Download presentation
Presentation is loading. Please wait.

1
Information Extraction from the World Wide Web Discriminative Finite State Models, Feature Induction & Scoped Learning Andrew McCallum University of Massachusetts, Amherst

2
An HR office Jobs, but not HR jobs

3
Extracting Job Openings from the Web foodscience.com-Job2 JobTitle: Ice Cream Guru Employer: foodscience.com JobCategory: Travel/Hospitality JobFunction: Food Services JobLocation: Upper Midwest Contact Phone: 800-488-2611 DateExtracted: January 8, 2001 Source: www.foodscience.com/jobs_midwest.html OtherCompanyJobs: foodscience.com-Job1

9
Extracting Continuing Education Courses Data automatically extracted from www.calpoly.edu Data automatically extracted from www.calpoly.edu Source web page. Color highlights indicate type of information. (e.g., orange=course #) Source web page. Color highlights indicate type of information. (e.g., orange=course #)
 Source web page. Color highlights indicate type of information. (e.g., orange=course #).")
10
This took place in ‘99 Not in Maryland Courses from all over the world

15
Why prefer “knowledge base search” over “page search” Targeted, restricted universe of hits –Don’t show resumes when I’m looking for job openings. Specialized queries –Topic-specific –Multi-dimensional –Based on information spread on multiple pages. Get correct granularity –Site, page, paragraph Specialized display –Super-targeted hit summarization in terms of DB slot values Ability to support sophisticated data mining

16
What is “Information Extraction” Filling slots in a database from sub-segments of text. As a task: October 14, 2002, 4:00 a.m. PT For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation. Today, Microsoft claims to "love" the open- source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers. "We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“ Richard Stallman, founder of the Free Software Foundation, countered saying… NAME TITLE ORGANIZATION

17
What is “Information Extraction” Filling slots in a database from sub-segments of text. As a task: October 14, 2002, 4:00 a.m. PT For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation. Today, Microsoft claims to "love" the open- source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers. "We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“ Richard Stallman, founder of the Free Software Foundation, countered saying… NAME TITLE ORGANIZATION Bill Gates CEO Microsoft Bill Veghte VP Microsoft Richard Stallman founder Free Soft.. IE

18
What is “Information Extraction” Information Extraction = segmentation + classification + clustering + association As a family of techniques: October 14, 2002, 4:00 a.m. PT For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation. Today, Microsoft claims to "love" the open- source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers. "We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“ Richard Stallman, founder of the Free Software Foundation, countered saying… Microsoft Corporation CEO Bill Gates Microsoft Gates Microsoft Bill Veghte Microsoft VP Richard Stallman founder Free Software Foundation

19
What is “Information Extraction” Information Extraction = segmentation + classification + association + clustering As a family of techniques: October 14, 2002, 4:00 a.m. PT For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation. Today, Microsoft claims to "love" the open- source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers. "We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“ Richard Stallman, founder of the Free Software Foundation, countered saying… Microsoft Corporation CEO Bill Gates Microsoft Gates Microsoft Bill Veghte Microsoft VP Richard Stallman founder Free Software Foundation

20
What is “Information Extraction” Information Extraction = segmentation + classification + association + clustering As a family of techniques: October 14, 2002, 4:00 a.m. PT For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation. Today, Microsoft claims to "love" the open- source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers. "We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“ Richard Stallman, founder of the Free Software Foundation, countered saying… Microsoft Corporation CEO Bill Gates Microsoft Gates Microsoft Bill Veghte Microsoft VP Richard Stallman founder Free Software Foundation

21
What is “Information Extraction” Information Extraction = segmentation + classification + association + clustering As a family of techniques: October 14, 2002, 4:00 a.m. PT For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation. Today, Microsoft claims to "love" the open- source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers. "We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“ Richard Stallman, founder of the Free Software Foundation, countered saying… Microsoft Corporation CEO Bill Gates Microsoft Gates Microsoft Bill Veghte Microsoft VP Richard Stallman founder Free Software Foundation NAME TITLE ORGANIZATION Bill Gates CEOMicrosoft Bill Veghte VP Microsoft RichardStallman founder Free Soft.. * * * *

22
IE in Context Create ontology Segment Classify Associate Cluster Load DB Spider Query, Search Data mine IE Document collection Database Filter by relevance Label training data Train extraction models

23
Hidden Markov Models S t-1 S t O t S t+1 O t +1 O t - 1... Finite state model Graphical model Parameters: for all states S={s 1,s 2,…} Start state probabilities: P(s t ) Transition probabilities: P(s t |s t-1 ) Observation (emission) probabilities: P(o t |s t ) Training: Maximize probability of training observations (w/ prior) HMMs are the standard sequence modeling tool in genomics, speech, NLP, …... transitions observations o 1 o 2 o 3 o 4 o 5 o 6 o 7 o 8 Generates: State sequence Observation sequence Usually a multinomial over atomic, fixed alphabet
 Transition probabilities: P(s t |s t-1 ) Observation (emission) probabilities: P(o t |s t ) Training: Maximize probability of training observations (w/ prior) HMMs are the standard sequence modeling tool in genomics, speech, NLP, …... transitions observations o 1 o 2 o 3 o 4 o 5 o 6 o 7 o 8 Generates: State sequence Observation sequence Usually a multinomial over atomic, fixed alphabet.")
24
IE with Hidden Markov Models Yesterday Lawrence Saul spoke this example sentence. Person name: Lawrence Saul Given a sequence of observations: and a trained HMM: Find the most likely state sequence: (Viterbi) Any words said to be generated by the designated “person name” state extract as a person name:
 Any words said to be generated by the designated person name state extract as a person name:.")
25
HMM Example: “Nymble” Other examples of shrinkage for HMMs in IE: [Freitag and McCallum ‘99] Task: Named Entity Extraction [Bikel, et al 1998], [BBN “IdentiFinder”] Person Org Other (Five other name classes) start-of- sentence end-of- sentence Transition probabilities Observation probabilities P(s t | s t-1, o t-1 ) P(o t | s t, s t-1 ) Back-off to: P(s t | s t-1 ) P(s t ) P(o t | s t, o t-1 ) P(o t | s t ) P(o t ) or
![HMM Example: Nymble Other examples of shrinkage for HMMs in IE: [Freitag and McCallum ‘99] Task: Named Entity Extraction [Bikel, et al 1998], [BBN IdentiFinder ] Person Org Other (Five other name classes) start-of- sentence end-of- sentence Transition probabilities Observation probabilities P(s t | s t-1, o t-1 ) P(o t | s t, s t-1 ) Back-off to: P(s t | s t-1 ) P(s t ) P(o t | s t, o t-1 ) P(o t | s t ) P(o t ) or](http://images.slideplayer.com/23/6867552/slides/slide_25.jpg "HMM Example: Nymble Other examples of shrinkage for HMMs in IE: [Freitag and McCallum ‘99] Task: Named Entity Extraction [Bikel, et al 1998], [BBN IdentiFinder ] Person Org Other (Five other name classes) start-of- sentence end-of- sentence Transition probabilities Observation probabilities P(s t | s t-1, o t-1 ) P(o t | s t, s t-1 ) Back-off to: P(s t | s t-1 ) P(s t ) P(o t | s t, o t-1 ) P(o t | s t ) P(o t ) or")
26
Regrets from Atomic View of Tokens Would like richer representation of text: multiple overlapping features, whole chunks of text. line, sentence, or paragraph features: –length –is centered in page –percent of non-alphabetics –white-space aligns with next line –containing sentence has two verbs –grammatically contains a question –contains links to “authoritative” pages –emissions that are uncountable –features at multiple levels of granularity Example word features: –identity of word –is in all caps –ends in “-ski” –is part of a noun phrase –is in a list of city names –is under node X in WordNet or Cyc –is in bold font –is in hyperlink anchor –features of past & future –last person name was female –next two words are “and Associates”

27
Problems with Richer Representation and a Generative Model These arbitrary features are not independent: –Overlapping and long-distance dependences –Multiple levels of granularity (words, characters) –Multiple modalities (words, formatting, layout) –Observations from past and future HMMs are generative models of the text: Generative models do not easily handle these non- independent features. Two choices: –Model the dependencies. Each state would have its own Bayes Net. But we are already starved for training data! –Ignore the dependencies. This causes “over-counting” of evidence (ala naïve Bayes). Big problem when combining evidence, as in Viterbi!
. Big problem when combining evidence, as in Viterbi!.")
28
Conditional Sequence Models We would prefer a conditional model: P(s|o) instead of P(s,o): –Can examine features, but not responsible for generating them. –Don’t have to explicitly model their dependencies. –Don’t “waste modeling effort” trying to generate what we are given at test time anyway. This answers the challenge of integrating the ability to handle many arbitrary features with the full power of finite state automata.

29
Locally Normalized Conditional Sequence Model S t-1 S t O t S t+1 O t +1 O t - 1... Generative (traditional HMM)... transitions observations S t-1 S t O t S t+1 O t +1 O t - 1... Conditional... transitions observations Standard belief propagation: forward-backward procedure. Viterbi and Baum-Welch follow naturally. Maximum Entropy Markov Models [McCallum, Freitag & Pereira, 2000] MaxEnt POS Tagger [Ratnaparkhi, 1996] SNoW-based Markov Model [Punyakanok & Roth, 2000]
... transitions observations S t-1 S t O t S t+1 O t +1 O t Conditional... transitions observations Standard belief propagation: forward-backward procedure. Viterbi and Baum-Welch follow naturally. Maximum Entropy Markov Models [McCallum, Freitag & Pereira, 2000] MaxEnt POS Tagger [Ratnaparkhi, 1996] SNoW-based Markov Model [Punyakanok & Roth, 2000].")
30
Locally Normalized Conditional Sequence Model S t-1 S t O t S t+1 O t +1 O t - 1... Generative (traditional HMM)... transitions observations S t-1 S t O t S t+1... Conditional... transitions entire observation sequence Standard belief propagation: forward-backward procedure. Viterbi and Baum-Welch follow naturally. Maximum Entropy Markov Models [McCallum, Freitag & Pereira, 2000] MaxEnt POS Tagger [Ratnaparkhi, 1996] SNoW-based Markov Model [Punyakanok & Roth, 2000] Or, more generally:...
... transitions observations S t-1 S t O t S t+1... Conditional... transitions entire observation sequence Standard belief propagation: forward-backward procedure. Viterbi and Baum-Welch follow naturally. Maximum Entropy Markov Models [McCallum, Freitag & Pereira, 2000] MaxEnt POS Tagger [Ratnaparkhi, 1996] SNoW-based Markov Model [Punyakanok & Roth, 2000] Or, more generally:....")
31
Exponential Form for “Next State” Function Overall Recipe: - Labeled data is assigned to transitions. - Train each state’s exponential model by maximum likelihood (iterative scaling or conjugate gradient). weightfeature Black-box classifier s t-1
. weightfeature Black-box classifier s t-1.")
32
Feature Functions Yesterday Lawrence Saul spoke this example sentence. s3s3 s1s1 s2s2 s4s4 o = o 1 o 2 o 3 o 4 o 5 o 6 o 7

33
Exponential Form for “Next State” Function Overall Recipe: - Labeled data is assigned to transitions. - Train each state’s exponential model by maximum likelihood (iterative scaling or conjugate gradient). weightfeature Black-box classifier s t-1
. weightfeature Black-box classifier s t-1.")
34
Experimental Data 38 files belonging to 7 UseNet FAQs Example: X-NNTP-Poster: NewsHound v1.33 Archive-name: acorn/faq/part2 Frequency: monthly 2.6) What configuration of serial cable should I use? Here follows a diagram of the necessary connection programs to work properly. They are as far as I know agreed upon by commercial comms software developers fo Pins 1, 4, and 8 must be connected together inside is to avoid the well known serial port chip bugs. The Procedure: For each FAQ, train on one file, test on other; average.

35
Features in Experiments begins-with-number begins-with-ordinal begins-with-punctuation begins-with-question-word begins-with-subject blank contains-alphanum contains-bracketed-number contains-http contains-non-space contains-number contains-pipe contains-question-mark contains-question-word ends-with-question-mark first-alpha-is-capitalized indented indented-1-to-4 indented-5-to-10 more-than-one-third-space only-punctuation prev-is-blank prev-begins-with-ordinal shorter-than-30

36
Models Tested ME-Stateless: A single maximum entropy classifier applied to each line independently. TokenHMM: A fully-connected HMM with four states, one for each of the line categories, each of which generates individual tokens (groups of alphanumeric characters and individual punctuation characters). FeatureHMM: Identical to TokenHMM, only the lines in a document are first converted to sequences of features. MEMM: The Maximum Entropy Markov Model described in this talk.
. FeatureHMM: Identical to TokenHMM, only the lines in a document are first converted to sequences of features. MEMM: The Maximum Entropy Markov Model described in this talk..")
37
Results

38
HMM MEMM CRF S t-1 StSt OtOt S t+1 O t+1 O t-1 S t-1 StSt OtOt S t+1 O t+1 O t-1 S t-1 StSt OtOt S t+1 O t+1 O t-1... (A special case of MEMMs and CRFs.) Conditional Random Fields (CRFs) [Lafferty, McCallum, Pereira ‘2001] From HMMs to MEMMs to CRFs
 Conditional Random Fields (CRFs) [Lafferty, McCallum, Pereira ‘2001] From HMMs to MEMMs to CRFs.")
39
Conditional Random Fields (CRFs) StSt S t+1 S t+2 O = O t, O t+1, O t+2, O t+3, O t+4 S t+3 S t+4 Markov on s, conditional dependency on o. Hammersley-Clifford-Besag theorem stipulates that the CRF has this form—an exponential function of the cliques in the graph. Assuming that the dependency structure of the states is tree-shaped (linear chain is a trivial tree), inference can be done by dynamic programming in time O(|o| |S|)—just like HMMs.
, inference can be done by dynamic programming in time O(|o| |S|)—just like HMMs..")
40
General CRFs vs. HMMs More general and expressive modeling technique Comparable computational efficiency Features may be arbitrary functions of any or all observations Parameters need not fully specify generation of observations; require less training data Easy to incorporate domain knowledge State means only “state of process”, vs “state of process” and “observational history I’m keeping”

41
Efficient Inference

42
Training CRFs Methods: iterative scaling (quite slow) conjugate gradient (much faster) conjugate gradient with preconditioning (super fast) limited-memory quasi-Newton methods (also super fast) Complexity comparable to standard Baum-Welch [Sha & Pereira 2002] & [Malouf 2002]
![Training CRFs Methods: iterative scaling (quite slow) conjugate gradient (much faster) conjugate gradient with preconditioning (super fast) limited-memory quasi-Newton methods (also super fast) Complexity comparable to standard Baum-Welch [Sha & Pereira 2002] & [Malouf 2002]](http://images.slideplayer.com/23/6867552/slides/slide_42.jpg "Training CRFs Methods: iterative scaling (quite slow) conjugate gradient (much faster) conjugate gradient with preconditioning (super fast) limited-memory quasi-Newton methods (also super fast) Complexity comparable to standard Baum-Welch [Sha & Pereira 2002] & [Malouf 2002]")
43
Voted Perceptron Sequence Models [Collins 2002] Like CRFs with stochastic gradient ascent and a Viterbi approximation. Avoids calculating the partition function (normalizer), Z o, but gradient ascent, not 2 nd -order or conjugate gradient method. Analogous to the gradient for this one training instance
![Voted Perceptron Sequence Models [Collins 2002] Like CRFs with stochastic gradient ascent and a Viterbi approximation.](http://images.slideplayer.com/23/6867552/slides/slide_43.jpg "Avoids calculating the partition function (normalizer), Z o, but gradient ascent, not 2 nd -order or conjugate gradient method. Analogous to the gradient for this one training instance.")
44
MEMM & CRF Related Work Maximum entropy for language tasks: –Language modeling [Rosenfeld ‘94, Chen & Rosenfeld ‘99] –Part-of-speech tagging [Ratnaparkhi ‘98] –Segmentation [Beeferman, Berger & Lafferty ‘99] –Named entity recognition “MENE” [Borthwick, Grishman,…’98] HMMs for similar language tasks –Part of speech tagging [Kupiec ‘92] –Named entity recognition [Bikel et al ‘99] –Other Information Extraction [Leek ‘97], [Freitag & McCallum ‘99] Serial Generative/Discriminative Approaches –Speech recognition [Schwartz & Austin ‘93] –Reranking Parses [Collins, ‘00] Other conditional Markov models –Non-probabilistic local decision models [Brill ‘95], [Roth ‘98] –Gradient-descent on state path [LeCun et al ‘98] –Markov Processes on Curves (MPCs) [Saul & Rahim ‘99] –Voted Perceptron-trained FSMs [Collins ’02]
![MEMM & CRF Related Work Maximum entropy for language tasks: –Language modeling [Rosenfeld ‘94, Chen & Rosenfeld ‘99] –Part-of-speech tagging [Ratnaparkhi ‘98] –Segmentation [Beeferman, Berger & Lafferty ‘99] –Named entity recognition MENE [Borthwick, Grishman,…’98] HMMs for similar language tasks –Part of speech tagging [Kupiec ‘92] –Named entity recognition [Bikel et al ‘99] –Other Information Extraction [Leek ‘97], [Freitag & McCallum ‘99] Serial Generative/Discriminative Approaches –Speech recognition [Schwartz & Austin ‘93] –Reranking Parses [Collins, ‘00] Other conditional Markov models –Non-probabilistic local decision models [Brill ‘95], [Roth ‘98] –Gradient-descent on state path [LeCun et al ‘98] –Markov Processes on Curves (MPCs) [Saul & Rahim ‘99] –Voted Perceptron-trained FSMs [Collins ’02]](http://images.slideplayer.com/23/6867552/slides/slide_44.jpg "MEMM & CRF Related Work Maximum entropy for language tasks: –Language modeling [Rosenfeld ‘94, Chen & Rosenfeld ‘99] –Part-of-speech tagging [Ratnaparkhi ‘98] –Segmentation [Beeferman, Berger & Lafferty ‘99] –Named entity recognition MENE [Borthwick, Grishman,…’98] HMMs for similar language tasks –Part of speech tagging [Kupiec ‘92] –Named entity recognition [Bikel et al ‘99] –Other Information Extraction [Leek ‘97], [Freitag & McCallum ‘99] Serial Generative/Discriminative Approaches –Speech recognition [Schwartz & Austin ‘93] –Reranking Parses [Collins, ‘00] Other conditional Markov models –Non-probabilistic local decision models [Brill ‘95], [Roth ‘98] –Gradient-descent on state path [LeCun et al ‘98] –Markov Processes on Curves (MPCs) [Saul & Rahim ‘99] –Voted Perceptron-trained FSMs [Collins ’02]")
45
Part-of-speech Tagging The asbestos fiber, crocidolite, is unusually resilient once it enters the lungs, with even brief exposures to it causing symptoms that show up decades later, researchers said. DT NN NN, NN, VBZ RB JJ IN PRP VBZ DT NNS, IN RB JJ NNS TO PRP VBG NNS WDT VBP RP NNS JJ, NNS VBD. 45 tags, 1M words training data, Penn Treebank Erroroov errorerror err oov error err HMM5.69%45.99% CRF5.55%48.05%4.27%-24%23.76%-50% Using spelling features* * use words, plus overlapping features: capitalized, begins with #, contains hyphen, ends in -ing, -ogy, -ed, -s, -ly, -ion, -tion, -ity, -ies. [Pereira 2001]

46
Chinese Word Segmentation [McCallum & Feng 2003] ~100k words data, Penn Chinese Treebank Lexicon features: Adjective ending characterdigit charactersprovinces adverb ending characterforeign name charspunctuation chars building wordsfunction wordsRoman alphabetics Chinese number charactersjob titleRoman digits Chinese periodlocationsstopwords cities and regionsmoneysurnames countriesnegative characterssymbol characters datesorganization indicatorverb chars department characterspreposition characterswordlist (188k lexicon)
![Chinese Word Segmentation [McCallum & Feng 2003] ~100k words data, Penn Chinese Treebank Lexicon features: Adjective ending characterdigit charactersprovinces adverb ending characterforeign name charspunctuation chars building wordsfunction wordsRoman alphabetics Chinese number charactersjob titleRoman digits Chinese periodlocationsstopwords cities and regionsmoneysurnames countriesnegative characterssymbol characters datesorganization indicatorverb chars department characterspreposition characterswordlist (188k lexicon)](http://images.slideplayer.com/23/6867552/slides/slide_46.jpg "Chinese Word Segmentation [McCallum & Feng 2003] ~100k words data, Penn Chinese Treebank Lexicon features: Adjective ending characterdigit charactersprovinces adverb ending characterforeign name charspunctuation chars building wordsfunction wordsRoman alphabetics Chinese number charactersjob titleRoman digits Chinese periodlocationsstopwords cities and regionsmoneysurnames countriesnegative characterssymbol characters datesorganization indicatorverb chars department characterspreposition characterswordlist (188k lexicon)")
47
Chinese Word Segmentation Results [McCallum & Feng 2003] Precision and recall of segments with perfect boundaries: # trainingtesting segmentation Methodsentencesprec.recallF1 [Peng]~5M75.174.074.2 [Ponte]?84.487.886.0 [Teahan]~40k??94.4 [Xue]~10k95.295.195.2 CRF280597.397.897.5 CRF14095.496.095.7 CRF5693.995.094.4 CRF+280599.699.799.6 Prev. world’s best error 50%
![Chinese Word Segmentation Results [McCallum & Feng 2003] Precision and recall of segments with perfect boundaries: # trainingtesting segmentation Methodsentencesprec.recallF1 [Peng]~5M [Ponte] [Teahan]~40k 94.4 [Xue]~10k CRF CRF CRF CRF Prev.](http://images.slideplayer.com/23/6867552/slides/slide_47.jpg "world’s best error 50%.")
48
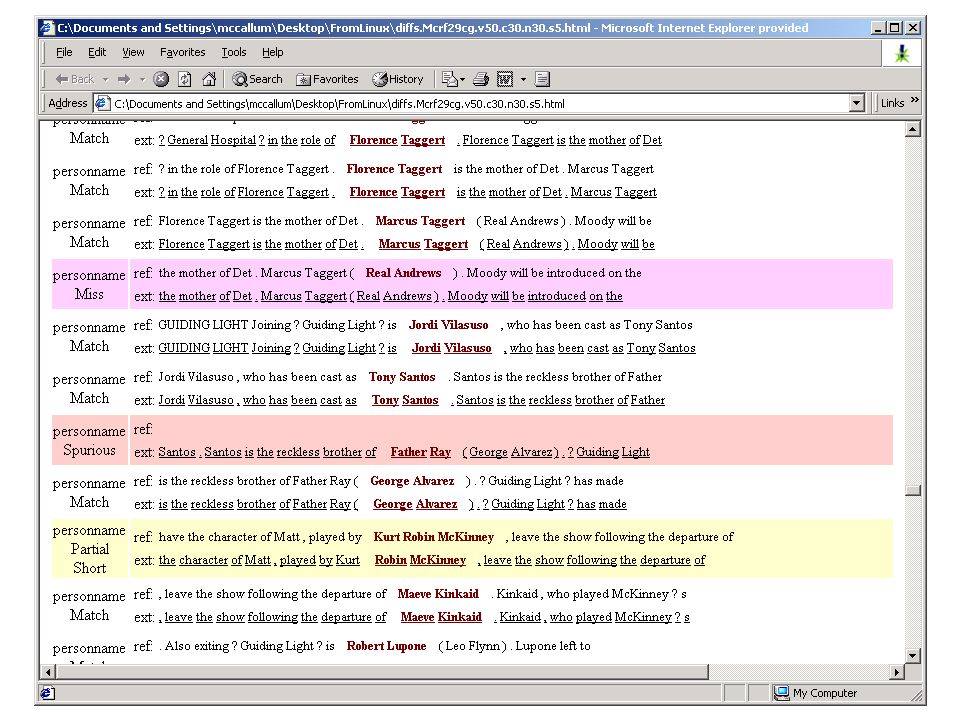
Person name Extraction [McCallum 2001]
![Person name Extraction [McCallum 2001]](http://images.slideplayer.com/23/6867552/slides/slide_48.jpg "Person name Extraction [McCallum 2001]")
49
Person name Extraction

50
Features in Experiment Capitalized Xxxxx Mixed Caps XxXxxx All Caps XXXXX Initial CapX…. Contains Digitxxx5 All lowercase xxxx InitialX Punctuation.,:;!(), etc Period. Comma, Apostrophe‘ Dash- Preceded by HTML tag Character n-gram classifier says string is a person name (80% accurate) In stopword list (the, of, their, etc) In honorific list (Mr, Mrs, Dr, Sen, etc) In person suffix list (Jr, Sr, PhD, etc) In name particle list (de, la, van, der, etc) In Census lastname list; segmented by P(name) In Census firstname list; segmented by P(name) In locations lists (states, cities, countries) In company name list (“J. C. Penny”) In list of company suffixes (Inc, & Associates, Foundation) Hand-built FSM person-name extractor says yes, (prec/recall ~ 30/95) Conjunctions of all previous feature pairs, evaluated at the current time step. Conjunctions of all previous feature pairs, evaluated at current step and one step ahead. All previous features, evaluated two steps ahead. All previous features, evaluated one step behind. Total number of features = ~200k
, etc Period. Comma, Apostrophe‘ Dash- Preceded by HTML tag Character n-gram classifier says string is a person name (80% accurate) In stopword list (the, of, their, etc) In honorific list (Mr, Mrs, Dr, Sen, etc) In person suffix list (Jr, Sr, PhD, etc) In name particle list (de, la, van, der, etc) In Census lastname list; segmented by P(name) In Census firstname list; segmented by P(name) In locations lists (states, cities, countries) In company name list ( J. C. Penny ) In list of company suffixes (Inc, & Associates, Foundation) Hand-built FSM person-name extractor says yes, (prec/recall ~ 30/95) Conjunctions of all previous feature pairs, evaluated at the current time step. Conjunctions of all previous feature pairs, evaluated at current step and one step ahead. All previous features, evaluated two steps ahead. All previous features, evaluated one step behind. Total number of features = ~200k.")
51
Training and Testing Trained on 65469 words from 85 pages, 30 different companies’ web sites. Training takes 4 hours on a 1 GHz Pentium. Training precision/recall is 96/96. Tested on different set of web pages with similar size characteristics. Testing precision is 0.92 - 0.95, recall is 0.89 - 0.91.

55
Feature Induction WORD=“interest” & WORD@+1=“rates” WORD=“put” & WORD@+1=“and” & WORD@+2=“call” (options) WORD=“to” & POS@+1=VB # features without conjunctions = ~90k # features with conjunctions = ~1 million
 WORD= to & # features without conjunctions = ~90k # features with conjunctions = ~1 million")
56
Feature Gain Current loss Loss if feature f were added and had optimal weight,

57
Feature Induction Procedure Partially train model with current features Find tokens significantly contributing to D(p||q). “Cluster” these errors by different cells of the confusion matrix. For each cell –Generate ~50k candidate new features –Measure the Gain of each –Add to the model the top N features ~

58
Feature Induction Discussion Decision trees partition the training data. Boosting is like feature induction –(Generate a new conjunction or tree & give it a weight) –but it typically adds just one feature for each round –and it doesn’t change the weight once set. [Della Piettra 2 & Lafferty 97] –also add one feature at a time, and would be quite inefficient for CRFs. Here we carefully select several approximations to their scheme.
 –but it typically adds just one feature for each round –and it doesn’t change the weight once set. [Della Piettra 2 & Lafferty 97] –also add one feature at a time, and would be quite inefficient for CRFs. Here we carefully select several approximations to their scheme..")
59
Feature Induction Results (Preliminary) Noun Phrase Segmentation Method# featuresF1 [Sha & Pereira 2003]3.8M94.4 Feature Induction140K94.4 Named Entity Extraction (in Spanish) MethodF1 With no conjunctions ~30 With fixed conjunctions51 With induced conjunctions65 (extra preliminary)
![Feature Induction Results (Preliminary) Noun Phrase Segmentation Method# featuresF1 [Sha & Pereira 2003]3.8M94.4 Feature Induction140K94.4 Named Entity Extraction (in Spanish) MethodF1 With no conjunctions ~30 With fixed conjunctions51 With induced conjunctions65 (extra preliminary)](http://images.slideplayer.com/23/6867552/slides/slide_59.jpg "Feature Induction Results (Preliminary) Noun Phrase Segmentation Method# featuresF1 [Sha & Pereira 2003]3.8M94.4 Feature Induction140K94.4 Named Entity Extraction (in Spanish) MethodF1 With no conjunctions ~30 With fixed conjunctions51 With induced conjunctions65 (extra preliminary)")
60
Person name Extraction

64
Local features, like formatting, exhibit regularity on a particular subset of the data (e.g. web site or document). Note that future data will probably not have the same regularities as the training data. Global features, like word content, exhibit regularity over an entire data set. Traditional classifiers are generally trained on these kinds of features. Local and Global Features w f
. Note that future data will probably not have the same regularities as the training data. Global features, like word content, exhibit regularity over an entire data set. Traditional classifiers are generally trained on these kinds of features. Local and Global Features w f.")
65
Scoped Learning Generative Model 1.For each of the D documents: a)Generate the multinomial formatting feature parameters from p( | ) 2.For each of the N words in the document: a)Generate the nth category c n from p(c n ). b)Generate the nth word (global feature) from p(w n |c n, ) c)Generate the nth formatting feature (local feature) from p(f n |c n, ) wf c N D
Generate the nth word (global feature) from p(w n |c n, ) c)Generate the nth formatting feature (local feature) from p(f n |c n, ) wf c N D .")
66
Inference Given a new web page, we would like to classify each word resulting in c = {c 1, c 2,…, c n } This is not feasible to compute because of the integral and sum in the denominator. We experimented with two approximations: - MAP point estimate of - Variational inference

67
MAP Point Estimate If we approximate with a point estimate, , then the integral disappears and c decouples. We can then label each word with: E-step: M-step: A natural point estimate is the posterior mode: a maximum likelihood estimate for the local parameters given the document in question: ^

68
Global Extractor: Correctly extracts 3 out of 9

69
Scoped Learning Extractor: Correctly extracts 8 out of 9

70
Coverage Accuracy Global Extractor: Precision = 46%, Recall = 75% Scoped Learning Extractor: Precision = 58%, Recall = 75% Error = -22%

71
Discriminative Model wf c N D When there are many non-independent formatting features, may prefer a non- generative model. Use a point estimate of . E-step computes p(c|w, f, ). M-step sets to maximize conditional likelihood, p(c|f)—uses MaxEnt.
. M-step sets to maximize conditional likelihood, p(c|f)—uses MaxEnt..")
72
More Experimental Results 42,548 web pages from 330 web sites. Each page labeled as PRESS_RELEASE, OTHER. Locale: web site Global features: words on page –E.g. “immediate” “release” “products” Local features: Character 4-gram window slid across URL. –E.g. “prel”, “/pr/”, “pres”…

73
Global Extractor: Precision = 54%, Recall = 90% Scoped Learning Extractor: Precision = 77%, Recall = 90% Error = -50%

74
Scoped Learning Related Work Co-training [Blum & Mitchell 1998] –Although it has no notion of scope, it also has an independence assumption about two independent views of data. PRMs for classification [Taskar, Segal & Koller 2001] –Extends notion of multiple views to multiple kinds of relationships –This model can be cast as a PRM where each locale is a separate group of nodes with separate parameters. Their inference corresponds our MAP estimate inference. Classification with Labeled & Unlabeled Data [Nigam et al, 1999, Joachims 1999, etc.] –Particularly transduction, in which the unlabeled set is the test set. –However, we model locales, represent a difference between local and global features, and can use locales at training time to learn hyper- parameters over local features. Classification with Hyperlink Structure [Slattery 2001] –Adjusts a web page classifier using ILP and a hubs & authorities algorithm.
![Scoped Learning Related Work Co-training [Blum & Mitchell 1998] –Although it has no notion of scope, it also has an independence assumption about two independent views of data.](http://images.slideplayer.com/23/6867552/slides/slide_74.jpg "PRMs for classification [Taskar, Segal & Koller 2001] –Extends notion of multiple views to multiple kinds of relationships –This model can be cast as a PRM where each locale is a separate group of nodes with separate parameters. Their inference corresponds our MAP estimate inference. Classification with Labeled & Unlabeled Data [Nigam et al, 1999, Joachims 1999, etc.] –Particularly transduction, in which the unlabeled set is the test set. –However, we model locales, represent a difference between local and global features, and can use locales at training time to learn hyper- parameters over local features. Classification with Hyperlink Structure [Slattery 2001] –Adjusts a web page classifier using ILP and a hubs & authorities algorithm..")
75
Future Directions Further work in feature selection and induction: automatically choose the f k functions (efficiently). Factorial CRFs Tree-structured Markov random fields for hierarchical parsing. Induction of finite state structure. Combine CRFs and Scoped Learning. Data mine the results of information extraction, and integrate the data mining with extraction. Create a text extraction and mining system that can be assembled and trained to a new vertical application by non-technical users. Papers on MEMMs, CRFs, Scoped Learning and more available at http://www.cs.umass.edu/~mccallum

Similar presentations













>")




 – presentations.>")







 Carnegie-Mellon University.>")
