Download presentation
Presentation is loading. Please wait.

1
Archiving the Web – The Bibliothèque nationale de France’s « L’archivage du Web » Bert Wendland Bibliothèque nationale de France

2
Who I am / who we are > Bert Wendland > Crawl engineer in the IT department of BnF > Semi-joint working group > Legal Deposit department > 1 head of group > 4 librarians > IT department > 1 project coordinator > 1 developer > 2 crawl engineers > A network of 80 digital curators 23 May 2013Archiving the Web2

3
27th November 2012Session 4 - Web archiving for decision-makers3

4
27th November 2012Session 4 - Web archiving for decision-makers4

14
27th November 2012Session 4 - Web archiving for decision-makers14

15
27th November 2012Session 4 - Web archiving for decision-makers15

16
28th November 2012Session 5 - Integrating web archiving in IT operations16 Agenda > Context: I will present the BnF and web archiving as part of its legal mission. > Concepts: I will describe how we operationalise the task of collecting and preserving the French web in terms of data, and how this relates to the general web archive at www.archive.org. > Infrastructure: I will give an overview of the infrastructure that supports this task. > Data acquisition: I will describe our mixed model of web harvesting that combines broad crawls and selective crawls to achieve a good trade-off between breadth and depth in coverage and temporal granularity. > Data storage and access: I will describe the indexing structures that allow users to query this web archive.

17
Context The BnF and web archiving as part of its legal mission

18
The BnF > Bibliothèque nationale de France > About 30 million books, periodicals and others > 10 million at the new site > Yearly 60.000 new books > 400 TB of data in the web archive > 100 TB of new data every year > Two sites > Old site « Richelieu » in the centre of Paris > New site « François-Mitterand » since 1996 > Two levels at the new site > Study library (« Haut-de-jardin »): open stacks > Research library (« Rez-de-jardin »): access to all collection, including web archives 23 May 2013Archiving the Web18
: open stacks > Research library (« Rez-de-jardin »): access to all collection, including web archives 23 May 2013Archiving the Web18")
19
The legal deposit 1368 Royal manuscripts of king Charles V in the Louvre 1537Legal deposit by king Francis I: all editors should send copies of their productions to the royal library 1648Legal deposit extended to maps and plans 1793Musical scores 1925Photographs and gramophone records 1975Video recordings 1992CD-ROMs and electronic documents 2002Websites (experimentally) 2006Websites (in production) 23 May 2013Archiving the Web19
 2006Websites (in production) 23 May 2013Archiving the Web19")
20
Extension of the Legal deposit Act in 2006 > Coverage (article 39) « Sont également soumis au dépôt légal les signes, signaux, écrits, images, sons ou messages de toute nature faisant l’objet d’une communication au public par voie électronique. » > Conditions (article 41 II) « Les organismes dépositaires procèdent à la collecte des signes, signaux, écrits, images sons ou messages de toute nature mis à la disposition du public ou de catégories de public, … Ils peuvent procéder eux-mêmes à cette collecte selon des procédures automatiques ou en déterminer les modalités en accord avec ces personnes. » > Responsibilities (article 50) INA (Institut national de l'audiovisuel) for radio and TV websites BnF for anything else > No permission required to collect, but access to the archive restricted to in-house > The goal is not to gather all or the “best of the Web”, but to preserve a representative collection of the Web at a certain date 23 May 2013Archiving the Web20
 « Les organismes dépositaires procèdent à la collecte des signes, signaux, écrits, images sons ou messages de toute nature mis à la disposition du public ou de catégories de public, … Ils peuvent procéder eux-mêmes à cette collecte selon des procédures automatiques ou en déterminer les modalités en accord avec ces personnes. » > Responsibilities (article 50) INA (Institut national de l audiovisuel) for radio and TV websites BnF for anything else > No permission required to collect, but access to the archive restricted to in-house > The goal is not to gather all or the best of the Web , but to preserve a representative collection of the Web at a certain date 23 May 2013Archiving the Web20.")
21
Concepts How we collect and preserve the French web

22
23 May 2013Archiving the Web22

23
The Internet Archive > Non-profit organisation, founded 1996 by Brewster Kahle in San Francisco > Stated mission of “universal access to all knowledge” > Websites, but also other media like scanned books, movies, audio collections, … > Web archiving from the beginning, only 4 years after the start of the WWW > Main technologies for web archiving: > Heritrix: the crawler > Wayback Machine: access the archive 23 May 2013Archiving the Web23

24
Partnership BnF – IA > A five-years partnership between 2004 and 2008 > Data > 2 focused crawls and 5 broad crawls on behalf of BnF > Extraction of historical Alexa data concerning.fr back to 1996 > Technology > Heritrix > Wayback Machine > 5 Petaboxes > Know-how > Installation of Petaboxes by engineers of IA > Presence of an IA crawl engineer one day a week for 6 months 23 May 2013Archiving the Web24

25
How search engines work Source : www.brightplanet.com Archiving the Web, that’s archiving the files, the links and some meta data.

26
How the web crawler works Queue of URLs “Seeds”: http://www.site-untel.fr http://www.monblog.fr … Web crawler (“Heritrix”) Verification parameters: YES NO Storage URL rejected Discovered URLs: http://www.unautre-site.fr http://www.autre-blog.fr … Connection to the page Storing the data Extraction of links Connection to the page Storing the data Extraction of links …
 Verification parameters: YES NO Storage URL rejected Discovered URLs: … Connection to the page Storing the data Extraction of links Connection to the page Storing the data Extraction of links …")
27
Planning Monitoring Access Indexing Validation CrawlingExperience Quality Assurance Preservation Selection Current production workflow BCWeb NetarchiveSuite Heritrix Wayback Machine SPAR Indexing Process VMware NetarchiveSuite NAS_qual NAS_preload 23 May 2013Archiving the Web27

28
> « »

29
Applications > BCWeb (“BnF Collecte du Web”) > BnF in-house development > Selection tool for librarians: proposition of URLs to collect for selective crawls > Technical validation of URLs by digital curators > Definition of collection packages > Transfer to NetarchiveSuite > NAS_preload (“NetarchiveSuite Pre-Load”) > BnF in-house development > Preparation of broad crawls, based on a list of officially registered domains by AFNIC 23 May 2013Archiving the Web29
 > BnF in-house development > Selection tool for librarians: proposition of URLs to collect for selective crawls > Technical validation of URLs by digital curators > Definition of collection packages > Transfer to NetarchiveSuite > NAS_preload ( NetarchiveSuite Pre-Load ) > BnF in-house development > Preparation of broad crawls, based on a list of officially registered domains by AFNIC 23 May 2013Archiving the Web29")
30
Applications > NetarchiveSuite > Open source application > Collaborative work of: > BnF > The two national deposit libraries in Denmark (the Royal Library in Copenhagen and the State and University Library in Aarhus) > Austrian National Library (ÖNB) > Central and main application of the archiving process > Planning the crawls > Creating and launching jobs > Monitoring > Quality Assurance > Experience evaluation 23 May 201330
 > Austrian National Library (ÖNB) > Central and main application of the archiving process > Planning the crawls > Creating and launching jobs > Monitoring > Quality Assurance > Experience evaluation 23 May")
31
Applications > Heritrix > Open source application by Internet Archive > Its name is an archaic English word for heiress (woman who inherits) > A crawl is configured as a job in Heritrix, which consists mainly of: > a list of URLs to start from (the seeds) > a scope (collect all URLs in the domain of a seed, stay on the same host, only a particular web page, etc.) > a set of filters to exclude unwanted URLs from the crawl > a list of extractors (to extract URLs from HTML, CSS, JavaScript) > many other technical parameters, for instance to define the “politeness” of a crawl or whether or not obey a website’s robots.txt file 23 May 2013Archiving the Web31
 > A crawl is configured as a job in Heritrix, which consists mainly of: > a list of URLs to start from (the seeds) > a scope (collect all URLs in the domain of a seed, stay on the same host, only a particular web page, etc.) > a set of filters to exclude unwanted URLs from the crawl > a list of extractors (to extract URLs from HTML, CSS, JavaScript) > many other technical parameters, for instance to define the politeness of a crawl or whether or not obey a website’s robots.txt file 23 May 2013Archiving the Web31")
32
Applications > The Wayback Machine > Open source application by Internet Archive > Gives access to the archived data > SPAR (“Système de Préservation et d’Archive Réparti”) > Not really an application, it is the BnF’s digital repository > Long-term preservation system for digital objects, compliant with the OAIS (Open Archival Information System) standard, ISO 14721 23 May 2013Archiving the Web32
 > Not really an application, it is the BnF’s digital repository > Long-term preservation system for digital objects, compliant with the OAIS (Open Archival Information System) standard, ISO May 2013Archiving the Web32")
33
Applications > NAS_qual (“NetarchiveSuite Quality Assurance”) > BnF in-house development > Indicators and statistics about the crawls > The Indexing Process > Chain of shell scripts, developed in-house by BnF 23 May 2013Archiving the Web33
 > BnF in-house development > Indicators and statistics about the crawls > The Indexing Process > Chain of shell scripts, developed in-house by BnF 23 May 2013Archiving the Web33")
34
Data and process model 23 May 2013Archiving the Web34

35
Daily operations: same steps, different actions Curators > Monitoring: dashboard in NetarchiveSuite, filters in Heritrix, answers to webmaster's requests > Quality assurance: analysis of indicators, visual control in WB > Experience: reports on harvest concerning contents and websites description Engineers > Monitoring: dashboard in Nagios, operation on virtual machines, information to give to webmasters > Quality assurance: production of indicators > Experience: reports on harvest concerning IT exploitation 23 May 2013Archiving the Web35

36
Challenges > What is the French web? > Not only.fr, also.com or.org > Some data remain difficult to harvest > Streaming, databases, videos, JavaScript > Dynamic web pages > Contents protected by passwords > Complex instructions for Dailymotion, paid contents for newspapers 23 May 2013Archiving the Web36

37
Infrastructure The machines that support the task

38
Platforms Pilot Database NAS Operational Platform Indexer master Indexer 23 May 2013Archiving the Web38 PostgreSQL Application Machines with Linux

39
Operational Platform: PFO Platforms Trial Run Platform: MAB Pre-production Platform: PFP 1 pilot, 1 indexer master, 2 to 10 indexers, 20 to 70 crawlers. Variable and scalable number of computers Identical setup to the PFO, the MAB (MAB = Marche À Blanc, Trial Run) aims to simulate and test harvests in real conditions for our curator team. Its size is also variable and subject to changes. The PFP is a technical test platform for the use of our engineers team. 23 May 2013Archiving the Web39
 aims to simulate and test harvests in real conditions for our curator team. Its size is also variable and subject to changes. The PFP is a technical test platform for the use of our engineers team. 23 May 2013Archiving the Web39.")
40
Platforms > Flexibility regarding the number of crawlers allocated to a platform > Hardware resources sharing and optimisation > All classical needs of production environments such as robustness and reliability hypervisor > Virtual computers > Configuration « templates » > Resource pool grouping of the computers > Automatic management of all shared resources Solution: Virtualisation! Our needs: 1234567 8 9 23 May 2013Archiving the Web40

41
The DL-WEB cluster Shared resources Cluster DL-WEB 1234567 8 9 23 May 2013Archiving the Web41

42
Dive into the hardware 2 x 9 RAM of 4 GB = 72 GB RAM / machine 2 sockets On every socket,1 CPU2 cores 1 2 3 4 Total of 16 logical CPUs per machine 4 threads

43
Physical Machines 2 x 9 x 4Gb = 72 GB 2 x 2 x 4 = 16 CPU 9 x 72 = 648 GB 9 x 16 = 144 CPU 1234567 8 9 23 May 2013Archiving the Web43

44
Park of virtual machines PFOMABPFP pilot111 index-server111 index-master1-- crawler70 10 indexer10-- heritrix555 free555 197938222

45
Distributed Resource Scheduler (DRS) and V-motion If one of the hosts fails, all the VM hosted on this server are moved to other hosts and are rebooted. A virtual machine is hosted on a single physical server at a given time. If the load of VM hosted on one of the servers becomes too heavy, some of the VMs are moved onto another host dynamically and without interruption. 23 May 2013Archiving the Web45

46
Fault tolerance (FT) > An active copy of the FT VM runs on another server > If the server where the master VM is hosted fails, the ghost VM instantly takes control without interruption > A copy is then created on a third server > The other VMs are moved and restarted Fault Tolerance can be quite greedy regarding resources especially concerning network consumption. That’s why we have activated this functionality only for the pilot machine. 23 May 201346Archiving the Web

47
Data acquisition Our mixed model of web harvesting

48
Calendar year Number of websites Broad crawls - once a year -.fr domains and beyond Ongoing crawls: - running throughout the year - news or reference websites Project crawls: - one shots -related to an event or a theme BnF “mixed model” of harvesting 23 May 2013Archiving the Web48

49
Aggregation of a large number of sources > In 2012: > 2.4 million domains in.fr and.re, provided by AFNIC (Association française pour le nommage Internet en coopération – the French domain name allocation authority) > 3,000 domains in.nc, provided by OPT-NC (Office des postes et télécommunications de Nouvelle-Calédonie – the office of telecommunications of New Caledonia) > 2.6 million domains already present in NetarchiveSuite database > 13,000 domains from the selection of URLs by BnF librarians (in BCWeb) > 6,000 domains from other workflows of the Library that contain URLs as part of the metadata: publishers’ declarations for books and periodicals, the BnF catalogue, identification of new periodicals by librarians, print periodicals that move to online publishing, and others > After de-duplication, this generated a list of 3.3 million unique domains 23 May 2013Archiving the Web49
 > 3,000 domains in.nc, provided by OPT-NC (Office des postes et télécommunications de Nouvelle-Calédonie – the office of telecommunications of New Caledonia) > 2.6 million domains already present in NetarchiveSuite database > 13,000 domains from the selection of URLs by BnF librarians (in BCWeb) > 6,000 domains from other workflows of the Library that contain URLs as part of the metadata: publishers’ declarations for books and periodicals, the BnF catalogue, identification of new periodicals by librarians, print periodicals that move to online publishing, and others > After de-duplication, this generated a list of 3.3 million unique domains 23 May 2013Archiving the Web49")
50
Volume of collections > Seven broad crawls since 2004 > 1996-2005 collections thanks to Internet Archive > Tens of thousands of focus-crawled websites since 2002 > Total size > 20 billion URLs > 400 Terabytes 23 May 2013Archiving the Web50

51
Volume of collections 23 May 2013Archiving the Web51

52
Data storage and access The indexing structures and how users query the web archive

53
Data access: the Wayback Machine CDX machine CDXPath CDX server Data storage machine Data server ARC Client Browser Web server URL server Web interface Data storage machine Data server ARC Data storage machine Data server ARC CDX machine CDXPath CDX server 12 3 4 912 14 1110 5/67/8 13 23 May 2013Archiving the Web53

54
The ARC files File description For every collected URL: URL, IP-address, Archive-date, Content- type, Archive-length, HTTP headers and HTML code filedesc://IA-001102.arc 0 19960923142103 text/plain 76 1 0 Alexa Internet http://www.dryswamp.edu:80/index.html 127.10.100.2 19961104142103 text/html 202 HTTP/1.0 200 Document follows Date: Mon, 04 Nov 1996 14:21:06 GMT Server: NCSA/1.4.1 Content-type: text/html Last-modified: Sat,10 Aug 1996 22:33:11 GMT Content-length: 30 Hello World!!! http://www. …

55
ARC file format 23 May 2013Archiving the Web55

56
The CDX files Indexation of the ARC files CDX A b e m s c V v D d g n 0-0-0checkmate.com/Bugs/Bug_Investigators.html 20010424210551 209.52.183.152 text/html 200 58670fbe7432c5bed6f3dcd7ea32b221 17130110 59129865 1927657 6501523 DE_crawl6.20010424210458 5750 A = canonized URL, b = date, e = IP, m = mime type, s = response code, c = checksum, V = compressed arc file offset, v = uncompressed arc file offset, D = compressed dat file offset, d = uncompr. dat file offset, g = file name, n = arc document length 23 May 2013Archiving the Web56

57
The PATH files Location of the ARC files ARC file name, location DE_crawl6.20010424210458 /dlwebdata/01002/ DE_crawl6.20010424210458.arc.gz IA-001102.arc /dlwebdata/01003/IA-001102.arc 23 May 2013Archiving the Web57

58
Indexing the data

59
Binary Search > Sorted list of data > O(log n) > a maximum of 35 search operations for 20 billion lines!
 > a maximum of 35 search operations for 20 billion lines!")
60
Pre Ingest Long-term preservation system for digital objects, compliant with the OAIS (Open Archival Information System) standard, ISO 14721 SPAR Système de Préservation et d’Archive Réparti Digitized books Digitized audiovisual documents Web archiving Pre Ingest Archiving the Web 60
 standard, ISO SPAR Système de Préservation et d’Archive Réparti Digitized books Digitized audiovisual documents Web archiving Pre Ingest Archiving the Web 60")
61
SPAR A generic repository solution at BnF

62
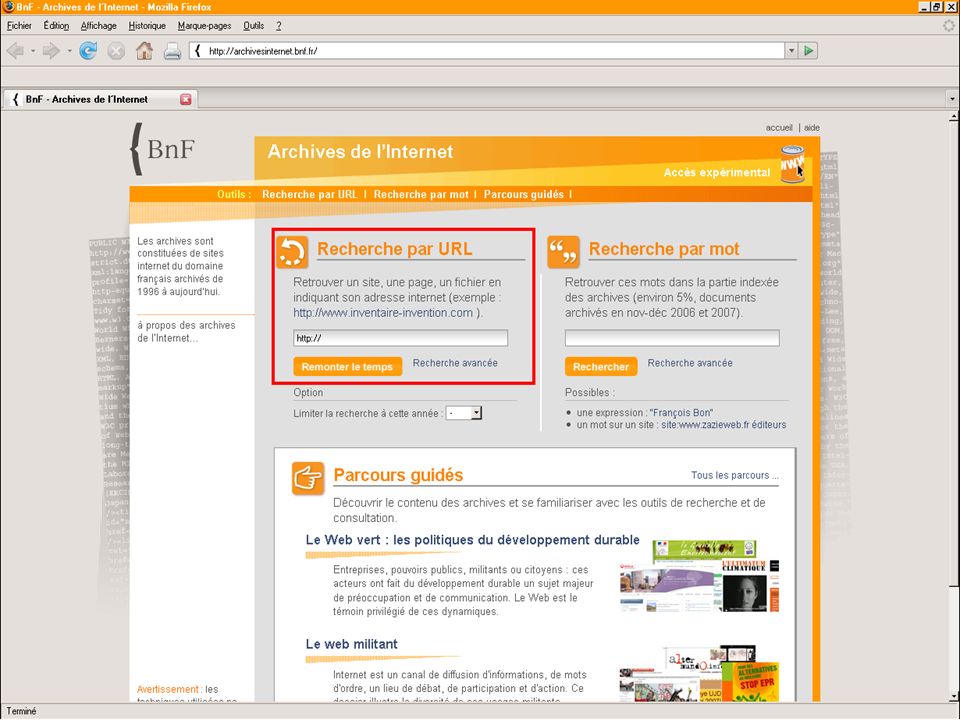
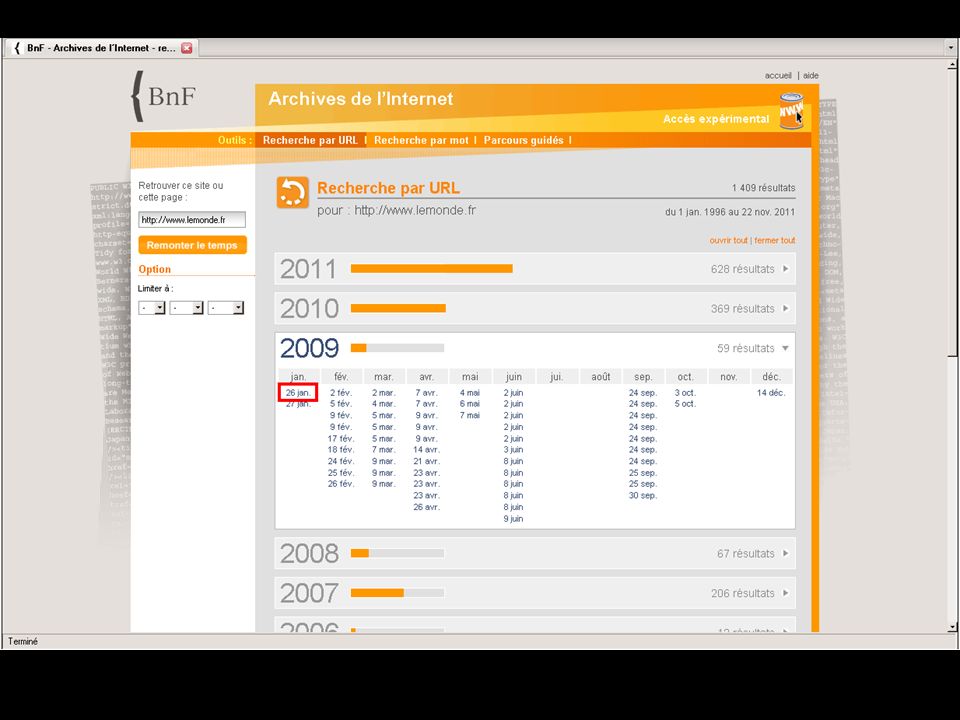
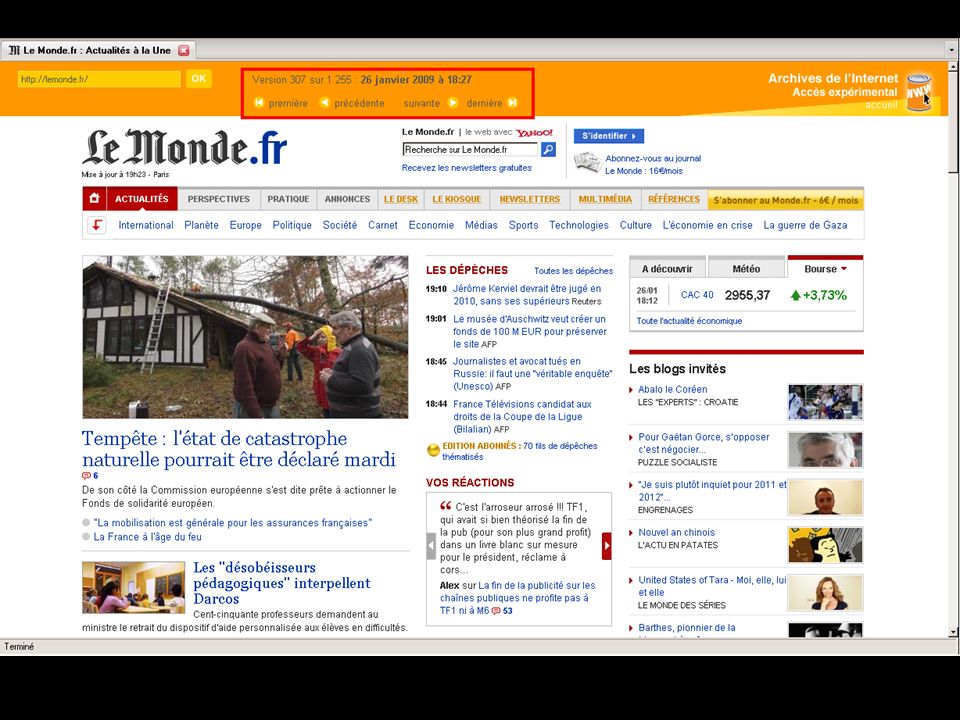
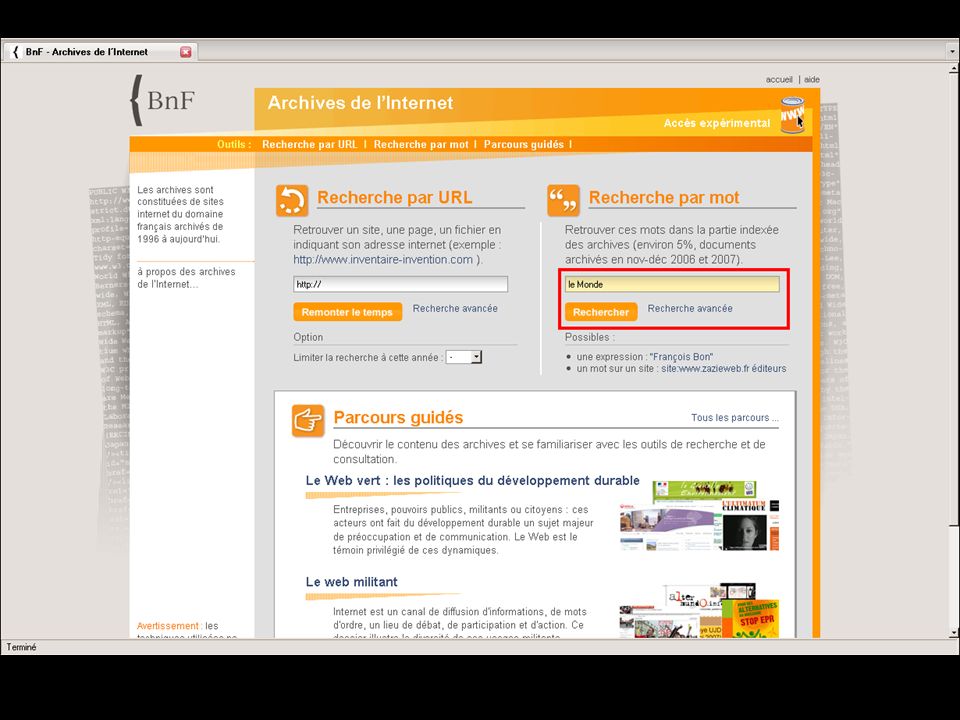
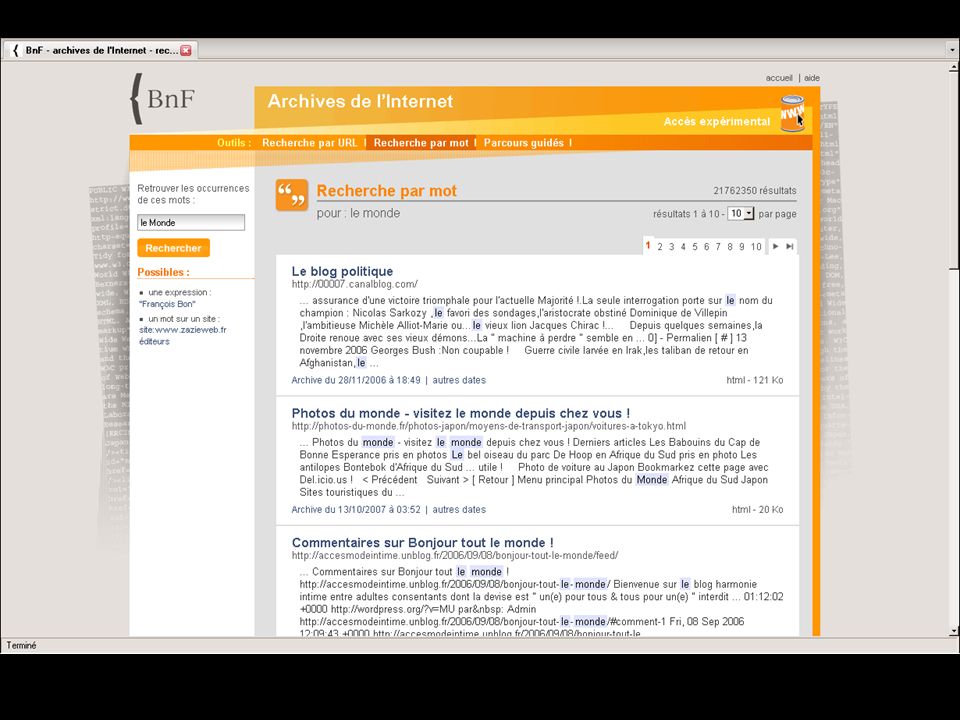
Public access to the collections > Customised version of open-source Wayback Machine > Three access points: > URL search > Experimental full-text search using NutchWAX (only covers about 10% of collections…) > Guided tours Archiving the Web6223 May 2013
 > Guided tours Archiving the Web6223 May 2013")
63
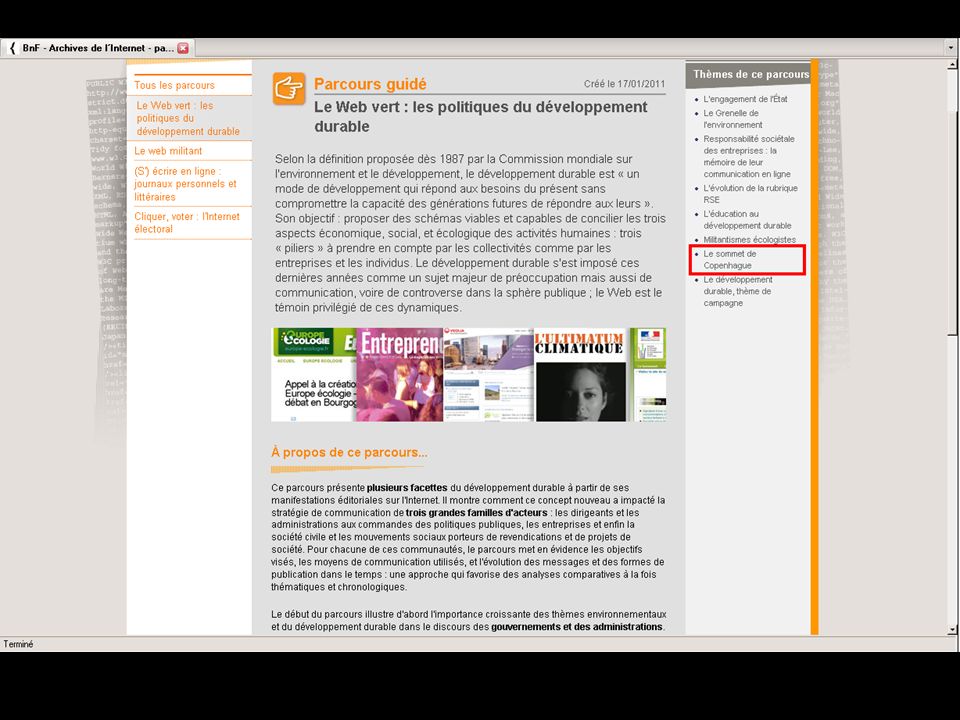
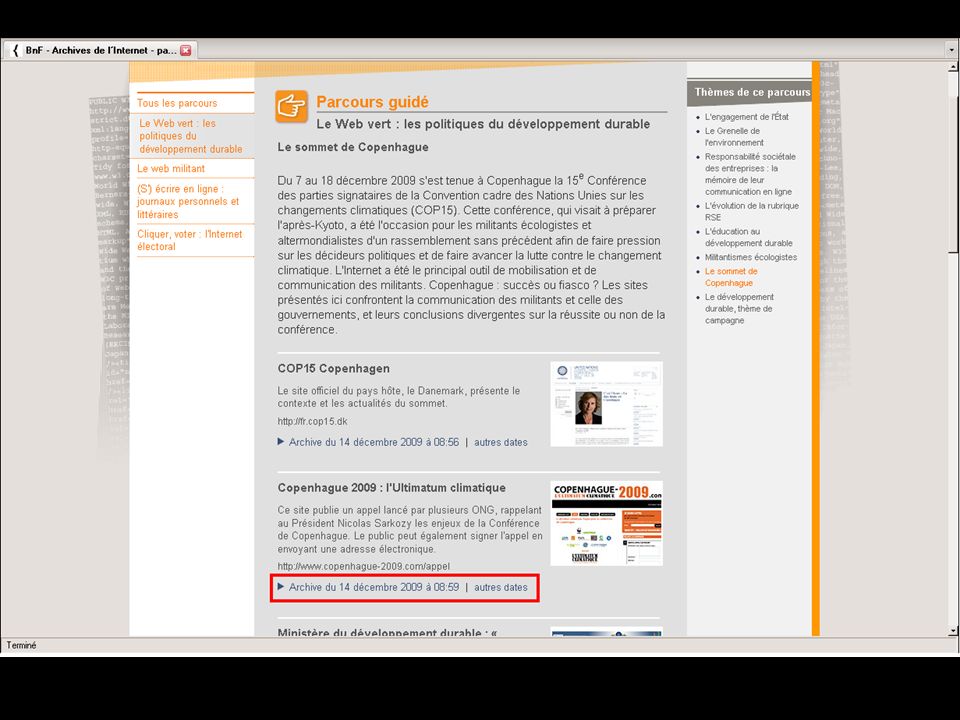
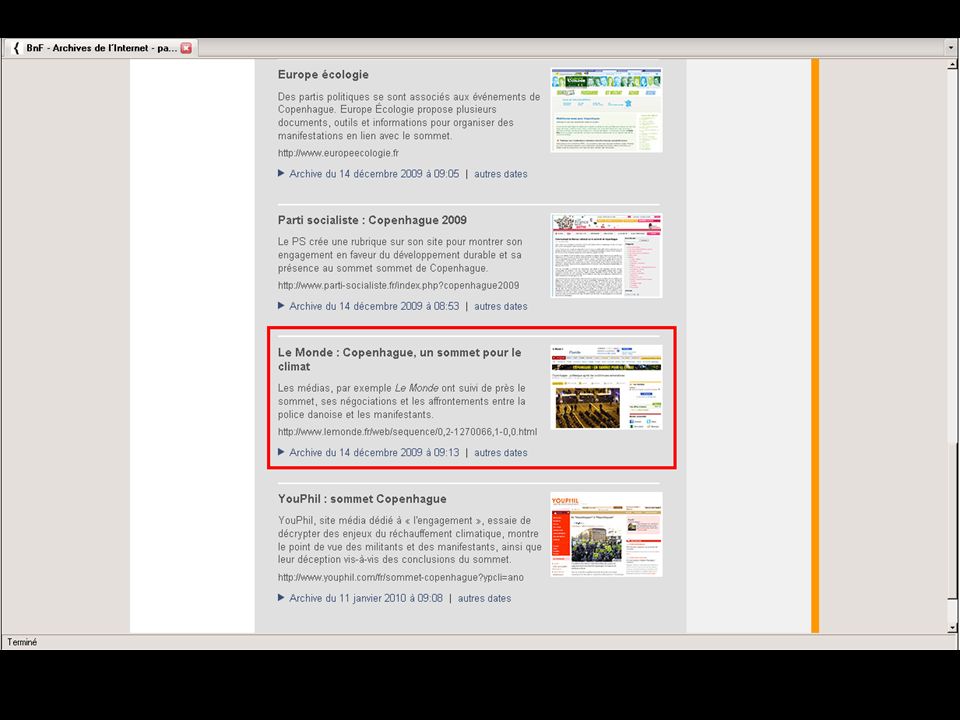
“Guided tours” > Selections in the web archives, created by BnF subject librarians and external partners > Provide a user-friendly way of discovering the contents of the archives > Provides visibility for project collections 23 May 2013Archiving the Web63

64
Thank you for your attention Questions?

Similar presentations