Download presentation
Presentation is loading. Please wait.

1
Tutorial for QUIZ 1: Interconnects, shared memory, and synchronization
Daniel Shapiro Explain partitioning and synchronization for shared memory systems.

2
Question #1 QUESTION: Can there be questions on the quiz that are not in the tutorial? ANSWER: YES.

3
INTERCONNECTS (QUIZ #2) QUESTION #1
The following network is asymmetric: [a] Hypercube [b] 2D Mesh [c] Ring If the main concern in the design of the interconnection network is configurability (ability to easily add more nodes), then which multistage network should be used: [a] Bus [b] Omega network [c] Crossbar network The number of permutations in 8x8 crossbar network is: [a] 256 [b] 40320 [c] In a single-bus system that uses split transactions: [a] Both masters and slaves have to compete for the bus by arbitration [b] Only the masters have to compete for the bus by arbitration [c] No arbitration is necessary (3)Non-blocking!! So num permutations = 8P8 = 8! / (8 -8)! = 8! / 0! = 8! / 1 = 8! = 40320
, then which multistage network should be used: [a] Bus. [b] Omega network. [c] Crossbar network. The number of permutations in 8x8 crossbar network is: [a] 256. [b] [c] In a single-bus system that uses split transactions: [a] Both masters and slaves have to compete for the bus by arbitration. [b] Only the masters have to compete for the bus by arbitration. [c] No arbitration is necessary. (3)Non-blocking!! So num permutations = 8P8. = 8! / (8 -8)! = 8! / 0! = 8! / 1 = 8! =")
4
INTERCONNECTS (QUIZ #2) QUESTION #2
Compute the diameter and bisection width for 3D mesh with p=64 processors Compute the diameter and bisection width for 2D torus with p=64 processors (assume that routing is bidirectional). c. Construct an 8-input Omega network using 2 x 2 switch modules in multiple stages. Show the routing of the message from input 010 to output 110. Static Interconnection Networks Slide Comparison of topologies (slide 11) 4x4x4 mesh D = 4+4+4=12, bisection along the middle = 4x4 = 16 8x8 bisection = 8x2=16… D=2*floor(sqrt(64)/2)=2*floor(4)=2*4=8
. c. Construct an 8-input Omega network using 2 x 2 switch modules in multiple stages. Show the routing of the message from input 010 to output 110. Static Interconnection Networks. Slide Comparison of topologies (slide 11) 4x4x4 mesh. D = 4+4+4=12, bisection along the middle = 4x4 = 16. 8x8 bisection = 8x2=16… D=2*floor(sqrt(64)/2)=2*floor(4)=2*4=8.")
5
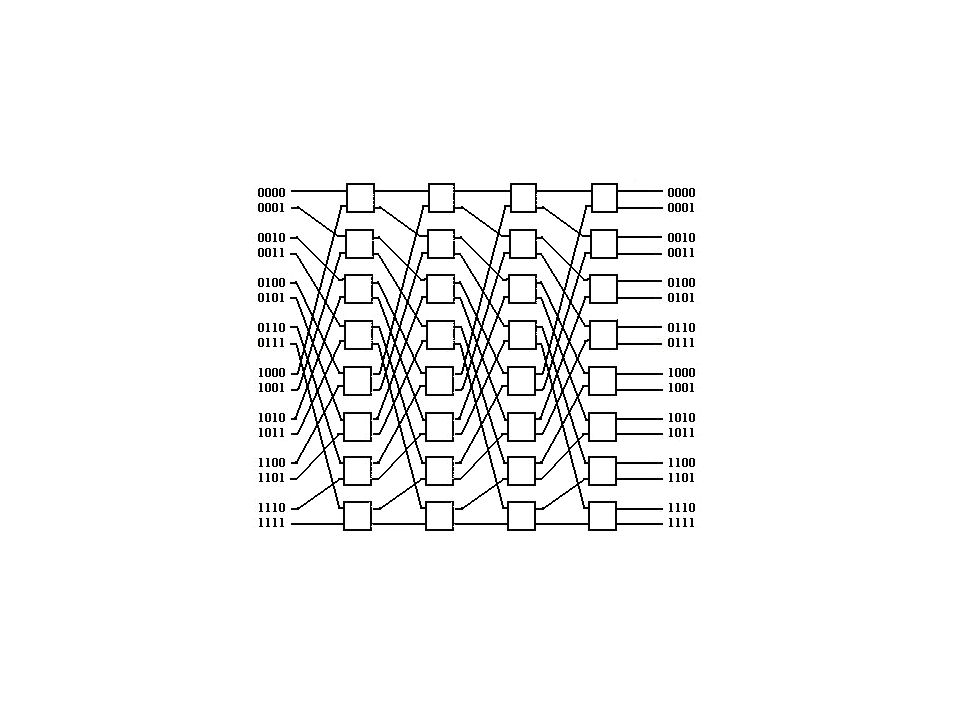
2. Consider the following 16x16 Omega network
Number of stages. Number of 2 x 2 switches needed to implement the network. Draw a 16-input Omega network using 2 x 2 switches as building blocks. Show switch settings for routing a message from node 1101 to node 0101 and from node 0111 to node 1001 simultaneously. Does blocking exist in this case? 4 Stages x switches = 8 x 4 = 32

8
You may be asked to… Analyze a program Modify a program
Write a program

9
Multiprocessor Software Functions
INITIALIZE – assigns a number (proc_num) to each processor in the system; assigns the total number of processors (num_procs). LOCK(data) Allows a processor to “check out” a certain piece of shared data. While one processor has the data locked, no other processors can obtain the lock. The lock is blocking, so once a LOCK is encountered, execution of the program cannot proceed until the LOCK is obtained. UNLOCK(data) – releases a lock so that other processors can obtain it. BARRIER(n_procs) – When a BARRIER is encountered, a processor waits at that BARRIER until n_procs processors reach the BARRIER, then execution can proceed.
 to each processor in the system; assigns the total number of processors (num_procs). LOCK(data) Allows a processor to check out a certain piece of shared data. While one processor has the data locked, no other processors can obtain the lock. The lock is blocking, so once a LOCK is encountered, execution of the program cannot proceed until the LOCK is obtained. UNLOCK(data) – releases a lock so that other processors can obtain it. BARRIER(n_procs) – When a BARRIER is encountered, a processor waits at that BARRIER until n_procs processors reach the BARRIER, then execution can proceed.")
10
Mutex is not the boss!! It is important to note that the mutex core does not physically protect resources in the system from being accessed at the same time by multiple processors. The software running on the processors is responsible for abiding by the rules. The software must be designed to always acquire the mutex before accessing its associated shared resource.

11
code of processors P1 and P2, do we need to use lock (mutex)? Why?
SHARED MEMORY 1. a) Consider a shared memory system with two processors. What value will processor P1 print? If variable flag is used only in this portion of the code of processors P1 and P2, do we need to use lock (mutex)? Why? P1 … A=0; while (flag==0) do nothing; print A; P2 … A=1; flag=1; b) System deadlock refers to a situation in a multiprocessor when concurrent processes are holding resources and preventing each other from completing their execution. Is it possible that software that executes on P1 and P2 causes deadlock situation? c) Why does NIOS II use a hardware mutex? What is the advantage of hardware mutex in comparison with the software one? Bus access locks up the system. P1 is hitting the bus every cycle and slowing down P2. Use a mutex to solve the problem. Mutex is atomic test and set, saving a cycle and ensuring there is no conflicting assignment. Nope Mutex is a core on the bus, not in the nios. Altera: A mutex allows cooperating processors to agree that one of them should be allowed mutually exclusive access to a hardware resource in the system. This is useful for the purpose of protecting resources from data corruption that can occur if more than one processor attempts to use the resource at the same time.
 Consider a shared memory system with two processors. What value will. processor P1 print If variable flag is used only in this portion of the. code of processors P1 and P2, do we need to use lock (mutex) Why P1. … A=0; while (flag==0) do nothing; print A; P2. … A=1; flag=1; b) System deadlock refers to a situation in a multiprocessor when concurrent. processes are holding resources and preventing each other from completing. their execution. Is it possible that software that executes on P1 and P2. causes deadlock situation c) Why does NIOS II use a hardware mutex What is the advantage of hardware mutex in comparison with the software one Bus access locks up the system. P1 is hitting the bus every cycle and slowing down P2. Use a mutex to solve the problem. Mutex is atomic test and set, saving a cycle and ensuring there is no conflicting assignment. Nope. Mutex is a core on the bus, not in the nios. Altera: A mutex allows cooperating processors to agree that one of them should be allowed mutually exclusive access to a hardware resource in the system. This is useful for the purpose of protecting resources from data corruption that can occur if more than one processor attempts to use the resource at the same time.")
12
global_MAC = X[0]*Y[0]+ X[1]*Y[1]+… X[N-1]*Y[N-1]
SHARED MEMORY QUESTION #4 (MIDTERM) Consider a machine with 2 processors that share the same memory. Multiply and Accumulate operation is performed: global_MAC = X[0]*Y[0]+ X[1]*Y[1]+… X[N-1]*Y[N-1] The MAC subroutine is implemented on both processors and it is shown bellow. Modify the program to make it suitable for execution in a four-processor machine. If processor P1 starts executing MAC subroutine before the processor P0, will the final result be different. Why? 1. id = mypid (); // Assign identification number: id=0 for processor 0, and id=1 for processor 1 2. read_array(X, Y, N); //read arrays X and Y that have size N 3. if (id == 0) //initialize the MAC 4. { 5. LOCK(global_MAC); 6. global_MAC = 0; 7. UNLOCK(global_MAC); 8. } 9. BARRIER(2); //waits for all processors to get to this point in the program BARRIER (4) 10. local_MAC = 0; 11. for (i =id*N/2; i < (id+1)*N/2; i++) for (i =id*N/4; i < (id+1)*N/4; i++) 12. local_MAC += X[i]*Y[i]; 13. LOCK(global_MAC); 14. global_MAC += local_MAC; 15. UNLOCK(global_MAC); 16. BARRIER(2); //waits for all processors to get to this point in the program BARRIER (4) 17. END;
![global_MAC = X[0]*Y[0]+ X[1]*Y[1]+… X[N-1]*Y[N-1]](http://slideplayer.com/slide/6918121/23/images/12/global_MAC+%3D+X%5B0%5D%2AY%5B0%5D%2B+X%5B1%5D%2AY%5B1%5D%2B%E2%80%A6+X%5BN-1%5D%2AY%5BN-1%5D.jpg "SHARED MEMORY. QUESTION #4 (MIDTERM) Consider a machine with 2 processors that share the same memory. Multiply and Accumulate operation. is performed: global_MAC = X[0]*Y[0]+ X[1]*Y[1]+… X[N-1]*Y[N-1] The MAC subroutine is implemented on both processors and it is shown bellow. Modify the program to make it suitable for execution in a four-processor machine. If processor P1 starts executing MAC subroutine before the processor P0, will the final result be different. Why 1. id = mypid (); // Assign identification number: id=0 for processor 0, and id=1 for processor read_array(X, Y, N); //read arrays X and Y that have size N. 3. if (id == 0) //initialize the MAC. 4. { 5. LOCK(global_MAC); 6. global_MAC = 0; 7. UNLOCK(global_MAC); 8. } 9. BARRIER(2); //waits for all processors to get to this point in the program BARRIER (4) 10. local_MAC = 0; 11. for (i =id*N/2; i < (id+1)*N/2; i++) for (i =id*N/4; i < (id+1)*N/4; i++) 12. local_MAC += X[i]*Y[i]; 13. LOCK(global_MAC); 14. global_MAC += local_MAC; 15. UNLOCK(global_MAC); 16. BARRIER(2); //waits for all processors to get to this point in the program BARRIER (4) 17. END;")
13
SHARED MEMORY Sum all the elements of an array Z of size n.
INITIALIZE; //assign proc_nums and num_procs read_array(Z, size); //read the array and array size from file if (proc_num == 0) //initialize the sum { LOCK(global_sum); global_sum = 0; UNLOCK(global_sum); } local_sum = 0; size_to_sum = size/num_procs; lower_ind = size_to_sum * proc_num; upper_ind = size_to_sum * (proc_num + 1); for (i = lower_ind; i < upper_ind; i++) local_sum += Z[i]; //if size =100, num_proc=4, processor 0 sums 0 to 24, proc 1 sums 25 to 49, etc. LOCK(global_sum); //locks the sum variable so only this process can change it global_sum += local_sum; UNLOCK(global_sum); //gives the sum back so other procs can add to it BARRIER(num_procs); //waits for num_procs to get to this point in the program if (proc_num == 0) printf("sum is %d", global_sum); END;
; //read the array and array size from file. if (proc_num == 0) //initialize the sum. { LOCK(global_sum); global_sum = 0; UNLOCK(global_sum); } local_sum = 0; size_to_sum = size/num_procs; lower_ind = size_to_sum * proc_num; upper_ind = size_to_sum * (proc_num + 1); for (i = lower_ind; i < upper_ind; i++) local_sum += Z[i]; //if size =100, num_proc=4, processor 0 sums 0 to 24, proc 1 sums 25 to 49, etc. LOCK(global_sum); //locks the sum variable so only this process can change it. global_sum += local_sum; UNLOCK(global_sum); //gives the sum back so other procs can add to it. BARRIER(num_procs); //waits for num_procs to get to this point in the program. if (proc_num == 0) printf( sum is %d , global_sum); END;")
14
SHARED MEMORY if M=2 and n = 4, then size_to_sum = 2 For P0
Cumulative sum the elements of an array Z of size n. i.e. C(i)=Z(1)+Z(2)+…Z(i). INITIALIZE; //assign proc_nums and M where M is the number of processors if (proc_num == 0) //initialize the sum C = {0}; BARRIER (M); read_array(Z, n); //read the array and array size n from file size_to_sum = n/M; lower_ind = size_to_sum * proc_num; upper_ind = size_to_sum * (proc_num + 1); for (i = lower_ind; i < upper_ind; i++) C[i]= C[i-1]+Z[i];//what happens when i-1 = 0-1 = 0?? Change to (i-1)>0?(i-1):0 //what happened when i-1 is not yet computed by another processor? BAD NEWS BARRIER(M); //waits for M processors to get to this point in the program for (j=M-1;j>=1;j--) { if (proc_num>=j) C[i]= C[i]+C[size_to_sum * j]; } if (proc_num == 0) for (i=0;i<=n;i++) printf("C[i]= %d", C[i]); END; if M=2 and n = 4, then size_to_sum = 2 For P0 lower_ind = 2*0=0 upper_ind = 2*1=2 C[0]=C[0]+Z[0]; C[1]=C[0]+Z[1]; For P1 lower_ind = 2*1=2 upper_ind = 2*2=4 C[2]=C[1]+Z[2]; C[3]=C[2]+Z[3];
=Z(1)+Z(2)+…Z(i). INITIALIZE; //assign proc_nums and M where M is the number of processors if (proc_num == 0) //initialize the sum C = {0}; BARRIER (M); read_array(Z, n); //read the array and array size n from file size_to_sum = n/M; lower_ind = size_to_sum * proc_num; upper_ind = size_to_sum * (proc_num + 1); for (i = lower_ind; i < upper_ind; i++) C[i]= C[i-1]+Z[i];//what happens when i-1 = 0-1 = 0 Change to (i-1)>0 (i-1):0 //what happened when i-1 is not yet computed by another processor BAD NEWS BARRIER(M); //waits for M processors to get to this point in the program for (j=M-1;j>=1;j--) { if (proc_num>=j) C[i]= C[i]+C[size_to_sum * j]; } if (proc_num == 0) for (i=0;i<=n;i++) printf( C[i]= %d , C[i]); END; if M=2 and n = 4, then size_to_sum = 2. For P0. lower_ind = 2*0=0 upper_ind = 2*1=2. C[0]=C[0]+Z[0]; C[1]=C[0]+Z[1]; For P1. lower_ind = 2*1=2 upper_ind = 2*2=4. C[2]=C[1]+Z[2]; C[3]=C[2]+Z[3];")
15
Let us do an example … see files in this folder

16
Questions?

Similar presentations












>")





 Review session,>")
 Multiprocessor: All processors can access all.>")
>")