Download presentation
Presentation is loading. Please wait.

1
Specification Issues in Relational Models David A. Kenny University of Connecticut Talk can be downloaded at: http://davidakenny.net/talks/nd.ppt

2
Overview Preliminaries Group Effects: Univariate X Y Effects with Group Data

3
What Is a Group? dyads –husband-wife –teacher-student –siblings more than two people –families –work groups –classrooms

4
A. Distinguishability In some groups, members can be distinguished by the role: e.g., heterosexual couples are usually distinguished by gender. In other groups, e.g., some work groups, members are indistinguishable. That is, members of the group cannot be ordered.

5
B. Distinguishability Both a theoretical and empirical issue. Differences by variable. Partial distinguishability. Will assume in the rest of the talk that members are indistinguishable.

6
Design Presume that each person in the group measured once. Alternative designs one measure per group each dyad in the group is measured (Social Relations Model) one informant or target in the group
 one informant or target in the group.")
7
Example Data Acitelli Study 148 married heterosexual couples Y (outcome): satisfaction X: how positively the partner is viewed Will use SPSS to illustrate some of the computations
: satisfaction X: how positively the partner is viewed Will use SPSS to illustrate some of the computations")
8
Univariate Case

11
Nonindependence l Definition: the degree of greater similarity (or dissimilarity) between two observations from members of the same group than between two scores from members of different groups l How to model: a group effect
 between two observations from members of the same group than between two scores from members of different groups l How to model: a group effect")
12
Y11Y12 Y13 Y14 Group Y Person 2 in Group 1

13
Intraclass Correlation Group is treated as the independent variable in a one-way, between-subjects ANOVA: where: MS B is the mean square between groups, MS W is the mean square within groups, and k is the group size.

14
Interpretation The intraclass correlation can be viewed as the proportion of variance due to the group.

15
Computing Group Variance by SPSS MIXED Y /FIXED = /PRINT = SOLUTION TESTCOV /RANDOM INTERCEPT | SUBJECT(GROUP) COVTYPE(VC). Person is the unit of analysis. GROUP is a variable that codes what group each person is in.

16
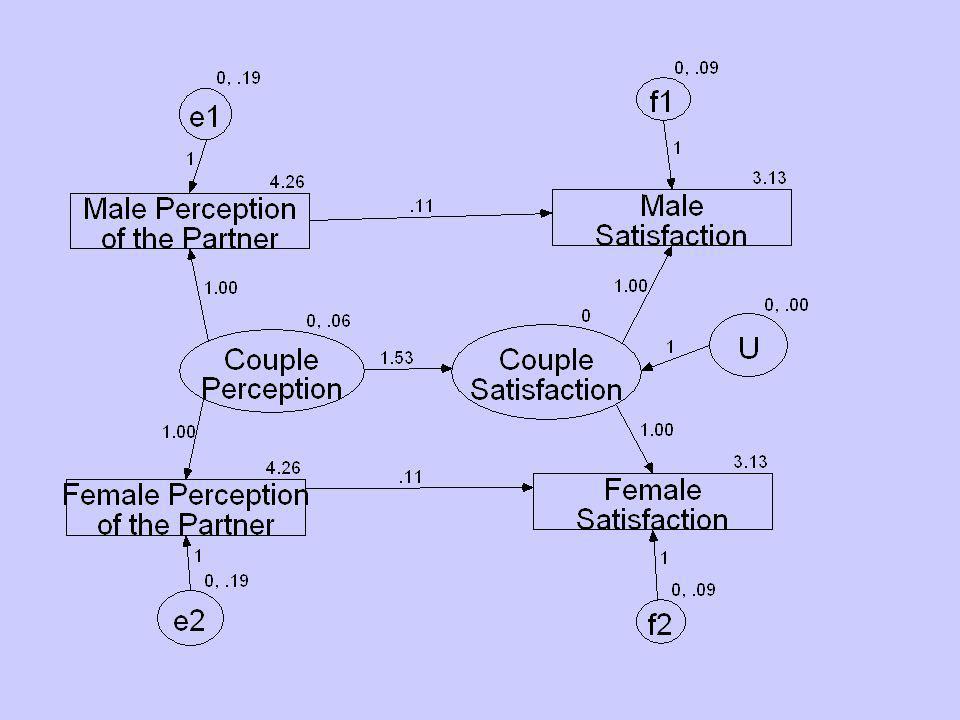
Example Error Variance (s E 2 ).094 Group Variance (s G 2 ).153 r I =.153/(.094 +.153) =.621 Husbands and wives similar in satisfaction.
.094 Group Variance (s G 2 ).153 r I =.153/( ) =.621 Husbands and wives similar in satisfaction.")
17
What if Negative? Nonindependence is a correlation. A correlation can be negative, but the proportion of group variance cannot be. Why would nonindependence be a negative intraclass correlation?

18
A. How Negative Correlations Might Arise? Compensation: If one person has a large score, the other person lowers his or her score. For example, if one person acts very friendly, the partner may distance him or herself, Social comparison: The members of the dyad use the relative difference on some measure to determine some other variable. For instance, satisfaction after a tennis match is determined by the score of that match.

19
B. How Negative Correlations Might Arise? Zero-sum: The sum of two scores is the same for each dyad. For instance, the two members divide a reward that is the same for all dyads. Division of labor: Dyad members assign one member to do one task and the other member to do another. For instance, the amount of housework done in the household may be negatively correlated.

20
Group Processes Make members similar: Solidarity Differentiate members: Status

21
Negative Intraclass Correlations Using SPSS MIXED Y /FIXED = /PRINT = SOLUTION TESTCOV /REPEATED = MEMBER | SUBJECT(GROUP) COVTYPE(CS). MEMBER is a variable that codes the different person in the group; e.g., it is 1, 2, and 3 in a three-person group. Not going to consider this any more.

22
II. X Y Effects with Group Data

23
Y11Y12 Y13 Y14 Group Y

24
Y11Y12 Y13 Y14 Group Y X11 X12 X13 X14

25
Computing X Y Effects in SPSS MIXED Y WITH X /FIXED = X /PRINT = SOLUTION TESTCOV /RANDOM INTERCEPT | SUBJECT(GROUP) COVTYPE(VC). X for example =.314 (CI of.219 to.408)
.")
26
X Y as a Random Variable The effect of X Y varies across groups. Requires groups of size 3 or more.

27
Random X Y Effects in SPSS MIXED Y WITH X /FIXED = X /PRINT = SOLUTION TESTCOV /RANDOM INTERCEPT X | SUBJECT(GROUP) COVTYPE(IN). IN allows for intercept and X effects to be correlated Not going to consider this any more.

28
X Y Effect May Occur at the Group Level Just because X is measured at the individual level does not mean that the effect of X on Y occurs only at that level. Need to model the effect of X on Y at more than the individual level. A simple idea but not so simple to do.

29
Consider Four Ways To Do So Group Mean (Contextual Analysis) Group Mean with Group Centering (Between-Within Analysis) Group Effect as a Latent Variable Group Effect as Everyone Else (Actor- Partner Interdependence Model)
 Group Mean with Group Centering (Between-Within Analysis) Group Effect as a Latent Variable Group Effect as Everyone Else (Actor- Partner Interdependence Model)")
30
Y11Y12 Y13 Y14 Group Y X11 X12 X13 X14 Mean X

31
Computing X Y Effects at Two Levels by SPSS MIXED Y WITH X XMEAN /FIXED = X XMEAN /PRINT = SOLUTION TESTCOV /RANDOM INTERCEPT | SUBJECT(GROUP) COVTYPE(VC).
 COVTYPE(VC).")
32
Example: Group Mean X.112(CI: -.001 to.226) XMEAN.576 (CI:.390 to.762) Suggests that when couples idealize, the couples are more satisfied.
 XMEAN.576 (CI:.390 to.762) Suggests that when couples idealize, the couples are more satisfied.")
33
Centering Group centering: Subtract from X the mean of X for the group in which the person is in. SPSS syntax is the same but now X become X or X minus the mean of X for the group.

34
Example: Group Centering X.112(CI: -.001 to.226) XMEAN.689 (CI:.539 to.837) Suggests that when couples view partner more favorably, the couples are more satisfied.
 XMEAN.689 (CI:.539 to.837) Suggests that when couples view partner more favorably, the couples are more satisfied.")
35
Group X as a Random Variable Group Mean may be an imperfect measure of the couple score. Treat X 11 and X 12 as indicators of a latent variable. Proposed by Kenny & La Voie in 1984 and a modified version by Griffin & Gonzalez used here.

36
Y11Y12 Y13 Y14 Group Y X11 X12 X13 X14 Group X

37
Estimation Not so easy to estimate the model with multilevel modeling Can use the Olsen & Kenny procedure (Psychological Methods, June issue).
.")
39
Example: Latent Group CI Variable Effect Lower Upper Individual.112.000.224 Latent Couple 1.532.574 2.490

40
Partner Effects Actor Effect or X –Member As X affects the member As Y Partner Effect or XMEAN –Member As X affects the member Bs Y

43
Estimating Partner Effects by SPSS MIXED Y WITH X XPART /FIXED = X XPART /PRINT = SOLUTION TESTCOV /RANDOM INTERCEPT | SUBJECT(GROUP) COVTYPE(VC). XPART is the mean of X of the other members in the group or XMEAN

44
Example: Partner Effects CI Effect b Lower Upper Actor or X.400.307.494 Partner (XMEAN).288.195.381
")
45
Four Answers Effect Individual Couple X & Mean.112.576 X & Mean.112.689 X & Latent.112 1.532 X & Mean.400.288

46
Four Ways Group Mean (Contextual Analysis) Group Mean with Group Centering (Between-Within Analysis) Group Effect as a Latent Variable Group Effect as Everyone Else (Actor- Partner Interdependence Model)
 Group Mean with Group Centering (Between-Within Analysis) Group Effect as a Latent Variable Group Effect as Everyone Else (Actor- Partner Interdependence Model)")
47
Which Is Right? All four are right! Each has advantages and disadvantages.

48
X & Mean Long history: contextual analysis Easily embedded within multilevel modeling

49
X & Mean (Between-Within) Statistical advantage: two effects orthogonal Easily embedded within multilevel modeling as group centered
 Statistical advantage: two effects orthogonal Easily embedded within multilevel modeling as group centered")
50
X & Latent Cannot work if the intraclass for X is not positive and estimates are unstable when intraclass is small Latent variable must make sense Not easily estimated Can lead to anomalous results Not frequently adopted by practitioners.

51
X & Mean (APIM) Has a simple interpretation Interaction can be meaningful Very popular in dyadic analysis Not used frequently in group research
 Has a simple interpretation Interaction can be meaningful Very popular in dyadic analysis Not used frequently in group research")
52
Translation of Effects We use the X and XMEAN analysis as the basic analysis. Denote i as the effect of X and g as the effect of XMEAN and k as group size: within= i and between = g + i actor = i + g/k and partner = (k – 1)g/k For the latent variable model, the X effect is again i, and the group effect equals p[1/(k – 1) + r x ]/r x where p is the partner effect and r x is the intraclass correlation for X.
g/k For the latent variable model, the X effect is again i, and the group effect equals p[1/(k – 1) + r x ]/r x where p is the partner effect and r x is the intraclass correlation for X..")
53
Concluding Comments In studying groups you need to give careful thought as to what type of effects might occur. No one right way to model effects. Be open to alternative ways to estimate effects. Beware of over-simplification Beware of over-complexity THINK!!!

54
Kenny, D. A., Mannetti, L., Pierro, A., Livi, S., & Kashy, D. A. (2002). The statistical analysis of data from small groups. Journal of Personality and Social Psychology, 83, 126-137. Kenny, D. A., Kashy, D. A., & Cook, W. L. (2007) Dyadic data analysis. New York: The Guilford Press. Talk can be downloaded at: http://davidakenny.net/talks/nd.ppt
. The statistical analysis of data from small groups. Journal of Personality and Social Psychology, 83, Kenny, D. A., Kashy, D. A., & Cook, W. L. (2007) Dyadic data analysis. New York: The Guilford Press. Talk can be downloaded at:")
Similar presentations