanding Machines activities support ‘Two-way Knowledge Capture’.

86
Expansion of the high level Structural View.

87
Detail ignores Understanding Humans and Machines aspect. Concentrates on higher-level processes. Enabling Environment and Representation form not only the central pillar to support high-level processes but also act as a unified medium to support: Data/Information exchange Interaction with the User Interface Data Visualization Flexibility in the framework by simplifying how new components can be added Interconnectivity between different components

88
This work to be published as a chapter in the second ‘Designing for the 21 st Century (D21C)’ book edited by Prof Tom Inns to be published later this year. See: http://www.design21.dundee.ac.uk// for more info/ Background to this work can be found in our chapter in the first D21C book: Designing for the 21st Century: Interdisciplinary Questions and Insights edited by Tom Inns. ISBN 978-0-566-08737-0, published December 2007 or by visiting http://www.ip-cc.org.uk

89
THANKYOU!

Similar presentations














 Authors: Yash Patel, Andrew.>")










