Download presentation
Presentation is loading. Please wait.

1
Individual Differences in the Ability to Judge Others Accurately David A. Kenny University of Connecticut University of Connecticut http://davidakenny.net/kenny.htm

2
Overview Review of previous literature –Reliability Internal consistency Cross-target correlations Parallel forms New model: SCARIB

3
Accuracy About What? the targets personality Is Dave friendly? targets opinions or attitudes How does Dave feel about Lucy? what the target is currently thinking or feeling What is Dave thinking about now? the targets mood Is Dave excited or bored?

4
Judgmental Accuracy or JA

5
Judgemental Accuracy or JA

6
What Is Accuracy? Correspondence between a judgement and a criterion measure

7
A Renewed Interest in Individual Differences Interest in Emotional Intelligence (EQ) Models that Provide a Framework for Understanding Judge Moderators Neurological Deficits Creating Lower JA
 Models that Provide a Framework for Understanding Judge Moderators Neurological Deficits Creating Lower JA")
8
Types of Measures Standardized Scales (fixed targets) PONS IPT CARAT Sternberg measures Agreement Across Targets empathic accuracy (EA) slide viewing
 PONS IPT CARAT Sternberg measures Agreement Across Targets empathic accuracy (EA) slide viewing")
9
Standardized Scales Develop a pool of items Pick the good items Establish reliability as measured by internal consistency

10
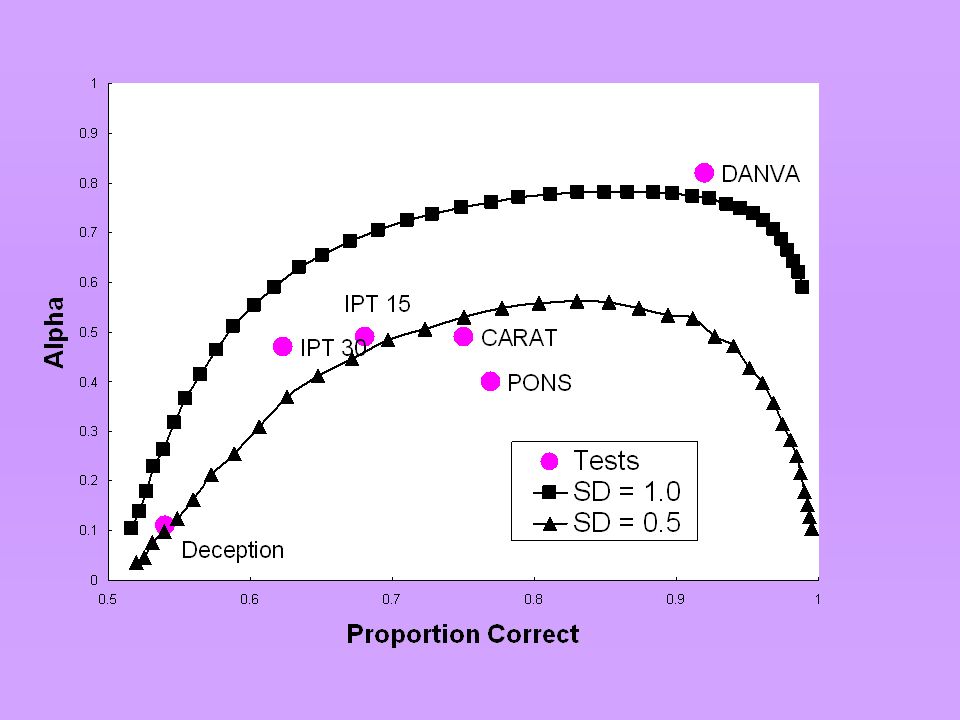
Low Reliability of Scales Scale IIC CARAT.56.038 IPT-30.52.035 IPT-15.38.039 PONS.86.027

11
Maybe an IIC of.03 Is Not All that Bad? Peabody Picture Vocabulary Test:.08 Beck Depression:.30 Bem M/F Scale:.19 Rosenberg Self-Esteem:.34 I guess it is bad.

12
Agreement Across Targets Same procedure, but different targets. example of slide viewing Treat target as an item to assess reliability.

13
Statistical Analysis of Multiple Target Data Social Relations Model Two-way data structure: Judge by Target Three sources of variance Judge Target Error and Relationship Judge/(Judge + Error) is like an IIC.
 is like an IIC.")
14
Social Relations Model Variance Partitioning: Emotion Recognition

15
Social Relations Model Variance Partitioning: Empathic Accuracy

16
Questions About EA Results Ickes et al. Many of the studies show very small amounts of judge variance 2 of the 3 studies that show the greatest level have only 3 targets, 2 of which are very similar Thomas & Fletcher Ad hoc analysis Possible nonindependence Perhaps individual differences emerge with emotionally-charged stimuli?

17
What Do We Learn? Small judge variance.10 Large target variance.30 Large error/relationship var..60

18
Convergent Validity? Do different tests of judgemental ability correlate?

19
Convergent Validity? CARAT 0.16 IPT-30 0.120.10 IPT15-0.02--- STERN 1 0.14--- STERN 2 0.16--- 0.02 PONSCARATIPT-30IPT-15STRN1

20
Summary of Convergent Validity Average correlation of about.10. Perhaps there are many skills? The different skills do not correlate highly.

21
Validity of JA? Recent Meta-analysis by Hall, Andrzejewski, and Yopchick (2008) gender differences (Hall: r.20) positive personality (r.08) negative personality (r -.07) social competence self rated (r.10) other rated (r.07)
 gender differences (Hall: r.20) positive personality (r.08) negative personality (r -.07) social competence self rated (r.10) other rated (r.07).")
22
Are There Individual Differences ? maybe not low internal consistency standardized scales cross-target studies (mostly) poor convergent validity
 poor convergent validity.")
23
intuition validity data hints at some validity Is JA the only skill or competence without any individual differences? That is, if people are scoring above chance, would not we expect individual differences? Maybe yes?

24
An Item Response Theory Model presume each question refers to a different item parameters r is ability (normally distributed variable) minus difficulty g is guessing (assuming two alternatives)
 minus difficulty g is guessing (assuming two alternatives)")
25
Model probability that the judge is correct: e r /(1 + e r ) (e approximately equals 2.718) allow for guessing e r /(1 + e r ) + g[1 (e r /(1 + e r )]
![Model probability that the judge is correct: e r /(1 + e r ) (e approximately equals 2.718) allow for guessing e r /(1 + e r ) + g[1 (e r /(1 + e r )]](http://images.slideplayer.com/2/691678/slides/slide_25.jpg "Model probability that the judge is correct: e r /(1 + e r ) (e approximately equals 2.718) allow for guessing e r /(1 + e r ) + g[1 (e r /(1 + e r )]")
26
Average Item Difficulty probability that judges are correct across all items allow for guessing What is the ideal average item difficulty? 75%? results from a simulation that varies average item difficulty…

28
Interpretation Curves peak in the high 80s Predicted by IRT (high.80s) Better to design easy tests Why? Performance of low ability judges is almost entirely due to chance. If you want to discriminate low ability judges, you need an easy test.

30
Limits of the Standard IRT Model Guessing assumed to be random Cannot score below chance Unidimensional

31
SCARIB Model Skewed Channels Attunement Reversal Information Biased Guessing

32
Channels Different sources of information Face Body Voice Different variables Negative emotion Positive emotion

33
Attunement Judgement is quite difficult: Many channels of information that must be monitored. A given judge generally allocates her or his attention in the same way. Metaphor of a radio: tuned into some channels more than others Different judges more attuned to different channels.

34
Skewed Total attunement represents the total resources that a judge can allocate to the task. The distribution of total resources is negatively skewed. Most judges have many resources. A few judges have very few resources. Total resources represents the true score.

35
Information For each channel of each item, there is information available. For a given test, there may be more information in some channels than in others.

36
Reversal Very often the information is counter- diagnostic. For example: Someone who is smiling may be unhappy.

37
Biased Guessing Assume two response alternatives (e.g., happy and sad) Some judges are biased in favor of one alternative and some in favor of the other.
 Some judges are biased in favor of one alternative and some in favor of the other.")
38
Formal Model for Judge i, Item j, and Channel k Resources: s i negatively skewed ranging from 0 to 10 Attunement: r ik = (1 – a)s i /c + ad ik s i or the allocation for judge i to channel k ( d ik = 1) Information: x ik = |z ik | I C IC Reversal: Some information is given a negative sign: x ik –x ik g ij = wh ij + (1 – w)/a where w is the amount of biased guessing and h ij is the direction (either 1 or 0)
s i /c + ad ik s i or the allocation for judge i to channel k ( d ik = 1) Information: x ik = |z ik | I C IC Reversal: Some information is given a negative sign: x ik –x ik g ij = wh ij + (1 – w)/a where w is the amount of biased guessing and h ij is the direction (either 1 or 0)")
39
IRT Equations for the Probability of Being Correct Diagnostic Information v ijk = (r ik x jk ) – 1.5(c + 1) e v /(1 + e v ) + g[1 (e v /(1 + e v )] Counter-Diagnostic Information v ijk = – (r ik x jk ) – 1.5(c + 1) g[1 (e v /(1 + e v )]
![IRT Equations for the Probability of Being Correct Diagnostic Information v ijk = (r ik x jk ) – 1.5(c + 1) e v /(1 + e v ) + g[1 (e v /(1 + e v )] Counter-Diagnostic Information v ijk = – (r ik x jk ) – 1.5(c + 1) g[1 (e v /(1 + e v )]](http://images.slideplayer.com/2/691678/slides/slide_39.jpg "IRT Equations for the Probability of Being Correct Diagnostic Information v ijk = (r ik x jk ) – 1.5(c + 1) e v /(1 + e v ) + g[1 (e v /(1 + e v )] Counter-Diagnostic Information v ijk = – (r ik x jk ) – 1.5(c + 1) g[1 (e v /(1 + e v )]")
40
Simulation 24 items 7 channels attunement reversal item biases biased guessing

41
Results SCARIB appears to be able to reproduce the basic results from JA studies. Also results agree with IRT and prior studies that the mean and alpha are positively correlated (r =.817)
.")
42
Why Low Internal Consistency? Multiple channels Information that varies by item or by item X channel Biased guessing However, attunement in conjunction with information varying by channel increases internal consistency.

43
Validity and Cross-Target Correlation Lowered by attunement in conjunction with information varying by channel. Slightly increased by biased guessing. Cross-target correlation mirrors validity (r =.929) much better than does internal consistency (r =.770).
 much better than does internal consistency (r =.770)..")
44
Why Target Variance? More information for some targets. Better information (i.e., fewer reversals) for some targets. Stereotype accuracy: Some targets conform more to item biases. Target differences are largely due to information differences, not to readability.
 for some targets. Stereotype accuracy: Some targets conform more to item biases. Target differences are largely due to information differences, not to readability..")
45
Why Below Chance Responding? Reversal Item Biases Reliability and validity can be improved by reversing some items when below-chance responding is due to reversal: Being wrong for the right reason. Reversal is counter productive when due to item biases.

46
One Major Limitation Ignores policy differences: You could be attuned to diagnostic information but use it the wrong way. Note though without allowing for policy differences, SCARIB does a good job reproducing JA results.

47
Implications JA tests should be easy. –Establish individual differences for deception. The cross-target correlation is a better way of validating a test than internal consistency. May, at times, be beneficial to use consensual criteria.

48
Final Point Needed are experiments and statistical analyses to better estimate the SCARIB parameters.

49
Kia ora! http://davidakenny.net/doc/scarib.ppt

50
Relationship to the Funders RAM Model Relevance: Is the information correlated with the correct answer (few reversals)? Availability: Does that information vary (|z| C I CI )? Detection: Is the judge attuned to that information (r ik )? Utilization: Does the judge know how to weight the information (o ijk )?
. Detection: Is the judge attuned to that information (r ik ). Utilization: Does the judge know how to weight the information (o ijk ) .")
51
Information (x jk ) C I CI The larger the above, the more available the information. A certain percentage of the information is reversed: If less than 50%, the information is diagnostic If equal to 50%, the information is irrelevant. If greater than 50%, the information is counter- diagnostic.

52
Details: Attunement (r ik ) c channels to which the judge can allocate resources to processing s i refers to the total resources that judge i can allocate to the task (1 – a)s i /c + ad ik s i refers to allocation for judge i to channel k ( d ik = 1) variance of s a measure of individual differences 7 channels (a working assumption)
 c channels to which the judge can allocate resources to processing s i refers to the total resources that judge i can allocate to the task (1 – a)s i /c + ad ik s i refers to allocation for judge i to channel k ( d ik = 1) variance of s a measure of individual differences 7 channels (a working assumption)")
53
Policy (o ijk ) Some judges have things backwards. For example, I might believe that being nice is a sign of hostility. Today we ignore this factor: Set o ijk = 1.

54
Judgement (v jik ) (a ik x jk o ik ) The above might be negative and so the judge may be inclined to believe in the wrong answer (one reason why there can be below chance responding). Parameter f is a difficulty (assumed to increase with more channels)
.")
55
Biased Guessing: Model g ij = wh ij + (1 – w)/a where w is the amount of biased guessing and h ij is the direction (either 1 or 0) In a standardized tests items are paired, and so g i1 = 1 – g i2.
/a where w is the amount of biased guessing and h ij is the direction (either 1 or 0) In a standardized tests items are paired, and so g i1 = 1 – g i2.")
56
Item Selection Issues Items that correlate may not measure a skill but rather a consistent bias. When correlations are small and sample sizes not large, there is the danger of capitalization on chance.

57
Follow-up Alphas? Scale nitial Follow-up CARAT.56.46 IPT-30.52.29 IPT-15.38.18

58
Reaction within the Area abandonment by some of the psychometric approach other forms of reliability (test- retest and split half) no attempt to explain the low inter-item correlations (.03)
 no attempt to explain the low inter-item correlations (.03)")
59
It is possible that most of the variance … is due to differences in the judgeability of targets as opposed to the sensitivity of the perceivers. Malone & DePaulo (2001)
.")
60
Channels: How Do They Work? Each item depends differentially on the different channels. Tests depend more on some channels than do others.

62
Still True Now? Our position is not that individual differences are nonexistent in interpersonal accuracy. Rather, we believe that the variability of such differences is rather limited. Kenny & Albright (1987)
.")
Similar presentations







 PS2001 Correlation and other topics.>")












