Download presentation
Presentation is loading. Please wait.

1
DATA MINING from data to information Ronald Westra Dep. Mathematics Knowledge Engineering Maastricht University

2
PART 2 Exploratory Data Analysis

3
VISUALISING AND EXPLORING DATA-SPACE Data Mining Lecture II [Chapter 3 from Principles of Data Mining by Hand,, Manilla, Smyth ]
![VISUALISING AND EXPLORING DATA-SPACE Data Mining Lecture II [Chapter 3 from Principles of Data Mining by Hand,, Manilla, Smyth ]](http://images.slideplayer.com/23/6859658/slides/slide_3.jpg "VISUALISING AND EXPLORING DATA-SPACE Data Mining Lecture II [Chapter 3 from Principles of Data Mining by Hand,, Manilla, Smyth ]")
4
LECTURE 3: Visualising and Exploring Data-Space Readings: Chapter 3 from Principles of Data Mining by Hand, Mannila, Smyth. 3.1 Obtain insight in the Structure in Data Space 1.distribution over the space 2.Are there separate and disconnected parts? 3.is there a model? 4.data-driven hypothesis testing 5.Starting point: use strong perceptual powers of humans

5
LECTURE 3: Visualising and Exploring Data-Space 3.2 Tools to represent a variabele 1.mean, variance, standard deviation, skewness 2.plot 3.moving-average plot 4.histogram, kernel

6
histogram

7
Box Plots

8
Overprinting

9
Contour plot

10
LECTURE 3: Visualising and Exploring Data-Space 3.3 Tools for repressenting two variables 1.scatter plot 2.moving-average plots

11
scatter plot

12
scatter plots

14
LECTURE 3: Visualising and Exploring Data-Space 3.4 Tools for representing multiple variables 1.all or selection of scatter plots 2.idem moving-average plots 3.‘trelis’ or other parameterised plots 4.icons: star icons, Chernoff’s faces

15
Chernoff’s faces

18
Star Plots

19
Parallel coordinates

20
3.5 PCA: Principal Component Ananlysis 3.6 MDS: Multidimensional Scaling DIMENSION REDUCTION

21
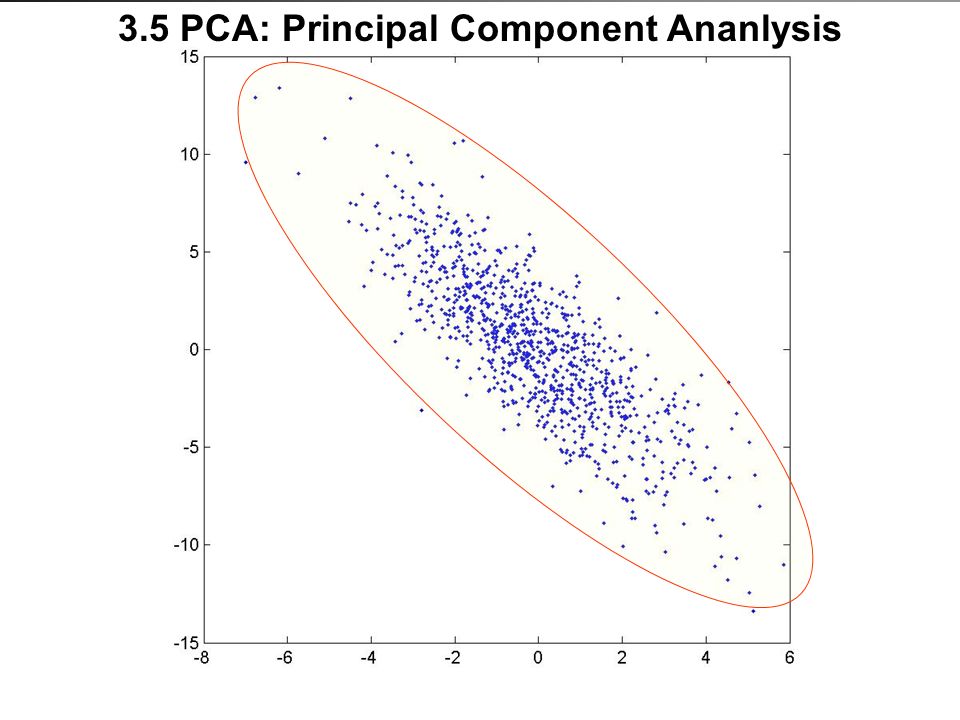
3.5 PCA: Principal Component Ananlysis With sub-scatter plots we already noticed that the best projections were determined by the projection that resulted in the maximal size of the set of data points. This is in the direction of the maximum variance. This idea is worked out in the approach of the Principal Components Analysis.

22
3.5 PCA: Principal Component Ananlysis Principal component analysis (PCA) is a vector space transform often used to reduce multidimensional data sets to lower dimensions for analysis. Depending on the field of application, it is also named the discrete Karhunen-Loève transform (KLT), the Hotelling transform or proper orthogonal decomposition (POD). PCA now is the mostly used as a tool in exploratory data analysis and for making predictive models. PCA involves the calculation of the eigenvalue decomposition of a data covariance matrix after mean centering the data for each attribute. The results of a PCA are usually discussed in terms of component scores and contribution.
, the Hotelling transform or proper orthogonal decomposition (POD). PCA now is the mostly used as a tool in exploratory data analysis and for making predictive models. PCA involves the calculation of the eigenvalue decomposition of a data covariance matrix after mean centering the data for each attribute. The results of a PCA are usually discussed in terms of component scores and contribution..")
23
3.5 PCA: Principal Component Ananlysis PCA is the simplest of the true eigenvector-based multivariate analyses. Often, its operation can be thought of as revealing the internal structure of the data in a way which best explains the variance in the data. If a multivariate dataset is visualised as a set of coordinates in a high-dimensional data space (1 axis per variable), PCA supplies the user with a lower-dimensional picture, a "shadow" of this object when viewed from its (in some sense) most informative viewpoint.
, PCA supplies the user with a lower-dimensional picture, a shadow of this object when viewed from its (in some sense) most informative viewpoint..")
24
3.5 PCA: Principal Component Ananlysis PCA is closely related to factor analysis.

25
3.5 PCA: Principal Component Ananlysis Consider a multivariate set in Data Space: this is a set with normal distributions in multiple dimensions, for instance: Observe that the spatial extent appears different in each dimension. Also observe that in this case the set is almost 1- dimensional. Can we project the set so that the spatial extent in one dimension is optimal?

26
3.5 PCA: Principal Component Ananlysis Data X: n rows of p fields: the vectors are rows in X. STEP 1: Subtract the average value from the dataset X: mean centered data. The spatial extent of this cloud of points can be measured by the variance in the dataset X. This is an entry in the correlation matrix V = X T X. The projection of the dataset X in a direction a is: y = Xa. a The spatial extent in direction a is the variance in the projected dataset Y: i.e. the variance σ a 2 = y T y = (Xa) T (Xa) = a T X T Xa = a T V a. We now want to maximize this extent σ a 2 over all possible vectors a (why?).
 T (Xa) = a T X T Xa = a T V a. We now want to maximize this extent σ a 2 over all possible vectors a (why )..")
27
3.5 PCA: Principal Component Ananlysis STEP 2: Maximize: σ a 2 = a T V a over all possible vectors a. This is unlimited, just like maximizing x 2 over x, therefore we restrict the size of vector a to 1: a T V a – 1 = 0 So we have: maximize: a T V a subject to: a T V a – 1 = 0 This can be solved with the Lagrange-multipliers method: maximize: f(x) subject to: g(x) = 0 → d/dx{ f(x) – λ g(x)} = 0 For our case this means: d/da{ a T V a – λ (a T V a – 1 )} = 0 → 2 Va – 2λa = 0 → Va = λa This means that we are looking for the eigen-vectors and eigen-values of the correlation matrix V = X T X.
 subject to: g(x) = 0 → d/dx{ f(x) – λ g(x)} = 0 For our case this means: d/da{ a T V a – λ (a T V a – 1 )} = 0 → 2 Va – 2λa = 0 → Va = λa This means that we are looking for the eigen-vectors and eigen-values of the correlation matrix V = X T X..")
28
3.5 PCA: Principal Component Analysis So, the underlying idea is: supose you have a high-dimensional normal- distributed data set. This will take the shape of a high-dimensional ellipsoid. An ellipsoid is structured from its centre by orthogonal vectors with different radii. The largest radii have the strongest influence on the shape of the ellipsoid. The ellipsoid is described by the covariance-matrix of the set of data- points. The axes are defined by the orthogonal eigen-vectors (from the centre – the centroid – of the set), the radii are defined by the associated values. So determine the eigen-values and order those in decreasing size:. The first n ordered eigen-vectors thus ‘explain’ the following amount of the data:.
, the radii are defined by the associated values. So determine the eigen-values and order those in decreasing size:. The first n ordered eigen-vectors thus ‘explain’ the following amount of the data:..")
29
3.5 PCA: Principal Component Ananlysis

31
MEAN

32
3.5 PCA: Principal Component Ananlysis MEAN Principal axis 2 Principal axis 1

33
3.5 PCA: Principal Component Ananlysis STEP 2: Plot the ordered eigen-values versus the index-number and inspect where a ‘shoulder’ occurs: this determines the number of eigen-values you take into acoount. This is a so-called ‘scree-plot’.

34
3.5 PCA: Principal Component Ananlysis For n points of p components there are: O(np 2 + p 3 ) operations required. Use LU-decomposition etcetera.

35
3.5 PCA: Principal Component Ananlysis Many benefits: considerable data-reduction, necessary for computational techniques like ‘Fisher-discriminant-analysis’ and ‘clustering’. This works very well in practice.

36
3.5 PCA: Principal Component Analysis PCA is closely related to and often confused with Factor Analysis: Factor Analysis is the explanation of p-dimensional data by a smaller number of m < p factors.

37
EXAMPLE of PCA

38
Dressler, et al. 1987 astronomical application: PCs for elliptical galaxies Rotating to PC in B T – Σ space improves Faber-Jackson relation as a distance indicator

39
astronomical application: Eigenspectra (KL transform) Connolly, et al. 1995
 Connolly, et al. 1995")
43
1 pc 2 pc 3 pc 4 pc

44
3.6 Multi-Dimensional Scaling [MDS] 1.Same purpose : represent high-dimensional data set 2.In the case of MS not by projections, but by reconstruction from the distance-table. The computed points are represented in an Euclidian sub-space – preferably a 2D-plane. 3.MDS performs better than PCA in case of strongly curved sets.
![3.6 Multi-Dimensional Scaling [MDS] 1.Same purpose : represent high-dimensional data set 2.In the case of MS not by projections, but by reconstruction from the distance-table.](http://images.slideplayer.com/23/6859658/slides/slide_44.jpg "The computed points are represented in an Euclidian sub-space – preferably a 2D-plane. 3.MDS performs better than PCA in case of strongly curved sets..")
45
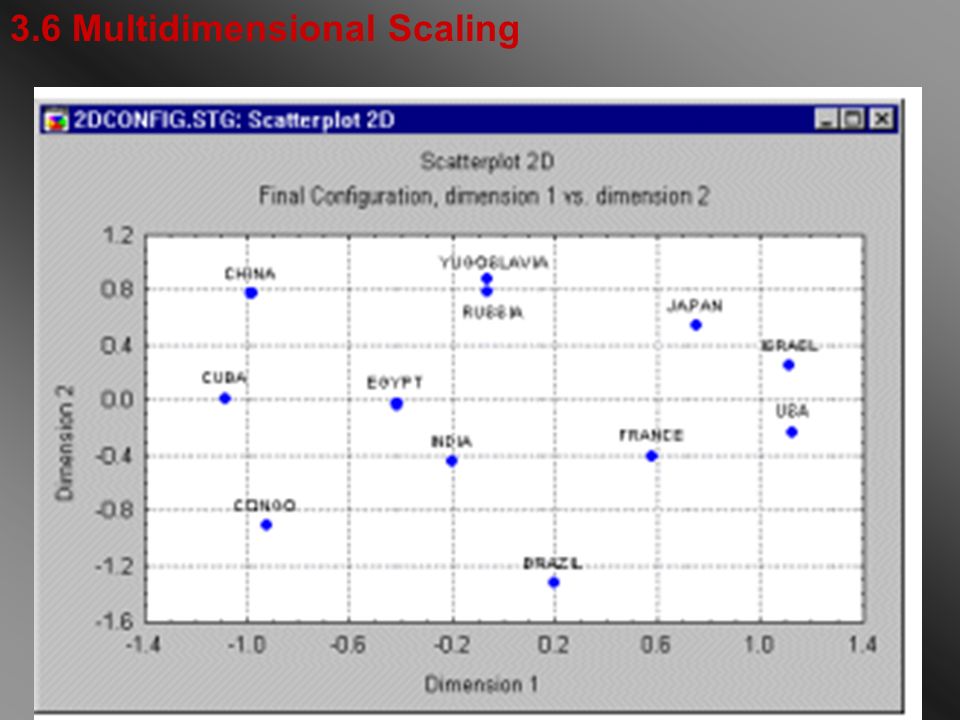
3.6 Multidimensional Scaling The purpose of multidimensional scaling (MDS) is to provide a visual representation of the pattern of proximities (i.e., similarities or distances) among a set of objects INPUT: distances dist[A i,A j ] where A is some class of objects OUTPUT: positions X[A i ] where X is a D-dimensional vector
![3.6 Multidimensional Scaling The purpose of multidimensional scaling (MDS) is to provide a visual representation of the pattern of proximities (i.e., similarities or distances) among a set of objects INPUT: distances dist[A i,A j ] where A is some class of objects OUTPUT: positions X[A i ] where X is a D-dimensional vector](http://images.slideplayer.com/23/6859658/slides/slide_45.jpg "3.6 Multidimensional Scaling The purpose of multidimensional scaling (MDS) is to provide a visual representation of the pattern of proximities (i.e., similarities or distances) among a set of objects INPUT: distances dist[A i,A j ] where A is some class of objects OUTPUT: positions X[A i ] where X is a D-dimensional vector")
46
3.6 Multidimensional Scaling

48
INPUT: distances dist[A i,A j ] where A is some class of objects
![INPUT: distances dist[A i,A j ] where A is some class of objects](http://images.slideplayer.com/23/6859658/slides/slide_48.jpg "INPUT: distances dist[A i,A j ] where A is some class of objects")
49
3.6 Multidimensional Scaling OUTPUT: positions X[A i ] where X is a D-dimensional vector
![3.6 Multidimensional Scaling OUTPUT: positions X[A i ] where X is a D-dimensional vector](http://images.slideplayer.com/23/6859658/slides/slide_49.jpg "3.6 Multidimensional Scaling OUTPUT: positions X[A i ] where X is a D-dimensional vector")
50
3.6 Multidimensional Scaling How many dimensions ??? SCREE PLOT

51
Multidimensional Scaling: Nederlandse dialekten

54
3.6 Kohonen’s Self Organizing Map (SOM) and Sammon mapping 1.Same purpose : DIMENSION REDUCTION : represent a high dimensional set in a smaller sub-space e.g. 2D-plane. 2.SOM gives better results than Sammon mapping, but strongly sensitive to initial values. 3.This is close to clustering!

55
3.6 Kohonen’s Self Organizing Map (SOM)
")
57
Sammon mapping

58
All information on math-part of course on: http://www.math.unimaas.nl/personal/ronaldw/ DAM/DataMiningPage.htm

Similar presentations


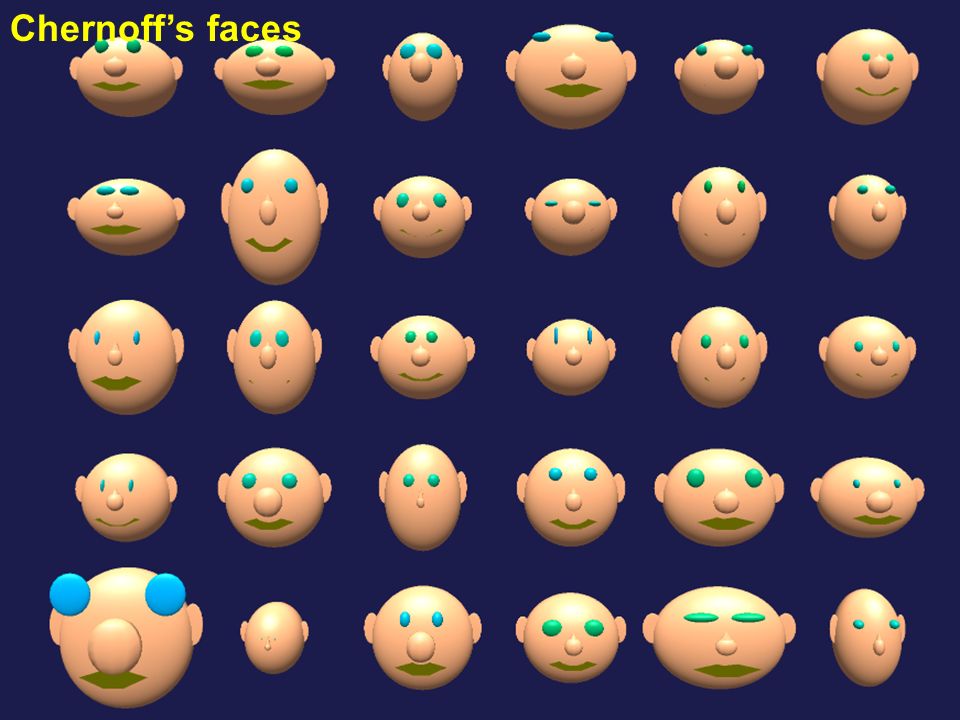









>")

 is a technique that is useful for the compression and classification.>")

 Distribution of values for single variables.>")


>")









 and Hotelling (1933) to describe the variation in a set of multivariate data.>")