Download presentation
Presentation is loading. Please wait.

1
College of Nanoscale Science and Engineering A uniform algebraically-based approach to computational physics and efficient programming James E. Raynolds College of Nanoscale Science and Engineering University at Albany, State University of New York, Albany, NY 12309 Lenore Mullin, Computer Science University at Albany, State University of New York, Albany, NY 12309

2
College of Nanoscale Science and Engineering Matrix Example In Fortran 90: First temporary computed: Second temporary: Last operation:

3
College of Nanoscale Science and Engineering Matrix Example (cont) Intermediate temporaries consume memory and add to processing operations Solution: compose index operations Loop over i, j: No temporaries:
 Intermediate temporaries consume memory and add to processing operations Solution: compose index operations Loop over i, j: No temporaries:")
4
College of Nanoscale Science and Engineering Need for formalism Few problems are as simple as Formalism designed to handle extremely complicated situations systematically Goal: composition of algorithms For Example: Radar is composed of the composition of numerous algorithms: QR(FFT(X)). Optimizations are classically done sequentially even when parallel processors and nodes are used. FFT(or DFT?) then QR Optimizations are classically done sequentially even when parallel processors and nodes are used. FFT(or DFT?) then QR Optimizations can be optimized across algorithms, processors, and memories Optimizations can be optimized across algorithms, processors, and memories
 then QR Optimizations are classically done sequentially even when parallel processors and nodes are used. FFT(or DFT ) then QR Optimizations can be optimized across algorithms, processors, and memories Optimizations can be optimized across algorithms, processors, and memories.")
5
College of Nanoscale Science and Engineering MoA and PSI Calculus Basic Properties: An index calculus: psi function. Shape polymorphic functions and operators: Operations are defined using shapes and psi. MoA defines some useful operations and function. As long as shapes define functions and operations any new function or operation may be defined and reduced. Fundamental type is the array: scalars are 0-dimensional arrays. Denotational Normal Form(DNF) = reduced form in Cartesian coordinates (independent of data layout: row major, column major, regular sparse, …) Operational Normal Form(ONF) = reduced form for 1-d memory layout(s). Defines How to Build the code on processor/memory hierarchies. ONF reveals loops and control.
 = reduced form in Cartesian coordinates (independent of data layout: row major, column major, regular sparse, …) Operational Normal Form(ONF) = reduced form for 1-d memory layout(s). Defines How to Build the code on processor/memory hierarchies. ONF reveals loops and control..")
6
College of Nanoscale Science and Engineering Applications Levels of Processor/Memory Hierarchy Can be Modeled by Increasing Dimensionality of Data Array. –Additional dimension for each level of the hierarchy. –Envision data as reshaped/transposed to reflect mapping to increased dimensionality. –An Index Calculus automatically transforms algorithm to reflect restructured data array. –Data, layout, data movement, and scalarization automatically generated based on MoA descriptions and Psi Calculus Definitions of Array Operations, Functions and their compositions. –Arrays are any dimension, even 0, I.e. scalars

7
College of Nanoscale Science and Engineering Processor/Memory Hierarchy continued Math and indexing operations in same expression Framework for design space search –Rigorous and provably correct –Extensible to complex architectures Approach Mathematics of Arrays Example:“raising” array dimensionality y= conv intricate math intricate memory accesses (indexing) (x)(x) Memory Hierarchy Parallelism Main Memory L2 Cache L1 Cache Map x: Map: P0 P1 P2 P0 P1 P2
 (x)(x) Memory Hierarchy Parallelism Main Memory L2 Cache L1 Cache Map x: Map: P0 P1 P2 P0 P1 P2")
8
College of Nanoscale Science and Engineering Manipulation of an array Given a 3 by 5 by 4 array: Shape vector: Index vector: Used to select:

9
College of Nanoscale Science and Engineering More Definitions Reverse: Given an array The reversal is given through indexing Examples:

10
College of Nanoscale Science and Engineering Some Psi Calculus Operations Built Using & Shapes Operations take drop rotate cat unaryOmega binaryOmega reshape iota Arguments Vector A, int N Vector A, Vector B Operation Op, dimension D, Array A Operation Op, Dimension Adim. Array A, Dimension Bdim, Array B Vector A, Vector B int N Definition Forms a Vector of the first N elements of A Forms a Vector of the last (A.size-N) elements of A Forms a Vector of the last N elements of A concatenated to the other elements of A Forms a Vector that is the concatenation of A and B Applies unary operator Op to D-dimensional components of A (like a for all loop) Applies binary operator Op to Adim-dimensional components of A and Bdim-dimensional components of B (like a for all loop) Reshapes B into an array having A.size dimensions, where the length in each dimension is given by the corresponding element of A Forms a vector of size N, containing values 0.. N-1 = index permutation= operators= restructuring= index generation
 elements of A Forms a Vector of the last N elements of A concatenated to the other elements of A Forms a Vector that is the concatenation of A and B Applies unary operator Op to D-dimensional components of A (like a for all loop) Applies binary operator Op to Adim-dimensional components of A and Bdim-dimensional components of B (like a for all loop) Reshapes B into an array having A.size dimensions, where the length in each dimension is given by the corresponding element of A Forms a vector of size N, containing values 0.. N-1 = index permutation= operators= restructuring= index generation.")
11
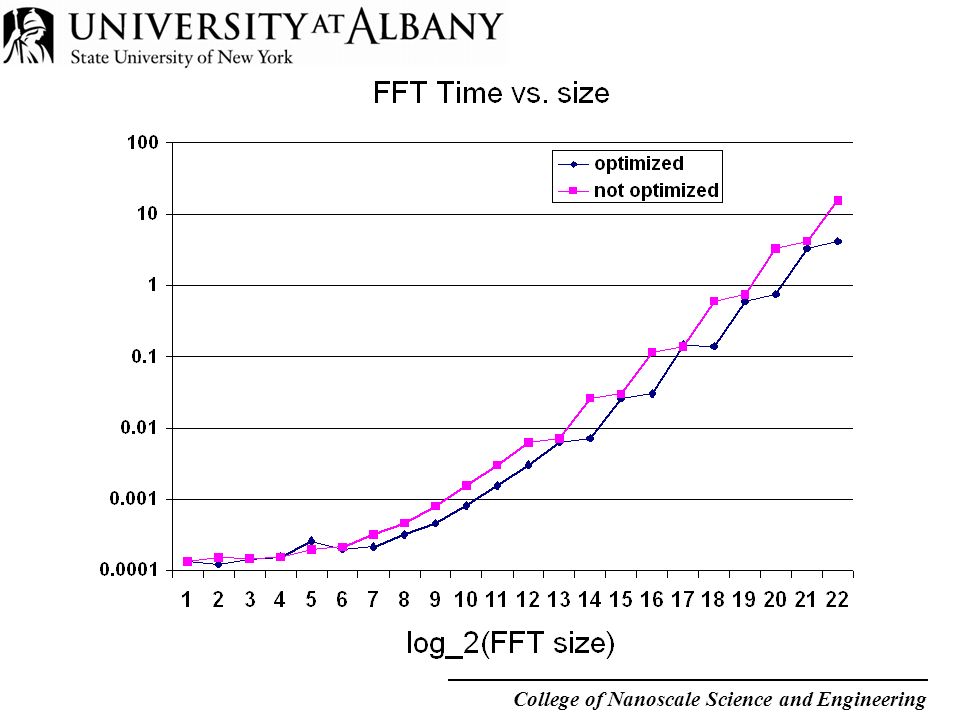
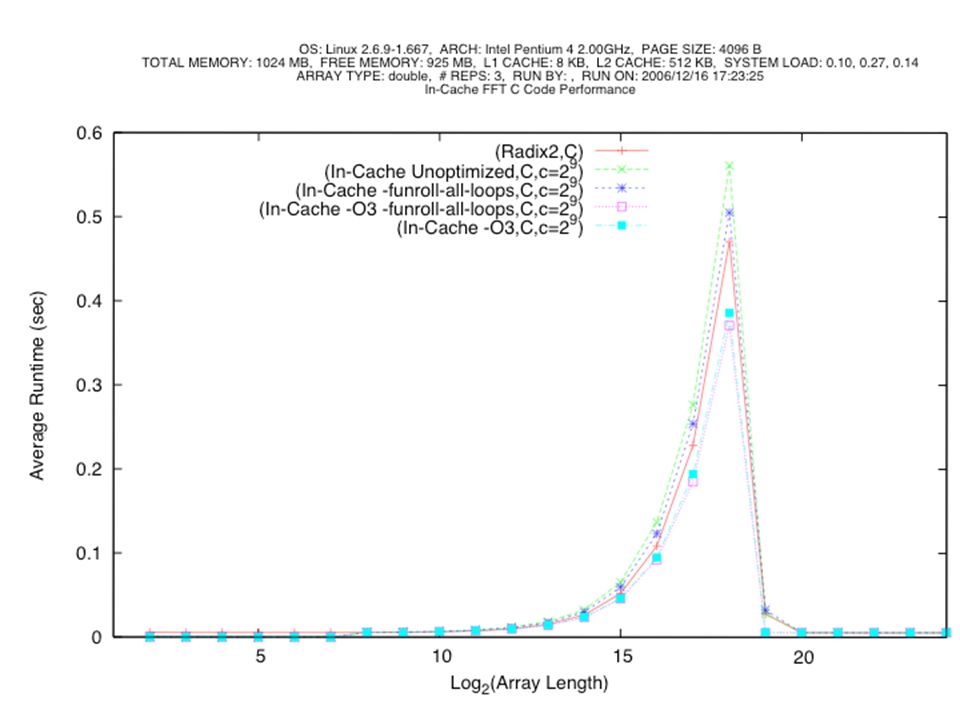
College of Nanoscale Science and Engineering New FFT algorithm: record speed Maximize in-cache operations through use of repeated transpose-reshape operations Similar to partitioning for parallel implementation Do as many operations in cache as possible Re-materialize the array to achieve locality Continue processing in cache and repeat process

12
College of Nanoscale Science and Engineering Example Assume cache size c = 4; input vector length n = 32; number of rows r = n/c = 8 Generate vector of indices: Use re-shape operator to generate a matrix

13
College of Nanoscale Science and Engineering Starting Matrix Each row is of length equal to the size “c” Standard butterfly applied to each row as...

14
College of Nanoscale Science and Engineering Next transpose To continue further would induce cache misses so transpose and reshape. Transpose-reshape operation composed over indices (only result is materialized. The transpose is:

15
College of Nanoscale Science and Engineering Resulting Transpose-Reshape Materialize the transpose- reshaped array B Carry out butterfly operation on each row Weights are re-ordered Access patterns are standard...

16
College of Nanoscale Science and Engineering Transpose-Reshape again As before: to proceed further would induce cache misses so: Do the transpose-reshape again (composing indices) The transpose is:
 The transpose is:")
17
College of Nanoscale Science and Engineering Last step (in this example) Materialize the composed transpose-reshaped array C Carry out the last step of the FFT This last step corresponds to cycles of length 2 involving elements 0 and 16, 1 and 17, etc. 1

18
College of Nanoscale Science and Engineering Final Transpose Data has been permuted numerous times Multiple reshape-transposes We could reverse the transformations There would be multiple steps, multiple writes. Viewing the problem as an n-cube(hypercube for radix 2) allows us to use the number of reshape-transposes as an argument to rotate(or shift) of a vector generated from the dimension of the hypercube. This rotated vector is used as an argument to binary transpose. Permutes everything at once. Express Algebraically, Psi reduce to DNF then ONF for a generic design. ONF has only two loops no matter what dimension hypercube(or n-cube for radix = n) we start with.
 allows us to use the number of reshape-transposes as an argument to rotate(or shift) of a vector generated from the dimension of the hypercube. This rotated vector is used as an argument to binary transpose. Permutes everything at once. Express Algebraically, Psi reduce to DNF then ONF for a generic design. ONF has only two loops no matter what dimension hypercube(or n-cube for radix = n) we start with..")
19
College of Nanoscale Science and Engineering

22
Summary All operations have been carried out in cache at the price of re-arranging the data Data blocks can be of any size (powers of the radix): need not equal the cache size Optimum performance: tradeoff between reduction of cache misses and cost of transpose-reshape operations Number of transpose-reshape operations determined by the data block size (cache size) Record performance: up to factor of 4 better than libraries
: need not equal the cache size Optimum performance: tradeoff between reduction of cache misses and cost of transpose-reshape operations Number of transpose-reshape operations determined by the data block size (cache size) Record performance: up to factor of 4 better than libraries")
23
College of Nanoscale Science and Engineering Science Direct 25 Hottest Articles

24
College of Nanoscale Science and Engineering Book under review at springer

25
College of Nanoscale Science and Engineering New paper at J. Comp. Phys.

Similar presentations




, Kerry Barnes (Gedae), James Steed (Gedae)>")




 Damian Schofield. HCI 530: Seminar (HCI) Transforms –Two Dimensional –Three Dimensional The Graphics Pipeline.>")







 - Asim LUMS 1 Cache Basics Adapted from a presentation by Beth Richardson>")

