Download presentation
Presentation is loading. Please wait.

1
What Could We Do better? Alternative Statistical Methods Jim Crooks and Xingye Qiao

2
Review of the Statistical Model We take measurements of the beam displacement, y, at times t 1,…,t n What we actually observe is which is a noisy version of y, –or is the error resulting from imperfect measurement at time t j

3
A Statistical Model For Displacement Under the spring model it is assumed that the displacement over time is governed by the spring model: So we could write:

4
A Statistical Model for Displacement Remember the assumptions: –Data at different time points are independent –Residuals are normally distributed –Residuals variance is constant over time With these assumptions the model can be written:

5
What if we have Replicates? We may have repeated measurements of the same beam Notation: Let t ij be the j th time point; then i indexes the repeats at t j Denote the repeated measurement of the beam displacement at tj by i (t j )= ij. If we believe C and K are the same across replicates then we may write the model as: independent over time and replicate
= ij. If we believe C and K are the same across replicates then we may write the model as: independent over time and replicate.")
6
The likelihood Because of our independence assumption, the likelihood of the model (which we think of as a function of the parameters C and K, not the data) is the product of the individual density functions evaluated at the data : where N(x;, 2 ) denotes the normal density with mean and variance 2 evaluated at x.
 is the product of the individual density functions evaluated at the data : where N(x;, 2 ) denotes the normal density with mean and variance 2 evaluated at x.")
7
Maximum Likelihood Estimates The Maximum Likelihood Estimates (MLEs) for C and K, denoted and, are the values of C and K that maximize the likelihood function Given 2 known, the MLEs are the same as what youd get with a Least-Squares procedure (the former tends to justify the use of the latter)
 for C and K, denoted and, are the values of C and K that maximize the likelihood function Given 2 known, the MLEs are the same as what youd get with a Least-Squares procedure (the former tends to justify the use of the latter)")
8
How Good is the Model? We can asses the goodness of fit by using the spring model to predict the observed measurements The predicted (AKA fitted) values, ŷ(t) are obtained by evaluating the spring model with and : We can compare the fitted values at the observed times ŷ(t ij ) = ŷ ij to the observed values ij. Run the MATLAB file inv_beam.m by typing: > inv_beam
 values, ŷ(t) are obtained by evaluating the spring model with and : We can compare the fitted values at the observed times ŷ(t ij ) = ŷ ij to the observed values ij. Run the MATLAB file inv_beam.m by typing: > inv_beam.")
9
Spring Model

12
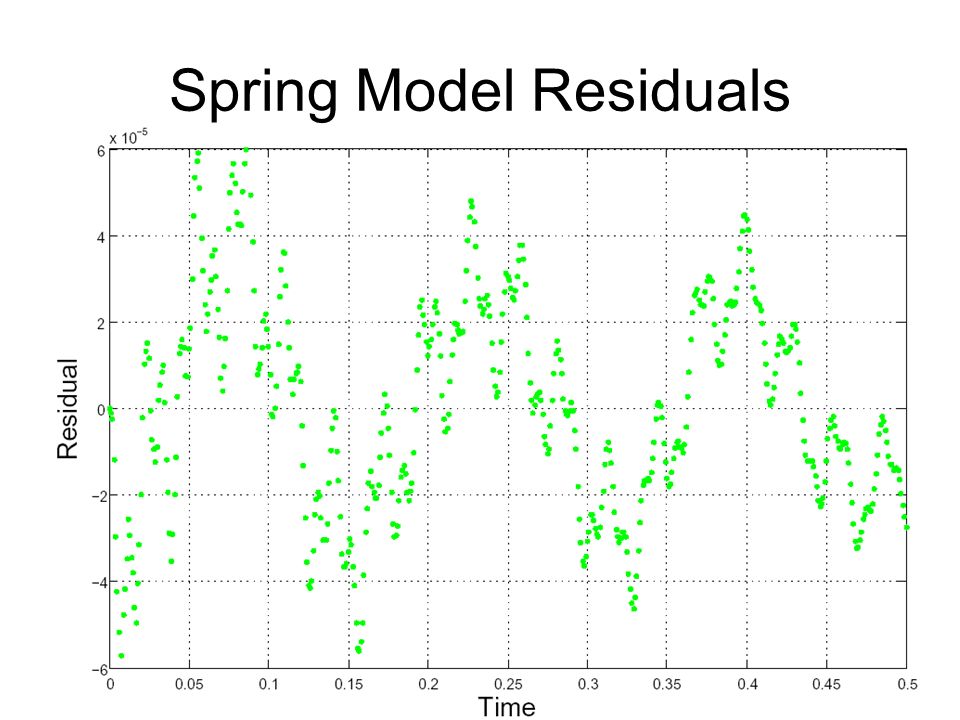
Model Residuals We need to know the difference between beam displacement data and our models predictions for the beam displacement: These are called the model residuals The residuals are our best guess for the values of ij. Hence from our current model we would expect the e ij to look independent and normally distributed with constant variance

13
Spring Model Residuals Are the residuals normally distributed? Are they independent (i.e., is there correlation in time)? Is their variance constant? Run the MATLAB file plotresidual.m by typing: > plotresidual
. Is their variance constant. Run the MATLAB file plotresidual.m by typing: > plotresidual.")
14
Spring Model Residuals

17
Spring Model QQ-plot

18
Coefficient of Determination R 2 One criteria to use when judging a model is the fraction of the variability in the data it can explain: SSTot is the total variability in the data SSE is the variability left over after fitting the model (SSE SSTot) So R 2 represents the fraction of variability in the data that is explained by the model
 So R 2 represents the fraction of variability in the data that is explained by the model")
19
Coefficient of Determination R 2 In the example shown above we can find that: This means the spring model accounts for about 52% of the variability in our displacement measurements Is 52% a lot?

20
Coefficient of Determination R 2 Brief aside: note that we can also get an estimate of 2 from SSE: where n is the number of data points and df is the number of degrees of freedom (AKA the number of unknown parameters)
")
21
How Good is this Model? Is R 2 = 52% any good? It depends. It can be useful (or even necessary) to set up a naïve straw man alternative against which to compare a physical model There are many possible alternatives and choosing between them is subjective To illustrate we will use a smoothing spline alternative
 to set up a naïve straw man alternative against which to compare a physical model There are many possible alternatives and choosing between them is subjective To illustrate we will use a smoothing spline alternative.")
22
Smoothing Splines A cubic spline is a function that is a piecewise cubic polynomial: –Between each sequential pair of time points the function is a cubic polynomial –At each time point the function is continuous and has continuous first and second derivatives –The time points are called knots

23
Smoothing Splines A smoothing spline is a type of cubic spline where: –The time points are specifically those at which measurements are made, t j –Given (y j,t j ) for all j, is determined to be that cubic spline that minimizes –Here is called the smoothing parameter What happens to the smoothness as α?
 for all j, is determined to be that cubic spline that minimizes –Here is called the smoothing parameter What happens to the smoothness as α")
24
Smoothing Splines The value of parameterizes the relative importance of smoothness to fit –Larger values of result in a bigger penalty for curvature and hence results in a smoother fit that may not fit the data –Smaller values of result in a wigglier spline that more closely follows the data Straight Line Exact Interpolator

25
Smoothing Splines But how do we choose the value of ? Another choice without an objectively correct answer! One useful answer is the value that minimizes the leave-one-out predictive error: –Fit the spline to all the displacement data except one point –Use the spline to predict the displacement at this time point –Repeat over all displacement points and sum the residual errors This is called leave-one-out cross-validation

26
Fitted Spline

29
Fitted Spline Residuals Are the residuals normally distributed? Are they independent (i.e., is there correlation in time)? Is their variance constant? You can make your own cross-validated spline using the MATLAB file splineplot.m Dont do it now!!!
. Is their variance constant. You can make your own cross-validated spline using the MATLAB file splineplot.m Dont do it now!!!.")
30
Spline Residuals

33
Spline QQ-plot

34
Compare the Spring Model to Splines If you compare residuals, those for the spline are generally smaller (i.e., it fits the data better) Spline Coefficient of variation is Our spring model explains less of the variation than does a naive spline (52% < 88%)
 Spline Coefficient of variation is Our spring model explains less of the variation than does a naive spline (52% < 88%)")
35
Compare the Spring Model to Splines Is the difference big enough to reject the use of the spring model? Again, this is subjective, but can use statistical tests to answer the question as objectively as possible Such tests are beyond the scope of this workshop, but if you are interested in supercharging your group project using them please ask me

36
Good Luck!!!

Similar presentations













 values must be estimated before.>")











 Maximum Likelihood Estimation (MLE)>")
