Download presentation
Presentation is loading. Please wait.

1
Archives and Information Retrieval
Lecture by; Ms. AQSAD RASHDA BIOINFORMATICS

2
Database indexing and specification of search terms
An index is a set of pointers to information in a database Search terms Entries: discrete coherent parcels of information. The information retrieval software Keywords AND’ NOT Follow-up questions

3
The archives Primary data collections related to biological macromolecules include: Nucleic acid sequences, including whole-genome projects Amino acid sequences of proteins Protein and nucleic acid structures Small-molecule crystal structures Protein functions Expression patterns of genes Publications

4
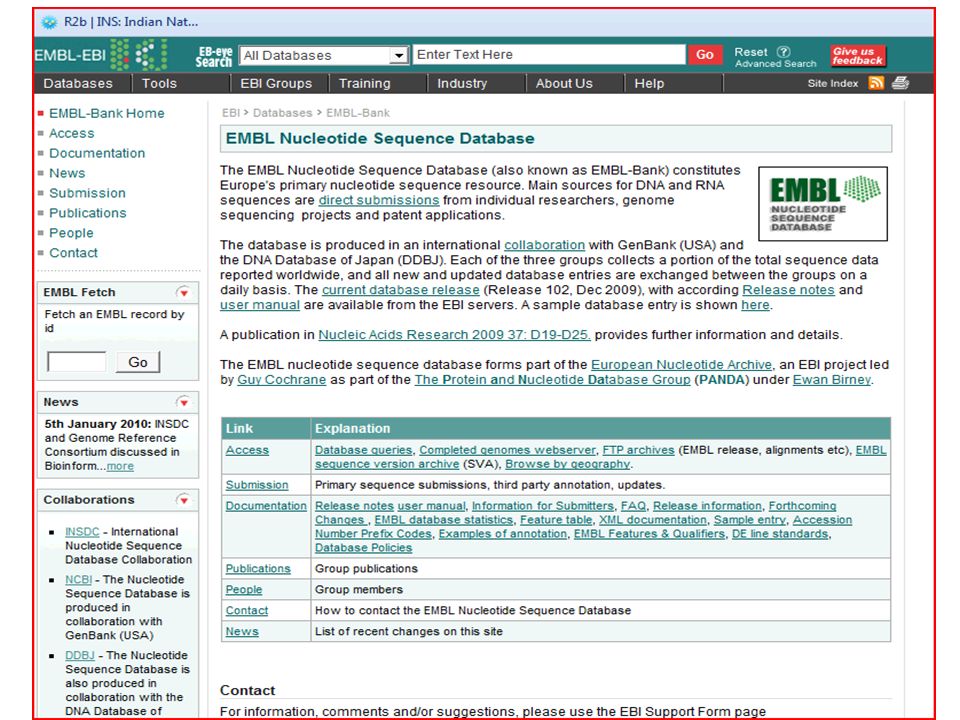
Nucleic acid sequence databases
Triple partnership of: National Center for Biotechnology Information (USA) EMBL Data Library (European Bioinformatics Institute, UK) DNA Data Bank of Japan (National Institute of Genetics, Japan). Entries have a life cycle
 EMBL Data Library (European Bioinformatics Institute, UK) DNA Data Bank of Japan (National Institute of Genetics, Japan). Entries have a life cycle.")
5
Nucleotide sequence databases
EMBL, GenBank, and DDBJ are the three primary nucleotide sequence databases EMBL GenBank DDBJ

8
The EMBL data library entry for the bovine pancreatic trypsin inhibitor gene
Identification Accession Date Description Keyword Organism Source Organism Classification Reference Number

9
Reference Position Reference Author Reference Title Reference Location Feature Table Header

10
FT: The feature table may indicate regions that 1
FT: The feature table may indicate regions that 1. perform or affect function 2. interact with other molecules 3. affect replication 4. are involved in recombination 5. are a repeated unit 6. have secondary or tertiary structure 7. are revised or corrected Sequence Header

11
Protein sequence databases
SWISS-PROT: The Swiss Institute of Bioinformatics collaborates with the EMBL Data Library to provide an annotated database of amino acid sequences called SWISS-PROT. PIR: Another protein sequence database is produced by The PIR International

13
PIR entry for the amino acid sequence of Bovine pancreatic trypsin inhibitor

16
Databases associated with SWISS-PROT
ENZYME DB, and PROSITE The ENZYME DB stores the following information about enzymes: EC Number: a numerical identifier assigned by the Enzyme Commission (authorized by the International Union of Biochemistry and Molecular Biology; see Recommended name Alternative names, if any Catalytic activity Cofactors, if any Pointers to SWISS-PROT and other data banks Pointers to disease associated with enzyme deficiency if any known

17
A Sample Entry in ENZYME DB

18
The PIR and associated databases
The PIR maintains several databases about proteins: 1. PIR-PSD: the main protein sequence database 2. iProClass: classification of proteins according to structure and function 3. ASDB: annotation and similarity database; each entry is linked to a list of similar sequences 4. P/R-NREF: a comprehensive non-redundant collection of over protein sequences merged from all available sources 5. NRL3D: a database of sequences and annotations of proteins of known structure deposited in the Protein Data Bank 6. ALN: a database of protein sequence alignments, and 7.RESID: a database of covalent protein structure modifications (recall that important structural features of proteins such as disulphide bridges are not inferrable from gene sequences, and will not appear in protein sequence databases derived solely by translation of genomic data)
")
19
Databases of structures
Structure databases archive, annotate and distribute sets of atomic coordinates Protein Data Bank (PDB). The information contained includes: What protein is the subject of the entry, and what species it came from Who solved the structure, and references to publications describing the structure determination Experimental details about the structure determination, including information related to the general quality of the result such as resolution of an X-ray structure determination and stereochemical statistics The amino acid sequence What additional molecules appear in the structure, including cofactors, inhibitors, and water molecules Assignments of secondary structure: helix, sheet Disulphide bridges The atomic coordinates
. The information contained includes: What protein is the subject of the entry, and what species it came from. Who solved the structure, and references to publications describing the structure determination. Experimental details about the structure determination, including information related to the general quality of the result such as resolution of an X-ray structure determination and stereochemical statistics. The amino acid sequence. What additional molecules appear in the structure, including cofactors, inhibitors, and water molecules. Assignments of secondary structure: helix, sheet. Disulphide bridges. The atomic coordinates.")
21
Protein data bank entry 2TRX, E. coli thioredoxin

27
Indicators of structure quality
X-ray crystal structure analysis Nuclear Magnetic Resonance Web Resource; Protein and Nucleic Acid Structures Home page of protein data bank: Home page of EBI macromolecular structure database: Home page of BioMagResBank: Searching the protein data bank: Home page of SCOP (Structural classification of proteins): List of browsers: OCA:
: List of browsers: OCA:")
28
Crystallisation Hanging drop method / vapour diffusion method
Microscope 1-Dilute protein solution Microscope slide many different conditions of 1&2 must be tried 2-Concentrated salt solution Crystal Slide courtesy from Shoshana Wodak

29
Determination of protein structure
Diffraction pattern Atomic model Slide courtesy from Shoshana Wodak

30
The resolution problem
q q q A high resolution protein structure : Å resolution Slide courtesy from Shoshana Wodak

31
Nuclear Magnetic Resonance (NMR)
Source: Branden & Tooze (1991)
")
32
Classifications of protein structures
SCOP: Structural Classification of Proteins CATH: Class/Architecture/Topology/Homology DALI:Classification of protein domains Based on extraction of similar structures from distance matrices. [ CE: A database of structural alignments

33
CATH - A protein domain classification
In CATH, protein domains are classified according to a tree with 4 levels of hierarchically Class Architecture Topology Homology Class Architecture Topology Figure from Shoshana Wodak

34
Specialized, or 'boutique' databases
VIPER (Virus Particle ExploreR) treats crystal structures of icosahedral viruses. In the field of immunology: IMGT, the international ImMunoGeneTics database, is a high-quality integrated database specializing in Immunoglobulins (Ig), T-cell receptors (TcR) and Major Histocompatibility Complex (MHC) molecules of all vertebrate species. The IMGT server provides a common access to all Immunogenetics data. At present, it includes two databases: IMGT/LIGM-DB, a comprehensive database of immunoglobulin and T-cell receptor gene sequences from human and other vertebrates, with translation for fully annotated sequences, and IMGT/HLA-DB, a database of the human MHC referred to as HLA (Human Leucocyte Antigens)
 treats crystal structures of icosahedral viruses. In the field of immunology: IMGT, the international ImMunoGeneTics database, is a high-quality integrated database specializing in Immunoglobulins (Ig), T-cell receptors (TcR) and Major Histocompatibility Complex (MHC) molecules of all vertebrate species. The IMGT server provides a common access to all Immunogenetics data. At present, it includes two databases: IMGT/LIGM-DB, a comprehensive database of immunoglobulin and T-cell receptor gene sequences from human and other vertebrates, with translation for fully annotated sequences, and IMGT/HLA-DB, a database of the human MHC referred to as HLA (Human Leucocyte Antigens)")
35
Web Resource: Databases for Specific Protein Families
Protein kinases HIV proteases Icosahedral viruses Immunology IGMT: KABAT: MHCPEP: Collections of links to databases on specific protein families KABAT - Database of Sequences of Proteins of Immunological Interest - North-Western University (USA) MHCPEP - Major Histocompatibility Complex Binding Peptides Database - Walter and Eliza Hall Institute (Melbourne, Australia)
 MHCPEP - Major Histocompatibility Complex Binding Peptides Database - Walter and Eliza Hall Institute (Melbourne, Australia)")
36
Expression and proteomics databases
Expression databases record measurements of mRNA levels, usually via ESTs (short terminal sequences of cDNA synthesized from mRNA). Comparisons of expression patterns give clues to: (1) the function and mechanism of action of gene products, (2) how organisms coordinate their control over metabolic processes in different conditions - for instance yeast under aerobic or anaerobic conditions, (3) the variations in mobilization of genes at different stages of the cell cycle, or of the development of an organism, (4) mechanisms of antibiotic resistance in bacteria, and consequent suggestion of targets for drug development (5) the response to challenge by a parasite (6) the response to medications of different types and dosages, to guide effective therapy.
. Comparisons of expression patterns give clues to: (1) the function and mechanism of action of gene products, (2) how organisms coordinate their control over metabolic processes in different conditions - for instance yeast under aerobic or anaerobic conditions, (3) the variations in mobilization of genes at different stages of the cell. cycle, or of the development of an organism, (4) mechanisms of antibiotic resistance in bacteria, and consequent suggestion of targets for drug development. (5) the response to challenge by a parasite. (6) the response to medications of different types and dosages, to guide effective therapy.")
Similar presentations












 Sequence Information Lecture 7.>")

>")


.>")




>")



 discussed in this section is in Box 2.1.>")


