Download presentation
Presentation is loading. Please wait.

1
Lecture 4 1.Protein Function prediction using network concepts 2.Hierarchical Clustering

2
Topology of Protein-protein interaction is informative but further analysis can reveal other information. A popular assumption, which is true in many cases is that similar function proteins interact with each other. Based on these assumption, we have developed methods to predict protein functions and protein complexes from the PPI networks mainly based on cluster analysis.

3
Cluster Analysis Cluster Analysis, also called data segmentation, implies grouping or segmenting a collection of objects into subsets or "clusters", such that those within each cluster are more closely related to one another than objects assigned to different clusters. In the context of a graph densely connected nodes are considered as clusters Visually we can detect two clusters in this graph

4
K-cores of Protein-Protein Interaction Networks Definition Let, a graph G=(V, E) consists of a finite set of nodes V and a finite set of edges E. A subgraph S=(V, E) where V V and E E is a k-core or a core of order k of G if and only if v V: deg(v) k within S and S is the maximal subgraph of this property.
 where V V and E E is a k-core or a core of order k of G if and only if v V: deg(v) k within S and S is the maximal subgraph of this property..")
5
1-core graph: The degree of all nodes are one or more Graph G Concept of a k-core graph

6
1-core graph: The degree of all nodes are one or more Concept of a k-core graph

7
2-core graph: The degree of all nodes are two or more Concept of a k-core graph

8
1-core graph: The degree of all nodes are one or more Concept of a k-core graph

9
3-core graph: The degree of all nodes are three or more The 3-core is the highest k-core subgraph of the graph G Graph G

10
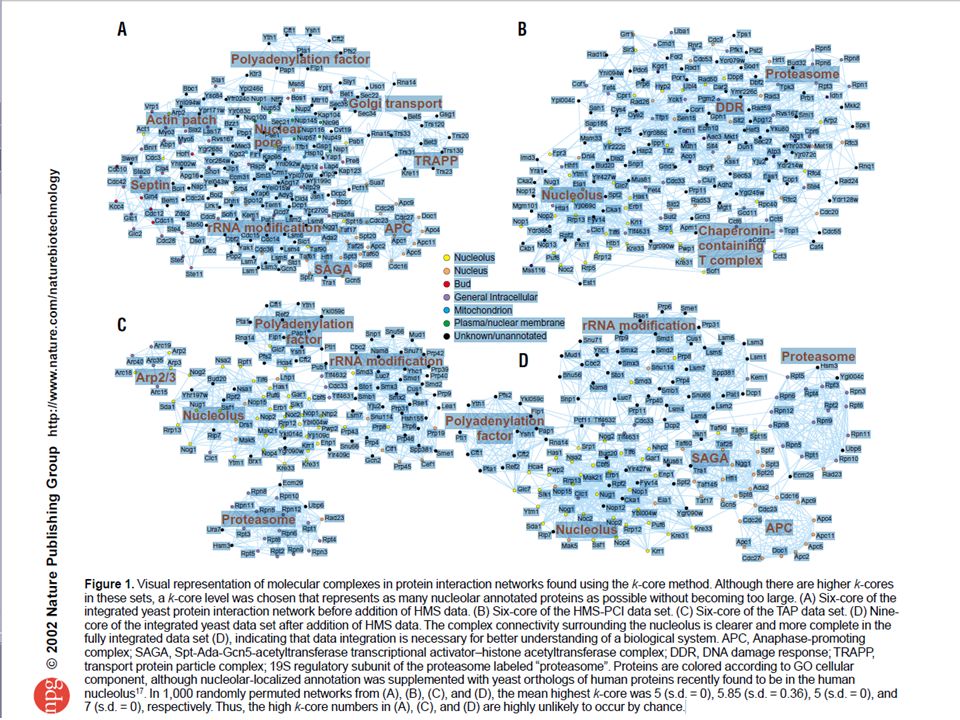
Analyzing protein-protein interaction data obtained from different sources, G. D. Bader and C.W.V. Hogue, Nature biotechnology, Vol 20, 2002 Application of a k-core graph

12
Protein function prediction using k-core graphs

13
Hishigaki, H., Nakai, K., Ono, T., Tanigami, A., and Tagaki, T. Assessment of prediction accuracy of protein function from protein-protein interaction data. Yeast 18, 523-531 (2001) Reported similar results.. Schwikowski, B., Uetz, P. and Fields, S. A network of protein- protein interactions in yeast. Nature Biotech. 18, 1257-1261 (2000) Deals with a network of 2039 proteins and 2709 interactions. 65% of interactions occurred between protein pairs with at least one common function Introduction : Function prediction
 Reported similar results.. Schwikowski, B., Uetz, P. and Fields, S. A network of protein- protein interactions in yeast. Nature Biotech. 18, (2000) Deals with a network of 2039 proteins and 2709 interactions. 65% of interactions occurred between protein pairs with at least one common function Introduction : Function prediction.")
14
14 Hypothesis Unknown function proteins that form densely connected subgraph with proteins of a particular function may belong to that functional group. Introduction : Function prediction We utilize this concept by determining k-cores of strategically constructed sub-networks.

15
Prediction of Protein Functions Based on K-cores of Protein-Protein Interaction Networks “Prediction of Protein Functions Based on K-cores of Protein-Protein Interaction Networks and Amino Acid Sequences”, Md. Altaf-Ul-Amin, Kensaku Nishikata, Toshihiro Koma, Teppei Miyasato, Yoko Shinbo, Md. Arifuzzaman, Chieko Wada, Maki Maeda, Taku Oshima, Hirotada Mori, Shigehiko Kanaya The 14th International Conference on Genome Informatics December 14-17, 2003, Yokohama Japan.

16
Total 3007 proteins and 11531 interactions Around 2000 are unknown function proteins Highest K-core of this total graph is not so helpful E.Coli PPI network

17
10-core graph—the highest k-core of the E.Coli PPI network

18
We separate 1072 interactions (out of 11531) involving protein synthesis and function unknown proteins. P. S.U. F. P. S.

19
Unknown Function unknown Proteins of this 6-kore graph are likely to be involved in protein synthesis

20
Extending the k-core based function prediction method and its application to PPI data of Arabidopsis thaliana Protein Function Prediction based on k-cores of Interaction Networks, Norihiko Kamakura, Hiroki Takahashi, Kensuke Nakamura, Shigehiko Kanaya and Md. Altaf-Ul-Amin, Proceedings of 2010 International Conference on Bioinformatics and Biomedical Technology (ICBBT 2010)
.")
21
21 Materials and Methods : Dataset All PPI data of Arabidopsis thaliana 3118 interactions involving 1302 proteins. Collected from databases and scientific literature by our laboratory. Green= Unknown proteins (289 proteins) Pink= Known proteins (1013 proteins)
 Pink= Known proteins (1013 proteins).")
22
22 Materials and Methods : Dataset Functional groups in the network The PPI dataset contains proteins of 19 different functions according to the first level categories of the KNApSAcK database.

23
23 Materials and Methods : Dataset The trends of interactions in the context of functional similarity Diagonal elements show number of interactions between similar function proteins.

24
24 Materials And Methods : Flowchart of the method

25
25 Results : Subnetworks we do not consider in this work the sub-networks that contain less than 100 interactions. And finally I consider subnetworks corresponding to 9 functional classes. Subnetwork Name Number of interactions

26
26 Subnetwork extraction Cellular communication-Cellular communication Cellular communication-Unknown, Unknown-Unknown Total 603 interactions We extracted the following 3 types of interactions. Results : Subnetwork corresponding to cellular communication As an example here we show the subnetworks and k-cores corresponding to cellular communication.

27
27 1-core Results : Subnetwork corresponding to cellular communication The red nodes : known proteins. The green nodes : unknown proteins.

28
28 2-core 3-core The red color nodes represent known proteins, the green color nodes represent function unknown proteins. Results : k-cores corresponding to cellular communication The red nodes : known proteins. The green nodes : unknown proteins.

29
29 4-core 5-core The red nodes : known proteins The green nodes : unknown proteins. 6-core 7-core This figure implies that determination of k-cores in strategically constructed sub-networks can reveal which unknown proteins are densely connected to proteins of a particular functional class. Results : k-cores corresponding to cellular communication

30
30 k-core 2k-core 3k-core 4k-core 5k-core 6k-core 7k-core 8 cell_cycle117 cell_rescue4 cellular_communicati on37332315128 energy5222222 metabo511 protein_fate693525 1510 protein_synthesis2 transcription3324141188 transport_facilitation2 total12988645236272 The number of unknown genes included in different k-cores corresponding to different functional groups Results : Function Predictions

31
31 Most proteins have been assigned unique functions and some have been assigned multiple functions 2-core 3-core Prediction based on 2-cores, 3-cores and 4-cores Results : Function Predictions 4-core Most proteins have been assigned unique functions

32
32 Assessment of Predictions However to assess statistically, we constructed 1000 random graphs consisting of the same 1,302 proteins but I inserted 3,118 edges randomly and constructed subnetworks. When k is much larger than one, the effect of false positives is greatly reduced. As most of the function predicted proteins are still unknown their annotations do not contain clear information on their functions.

33
The box plots show the distribution of k-cores with respect to their size in 1000 graphs corresponding to each sub-network and the filled triangles show the size of k-cores in real PPI sub-networks. Assessment of Predictions

34
34 Assessment of Predictions it can be theoretically concluded that the existence of higher order k-core graphs in PPI sub-networks compared to in the random graphs of the same size are likely to be because of interaction between similar function proteins. Therefore we assume that the function prediction based on k-cores for the value of k greater than highest possible value of k for corresponding random graphs are statistically significant predictions. Based on this we predicted the functions of 67 proteins(list is available online at http://kanaya.naist.jp/Kcore/supplementary/Function_pre diction.xls. http://kanaya.naist.jp/Kcore/supplementary/Function_pre diction.xls

35
“Prediction of Protein Functions Based on Protein- Protein Interaction Networks: A Min-Cut Approach”, Md. Altaf-Ul-Amin, Toshihiro Koma, Ken Kurokawa, Shigehiko Kanaya, Proceedings of the Workshop on Biomedical Data Engineering (BMDE), Tokyo, Japan, pp. 37-43, April 3-4, 2005.
, Tokyo, Japan, pp , April 3-4,")
36
Outline Introduction The concept of Min-Cut Problem Formulation A Heuristic Method Evaluation of the Proposed Method Conclusions

37
Outline Introduction The concept of Min-Cut Problem Formulation A Heuristic Method Evaluation of the Proposed Method Conclusions

38
Introduction After the complete sequencing of several genomes, the challenging problem now is to determine the functions of proteins 1)Determining protein functions experimentally 2)Using various computational methods a) sequence b) structure c) gene neighborhood d) gene fusions e) cellular localization f) protein-protein interactions
Determining protein functions experimentally 2)Using various computational methods a) sequence b) structure c) gene neighborhood d) gene fusions e) cellular localization f) protein-protein interactions")
39
Present work predicts protein functions based on protein- protein interaction network. Introduction For the purpose of prediction, we consider the interactions of function-unknown proteins with function-known proteins and function-unknown proteins with function-unknown proteins In the context of the whole network.

40
Hence we call the proposed approach a Min-Cut approach. Introduction Majority of protein-protein interactions are between similar function protein pairs. Therefore, We assign function-unknown proteins to different functional groups in such a way so that the number of inter-group interactions becomes the minimum.

41
Outline Introduction The concept of Min-Cut Problem Formulation A Heuristic Method Evaluation of the Proposed Method Conclusions

42
U4 K2 K6 K4 K3 K1 K8 K5 U1 U2 U3 The concept of Min-Cut G1G1 G2G2 A typical and small network of known and unknown proteins

43
U4 K K K K K K K U1 U2 U3 G1G1 G2G2 The concept of Min-Cut Unknown proteins assigned to known groups based on majority interactions

44
U4 K K K K K K K U1 U2 U3 G1G1 G2G2 The concept of Min-Cut Number of CUT = 4

45
U4 K K K K K K K U1 U2 U3 G1G1 G2G2 The concept of Min-Cut An alternative assignment of unknown proteins

46
U4 K K K K K K K U1 U2 U3 G1G1 G2G2 The concept of Min-Cut Number of CUT = 2 For every assignment of unknown proteins, there is a value of CUT. Min-cut approach looks for an assignment for which the number of CUT is minimum.

47
Outline Introduction The concept of Min-Cut Problem Formulation A Heuristic Method Evaluation of the Proposed Method Conclusions

48
Problem Formulation Here we explain some points with a typical example.

49
V= set of all nodes E =set of all edges G={K1, K2, K3, K4, K5, K6, K7, K8, K9, K10} U={U1, U2, U3, U4, U5, U6, U7, U8} Problem Formulation

50
U´= {U1, U2, U3, U4, U5, U6, U7} Problem Formulation We generate U´ U such that each protein of U´ is connected in N with at least one protein of group G by a path of length 1 or length 2.

51
For this assignment of unknown proteins, the CUT= 6 Interactions between known protein pairs can never be part of CUT Problem Formulation We can assign proteins of U´ to different groups and calculate CUT

52
The problem we are trying to solve is to assign the proteins of set U´ to known groups G 1, G 2,…….., G 3 in such a way so that the CUT becomes the minimum. Problem Formulation

53
Outline Introduction The concept of Min-Cut Problem Formulation A Heuristic Method Evaluation of the Proposed Method Conclusions

54
The problem under hand is a variant of network partitioning problem. It is known that network partitioning problems are NP-hard. Therefore, we resort to some heuristics to find a solution as better as it is possible. A Heuristic Method

55
U1 U2 U3 U4 U5 U6 U7

56
U1G2G1x U2 U3 U4 U5 U6 U7 A Heuristic Method U1 has one path of length 1 with G 2 and two paths of length two with G 1

57
U1G2G1x U2G2G1x U3G2G1x U4G1G2G3 U5 U6 U7 A Heuristic Method U4 has two paths of length 1 with G 1, one path of length one with G 2 and one path of length two with G 3.

58
U1G2G1x U2G2G1x U3G2G1x U4G1G2G3 U5G1G2G3 U6G1G3G2 U7G3G2x A Heuristic Method

59
U1G2G1x U2G2G1x U3G2G1x U4G1G2G3 U5G1G2G3 U6G1G3G2 U7G3G2x A Heuristic Method

60
U1G2G1x U2G2G1x U3G2G1x U4G1G2G3 U5G1G2G3 U6G1G3G2 U7G3G2x A Heuristic Method By assigning all the unknown proteins to respective height priority groups, CUT = 6

61
U1G2G1x U2G2G1x U3G2G1x U4G1G2G3 U5G1G2G3 U6G1G3G2 U7G3G2x A Heuristic Method For this assignment of unknown proteins, the CUT= 7

62
U1G2G1x U2G2G1x U3G2G1x U4G1G2G3 U5G1G2G3 U6G1G3G2 U7G3G2x For this assignment of unknown proteins, the CUT= 4 A Heuristic Method

63
Outline Introduction The concept of Min-Cut Problem Formulation A Heuristic Method Evaluation of the Proposed Method Conclusions

64
Evaluation of the Proposed Approach The proposed method is a general one and can be applied to any organism and any type of functional classification. Here we applied it to yeast Saccharomyces cerevisiae protein-protein interaction network We obtain the protein-protein interaction data from ftp://ftpmips.gsf.de/yeast/PPI/ which contains 15613 genetic and physical interactions.

65
YAR019cYMR001c YAR019cYNL098c YAR019cYOR101w YAR019cYPR111w YAR027wYAR030c YAR027wYBR135w YAR031wYBR217w-------------------------- Total 12487 pairs We discard self- interactions and extract a set of 12487 unique binary interactions involving 4648 proteins. Evaluation of the Proposed Approach

66
A network of 12487 interactions and 4648 proteins is reasonably big Evaluation of the Proposed Approach

67
We collect from http://mips.gsf.de/genre/proj/yeast/index.jsp the classification data Evaluation of the Proposed Approach

68
The proposed approach is intended to predict the functions of function-unknown proteins. However, by predicting the functions of function-unknown proteins, it is not possible to determine the correctness of the predictions. We consider around 10% randomly selected proteins of each group of Table 1 as function-unknown proteins. Evaluation of the Proposed Approach

69
The union of 10% of all groups consists of 604 proteins. This is the unknown group U. The union of the rest 90% of each of the functional groups constitutes the set of known proteins G. There are total 3783 proteins in G. We generate U´ U such that each protein of U´ is connected in N with at least one protein of group G by a path of length 1 or length 2. There are 470 proteins in U´. We predicted functions of these 470 proteins using the proposed method. Evaluation of the Proposed Approach

70
We applied this algorithm using Max_value=50000 to predict the functions 470 proteins. Evaluation of the Proposed Approach

71
We cannot guarantee that minimum CUT corresponds to maximum successful prediction. However, the trends of the results of the Figure above shows that it is very likely that the lower is the value of CUT the greater is the number of successful predictions Evaluation of the Proposed Approach

72
We then examine the relation of successful predictions with the number of degrees of the proteins in the network. Evaluation of the Proposed Approach Degree of U4 =7 Degree of U7=3

73
We then examine the relation of successful predictions with the number of degrees of the proteins in the network. Evaluation of the Proposed Approach

74
The success rate of prediction is as low as 30.46% for proteins that have only one degree in the interaction network. However it is 67.61% for proteins that have degrees 8 or more. This implies that the reliability of the prediction can be improved by providing reasonable amount of interaction information Evaluation of the Proposed Approach

75
Hierarchical clustering

76
Hierarchical Clustering AtpBAtpA AtpGAtpE AtpAAtpH AtpBAtpH AtpGAtpH AtpEAtpH Data is not always available as binary relations as in the case of protein-protein interactions where we can directly apply network clustering algorithms. In many cases for example in case of microarray gene expression analysis the data is multivariate type. An Introduction to Bioinformatics Algorithms by Jones & Pevzner

77
We can convert multivariate data into networks and can apply network clustering algorithm about which we will discuss in some later class. If dimension of multivariate data is 3 or less we can cluster them by plotting directly. Hierarchical Clustering An Introduction to Bioinformatics Algorithms by Jones & Pevzner

78
However, when dimension is more than 3, we can apply hierarchical clustering to multivariate data. In hierarchical clustering the data are not partitioned into a particular cluster in a single step. Instead, a series of partitions takes place. Some data reveal good cluster structure when plotted but some data do not. Data plotted in 2 dimensions Hierarchical Clustering

79
Hierarchical clustering is a technique that organizes elements into a tree. A tree is a graph that has no cycle. A tree with n nodes can have maximum n-1 edges. A Graph A tree Hierarchical Clustering

80
Hierarchical Clustering is subdivided into 2 types 1.agglomerative methods, which proceed by series of fusions of the n objects into groups, 2.and divisive methods, which separate n objects successively into finer groupings. Agglomerative techniques are more commonly used Data can be viewed as a single cluster containing all objects to n clusters each containing a single object. Hierarchical Clustering

81
Distance measurements Euclidean distance between g 1 and g 2 Hierarchical Clustering

82
An Introduction to Bioinformatics Algorithms by Jones & Pevzner In stead of Euclidean distance correlation can also be used as a distance measurement. For biological analysis involving genes and proteins, nucleotide and or amino acid sequence similarity can also be used as distance between objects Hierarchical Clustering

83
An agglomerative hierarchical clustering procedure produces a series of partitions of the data, P n, P n-1,......., P 1. The first P n consists of n single object 'clusters', the last P1, consists of single group containing all n cases. At each particular stage the method joins together the two clusters which are closest together (most similar). (At the first stage, of course, this amounts to joining together the two objects that are closest together, since at the initial stage each cluster has one object.) Hierarchical Clustering
. (At the first stage, of course, this amounts to joining together the two objects that are closest together, since at the initial stage each cluster has one object.) Hierarchical Clustering.")
84
An Introduction to Bioinformatics Algorithms by Jones & Pevzner Differences between methods arise because of the different ways of defining distance (or similarity) between clusters. Hierarchical Clustering

85
How can we measure distances between clusters? Single linkage clustering Distance between two clusters A and B, D(A,B) is computed as D(A,B) = Min { d(i,j) : Where object i is in cluster A and object j is cluster B} Hierarchical Clustering
 is computed as D(A,B) = Min { d(i,j) : Where object i is in cluster A and object j is cluster B} Hierarchical Clustering.")
86
Complete linkage clustering Distance between two clusters A and B, D(A,B) is computed as D(A,B) = Max { d(i,j) : Where object i is in cluster A and object j is cluster B} Hierarchical Clustering
 is computed as D(A,B) = Max { d(i,j) : Where object i is in cluster A and object j is cluster B} Hierarchical Clustering")
87
Average linkage clustering Distance between two clusters A and B, D(A,B) is computed as D(A,B) = T AB / ( N A * N B ) Where T AB is the sum of all pair wise distances between objects of cluster A and cluster B. N A and N B are the sizes of the clusters A and B respectively. Total N A * N B edges Hierarchical Clustering

88
Average group linkage clustering Distance between two clusters A and B, D(A,B) is computed as D(A,B) = = Average { d(i,j) : Where observations i and j are in cluster t, the cluster formed by merging clusters A and B } Total n(n-1)/2 edges Hierarchical Clustering
 is computed as D(A,B) = = Average { d(i,j) : Where observations i and j are in cluster t, the cluster formed by merging clusters A and B } Total n(n-1)/2 edges Hierarchical Clustering")
89
Alizadeh et al. Nature 403: 503-511 (2000). Hierarchical Clustering
. Hierarchical Clustering")
90
Classifying bacteria based on 16s rRNA sequences.

Similar presentations





 for Clustering Gene Expression Data K. Y. Yeung and W. L. Ruzzo.>")









 Analysis of co-expression Search for similarly expressed genes experiment1 experiment2 experiment3 ……….. Gene i:>")



