Download presentation
Presentation is loading. Please wait.

1
Clustered Principal Components for Precomputed Radiance Transfer Peter-Pike Sloan Microsoft Corporation Jesse Hall, John Hart UIUC John Snyder Microsoft Research

2
Demo

3
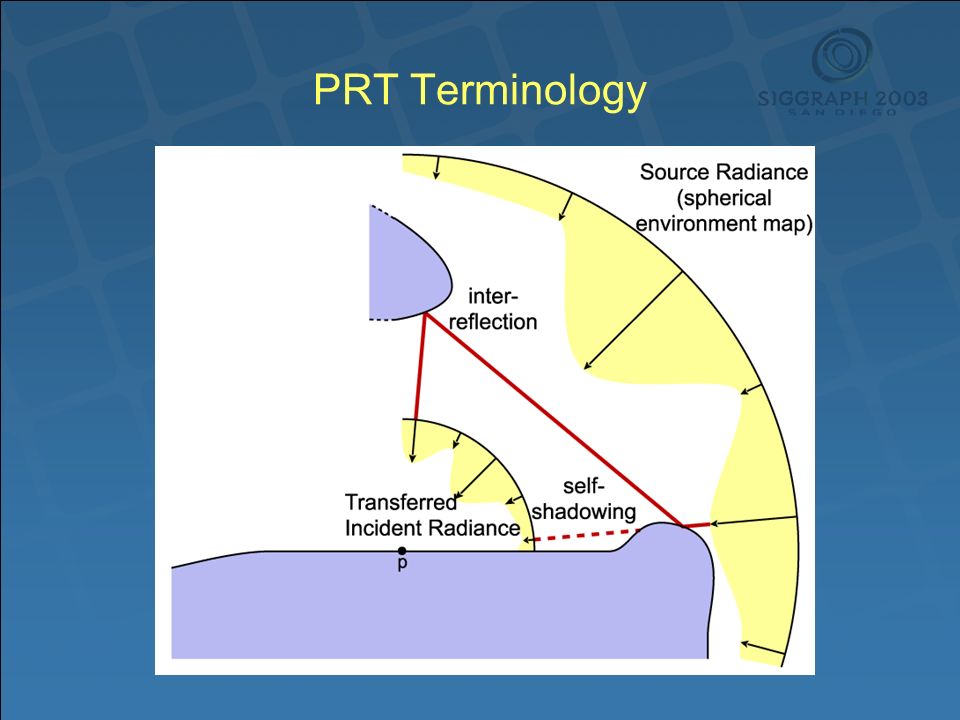
PRT Terminology

7
PRT as a Linear Operator l : light vector (in source basis) M p : source-to-exit transfer matrix e p : exit radiance vector (in exit basis) y(v p ) : exit basis evaluated in direction v p e p (v p ) : exit radiance in direction v p
 M p : source-to-exit transfer matrix e p : exit radiance vector (in exit basis) y(v p ) : exit basis evaluated in direction v p e p (v p ) : exit radiance in direction v p")
8
PRT Special Case: Diffuse Objects transfer vector rather than matrix independent of view (constant exit basis) matrix is row vector previous work uses different light bases image relighting [PRT02]SH [Xi03]Directional [Ng03]Haar [Ashikhmin02]Steerable
![PRT Special Case: Diffuse Objects transfer vector rather than matrix independent of view (constant exit basis) matrix is row vector previous work uses different light bases image relighting [PRT02]SH [Xi03]Directional [Ng03]Haar [Ashikhmin02]Steerable](http://images.slideplayer.com/2/685464/slides/slide_8.jpg "PRT Special Case: Diffuse Objects transfer vector rather than matrix independent of view (constant exit basis) matrix is row vector previous work uses different light bases image relighting [PRT02]SH [Xi03]Directional [Ng03]Haar [Ashikhmin02]Steerable")
9
PRT Special Case: Surface Light Fields transfer vector rather than matrix frozen lighting environment matrix is column vector [Miller98] [Nishino99] [Wood00] [Chen02] [Matusik02]
![PRT Special Case: Surface Light Fields transfer vector rather than matrix frozen lighting environment matrix is column vector [Miller98] [Nishino99] [Wood00] [Chen02] [Matusik02]](http://images.slideplayer.com/2/685464/slides/slide_9.jpg "PRT Special Case: Surface Light Fields transfer vector rather than matrix frozen lighting environment matrix is column vector [Miller98] [Nishino99] [Wood00] [Chen02] [Matusik02]")
10
Factoring PRT (BRDFs) T p : source transferred incident radiance R p : rotate to local frame B : integrate against BRDF [Westin92] y ( v p ) e p : evaluate exit radiance at v p
![Factoring PRT (BRDFs) T p : source transferred incident radiance R p : rotate to local frame B : integrate against BRDF [Westin92] y ( v p ) e p : evaluate exit radiance at v p](http://images.slideplayer.com/2/685464/slides/slide_10.jpg "Factoring PRT (BRDFs) T p : source transferred incident radiance R p : rotate to local frame B : integrate against BRDF [Westin92] y ( v p ) e p : evaluate exit radiance at v p")
11
Hemispherical Projection exit radiance is defined over hemisphere, not sphere spherical harmonics not orthogonal over hemisphere how to project hemispherical functions using SH? –naïve projection assumes underside is zero –least squares projection minimizes approximation error see appendix

12
Factoring PRT (BRDFs) TechniqueLightBExitBNote [Sloan02] SH Phong [Kautz02] SHDirArb [Lehtinen03] SHDirLsq [Matusik02] Dir IBR
![Factoring PRT (BRDFs) TechniqueLightBExitBNote [Sloan02] SH Phong [Kautz02] SHDirArb [Lehtinen03] SHDirLsq [Matusik02] Dir IBR](http://images.slideplayer.com/2/685464/slides/slide_12.jpg "Factoring PRT (BRDFs) TechniqueLightBExitBNote [Sloan02] SH Phong [Kautz02] SHDirArb [Lehtinen03] SHDirLsq [Matusik02] Dir IBR")
13
Extending PRT to BSSRDFs already handled by original equation use [Jensen02], only multiple scattering (matrix with only 1 row) mix with conventional BRDF
![Extending PRT to BSSRDFs already handled by original equation use [Jensen02], only multiple scattering (matrix with only 1 row) mix with conventional BRDF](http://images.slideplayer.com/2/685464/slides/slide_13.jpg "Extending PRT to BSSRDFs already handled by original equation use [Jensen02], only multiple scattering (matrix with only 1 row) mix with conventional BRDF")
14
Problems With PRT Big matrices at each surface point –25-vectors for diffuse, x3 for spectral –25x25-matrices for glossy –at ~50,000 vertices Slows glossy rendering (4hz) –Frozen View/Light can increase performance –Not as GPU friendly Limits diffuse lighting order –Only very soft shadows
 –Frozen View/Light can increase performance –Not as GPU friendly Limits diffuse lighting order –Only very soft shadows")
15
Compression Goals Decode efficiently –As much on the GPU as possible –Render compressed representation directly Increase rendering performance –Make non-diffuse case practical Reduce memory consumption –Not just on disk

16
Compression Example Surface is curve, signal is normal

17
Compression Example Signal Space

18
VQ Cluster normals

19
VQ Replace samples with cluster mean

20
PCA Replace samples with mean + linear combination

21
CPCA Compute a linear subspace in each cluster

22
CPCA Clusters with low dimensional affine models How should clustering be done? Static PCA –VQ, followed by one-time per-cluster PCA –optimizes for piecewise-constant reconstruction Iterative PCA –PCA in the inner loop, slower to compute –optimizes for piecewise-affine reconstruction

23
Static vs. Iterative

24
Related Work VQ+PCA [Kambhatla94] (static) VQPCA [Khambhatla97] (iterative) Mixture PC [Dony95] (iterative) More sophisticated models exist –[Brand03], [Roweis02] –Mapping to current GPUs is challenging Variable storage per vertex Partitioning is more difficult (or requires more passes)
![Related Work VQ+PCA [Kambhatla94] (static) VQPCA [Khambhatla97] (iterative) Mixture PC [Dony95] (iterative) More sophisticated models exist –[Brand03], [Roweis02] –Mapping to current GPUs is challenging Variable storage per vertex Partitioning is more difficult (or requires more passes)](http://images.slideplayer.com/2/685464/slides/slide_24.jpg "Related Work VQ+PCA [Kambhatla94] (static) VQPCA [Khambhatla97] (iterative) Mixture PC [Dony95] (iterative) More sophisticated models exist –[Brand03], [Roweis02] –Mapping to current GPUs is challenging Variable storage per vertex Partitioning is more difficult (or requires more passes)")
25
Equal Rendering Cost VQPCACPCA

26
Rendering with CPCA

27
Constant per cluster – precompute on the CPU Rendering is a dot product Compute linear combination of vectors Only depends on # rows of M

28
Non-Local Viewer Assume: v p constant across object (distant viewer) Rendering independent of view & light orders - linear combination of colors
 Rendering independent of view & light orders - linear combination of colors")
29
Rendering = + +

30
Overdraw 1 1 1 3 3 2 2 2 2 2 2 2 2 2 2 2 2 2 faces belong to 1-3 clusters OD = 1 face drawn once OD = 2 face drawn 2x OD = 3 face drawn 3x coherence optimization: reclassification superclustering

31
Pixel Shader TextureConstants GPU Dataflow Vertices Vertex Shader Exit Rad.

32
Demo

33
Results Model#PtsSPCAIPCAFPS Buddha49.9k3m30s1h51m27 BuddhaSS49.9k6m12s4h32m27 Bird Anis48.7k6m34s3h43m45 Bird Diff48.7k43s3m26s227 Head50k4m20s2h12m58.5 All examples have 25x25 matrices, 256 clusters, 8 PCA vectors

34
Conclusions CPCA works in signal space, not surface space uses affine subspace per-cluster compresses PRT well is used directly without blowing out signal requires small, uniform state storage provides –faster rendering –higher-frequency lighting

35
Future Work time-dependent and parameterized geometry higher-frequency lighting combination with bi-scale rendering better signal continuity

36
Questions? DirectX SDK for PRT available soon. Jason Mitchell, Hugues Hoppe, Jason Sandlin, David Kirk Stanford, MPI for models

Similar presentations




















>")
