Download presentation
Presentation is loading. Please wait.

1
Bioinformatics Jack Min Office 3012 Office hours: TR 12:15 – 4

2
How would you define "bioinformatics"? Can you distinguish between a gene and a genome? Do you know what a Blast search is? Do you know what any of the letters in "blast" represent? What is Genbank? What is NCBI? What is meant by "codon usage"?

3
Here are two nucleotide sequences: (i) AGTCGGTAACCTAAG (ii) GGCAAAUACUAAGGA Which of these is a DNA sequence? Explain your answer. Here is a DNA sequence: 5' ATTGGRTCCAATA 3‘ (i) What do the 5' and 3' mean? (ii) What does the R stand for? (iii) Write the sequence of the complementary DNA strand, using the same notation.
 What do the 5 and 3 mean. (ii) What does the R stand for. (iii) Write the sequence of the complementary DNA strand, using the same notation..")
4
What is meant by the "template" and "coding" strands of DNA? Name three different kinds of RNA. Which amino acids are represented by the following symbols?A L Q K G W

5
International Union of Pure and Applied Chemistry

6
What is a PAM matrix? Can both nucleotide and amino acid sequences be used to build molecular phylogenies? Explain the method of parsimony for building sequence-based phylogenies. What is the program CLUSTAL used for? What do you know about microarrays? For instance, are there different types of microarrays, and what are they used for?

7
This question is to test your general knowledge of genetics and molecular biology. Can you define the following terms? (a) Gene (b)Locus (c) Allele (d) Linkage (e) Linkage disequilibrium (f) synonymous substitution (g) Intron (h) concerted evolution (i) Pleiotropy (j) PCR (k) RFLP (l) Haplotype
 Gene (b)Locus (c) Allele (d) Linkage (e) Linkage disequilibrium (f) synonymous substitution (g) Intron (h) concerted evolution (i) Pleiotropy (j) PCR (k) RFLP (l) Haplotype.")
8
To provide an introduction to bioinformatics with a focus on the National Center for Biotechnology Information (NCBI) and EBI To focus on the analysis of DNA, RNA and proteins To introduce you to the analysis of genomes To combine theory and practice to help you solve research problems What are the goals of the course?
 and EBI To focus on the analysis of DNA, RNA and proteins To introduce you to the analysis of genomes To combine theory and practice to help you solve research problems What are the goals of the course")
9
Themes throughout the course Textbooks Web sites Literature references Gene/protein families Computer labs

10
Textbook Bioinformatics and Functional Genomics Second edition (Wiley, 2009). Reference Bioinformatics Third edition (Wiley, 2005) Baxevanis and Ouellette
 Baxevanis and Ouellette.")
11
Web sites The course website is reached via moodle: http://pevsnerlab.kennedykrieger.org/moodle (or Google “moodle bioinformatics”) --This site contains the powerpoints for each lecture. including color and black & white versions --The weekly quizzes are here The textbook website is: http://www.bioinfbook.org This has powerpoints, URLs, etc. organized by chapter

12
Literature references You are encouraged to read original source articles (posted on moodle). They will enhance your understanding of the material. Readings are optional but recommended. http://ghr.nlm.nih.gov/handbook.pdf http://www.ncbi.nlm.nih.gov/books/NBK21101/

13
Themes throughout the course: gene/protein families We will use beta globin and retinol-binding protein 4 (RBP4) as model genes/proteins throughout the course. Globins including hemoglobin and myoglobin carry oxygen. RBP4 is a member of the lipocalin family. It is a small, abundant carrier protein. We will study globins and lipocalins in a variety of contexts including --sequence alignment --gene expression --protein structure --phylogeny --homologs in various species

14
Computer labs You can use any computer you can find – Computer lab in the department, in your lab, Computers in my lab (3013)
")
15
Outline for today Definition of bioinformatics Overview of the NCBI website Accessing information about DNA and proteins --Definition of an accession number --Four ways to find information on proteins and DNA Access to biomedical literature Pairwise alignment: introduction

16
What is Bioinformatics? Broad definition: The use of computational tools for: acquiring, storing and analyzing biological information. Narrow definition: The use of computational tools for: acquiring, storing and analyzing molecular sequence information.

17
Interface of biology and computers Analysis of proteins, genes and genomes using computer algorithms and computer databases Genomics is the analysis of genomes. The tools of bioinformatics are used to make sense of the billions of base pairs of DNA that are sequenced by genomics projects. What is bioinformatics?

18
Tool-users Tool-makers bioinformatics public health informatics medical informatics infrastructure databases algorithms

19
Three perspectives on bioinformatics The cell The organism The tree of life Page 4

20
DNARNAphenotypeprotein Page 5

21
Time of development Body region, physiology, pharmacology, pathology Page 5

22
After Pace NR (1997) Science 276:734 Page 6
 Science 276:734 Page 6")
23
Fig. 2.1 Page 17

24
Growth of GenBank + Whole Genome Shotgun (1982-November 2008) Number of sequences in GenBank (millions) 0 50 100 150 200 250 198219871992199720022007 Base pairs of DNA in GenBank (billions) Base pairs in GenBank + WGS (billions)
 Number of sequences in GenBank (millions) Base pairs of DNA in GenBank (billions) Base pairs in GenBank + WGS (billions)")
25
DNARNAprotein Central dogma of molecular biology genometranscriptomeproteome Central dogma of bioinformatics and genomics

26
DNARNA cDNA ESTs UniGene phenotype genomic DNA databases protein sequence databases protein Fig. 2.2 Page 20

27
GenBankEMBLDDBJ There are three major public DNA databases The underlying raw DNA sequences are identical Page 16

28
GenBankEMBLDDBJ Housed at EBI European Bioinformatics Institute There are three major public DNA databases Housed at NCBI National Center for Biotechnology Information Housed in Japan Page 16

29
The Trace Archive at NCBI contains over 2 billion traces 11/08

30
Taxonomy at NCBI: ~200,000 species are represented in GenBank http://www.ncbi.nlm.nih.gov/Taxonomy/txstat.cgi11/08

31
The most sequenced organisms in GenBank Homo sapiens 13.1 billion bases Mus musculus 8.4b Rattus norvegicus 6.1b Bos taurus5.2b Zea mays 4.6b Sus scrofa (wild boar)3.6b Danio rerio (zebrafish) 3.0b Oryza sativa (japonica) 1.5b Strongylocentrotus purpurata (sea urchins)1.4b Nicotiana tabacum 1.1b Updated 11-6-08 GenBank release 168.0 Excluding WGS, organelles, metagenomics Table 2-2 Page 18
3.6b Danio rerio (zebrafish) 3.0b Oryza sativa (japonica) 1.5b Strongylocentrotus purpurata (sea urchins)1.4b Nicotiana tabacum 1.1b Updated GenBank release Excluding WGS, organelles, metagenomics Table 2-2 Page 18")
32
National Center for Biotechnology Information (NCBI) www.ncbi.nlm.nih.gov Page 24
 Page 24")
33
www.ncbi.nlm.nih.gov Fig. 2.5 Page 25

35
Fig. 2.5 Page 25

36
PubMed is… National Library of Medicine's search service 16 million citations in MEDLINE links to participating online journals PubMed tutorial (via “Education” on side bar) Page 24
 Page 24")
37
Entrez integrates… the scientific literature; DNA and protein sequence databases; 3D protein structure data; population study data sets; assemblies of complete genomes Page 24

38
Entrez is a search and retrieval system that integrates NCBI databases Page 24

39
BLAST is… Basic Local Alignment Search Tool NCBI's sequence similarity search tool supports analysis of DNA and protein databases 100,000 searches per day Page 25

40
OMIM is… Online Mendelian Inheritance in Man catalog of human genes and genetic disorders created by Dr. Victor McKusick; led by Dr. Ada Hamosh at JHMI Page 25

41
Books is… searchable resource of on-line books Page 26

42
TaxBrowser is… browser for the major divisions of living organisms (archaea, bacteria, eukaryota, viruses) taxonomy information such as genetic codes molecular data on extinct organisms Page 26
 taxonomy information such as genetic codes molecular data on extinct organisms Page 26")
43
Structure site includes… Molecular Modelling Database (MMDB) biopolymer structures obtained from the Protein Data Bank (PDB) Cn3D (a 3D-structure viewer) vector alignment search tool (VAST) Page 26
 biopolymer structures obtained from the Protein Data Bank (PDB) Cn3D (a 3D-structure viewer) vector alignment search tool (VAST) Page 26")
44
Outline for today Definition of bioinformatics Overview of the NCBI website Accessing information about DNA and proteins --Definition of an accession number --Five ways to find information on proteins and DNA Access to biomedical literature Pairwise alignment: introduction

45
Accession numbers are labels for sequences NCBI includes databases (such as GenBank) that contain information on DNA, RNA, or protein sequences. You may want to acquire information beginning with a query such as the name of a protein of interest, or the raw nucleotides comprising a DNA sequence of interest. DNA sequences and other molecular data are tagged with accession numbers that are used to identify a sequence or other record relevant to molecular data. Page 26

46
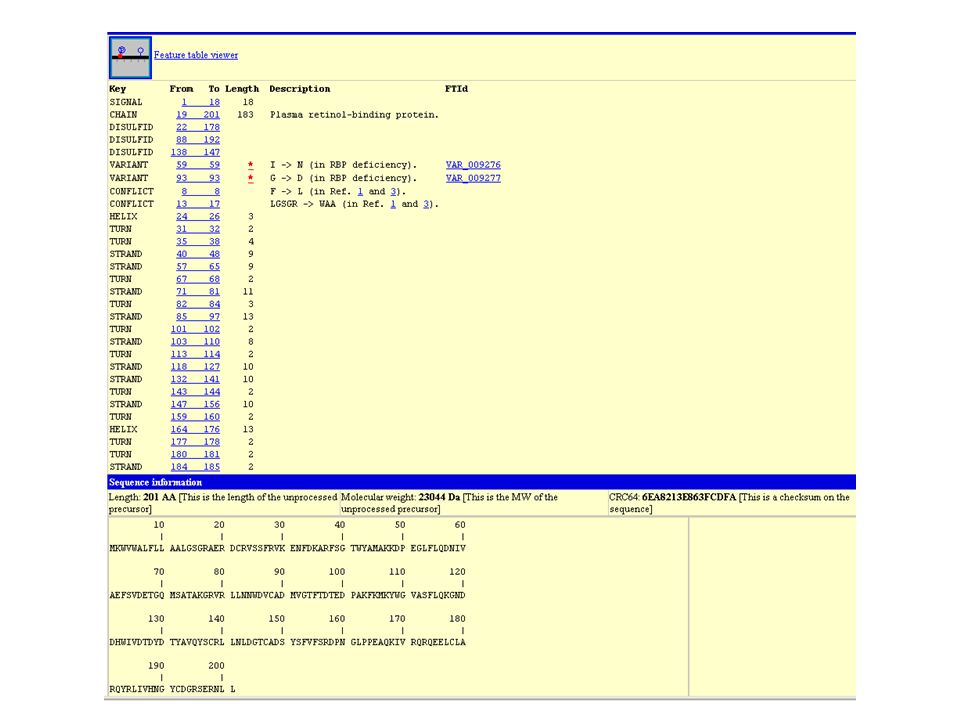
What is an accession number? An accession number is label that used to identify a sequence. It is a string of letters and/or numbers that corresponds to a molecular sequence. Examples (all for retinol-binding protein, RBP4): X02775GenBank genomic DNA sequence NT_030059Genomic contig Rs7079946dbSNP (single nucleotide polymorphism) N91759.1An expressed sequence tag (1 of 170) NM_006744RefSeq DNA sequence (from a transcript) NP_007635RefSeq protein AAC02945GenBank protein Q28369SwissProt protein 1KT7Protein Data Bank structure record protein DNA RNA Page 27
: X02775GenBank genomic DNA sequence NT_030059Genomic contig Rs dbSNP (single nucleotide polymorphism) N An expressed sequence tag (1 of 170) NM_006744RefSeq DNA sequence (from a transcript) NP_007635RefSeq protein AAC02945GenBank protein Q28369SwissProt protein 1KT7Protein Data Bank structure record protein DNA RNA Page 27.")
47
Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 27
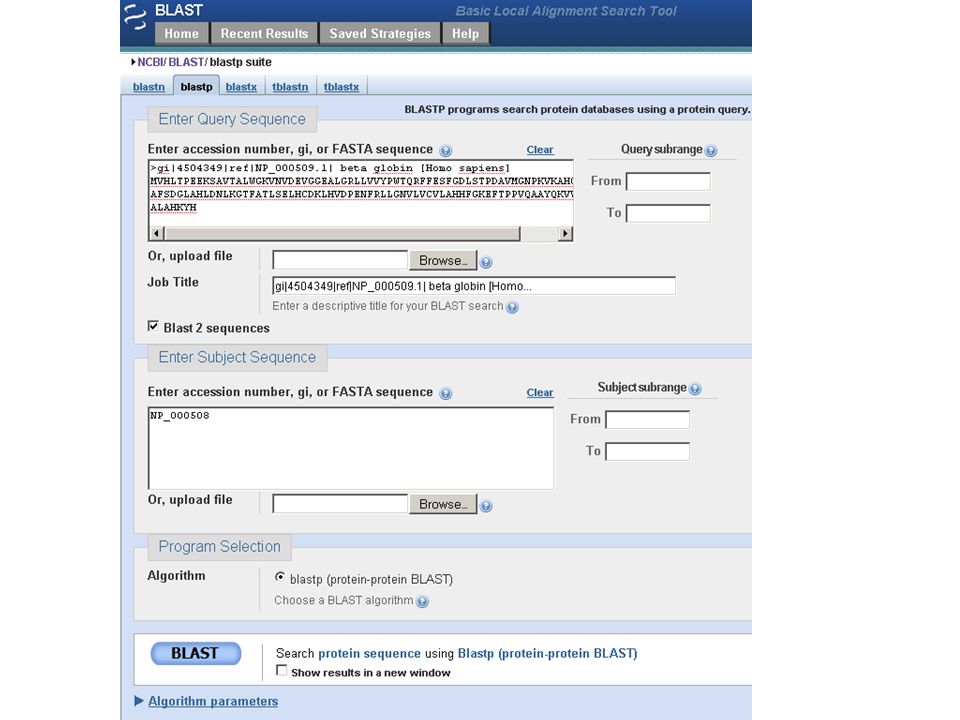
![Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 27](http://images.slideplayer.com/24/7024154/slides/slide_47.jpg "Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 27")
48
5 ways to access protein and DNA sequences [1] Entrez Gene with RefSeq Entrez Gene is a great starting point: it collects key information on each gene/protein from major databases. It covers all major organisms. RefSeq provides a curated, optimal accession number for each DNA (NM_006744) or protein (NP_007635) Page 27
![5 ways to access protein and DNA sequences [1] Entrez Gene with RefSeq Entrez Gene is a great starting point: it collects key information on each gene/protein from major databases.](http://images.slideplayer.com/24/7024154/slides/slide_48.jpg "It covers all major organisms. RefSeq provides a curated, optimal accession number for each DNA (NM_006744) or protein (NP_007635) Page 27.")
49
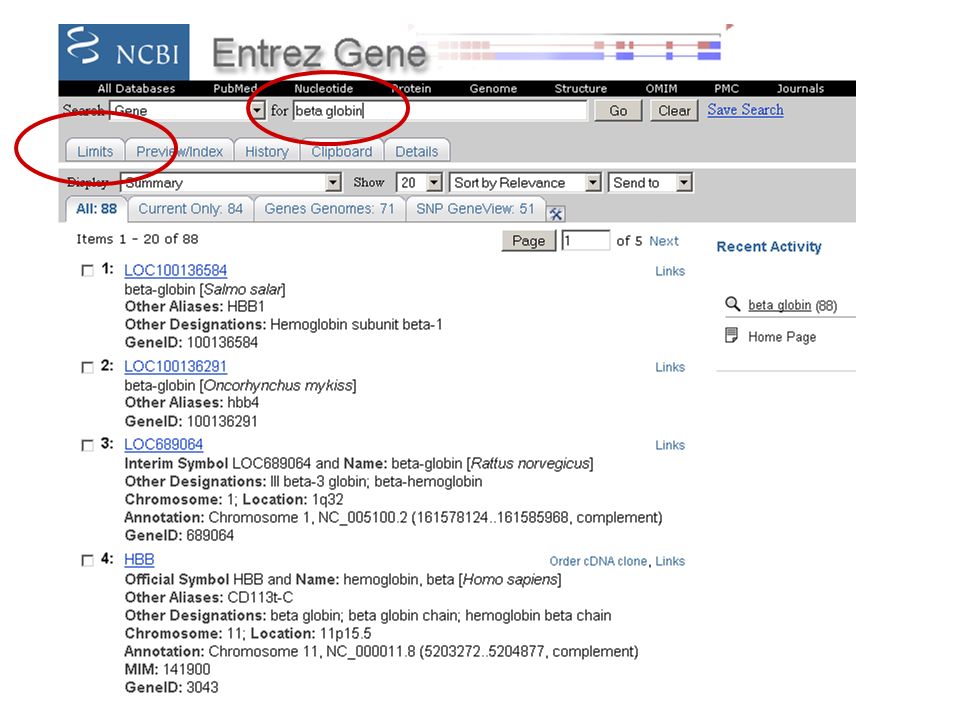
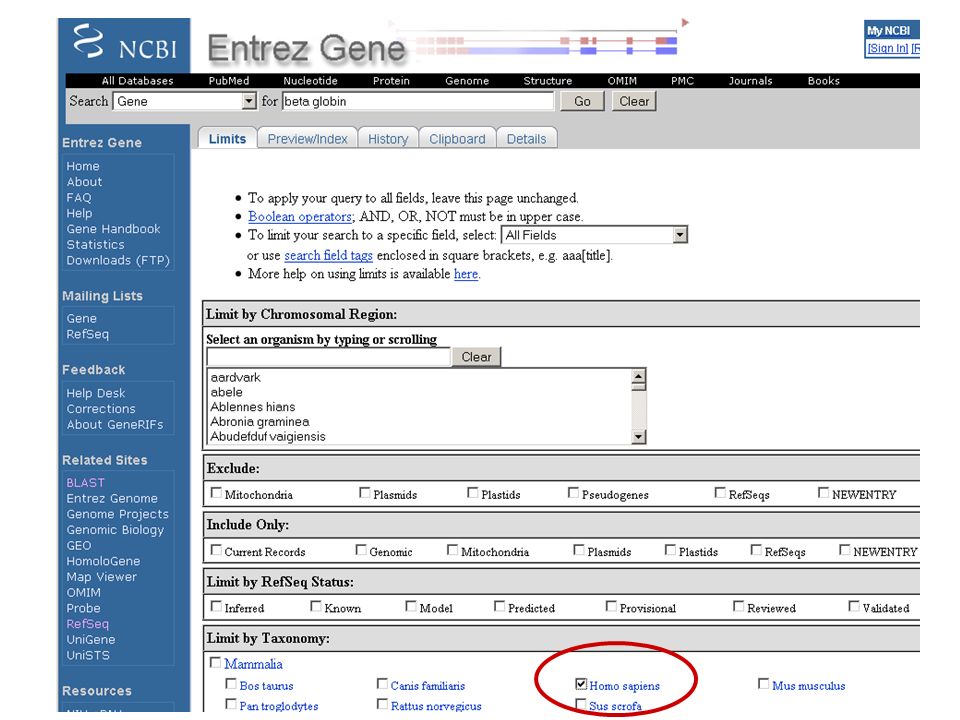
From the NCBI home page, type “beta globin” and hit “Go” revised 11/08 Fig. 2.7 Page 29

50
revised Fig. 2.7 Page 29

53
By applying limits, there are now fewer entries

54
revised Fig. 2.8 Page 30 Entrez Gene (top of page) Note that links to many other HBB database entries are available
 Note that links to many other HBB database entries are available.")
55
Entrez Gene (middle of page)
")
56
Entrez Gene (middle of page, continued)
")
57
Entrez Gene (bottom of page): RefSeqs
: RefSeqs")
58
Entrez Gene (bottom of page): non-RefSeq accessions
: non-RefSeq accessions")
59
Fig. 2.9 Page 32

60
Fig. 2.9 Page 32

61
Fig. 2.9 Page 32

62
FASTA format: versatile, compact with >one header line followed by a string of nucleotides or amino acids in the single letter code Fig. 2.10 Page 32

63
Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 31
![Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 31](http://images.slideplayer.com/24/7024154/slides/slide_63.jpg "Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 31")
64
DNARNA complementary DNA (cDNA) protein UniGene Fig. 2.3 Page 23
 protein UniGene Fig. 2.3 Page 23")
65
UniGene: unique genes via ESTs Find UniGene at NCBI: www.ncbi.nlm.nih.gov/UniGene UniGene clusters contain many expressed sequence tags (ESTs), which are DNA sequences (typically 500 base pairs in length) corresponding to the mRNA from an expressed gene. ESTs are sequenced from a complementary DNA (cDNA) library. UniGene data come from many cDNA libraries. Thus, when you look up a gene in UniGene you get information on its abundance and its regional distribution. Pages 20-21
 library. UniGene data come from many cDNA libraries. Thus, when you look up a gene in UniGene you get information on its abundance and its regional distribution. Pages")
66
Cluster sizes in UniGene This is a gene with 1 EST associated; the cluster size is 1 Fig. 2.3 Page 23

67
Cluster sizes in UniGene This is a gene with 10 ESTs associated; the cluster size is 10

68
Cluster sizes in UniGene (human) Cluster size (ESTs) Number of clusters 1 40,300 218,500 3-418,000 5-813,400 9-168,100 17-325,200 500-10001,900 1000-4000940 4000-16,00074 16,000-65,0008 UniGene build 216, 11/08 16000:70000[ESTC]
![Cluster sizes in UniGene (human) Cluster size (ESTs) Number of clusters 1 40, , , , , ,200 ,900 ,00074 16,000-65,0008 UniGene build 216, 11/ :70000[ESTC]](http://images.slideplayer.com/24/7024154/slides/slide_68.jpg "Cluster sizes in UniGene (human) Cluster size (ESTs) Number of clusters 1 40, , , , , ,200 ,900 ,00074 16,000-65,0008 UniGene build 216, 11/ :70000[ESTC]")
69
UniGene: unique genes via ESTs Conclusion: UniGene is a useful tool to look up information about expressed genes. UniGene displays information about the abundance of a transcript (expressed gene), as well as its regional distribution of expression (e.g. brain vs. liver). We will discuss UniGene further in gene expression section. Page 31
, as well as its regional distribution of expression (e.g. brain vs. liver). We will discuss UniGene further in gene expression section. Page 31.")
70
Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 31
![Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 31](http://images.slideplayer.com/24/7024154/slides/slide_70.jpg "Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 31")
71
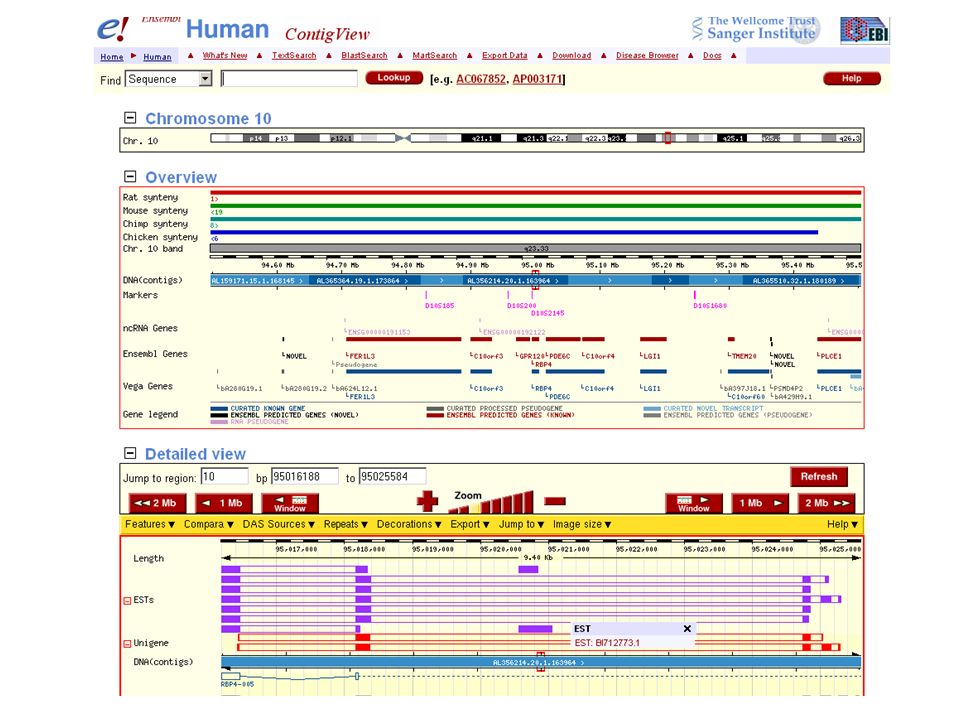
Ensembl to access protein and DNA sequences Try Ensembl at www.ensembl.org for a premier human genome web browser. We will encounter Ensembl as we study the human genome, BLAST, and other topics.

72
click human

73
enter RBP4

75
Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 33
![Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 33](http://images.slideplayer.com/24/7024154/slides/slide_75.jpg "Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 33")
76
ExPASy to access protein and DNA sequences ExPASy sequence retrieval system (ExPASy = Expert Protein Analysis System) Visit http://www.expasy.ch/ Page 33
 Visit Page 33")
77
Fig. 2.11 Page 33

79
Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 33
![Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 33](http://images.slideplayer.com/24/7024154/slides/slide_79.jpg "Five ways to access DNA and protein sequences [1] Entrez Gene with RefSeq [2] UniGene [3] European Bioinformatics Institute (EBI) and Ensembl (separate from NCBI) [4] ExPASy Sequence Retrieval System (separate from NCBI) [5] UCSC Genome Browser Page 33")
80
[1] Visit http://genome.ucsc.edu/, click Genome Browser [2] Choose organisms, enter query (beta globin), hit submit
![[1] Visit click Genome Browser [2] Choose organisms, enter query (beta globin), hit submit](http://images.slideplayer.com/24/7024154/slides/slide_80.jpg "[1] Visit click Genome Browser [2] Choose organisms, enter query (beta globin), hit submit")
81
Example of how to access sequence data: HIV-1 pol There are many possible approaches. Begin at the main page of NCBI, and type an Entrez query: hiv-1 pol Page 34

82
11/08

83
Page 34 Searching for HIV-1 pol: Following the “genome” link yields a manageable five results

84
Example of how to access sequence data: HIV-1 pol For the Entrez query: hiv-1 pol there are about 80,000 nucleotide or protein records (and >200,000 records for a search for “hiv-1”), but these can easily be reduced in two easy steps: --specify the organism, e.g. hiv-1[organism] --limit the output to RefSeq! Page 34

85
only 1 RefSeq over 200,000 nucleotide entries for HIV-1

86
Examples of how to access sequence data: histone query for “histone”# results protein records21847 RefSeq entries7544 RefSeq (limit to human)1108 NOT deacetylase697 At this point, select a reasonable candidate (e.g. histone 2, H4) and follow its link to Entrez Gene. There, you can confirm you have the right gene/protein. 8-12-06
 and follow its link to Entrez Gene. There, you can confirm you have the right gene/protein")
88
Outline for today Definition of bioinformatics Overview of the NCBI website Accessing information about DNA and proteins --Definition of an accession number --Four ways to find information on proteins and DNA Access to biomedical literature Pairwise alignment: introduction

89
PubMed at NCBI to find literature information

90
PubMed is the NCBI gateway to MEDLINE. MEDLINE contains bibliographic citations and author abstracts from over 4,600 journals published in the United States and in 70 foreign countries. It has >18 million records dating back to 1950s. Page 35 Updated 11-08

91
MeSH is the acronym for "Medical Subject Headings." MeSH is the list of the vocabulary terms used for subject analysis of biomedical literature at NLM. MeSH vocabulary is used for indexing journal articles for MEDLINE. The MeSH controlled vocabulary imposes uniformity and consistency to the indexing of biomedical literature. Page 35

94
lipocalin AND disease (60 results) lipocalin OR disease (1,650,000 results) lipocalin NOT disease (530 results) 1 AND 2 1 OR 2 1 NOT 2 1 1 1 2 2 2 Fig. 2.12 Page 34

95
true positive “globin” is found “globin” is not found “globin” is present “globin” is absent Article contents: Search result: true negative false negative ( article discusses globins ) false positive ( article does not discuss globins )
 false positive ( article does not discuss globins )")
96
Pairwise sequence alignment

97
Outline: pairwise alignment Overview and examples Definitions: homologs, paralogs, orthologs Assigning scores to aligned amino acids: Dayhoff’s PAM matrices Alignment algorithms: Needleman-Wunsch, Smith-Waterman Statistical significance of pairwise alignments

98
It is used to decide if two proteins (or genes) are related structurally or functionally It is used to identify domains or motifs that are shared between proteins It is the basis of BLAST searching It is used in the analysis of genomes Pairwise sequence alignment is the most fundamental operation of bioinformatics
 are related structurally or functionally It is used to identify domains or motifs that are shared between proteins It is the basis of BLAST searching It is used in the analysis of genomes Pairwise sequence alignment is the most fundamental operation of bioinformatics")
101
Pairwise alignment: protein sequences can be more informative than DNA protein is more informative (20 vs 4 characters); many amino acids share related biophysical properties codons are degenerate: changes in the third position often do not alter the amino acid that is specified protein sequences offer a longer “look-back” time DNA sequences can be translated into protein, and then used in pairwise alignments
; many amino acids share related biophysical properties codons are degenerate: changes in the third position often do not alter the amino acid that is specified protein sequences offer a longer look-back time DNA sequences can be translated into protein, and then used in pairwise alignments")
102
Page 54

103
DNA can be translated into six potential proteins 5’ CAT CAA 5’ ATC AAC 5’ TCA ACT 5’ GTG GGT 5’ TGG GTA 5’ GGG TAG Pairwise alignment: protein sequences can be more informative than DNA 5’ CATCAACTACAACTCCAAAGACACCCTTACACATCAACAAACCTACCCAC 3’ 3’ GTAGTTGATGTTGAGGTTTCTGTGGGAATGTGTAGTTGTTTGGATGGGTG 5’

104
Pairwise alignment: protein sequences can be more informative than DNA Many times, DNA alignments are appropriate --to confirm the identity of a cDNA --to study noncoding regions of DNA --to study DNA polymorphisms --example: Neanderthal vs modern human DNA Query: 181 catcaactacaactccaaagacacccttacacccactaggatatcaacaaacctacccac 240 |||||||| |||| |||||| ||||| | ||||||||||||||||||||||||||||||| Sbjct: 189 catcaactgcaaccccaaagccacccct-cacccactaggatatcaacaaacctacccac 247

105
Pairwise alignment The process of lining up two sequences to achieve maximal levels of identity (and conservation, in the case of amino acid sequences) for the purpose of assessing the degree of similarity and the possibility of homology. Definitions

106
Homology Similarity attributed to descent from a common ancestor. Definitions Page 42

107
Homology Similarity attributed to descent from a common ancestor. Definitions Identity The extent to which two (nucleotide or amino acid) sequences are invariant. Page 44 RBP: 26 RVKENFDKARFSGTWYAMAKKDPEGLFLQDNIVA 59 + K++ + ++ GTW++MA + L + A glycodelin: 23 QTKQDLELPKLAGTWHSMAMA-TNNISLMATLKA 55
 sequences are invariant. Page 44 RBP: 26 RVKENFDKARFSGTWYAMAKKDPEGLFLQDNIVA 59 + K GTW++MA + L + A glycodelin: 23 QTKQDLELPKLAGTWHSMAMA-TNNISLMATLKA 55.")
108
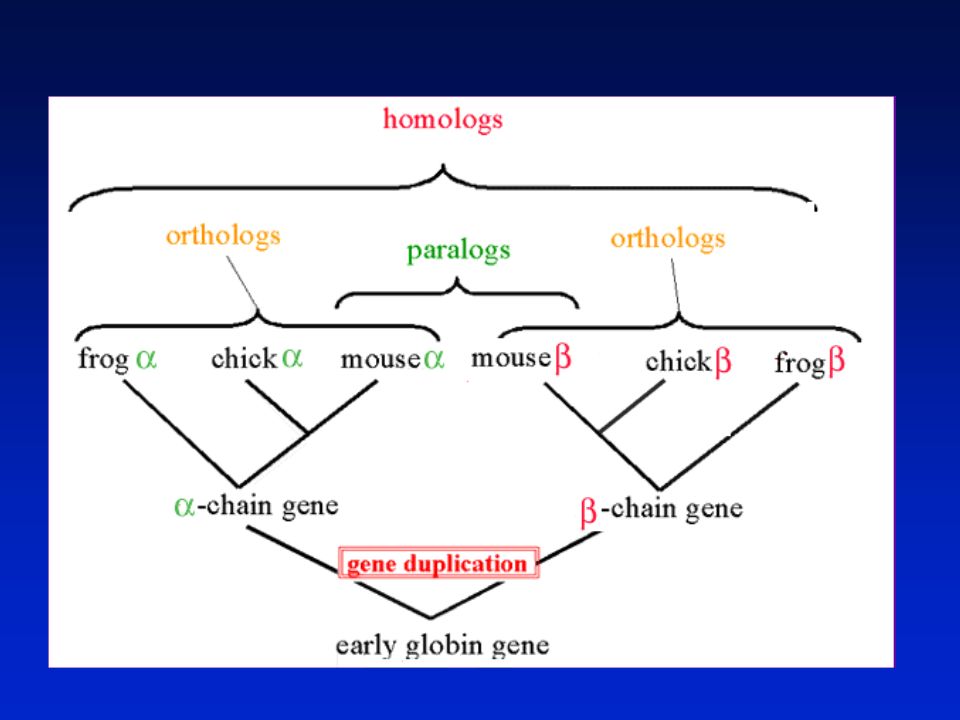
Orthologs Homologous sequences in different species that arose from a common ancestral gene during speciation; may or may not be responsible for a similar function. Paralogs Homologous sequences within a single species that arose by gene duplication. Definitions: two types of homology Page 43

109
Orthologs: members of a gene (protein) family in various organisms. This tree shows RBP orthologs. common carp zebrafish rainbow trout teleost African clawed frog chicken mouse rat rabbitcowpig horse human 10 changes Page 43

110
Paralogs: members of a gene (protein) family within a species apolipoprotein D retinol-binding protein 4 Complement component 8 prostaglandin D2 synthase neutrophil gelatinase- associated lipocalin 10 changes Lipocalin 1 Odorant-binding protein 2A progestagen- associated endometrial protein Alpha-1 Microglobulin /bikunin Page 44
 family within a species apolipoprotein D retinol-binding protein 4 Complement component 8 prostaglandin D2 synthase neutrophil gelatinase- associated lipocalin 10 changes Lipocalin 1 Odorant-binding protein 2A progestagen- associated endometrial protein Alpha-1 Microglobulin /bikunin Page 44")
112
1 MKWVWALLLLAAWAAAERDCRVSSFRVKENFDKARFSGTWYAMAKKDPEG 50 RBP. ||| |. |... | :.||||.:| : 1...MKCLLLALALTCGAQALIVT..QTMKGLDIQKVAGTWYSLAMAASD. 44 lactoglobulin 51 LFLQDNIVAEFSVDETGQMSATAKGRVR.LLNNWD..VCADMVGTFTDTE 97 RBP : | | | | :: |.|. || |: || |. 45 ISLLDAQSAPLRV.YVEELKPTPEGDLEILLQKWENGECAQKKIIAEKTK 93 lactoglobulin 98 DPAKFKMKYWGVASFLQKGNDDHWIVDTDYDTYAV...........QYSC 136 RBP || ||. | :.|||| |..| 94 IPAVFKIDALNENKVL........VLDTDYKKYLLFCMENSAEPEQSLAC 135 lactoglobulin 137 RLLNLDGTCADSYSFVFSRDPNGLPPEAQKIVRQRQ.EELCLARQYRLIV 185 RBP. | | | : ||. | || | 136 QCLVRTPEVDDEALEKFDKALKALPMHIRLSFNPTQLEEQCHI....... 178 lactoglobulin Pairwise alignment of retinol-binding protein 4 and -lactoglobulin Page 46

113
Similarity The extent to which nucleotide or protein sequences are related. It is based upon identity plus conservation. Identity The extent to which two sequences are invariant. Conservation Changes at a specific position of an amino acid or (less commonly, DNA) sequence that preserve the physico- chemical properties of the original residue. Definitions
 sequence that preserve the physico- chemical properties of the original residue. Definitions.")
114
1 MKWVWALLLLAAWAAAERDCRVSSFRVKENFDKARFSGTWYAMAKKDPEG 50 RBP. ||| |. |... | :.||||.:| : 1...MKCLLLALALTCGAQALIVT..QTMKGLDIQKVAGTWYSLAMAASD. 44 lactoglobulin 51 LFLQDNIVAEFSVDETGQMSATAKGRVR.LLNNWD..VCADMVGTFTDTE 97 RBP : | | | | :: |.|. || |: || |. 45 ISLLDAQSAPLRV.YVEELKPTPEGDLEILLQKWENGECAQKKIIAEKTK 93 lactoglobulin 98 DPAKFKMKYWGVASFLQKGNDDHWIVDTDYDTYAV...........QYSC 136 RBP || ||. | :.|||| |..| 94 IPAVFKIDALNENKVL........VLDTDYKKYLLFCMENSAEPEQSLAC 135 lactoglobulin 137 RLLNLDGTCADSYSFVFSRDPNGLPPEAQKIVRQRQ.EELCLARQYRLIV 185 RBP. | | | : ||. | || | 136 QCLVRTPEVDDEALEKFDKALKALPMHIRLSFNPTQLEEQCHI....... 178 lactoglobulin Pairwise alignment of retinol-binding protein and -lactoglobulin Identity (bar) Page 46
 Page 46.")
115
1 MKWVWALLLLAAWAAAERDCRVSSFRVKENFDKARFSGTWYAMAKKDPEG 50 RBP. ||| |. |... | :.||||.:| : 1...MKCLLLALALTCGAQALIVT..QTMKGLDIQKVAGTWYSLAMAASD. 44 lactoglobulin 51 LFLQDNIVAEFSVDETGQMSATAKGRVR.LLNNWD..VCADMVGTFTDTE 97 RBP : | | | | :: |.|. || |: || |. 45 ISLLDAQSAPLRV.YVEELKPTPEGDLEILLQKWENGECAQKKIIAEKTK 93 lactoglobulin 98 DPAKFKMKYWGVASFLQKGNDDHWIVDTDYDTYAV...........QYSC 136 RBP || ||. | :.|||| |..| 94 IPAVFKIDALNENKVL........VLDTDYKKYLLFCMENSAEPEQSLAC 135 lactoglobulin 137 RLLNLDGTCADSYSFVFSRDPNGLPPEAQKIVRQRQ.EELCLARQYRLIV 185 RBP. | | | : ||. | || | 136 QCLVRTPEVDDEALEKFDKALKALPMHIRLSFNPTQLEEQCHI....... 178 lactoglobulin Pairwise alignment of retinol-binding protein and -lactoglobulin Somewhat similar (one dot) Very similar (two dots) Page 46
 Very similar (two dots) Page 46.")
116
1 MKWVWALLLLAAWAAAERDCRVSSFRVKENFDKARFSGTWYAMAKKDPEG 50 RBP. ||| |. |... | :.||||.:| : 1...MKCLLLALALTCGAQALIVT..QTMKGLDIQKVAGTWYSLAMAASD. 44 lactoglobulin 51 LFLQDNIVAEFSVDETGQMSATAKGRVR.LLNNWD..VCADMVGTFTDTE 97 RBP : | | | | :: |.|. || |: || |. 45 ISLLDAQSAPLRV.YVEELKPTPEGDLEILLQKWENGECAQKKIIAEKTK 93 lactoglobulin 98 DPAKFKMKYWGVASFLQKGNDDHWIVDTDYDTYAV...........QYSC 136 RBP || ||. | :.|||| |..| 94 IPAVFKIDALNENKVL........VLDTDYKKYLLFCMENSAEPEQSLAC 135 lactoglobulin 137 RLLNLDGTCADSYSFVFSRDPNGLPPEAQKIVRQRQ.EELCLARQYRLIV 185 RBP. | | | : ||. | || | 136 QCLVRTPEVDDEALEKFDKALKALPMHIRLSFNPTQLEEQCHI....... 178 lactoglobulin Pairwise alignment of retinol-binding protein and -lactoglobulin Internal gap Terminal gap Page 46

117
Positions at which a letter is paired with a null are called gaps. Gap scores are typically negative. Since a single mutational event may cause the insertion or deletion of more than one residue, the presence of a gap is ascribed more significance than the length of the gap. In BLAST, it is rarely necessary to change gap values from the default. Gaps

Similar presentations









 Sequence Information Lecture 7.>")










