Download presentation
Presentation is loading. Please wait.

1
8-Speech Recognition Speech Recognition Concepts Speech Recognition Approaches Recognition Theories Bayse Rule Simple Language Model P(A|W) Network Types 1
 Network Types 1")
2
7-Speech Recognition (Cont’d) HMM Calculating Approaches Neural Components Three Basic HMM Problems Viterbi Algorithm State Duration Modeling Training In HMM 2
 HMM Calculating Approaches Neural Components Three Basic HMM Problems Viterbi Algorithm State Duration Modeling Training In HMM 2")
3
Recognition Tasks Isolated Word Recognition (IWR) Connected Word (CW), And Continuous Speech Recognition (CSR) Speaker Dependent, Multiple Speaker, And Speaker Independent Vocabulary Size Small <20 Medium >100, <1000 Large >1000, <10000 Very Large >10000 3
 Connected Word (CW), And Continuous Speech Recognition (CSR) Speaker Dependent, Multiple Speaker, And Speaker Independent Vocabulary Size Small <20 Medium >100, <1000 Large >1000, <10000 Very Large >")
4
Speech Recognition Concepts 4 NLP Speech Processing Text Speech NLP Speech Processing Speech Understanding Speech Synthesis Text Phone Sequence Speech Recognition Speech recognition is inverse of Speech Synthesis

5
Speech Recognition Approaches Bottom-Up Approach Top-Down Approach Blackboard Approach 5

6
Bottom-Up Approach 6 Signal Processing Feature Extraction Segmentation Signal Processing Feature Extraction Segmentation Sound Classification Rules Phonotactic Rules Lexical Access Language Model Voiced/Unvoiced/Silence Knowledge Sources Recognized Utterance

7
Top-Down Approach 7 Unit Matching System Feature Analysis Lexical Hypo thesis Syntactic Hypo thesis Semantic Hypo thesis Utterance Verifier/ Matcher Inventory of speech recognition units Word Dictionary Grammar Task Model Recognized Utterance

8
Blackboard Approach 8 Environmental Processes Acoustic Processes Lexical Processes Syntactic Processes Semantic Processes Black board

9
Recognition Theories Articulatory Based Recognition Use from Articulatory system for recognition This theory is the most successful until now Auditory Based Recognition Use from Auditory system for recognition Hybrid Based Recognition Is a hybrid from the above theories Motor Theory Model the intended gesture of speaker 9

10
Recognition Problem We have the sequence of acoustic symbols and we want to find the words that expressed by speaker Solution : Finding the most probable of word sequence by having Acoustic symbols 10

11
Recognition Problem A : Acoustic Symbols W : Word Sequence we should find so that 11

12
Bayse Rule 12

13
Bayse Rule (Cont’d) 13
 13")
14
Simple Language Model 14 Computing this probability is very difficult and we need a very big database. So we use from Trigram and Bigram models.

15
Simple Language Model (Cont’d) 15 Trigram : Bigram : Monogram :
 15 Trigram : Bigram : Monogram :")
16
Simple Language Model (Cont’d) 16 Computing Method : Number of happening W3 after W1W2 Total number of happening W1W2 AdHoc Method :
 16 Computing Method : Number of happening W3 after W1W2 Total number of happening W1W2 AdHoc Method :")
17
Error Production Factor Prosody (Recognition should be Prosody Independent) Noise (Noise should be prevented) Spontaneous Speech 17
 Noise (Noise should be prevented) Spontaneous Speech 17")
18
P(A|W) Computing Approaches Dynamic Time Warping (DTW) Hidden Markov Model (HMM) Artificial Neural Network (ANN) Hybrid Systems 18
 Computing Approaches Dynamic Time Warping (DTW) Hidden Markov Model (HMM) Artificial Neural Network (ANN) Hybrid Systems 18")
19
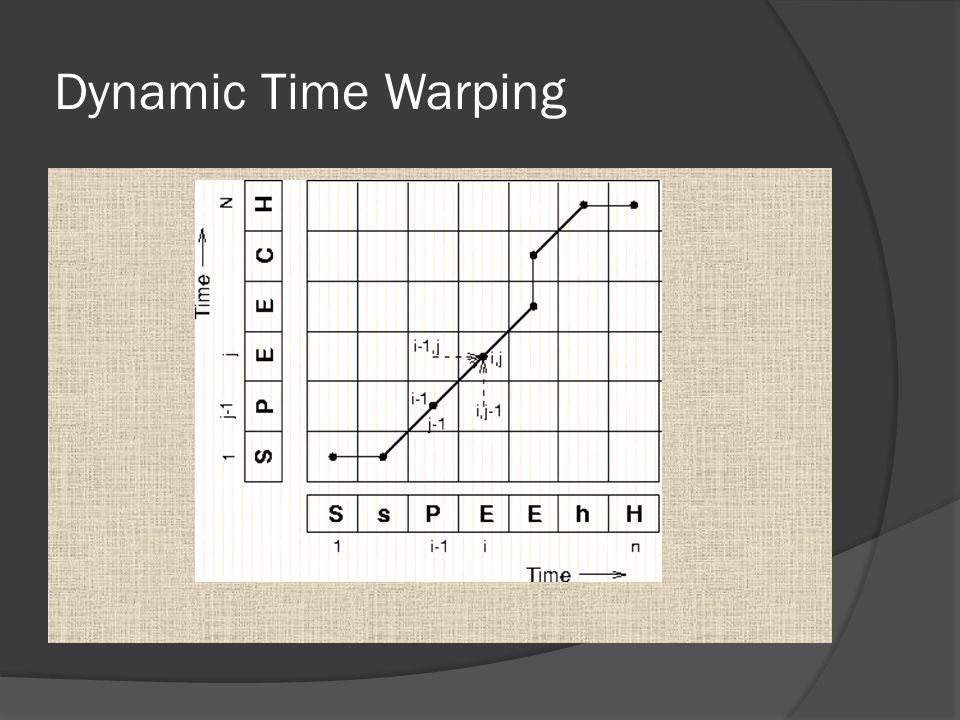
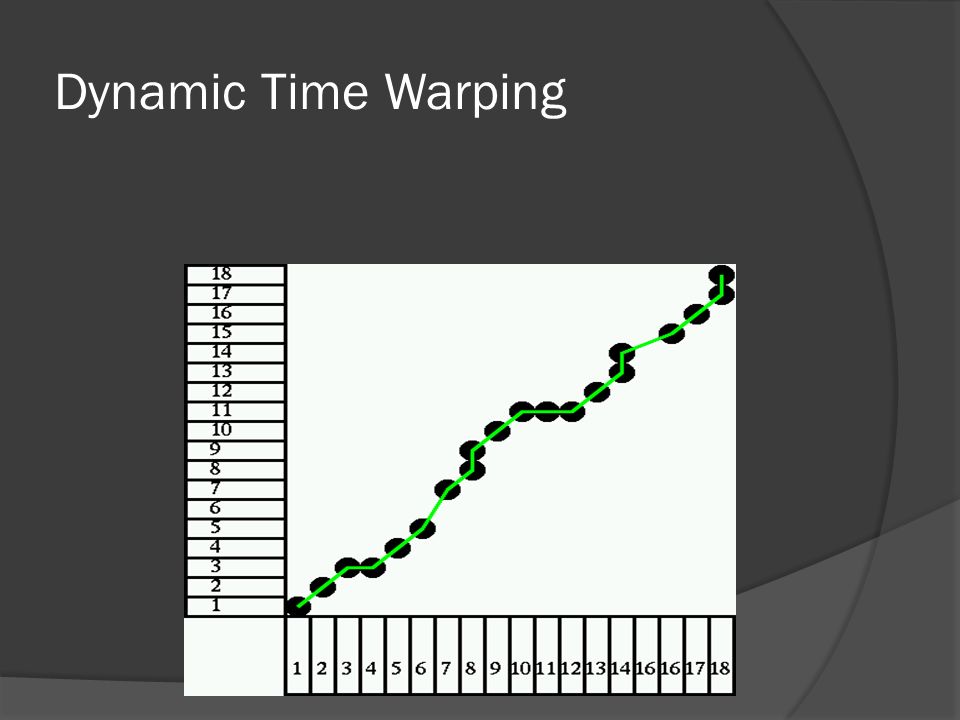
Dynamic Time Warping

23
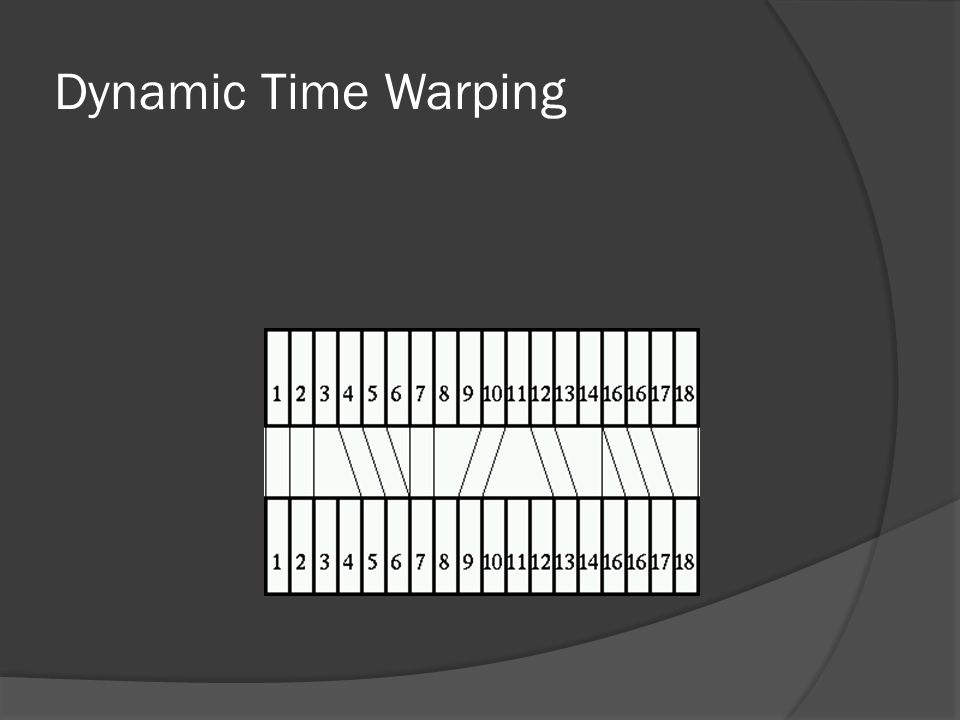
Search Limitation : - First & End Interval - Global Limitation - Local Limitation

24
Dynamic Time Warping Global Limitation :

25
Dynamic Time Warping Local Limitation :

26
Artificial Neural Network 26...... Simple Computation Element of a Neural Network

27
Artificial Neural Network (Cont’d) Neural Network Types Perceptron Time Delay Time Delay Neural Network Computational Element (TDNN) 27
 Neural Network Types Perceptron Time Delay Time Delay Neural Network Computational Element (TDNN) 27")
28
Artificial Neural Network (Cont’d) 28... Single Layer Perceptron
 Single Layer Perceptron")
29
Artificial Neural Network (Cont’d) 29... Three Layer Perceptron...
 Three Layer Perceptron...")
30
2.5.4.2 Neural Network Topologies 30

31
TDNN 31

32
2.5.4.6 Neural Network Structures for Speech Recognition 32

33
2.5.4.6 Neural Network Structures for Speech Recognition 33

34
Hybrid Methods Hybrid Neural Network and Matched Filter For Recognition 34 PATTERN CLASSIFIER Speech Acoustic Features Delays Output Units

35
Neural Network Properties The system is simple, But too much iteration is needed for training Doesn’t determine a specific structure Regardless of simplicity, the results are good Training size is large, so training should be offline Accuracy is relatively good 35

36
Pre-processing Different preprocessing techniques are employed as the front end for speech recognition systems The choice of preprocessing method is based on the task, the noise level, the modeling tool, etc. 36

37
37

38
38

39
39

40
40

41
41

42
42

43
روش MFCC روش MFCC مبتني بر نحوه ادراک گوش انسان از اصوات مي باشد. روش MFCC نسبت به ساير ويژگِيها در محيطهاي نويزي بهتر عمل ميکند. MFCC اساساً جهت کاربردهاي شناسايي گفتار ارايه شده است اما در شناسايي گوينده نيز راندمان مناسبي دارد. واحد شنيدار گوش انسان Mel مي باشد که به کمک رابطه زير بدست مي آيد: 43

44
مراحل روش MFCC مرحله 1: نگاشت سيگنال از حوزه زمان به حوزه فرکانس به کمک FFT زمان کوتاه. 44 : سيگنال گفتارZ(n) : تابع پنجره مانند پنجره همينگW(n( W F = e -j2 π/F m : 0,…,F – 1; : طول فريم گفتاري.F
 : تابع پنجره مانند پنجره همينگW(n( W F = e -j2 π/F m : 0,…,F – 1; : طول فريم گفتاري.F.")
45
مراحل روش MFCC مرحله 2: يافتن انرژي هر کانال بانک فيلتر. M تعداد بانکهاي فيلتر مبتني بر معيار مل ميباشد. تابع فيلترهاي بانک فيلتر است. 45

46
توزيع فيلتر مبتنی بر معيار مل 46

47
مراحل روش MFCC مرحله 4: فشرده سازي طيف و اعمال تبديل DCT جهت حصول به ضرايب MFCC 47 در رابطه بالا L،...،0=n مرتبه ضرايب MFCC ميباشد. در رابطه بالا L،...،0=n مرتبه ضرايب MFCC ميباشد.

48
روش مل - کپستروم 48 Mel-scaling فریم بندی IDCT |FFT| 2 Low-order coefficients Differentiator Cepstra Delta & Delta Delta Cepstra سیگنال زمانی Logarithm

49
ضرایب مل کپستروم (MFCC) 49
 49")
50
ویژگی های مل کپستروم (MFCC) نگاشت انرژی های بانک فیلترمل درجهتی که واریانس آنها ماکسیمم باشد (با استفاده از DCT ) استقلال ویژگی های گفتار به صورت غیرکامل نسبت به یکدیگر(تاثیر DCT ) پاسخ مناسب در محیطهای تمیز کاهش کارایی آن در محیطهای نویزی 50
 نگاشت انرژی های بانک فیلترمل درجهتی که واریانس آنها ماکسیمم باشد (با استفاده از DCT ) استقلال ویژگی های گفتار به صورت غیرکامل نسبت به یکدیگر(تاثیر DCT ) پاسخ مناسب در محیطهای تمیز کاهش کارایی آن در محیطهای نویزی 50")
51
Time-Frequency analysis Short-term Fourier Transform Standard way of frequency analysis: decompose the incoming signal into the constituent frequency components. W(n): windowing function N: frame length p: step size 51
: windowing function N: frame length p: step size 51.")
52
Critical band integration Related to masking phenomenon: the threshold of a sinusoid is elevated when its frequency is close to the center frequency of a narrow-band noise Frequency components within a critical band are not resolved. Auditory system interprets the signals within a critical band as a whole 52

53
Bark scale 53

54
Feature orthogonalization Spectral values in adjacent frequency channels are highly correlated The correlation results in a Gaussian model with lots of parameters: have to estimate all the elements of the covariance matrix Decorrelation is useful to improve the parameter estimation. 54

55
Cepstrum Computed as the inverse Fourier transform of the log magnitude of the Fourier transform of the signal The log magnitude is real and symmetric -> the transform is equivalent to the Discrete Cosine Transform. Approximately decorrelated 55

56
Principal Component Analysis Find an orthogonal basis such that the reconstruction error over the training set is minimized This turns out to be equivalent to diagonalize the sample autocovariance matrix Complete decorrelation Computes the principal dimensions of variability, but not necessarily provide the optimal discrimination among classes 56

57
Principal Component Analysis (PCA) Mathematical procedure that transforms a number of (possibly) correlated variables into a (smaller) number of uncorrelated variables called principal components (PC) Find an orthogonal basis such that the reconstruction error over the training set is minimized This turns out to be equivalent to diagonalize the sample autocovariance matrix Complete decorrelation Computes the principal dimensions of variability, but not necessarily provide the optimal discrimination among classes 57
 Mathematical procedure that transforms a number of (possibly) correlated variables into a (smaller) number of uncorrelated variables called principal components (PC) Find an orthogonal basis such that the reconstruction error over the training set is minimized This turns out to be equivalent to diagonalize the sample autocovariance matrix Complete decorrelation Computes the principal dimensions of variability, but not necessarily provide the optimal discrimination among classes 57")
58
PCA (Cont.) Algorithm 58 Apply Transform Output = (R- dim vectors) Input= (N-dim vectors) Covariance matrix Transform matrix Eigen values Eigen vectors
 Algorithm 58 Apply Transform Output = (R- dim vectors) Input= (N-dim vectors) Covariance matrix Transform matrix Eigen values Eigen vectors")
59
PCA (Cont.) PCA in speech recognition systems 59
 PCA in speech recognition systems 59")
60
Linear discriminant Analysis Find an orthogonal basis such that the ratio of the between-class variance and within-class variance is maximized This also turns to be a general eigenvalue-eigenvector problem Complete decorrelation Provide the optimal linear separability under quite restrict assumption 60

61
PCA vs. LDA 61

62
Spectral smoothing Formant information is crucial for recognition Enhance and preserve the formant information: Truncating the number of cepstral coefficients Linear prediction: peak-hugging property 62

63
Temporal processing To capture the temporal features of the spectral envelop; to provide the robustness: Delta Feature: first and second order differences; regression Cepstral Mean Subtraction: ○ For normalizing for channel effects and adjusting for spectral slope 63

64
RASTA (RelAtive SpecTral Analysis) Filtering of the temporal trajectories of some function of each of the spectral values; to provide more reliable spectral features This is usually a bandpass filter, maintaining the linguistically important spectral envelop modulation (1-16Hz) 64
 Filtering of the temporal trajectories of some function of each of the spectral values; to provide more reliable spectral features This is usually a bandpass filter, maintaining the linguistically important spectral envelop modulation (1-16Hz) 64")
65
65

66
RASTA-PLP 66

67
67

68
68

69
Language Models for LVCSR Word Pair Model: Specify which word pairs are valid

70
Statistical Language Modeling

71
Perplexity of the Language Model Entropy of the Source: First order entropy of the source: If the source is ergodic, meaning its statistical properties can be completely characterized in a sufficiently long sequence that the Source puts out,

72
We often compute H based on a finite but sufficiently large Q: H is the degree of difficulty that the recognizer encounters, on average, When it is to determine a word from the same source. Using language model, if the N-gram language model P N (W) is used, An estimate of H is: In general: Perplexity is defined as:
 is used, An estimate of H is: In general: Perplexity is defined as:.")
73
Overall recognition system based on subword units

Similar presentations


 signal using different mathematical models in Matlab to predict.>")














 HMM Calculating Approaches Neural Components Three Basic HMM Problems Viterbi Algorithm State Duration Modeling Training.>")

 Speech.>")