Download presentation
Presentation is loading. Please wait.

1
Genome Annotation: A Protein-centric Perspective

2
Protein data contributing to genome annotation Gene structure prediction Gene function prediction

10
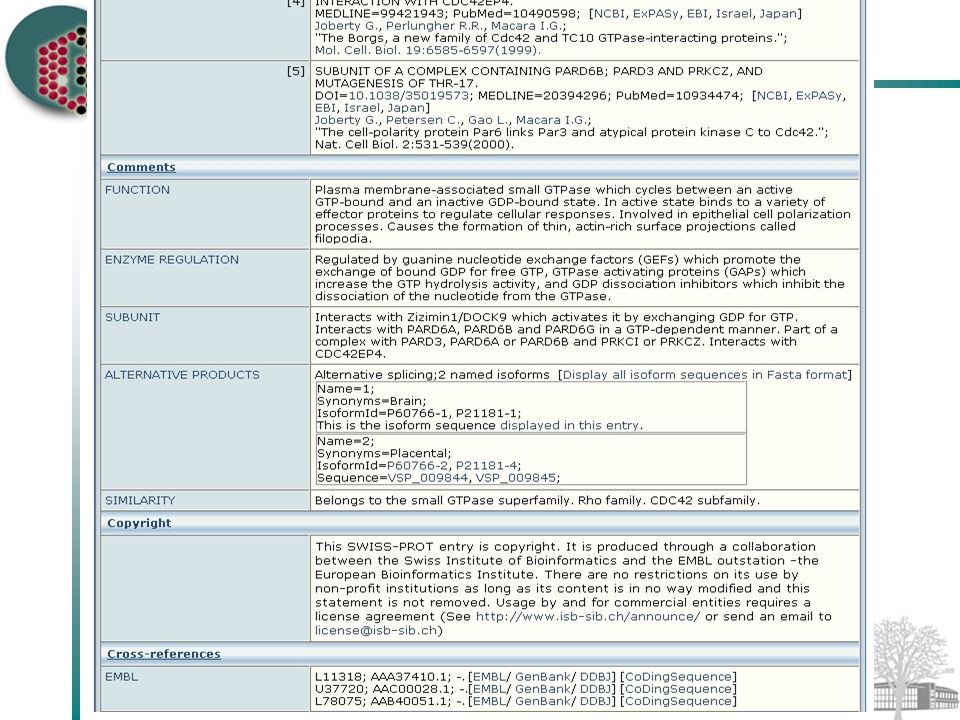
UniProt Collaboration between EBI, SIB and PIR Funded mainly by NIH Based on the original work on PIR, Swiss-Prot and TrEMBL

11
UniProt Goals High level of annotation Minimal redundancy High level of integration with other databases Complete and up-to-date

13
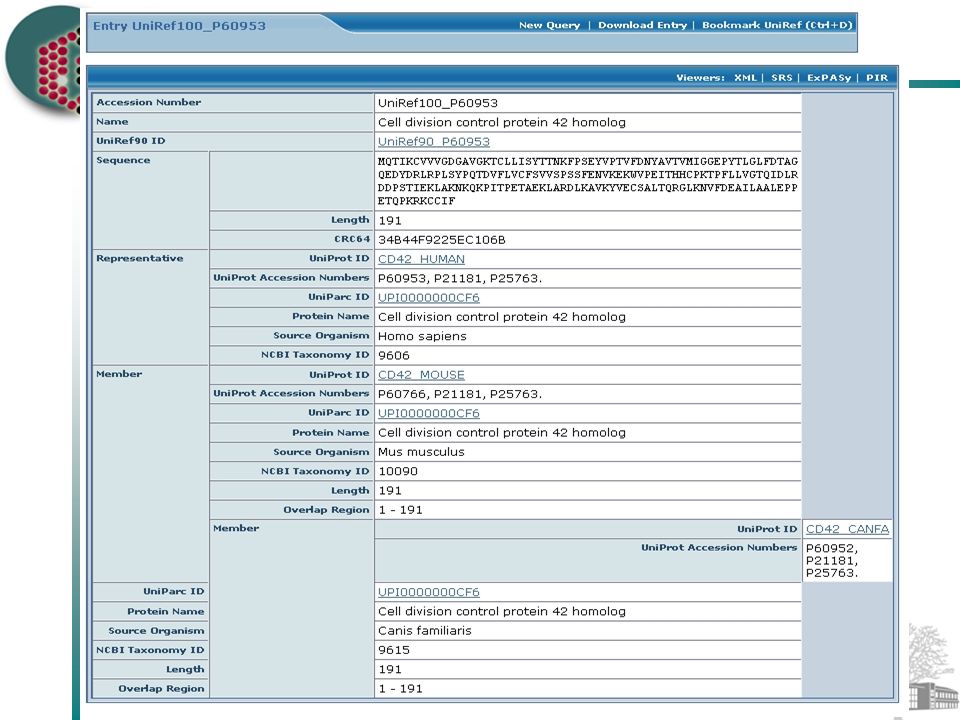
UniProt Non-Redundancy Concepts UniProt Archive (UniParc): All sequences that are 100% identical over their entire length are merged into a single entry, regardless of species. UniParc represents each protein sequence once and only once, assigning it a unique Identifier. UniParc cross-references the accession numbers of the source databases. UniProt Knowledgebase: Aims to describe in a single record all protein products derived from a certain gene (or genes if the translation from different genes in a genome leads to indistinguishable proteins) from a certain species. UniProt Nref: Merges sequences automatically across different species.
 from a certain species. UniProt Nref: Merges sequences automatically across different species..")
15
UniParc 2.2. July 2004 3,913,916 unique sequences from 10,422,131 source records Source databases are DDBJ/EMBL/GenBank, UniProt/Swiss-Prot, UniProt/TrEMBL, PIR-PSD, Ensembl, International Protein Index (IPI), PDB, RefSeq, FlyBase, WormBase, H-Inv, TROME, European Patent Office, United States Patent and Trademark Office and Japan Patent Office
, PDB, RefSeq, FlyBase, WormBase, H-Inv, TROME, European Patent Office, United States Patent and Trademark Office and Japan Patent Office.")
27
UniProt Protein DAS Reference Server Aristotle – Data Source for the Reference Server Creating a Plugin for Thomas Down's DAZZLE Servlet

28
DAS Infrastructure - Overview EBI UniProt InterPro Aristotle Protein DAS Reference Server Download every 2 weeks Reference and Annotation from the EBI Protein DAS Annotation Server Protein DAS Annotation Server DAS Client – Connects to Reference Server and zero or more Annotation Servers. Merge duplicate features? Resolve version differences ?

29
Creating a Plugin for DAZZLE / Aristotle Involved linking the Aristotle Java API to the BioJava & DAZZLE Java API's Issues with enabling a useful entry_point command Creation of an 'artificial' hierarchy of entry points, based upon sequence length

31
Possible Approach to Implementing Local Annotation Servers Use GFF Format as a simple and accessible primary data source Problem with this – not suitable for very large numbers of records, so... Load this into a relational database (sticking with SQL-92 to ensure as cross-platform as possible) Use a standard plugin that will allow the 'GFF' data to be read from the relational database. From the point of view of the data curators, this process should be transparent, i.e. they should be able to work with GFF files and not need to worry about the database structure
 Use a standard plugin that will allow the GFF data to be read from the relational database. From the point of view of the data curators, this process should be transparent, i.e. they should be able to work with GFF files and not need to worry about the database structure.")
32
UniProt Protein DAS Server External Page: http://www.ebi.ac.uk/uniprot-das/http://www.ebi.ac.uk/uniprot-das/ DAS server package downloadpage: http://www.ebi.ac.uk/uniprot-das/gffDasApp.html http://www.ebi.ac.uk/uniprot-das/gffDasApp.html The UniProt DAS Server itself: http://www.ebi.ac.uk/das-srv/uniprot/das http://www.ebi.ac.uk/das-srv/uniprot/das

Similar presentations






















 NCBINCBI (National Center for Biotechnology Information) is a home for many public biological databases (see an older diagram below). All.>")















