Download presentation
Presentation is loading. Please wait.

1
A Framework for Scalable Cost- sensitive Learning Based on Combining Probabilities and Benefits Wei Fan, Haixun Wang, and Philip S. Yu IBM T.J.Watson Salvatore J. Stolfo Columbia University

2
Scalable Issues of Data Mining Scalable Issues of Data Mining ƒTwo folds: the data and the algorithm. ƒDataset: too big to fit into memory. inherently distributed across the network. incremental data available periodically.

3
Scalable Issues of Data Mining Scalable Issues of Data Mining ƒLearning algorithm: non-linear complexity in the size of dataset n. memory based due to random access pattern of record in dataset. significantly slower if dataset is not held entirely in memory. ƒState-of-the-art many scalable solutions are algorithm specific. decision trees: SPRINT, RainForest and BOAT general algorithms are not very scalable and only work for cost-insensitive problems meta-learning ƒQuestion: general and work for both cost-sensitive and cost-insentive problems.

4
Cost-sensitive Problems ƒCharity Donation: Solicit to people who will donate large amount of charity. Costs $0.68 to send a letter. E(x): expected donation amount. Only solicit if E(x) > 0.68, otherwise lose money. ƒ Credit card fraud detection: Detect frauds with high transaction amount $90 to challenge a potential fraud E(x): expected fraudulant transaction amount. Only challenge if E(x) > $90, otherwise lose money. ƒQuestion: how to estimate E(x) efficiently?
: expected donation amount. Only solicit if E(x) > 0.68, otherwise lose money. ƒ Credit card fraud detection: Detect frauds with high transaction amount $90 to challenge a potential fraud E(x): expected fraudulant transaction amount. Only challenge if E(x) > $90, otherwise lose money. ƒQuestion: how to estimate E(x) efficiently .")
5
Basic Framework D D1D1 D2D2 D2D2 large dataset partition into k subsets ML 1 ML 2 ML t C1C1 C2C2 CkCk generate k models

6
Basic Framework D Test Set C1C1 C2C2 CkCk Sent to k models P1P1 P2P2 PkPk Compute k predictions Combine P Combine to one prediction

7
Cost-sensitive Decision Making ƒAssume that records the benefit received by predicting an example of class to be an instance of class. ƒThe expected benefit received to predict an example to be an instance of class (regardless of its true label) is ƒThe optimal decision-making policy chooses the label that maximizes the expected benefit, i.e., ƒWhen and is a traditional accuracy-based problem. ƒTotal benefits
 is ƒThe optimal decision-making policy chooses the label that maximizes the expected benefit, i.e., ƒWhen and is a traditional accuracy-based problem. ƒTotal benefits.")
8
Charity Donation Example ƒIt costs $.68 to send a solicitation. ƒAssume that is the best estimate of the donation amount, ƒThe cost-sensitive decision making will solicit an individual if and only if

9
Credit Card Fraud Detection Example ƒIt costs $90 to challenge a potential fraud ƒAssume that y(x) is the transaction amount ƒThe cost-sensitive decision making policy will predict a transaction to be fraudulent if and only if
 is the transaction amount ƒThe cost-sensitive decision making policy will predict a transaction to be fraudulent if and only if")
10
Adult Dataset ƒDownloaded from UCI database. ƒAssociate a benefit factor 2 to positives and a benefit factor 1 to negatives ƒThe decision to predict positive is

11
Calculating probabilities For decision trees, is the number of examples in a node and is the number of examples with class label, then the probability is more sophisticated methods smoothing: early stopping, and early stopping plus smoothing For rules, probability is calucated in the same way as decision trees For naive Bayes, is the score for class label, then binning

12
Combining Technique-Averaging ƒEach model computes an expected benefit for example over every class label ƒCombining individual expected benefit together ƒWe choose the label with the highest combined expected benefit

13
1. Decision threshold line 2. Examples on the left are more profitable than those on the right 3. "Evening effect": biases towards big fish. Why accuracy is higher?

14
More sophisticated combining approaches ƒRegression: Treat base classifiers' outputs as indepedent variables of regression and the true label as dependent variables. ƒModify Meta-learning: Learning a classifier that maps the base classifiers' class label predictions to that the true class label. For cost-sensitive learning, the top level classifier output probability instead of just a label.

15
Experiments ƒLearner: C4.5 version 8 ƒDataset: Donation (KDD98) Credit Card Adult ƒNumber of partitions: 8,16,32,64,128,and 256
 Credit Card Adult ƒNumber of partitions: 8,16,32,64,128,and 256")
16
Accuracy comparision

17
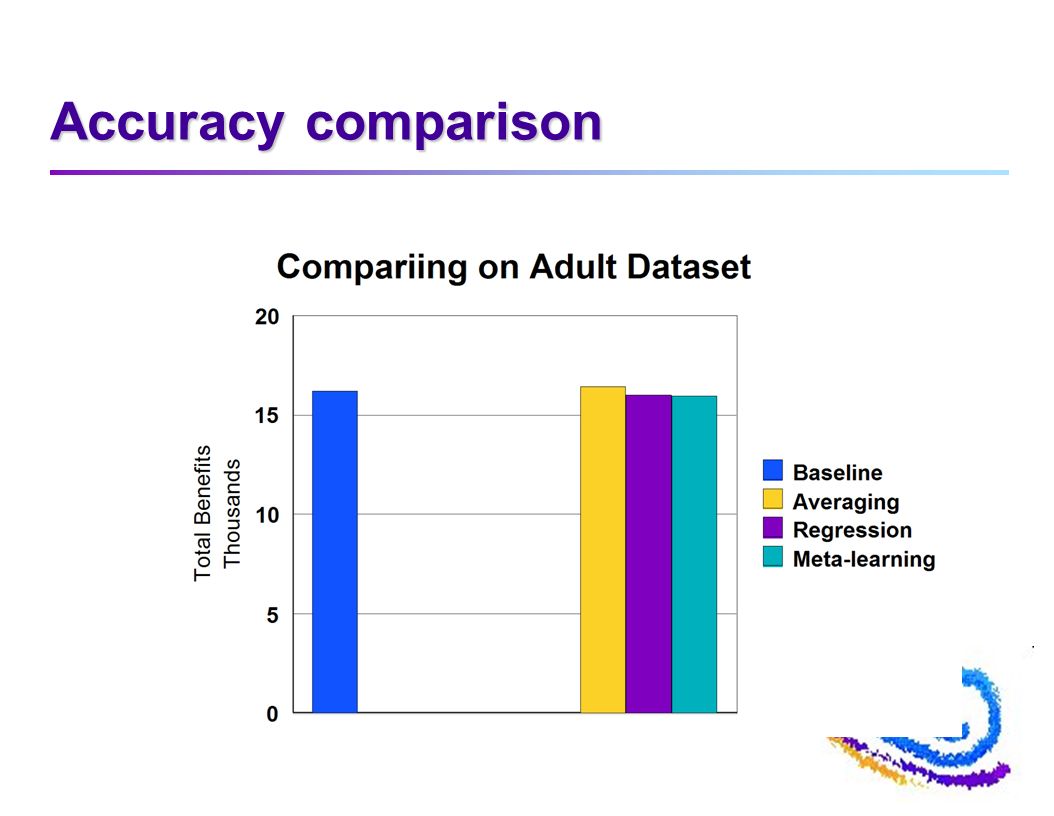
Accuracy comparison

19
Detailed Spread

20
Credit Card Fraud Dataset

21
Adult Dataset

22
Why accuracy is higher?

23
Scalability Analysis of Averaging Method ƒBaseline: a single model that is computed from the entire dataset as a whole. ƒOur approach: ensemble of multiple models, each of which is computed from disjoint datasets.

24
Scalability Analysis ƒSerial Improvment ƒParallel Improvment ƒSpeedup ƒScaled Speedup

25
Scalability Results - Serial Improvement

26
Scalability Results - Parallel Improvement

27
Scalability Results - Speedup

28
D1D1 D2D2 D2D2 k sites ML 1 ML 2 ML t C1C1 C2C2 CkCk generate k models Fully distributed learning framework

29
Communication overhead

30
Overhead analysis

31
Summary and Future Work ƒEvaluated a wide range of combining techniques include variations of averaging, regression and meta- learning for scalable cost-sensitive (and cost- insensitive learning). ƒAveraging, although simple, has the highest accuracy. ƒPreviously proposed approaches have significantly more overhead and only work well for tradtional accuracy-based problems. ƒFuture work: ensemble pruning and performance estimation

32
ƒSuppose that is the probability that is an instance of class label. ƒAn inductive model will always predict the label with the highest probability, i.e., ƒThe accuracy of a method on dataset is Accuracy-based Problems (0-1 loss)
.")
Similar presentations