Download presentation
Presentation is loading. Please wait.

1
Quantitative Data Analysis: Statistics – Part 2

2
Overview Part 1 Picturing the Data Pitfalls of Surveys Averages Variance and Standard Deviation Part 2 The Normal Distribution Z-Tests Confidence Intervals T-Tests

3
The Normal Distribution

4
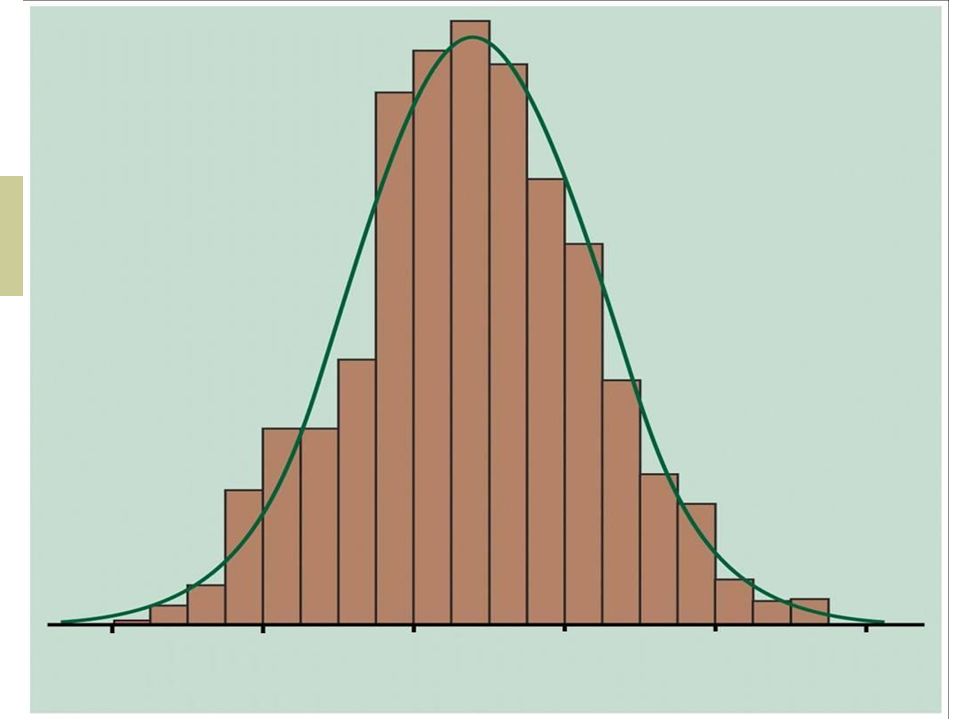
Abraham de Moivre, the 18th century statistician and consultant to gamblers was often called upon to make lengthy computations about coin flips. de Moivre noted that when the number of events (coin flips) increased, the shape of the binomial distribution approached a very smooth curve. In 1809 Carl Gauss developed the formula for the normal distribution and showed that the distribution of many natural phenomena are at least approximately normally distributed.
 increased, the shape of the binomial distribution approached a very smooth curve. In 1809 Carl Gauss developed the formula for the normal distribution and showed that the distribution of many natural phenomena are at least approximately normally distributed..")
5
Abraham de Moivre Born 26 May 1667 Died 27 November 1754 Born in Champagne, France wrote a textbook on probability theory, "The Doctrine of Chances: a method of calculating the probabilities of events in play". This book came out in four editions, 1711 in Latin, and 1718, 1738 and 1756 in English. In the later editions of his book, de Moivre gives the first statement of the formula for the normal distribution curve.

6
Carl Friedrich Gauss Born 30 April 1777 Died 23 February 1855 Born in Lower Saxony, Germany In 1809 Gauss published the monograph “Theoria motus corporum coelestium in sectionibus conicis solem ambientium” where among other things he introduces and describes several important statistical concepts, such as the method of least squares, the method of maximum likelihood, and the normal distribution.

9
The Normal Distribution

10
Age of students in a class Body temperature Pulse rate Shoe size IQ score Diameter of trees Height?

11
The Normal Distribution

14
Density Curves: Properties

15
The Normal Distribution The graph has a single peak at the center, this peak occurs at the mean The graph is symmetrical about the mean The graph never touches the horizontal axis The area under the graph is equal to 1

16
Characterization A normal distribution is bell-shaped and symmetric. The distribution is determined by the mean mu, and the standard deviation sigma, . The mean mu controls the center and sigma controls the spread.

17
Same Mean, Different Standard Deviation 101

18
Different Mean, Different Standard Deviation 101

19
Different Mean, Same Standard Deviation 101

29
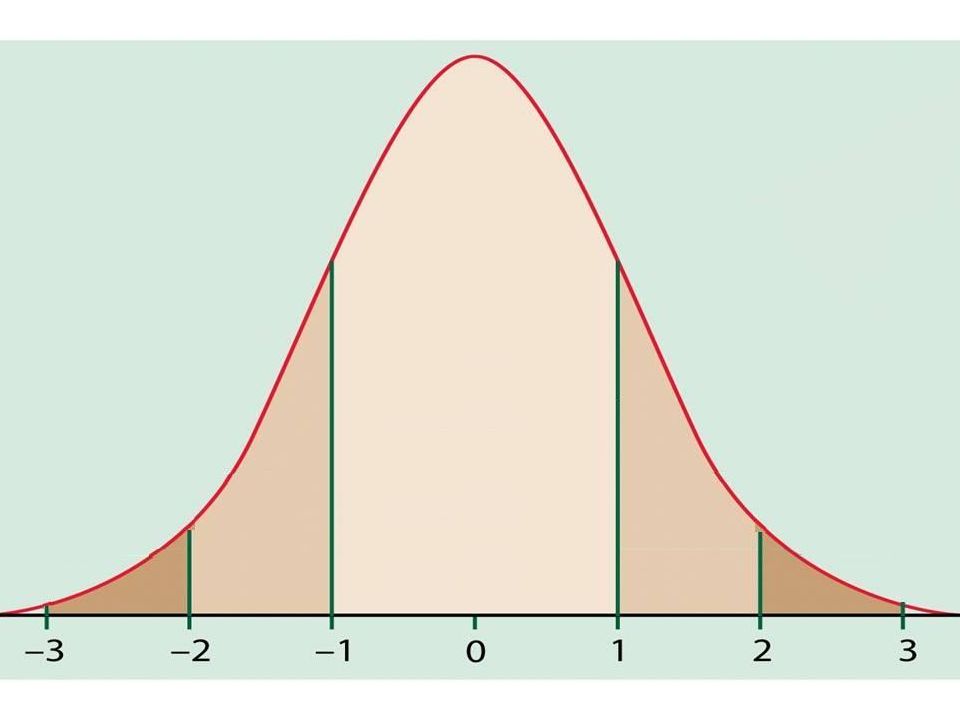
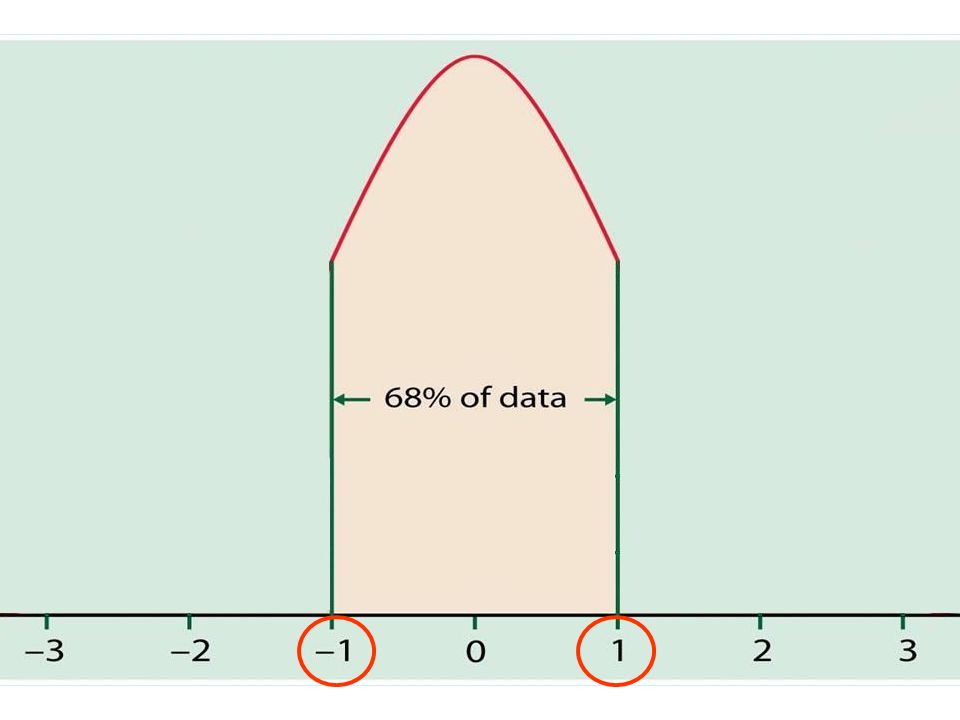
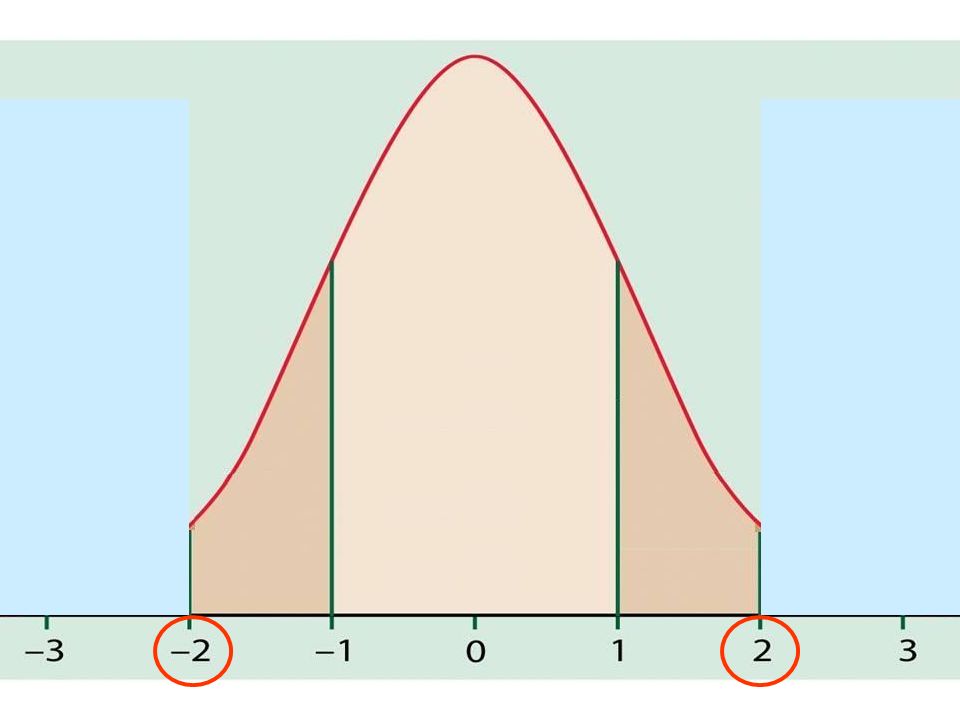
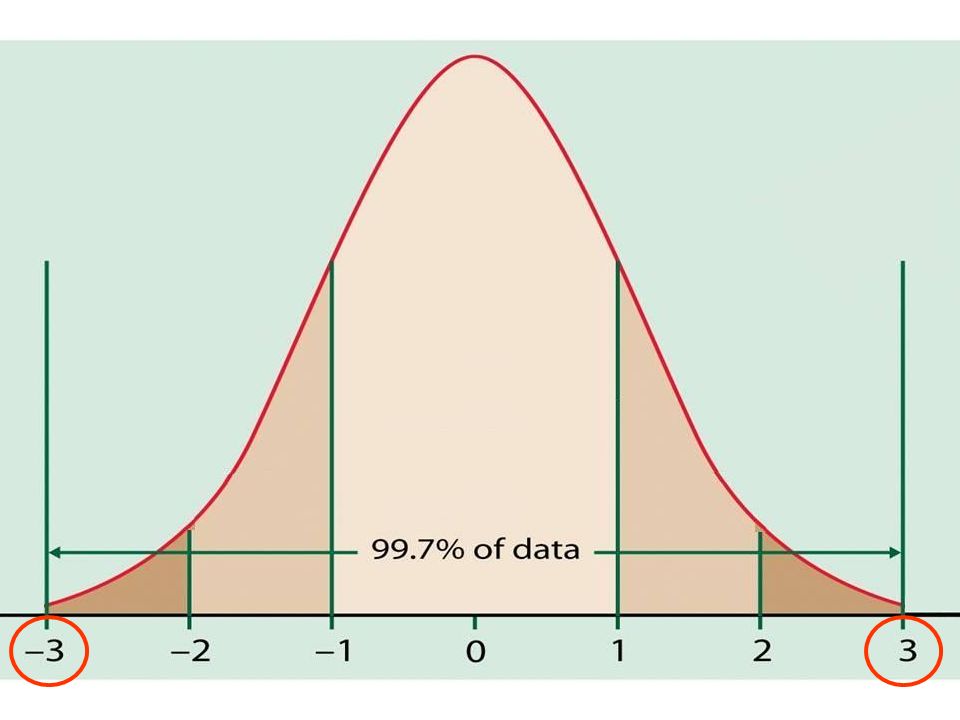
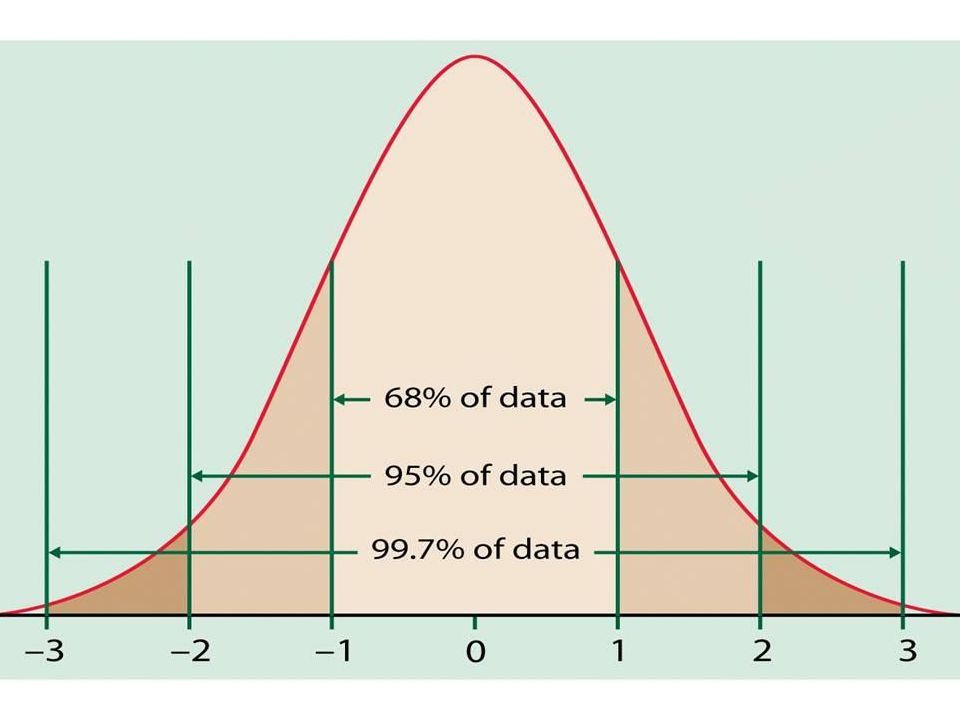
The Normal Distribution If a variable is normally distributed, then: within one standard deviation of the mean there will be approximately 68% of the data within two standard deviations of the mean there will be approximately 95% of the data within three standard deviations of the mean there will be approximately 99.7% of the data

30
The Normal Distribution

31
Why? One reason the normal distribution is important is that many psychological and organsational variables are distributed approximately normally. Measures of reading ability, introversion, job satisfaction, and memory are among the many psychological variables approximately normally distributed. Although the distributions are only approximately normal, they are usually quite close.

32
Why? A second reason the normal distribution is so important is that it is easy for mathematical statisticians to work with. This means that many kinds of statistical tests can be derived for normal distributions. Almost all statistical tests discussed in this text assume normal distributions. Fortunately, these tests work very well even if the distribution is only approximately normally distributed. Some tests work well even with very wide deviations from normality.

33
So what? Imagine we undertook an experiment where we measured staff productivity before and after we introduced a computer system to help record solutions to common issues of work Average productivity before = 6.4 Average productivity after = 9.2

34
So what? Before = 6.4 After = 9.2010

35
So what? Before = 6.4 After = 9.2100

36
So what? Before = 6.4 After = 9.2100

37
So what? Before = 6.4 After = 9.2100

38
So what? Before = 6.4 After = 9.2100

39
So what? Before = 6.4 After = 9.2100

40
So what? Before = 6.4 After = 9.2100

41
So what? Before = 6.4 After = 9.2100 σ σ σ

42
One Tail / Two Tail One-Tailed H0 : m1 >= m2 HA : m1 < m2 Two-Tailed H0 : m1 = m2 HA : m1 <>m2

43
STANDARD NORMAL DISTRIBUTION Normal Distribution is defined as N(mean, (Std dev)^2) Standard Normal Distribution is defined as N(0, (1)^2)
^2) Standard Normal Distribution is defined as N(0, (1)^2)")
44
STANDARD NORMAL DISTRIBUTION Using the following formula : will convert a normal table into a standard normal table.

45
Exercise If the average IQ in a given population is 100, and the standard deviation is 15, what percentage of the population has an IQ of 145 or higher ?

46
Answer P(X >= 145) P(Z >= ((145 - 100)/15)) P(Z >= 3) From tables: 99.87% are less than 3 => 0.13% of population
 P(Z >= (( )/15)) P(Z >= 3) From tables: 99.87% are less than 3 => 0.13% of population")
47
Trends in Statistical Tests used in Research Papers HistoricallyCurrently Results in: Accept/Reject Results in: p-Value Results in: Approx. Mean

48
Confidence Intervals A confidence interval is used to express the uncertainty in a quantity being estimated. There is uncertainty because inferences are based on a random sample of finite size from a population or process of interest. To judge the statistical procedure we can ask what would happen if we were to repeat the same study, over and over, getting different data (and thus different confidence intervals) each time.
 each time..")
49
Confidence Intervals

50
Born April 16, 1894 Died August 5, 1981 Born in Bessarabia, Imperial Russia statistician who spent most of his professional career at the University of California, Berkeley. Developed modern scientific sampling (random samples) in 1934, the Neyman- Pearson lemma in 1933 and the confidence interval in 1937. Jerzy Neyman
 in 1934, the Neyman- Pearson lemma in 1933 and the confidence interval in Jerzy Neyman.")
51
Born 11 August 1895 Died 12 June 1980 Born in Hampstead, London Son of Karl Pearson Leading British statistician Developed the Neyman- Pearson lemma in 1933. Egon Pearson

52
Neyman and Pearson's joint work formally started in the spring of 1927. From 1928 to 1934, they published several important papers on the theory of testing statistical hypotheses. In developing their theory, Neyman and Pearson recognized the need to include alternative hypotheses and they perceived the errors in testing hypotheses concerning unknown population values based on sample observations that are subject to variation. They called the error of rejecting a true hypothesis the first kind of error and the error of accepting a false hypothesis the second kind of error. They called a hypothesis that completely specifies a probability distribution a simple hypothesis. A hypothesis that is not a simple hypothesis is a composite hypothesis. Their joint work lead to Neyman developing the idea of confidence interval estimation, published in 1937.

53
Confidence Intervals Neyman, J. (1937) "Outline of a theory of statistical estimation based on the classical theory of probability" Philos. Trans. Roy. Soc. London. Ser. A., Vol. 236 pp. 333–380.
 Outline of a theory of statistical estimation based on the classical theory of probability Philos. Trans. Roy. Soc. London. Ser. A., Vol. 236 pp. 333–380..")
54
Confidence Intervals If we know the true population mean and sample n individuals, we know that if the data is normally distributed, Average mean of these n samples has a 95% chance of falling into the interval.

55
Confidence Intervals where the standard error for a 95% CI may be calculated as follows;

56
Example 1

57
Did FF have more of the popular vote than FG-L ? In a random sample of 721 respondents : 382 FF 339 FG-L Can we conclude that FF had more than 50% of the popular vote ?

58
Example 1 - Solution Sample proportion = p = 382/721 = 0.53 Sample size = n = 721 Standard Error = (SqRt((p(1-p)/n))) = 0.02 95% Confidence Interval 0.53 +/- 1.96 (0.02) 0.53 +/- 0.04 [0.49, 0.57] Thus, we cannot conclude that FF had more of the popular vote, since this interval spans 50%. So, we say: "the data are consistent with the hypothesis that there is no difference"
![Example 1 - Solution Sample proportion = p = 382/721 = 0.53 Sample size = n = 721 Standard Error = (SqRt((p(1-p)/n))) = 0.02 95% Confidence Interval / (0.02) / [0.49, 0.57] Thus, we cannot conclude that FF had more of the popular vote, since this interval spans 50%.](http://images.slideplayer.com/24/7268889/slides/slide_58.jpg "So, we say: the data are consistent with the hypothesis that there is no difference .")
59
Example 2

60
Did Obama have more of the popular vote than McCain ? In a random sample of 1000 respondents 532 Obama 468 McCain Can we conclude that Obama had more than 50% of the popular vote ?

61
Example 2 – 95% CI Sample proportion = p = 532/1000 = 0.532 Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = 0.016 95% Confidence Interval 0.532 +/- 1.96 (0.016) 0.532 +/- 0.03136 [0.5006, 0.56336] Thus, we can conclude that Obama had more of the popular vote, since this interval does not span 50%. So, we say : "the data are consistent with the hypothesis that there is a difference in a 95% CI"
![Example 2 – 95% CI Sample proportion = p = 532/1000 = Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = 95% Confidence Interval / (0.016) / [0.5006, ] Thus, we can conclude that Obama had more of the popular vote, since this interval does not span 50%.](http://images.slideplayer.com/24/7268889/slides/slide_61.jpg "So, we say : the data are consistent with the hypothesis that there is a difference in a 95% CI .")
62
Example 2 – 99% CI Sample proportion = p = 532/1000 = 0.532 Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = 0.016 99% Confidence Interval 0.532 +/- 2.58 (0.016) 0.532 +/- 0.041 [0.491, 0.573] Thus, we cannot conclude that Obama had more of the popular vote, since this interval does span 50%. So, we say : "the data are consistent with the hypothesis that there is no difference in a 99% CI"
![Example 2 – 99% CI Sample proportion = p = 532/1000 = Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = 99% Confidence Interval / (0.016) / [0.491, 0.573] Thus, we cannot conclude that Obama had more of the popular vote, since this interval does span 50%.](http://images.slideplayer.com/24/7268889/slides/slide_62.jpg "So, we say : the data are consistent with the hypothesis that there is no difference in a 99% CI .")
63
Example 2 – 99.99% CI Sample proportion = p = 532/1000 = 0.532 Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = 0.016 99.99% Confidence Interval 0.532 +/- 3.87 (0.016) 0.532 +/- 0.06 [0.472, 0.592] Thus, we cannot conclude that Obama had more of the popular vote, since this interval does span 50%. So, we say : "the data are consistent with the hypothesis that there is no difference in a 99.99% CI"
![Example 2 – 99.99% CI Sample proportion = p = 532/1000 = Sample size = n = 1000 Standard Error = (SqRt((p(1-p)/n))) = 99.99% Confidence Interval / (0.016) / [0.472, 0.592] Thus, we cannot conclude that Obama had more of the popular vote, since this interval does span 50%.](http://images.slideplayer.com/24/7268889/slides/slide_63.jpg "So, we say : the data are consistent with the hypothesis that there is no difference in a 99.99% CI .")
64
T-Tests

65
William Sealy Gosset Born June 13, 1876 Died October 16, 1937 Born in Canterbury, England On graduating from Oxford in 1899, he joined the Dublin brewery of Arthur Guinness & Son. Published significant paper in 1908 concerning the t- distribution

66
Gosset acquired his statistical knowledge by study, and he also spend two terms in 1906–1907 in the biometric laboratory of Karl Pearson. Gosset applied his knowledge for Guinness both in the brewery and on the farm - to the selection of the best yielding varieties of barley, and to compare the different brewing processes for changing raw materials into beer. Gosset and Pearson had a good relationship and Pearson helped Gosset with the mathematics of his papers. Pearson helped with the 1908 paper but he had little appreciation of their importance. The papers addressed the brewer's concern with small samples, while the biometrician typically had hundreds of observations and saw no urgency in developing small-sample methods.

67
T-Tests Student (1908), “The Probable Error of a Mean” Biometrika, Vol. 6, No. 1, pp.1-25.
, The Probable Error of a Mean Biometrika, Vol. 6, No. 1, pp.1-25.")
68
T-Tests Guinness did not allow its employees to publish results but the management decided to allow Gossett to publish it under a pseudonym - Student. Hence we have the Student's t-test.

69
T-Tests powerful parametric test for calculating the significance of a small sample mean necessary for small samples because their distributions are not normal one first has to calculate the "degrees of freedom"

71
~ THE GOLDEN RULE ~ Use the t-Test when your sample size is less than 30

72
T-Tests If the underlying population is normal If the underlying population is not skewed and reasonable to normal (n < 15) If the underlying population is skewed and there are no major outliers (n > 15) If the underlying population is skewed and some outliers (n > 24)
 If the underlying population is skewed and there are no major outliers (n > 15) If the underlying population is skewed and some outliers (n > 24)")
73
T-Tests Form of Confidence Interval with t- Value Mean +/- tValue * SE -------- ------- as before as before

74
Two Sample T-Test: Unpaired Sample Consider a questionnaire on computer use to final year undergraduates in year 2007 and the same questionnaire give to undergraduates in 2008. As there is no direct one-to-one correspondence between individual students (in fact, there may be different number of students in different classes), you have to sum up all the responses of a given year, obtain an average from that, down the same for the following year, and compare averages.
, you have to sum up all the responses of a given year, obtain an average from that, down the same for the following year, and compare averages..")
75
Two Sample T-Test: Paired Sample If you are doing a questionnaire that is testing the BEFORE/AFTER effect of parameter on the same population, then we can individually calculate differences between each sample and then average the differences. The paired test is a much strong (more powerful) statistical test.
 statistical test..")
76
Choosing the right test

77
Choosing a statistical test http://www.graphpad.com/www/Book/Choose.htm

78
Choosing a statistical test http://www.graphpad.com/www/Book/Choose.htm

Similar presentations









>")
















