Download presentation
Presentation is loading. Please wait.

1
Canonical Correlation

2
What is Canonical Correlation? Canonical correlation seeks the weighted linear composite for each variate (sets of D.V.s or I.V.s) to maximize the overlap in their distributions. Labeling of D.V. and I.V. is arbitrary. The procedure looks for relationships and not causation. Goal is to maximize the correlation (not the variance extracted as in most other techniques). Canonical correlation is the “mother” m.v. model Lacks specificity in interpreting results that may limit its usefulness in many situations
 to maximize the overlap in their distributions. Labeling of D.V. and I.V. is arbitrary. The procedure looks for relationships and not causation. Goal is to maximize the correlation (not the variance extracted as in most other techniques). Canonical correlation is the mother m.v. model Lacks specificity in interpreting results that may limit its usefulness in many situations.")
3
X1X2X3X4...XqX1X2X3X4...Xq Y1Y2Y3Y4...YpY1Y2Y3Y4...Yp What is the best way to understand how the variables in these two sets are related?

4
Bivariate correlations across sets Multiple correlations across sets Principal components within sets; correlations between principal components across sets

5
X1X2X3X4...XqX1X2X3X4...Xq Y1Y2Y3Y4...YpY1Y2Y3Y4...Yp What linear combinations of the X variables (u) and the Y variables (t) will maximize their correlation?
 and the Y variables (t) will maximize their correlation")
6
b1X1+b2X2+b3X3+b4X4+.+bpXp=ub1X1+b2X2+b3X3+b4X4+.+bpXp=u a 1 Y 1 + a 2 Y 2 + a 3 Y 3 + a 4 Y 4 +. + a q Y q = t What linear combinations of the X variables (u) and the Y variables (t) will maximize their correlation?
 and the Y variables (t) will maximize their correlation .")
7
b1X1+b2X2+b3X3+b4X4+.+bpXpb1X1+b2X2+b3X3+b4X4+.+bpXp a1Y1+a2Y2+a3Y3+a4Y4+.+aqYqa1Y1+a2Y2+a3Y3+a4Y4+.+aqYq Max(R c ) Where Rc represents the overlapping variance between two variates which are linear composites of each set of variables
 Where Rc represents the overlapping variance between two variates which are linear composites of each set of variables")
8
Assumptions Multiple continuous variables for D.V.s and I.V.s or categorical with dummy coding Assumes linear relationship between any two variables and between variates. Multivariate normality is necessary to perform statistical tests. Sensitive to homoscedasticity decreases correlation between variables Multicollinearity in either variate confounds interpretation of canonical results

9
When use Canonical Correlation? Descriptive technique which can define structure in both the D.V. and I.V. variates simultaneously Series of measures are used for both D.V. and I.V. Canonical correlation also has ability to define structure in each variate, which are derived to maximize their correlation

10
Objectives of Canonical Correlation Determine the magnitude of the relationships that may exist between two sets of variables Derive a variate(s) for each set of criterion and predictor variables such that the variate(s) of each set is maximally correlated. Explain the nature of whatever relationships exist between the sets of criterion and predictor variables Seek the max correlation of shared variance between the two sides of the equation

11
Canonical correlation: Correlation between two sets; the largest possible correlation that can be found between linear combinations. Canonical variate: The linear combinations created from the IV set and DV set. Extraction of canonical variates can continue up to a maximum defined by the number of measures in the smaller of the two sets. Information: Canonical Functions

12
Information: Canonical Variates Canonical weights: weights used to create the linear combinations; interpreted like regression coefficients Canonical loadings: correlations between each variable and its variate; interpreted like loadings in PCA Canonical cross-loadings: Correlation of each observed independent or dependent variable with opposite canonical variate

13
Interpreting Canonical Variates Canonical Weights –Larger weight contributes more to the function –Negative weight indicates an inverse relationship with other variables –Be careful of multicollinearity –Assess stability of samples

14
Interpreting Canonical Variates Canonical Loadings – direct assessment of each variable’s contribution to its respective canonical variate –Larger loadings = more important to deriving the canonical variate –Correlation between the original variable and its canonical variate –Assess stability of loadings across samples

15
Interpreting Canonical Variates Canonical Cross-Loadings –Measure of correlation of each original D.V. with the independent canonical variate. –Direct assessment of the relationship between each D.V. and the independent variate. –Provides a more pure measure of the dependent and independent variable relationship –Preferred approach to interpretation

16
X1X2X3X4...XqX1X2X3X4...Xq Y1Y2Y3Y4...YpY1Y2Y3Y4...Yp Canonical Cross-Loadings Represents the correlation between Y1 and the X variate

17
X1X2X3X4...XqX1X2X3X4...Xq Y1Y2Y3Y4...YpY1Y2Y3Y4...Yp Canonical Loadings and Weights Loading X1: correlation between X1 and X variate (its own variate) r Weight X1: unique partial contribution of X1 to X variate (its own variate)
 r Weight X1: unique partial contribution of X1 to X variate (its own variate)")
18
Deriving Canonical Functions & Assessing Overall Fit Max # of variate functions = # of variables in the smallest set - I.V. or D.V. Variates extracted in steps. Factor which accounts for max residual variance is selected –First pair of canonical variates has the highest intercorrelation possible –Successive pairs of variates are orthogonal and independent of all variates –Canonical correlation squared represents the amount of variance in one canonical variate that is accounted for by the other canonical variate

19
Interpretation: Selection of Functions Level of statistical significance of the function – usually F statistic based on Rao’s approximation, p <.05 Magnitude of the canonical relationship –size of canonical correlations; practical significance –R c 2 variance shared by variates, not variance extracted from predictor & criterion variables Redundancy index – summary of the ability of a set of predictor variables to account for variation in criterion variables

20
Redundancy Index Redundancy = [Mean of (loadings) 2 ] x R c 2 Provides the shared variance that can be explained by the canonical function Redundancy provided for both IV and DV variates, but DV variate of more interest Both loadings and R c 2 must be high to get high redundancy
![Redundancy Index Redundancy = [Mean of (loadings) 2 ] x R c 2 Provides the shared variance that can be explained by the canonical function Redundancy provided for both IV and DV variates, but DV variate of more interest Both loadings and R c 2 must be high to get high redundancy](http://images.slideplayer.com/23/6825412/slides/slide_20.jpg "Redundancy Index Redundancy = [Mean of (loadings) 2 ] x R c 2 Provides the shared variance that can be explained by the canonical function Redundancy provided for both IV and DV variates, but DV variate of more interest Both loadings and R c 2 must be high to get high redundancy")
21
Considerations: Canonical R Small sample sizes may have an adverse affect –Suggested minimum sample size = 10 * # of variables Selection of variables to be included: –Conceptual or Theoretical basis –Inclusion of irrelevant or deletion of relevant variables may adversely affect the entire canonical solution –All I.V.s must be interrelated and all D.V.s must be interrelated –Composition of D.V. and I.V. variates is critical to producing practical results

22
Limitations Rc reflects only the variance shared by the linear composites, not the variances extracted from the variables Canonical weights are subject to a great deal of instability Interpretation difficult because rotation is not possible Precise statistics have not been developed to interpret canonical analysis

23
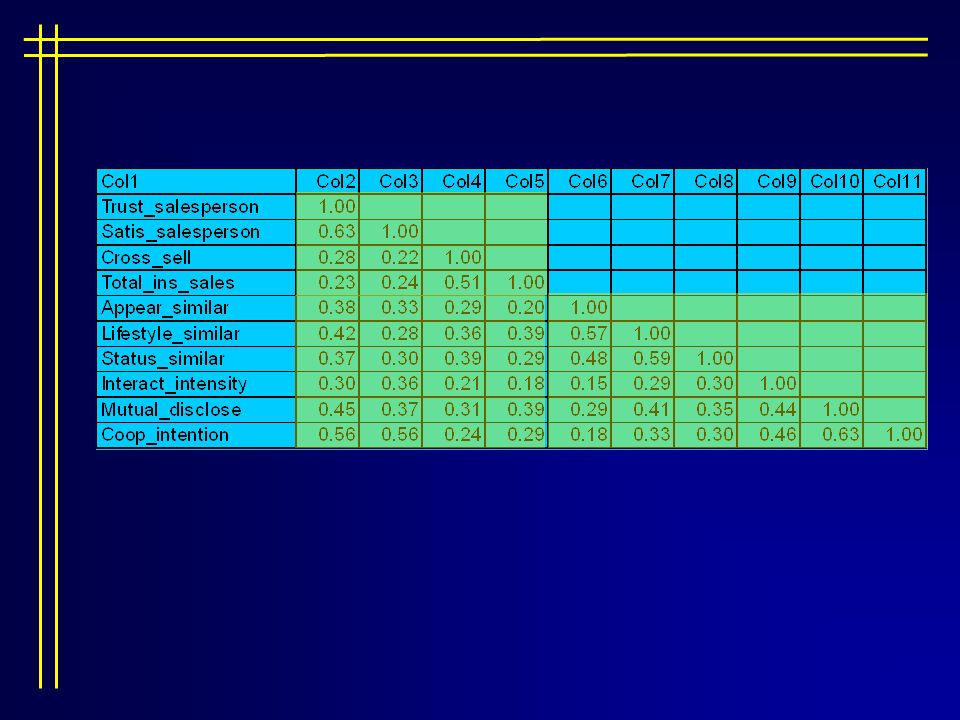
Crosby, Evans, and Cowles (1990) examined the impact of relationship quality on the outcome of insurance sales. They examined relationship characteristics and outcomes for 151 transactions. Relationship Characteristics: Appearance similarity Lifestyle similarity Status similarity Interaction intensity Mutual disclosure Cooperative intentions

24
Crosby, Evans, and Cowles (1990) examined the impact of relationship quality on the outcome of insurance sales. They examined relationship characteristics and outcomes for 151 transactions. Outcomes: Trust in the salesperson Satisfaction with the salesperson Cross-sell Total insurance sales

26
Matrix data Variables = rowtype_ trust satis cross total appear life status interact mutual coop. Begin data N 151 151 151 151 151 151 151 151 151 151 Mean 0 0 0 0 0 0 0 0 0 0 STDDEV 1 1 1 1 1 1 1 1 1 1 Corr 1.00 corr.63 1.00 corr.28.22 1.00 corr.23.24.51 1.00 corr.38.33.29.20 1.00 corr.42.28.36.39.57 1.00 corr.37.30.39.29.48.59 1.00 corr.30.36.21.18.15.29.30 1.00 corr.45.37.31.39.29.41.35.44 1.00 corr.56.56.24.29.18.33.30.46.63 1.00 end data.

27
Variable labels trust ' Trust in the salesperson' Satis 'Satisfaction with the salesperson' cross 'Cross-sell' total 'Total insurance sales' appear 'Appearance similarity' life 'Lifestyle similarity' status 'Status similarity' interact 'Interaction intensity' mutual 'Mutual disclosure' coop 'Cooperative intentions'. MANOVA trust satis cross total with appear life status interact mutual coop /matrix=IN(*) /print signif(multiv dimenr eigen stepdown univ hypoth) error(cor) /discrim raw stan cor alpha(1).
 /print signif(multiv dimenr eigen stepdown univ hypoth) error(cor) /discrim raw stan cor alpha(1)..")
28
Multivariate Tests of Significance (S = 4, M = 1/2, N = 69 1/2) Test Name Value Approx. F Hypoth. DF Error DF Sig. of F Pillais.73301 5.38481 24.00 576.00.000 Hotellings 1.35153 7.85574 24.00 558.00.000 Wilks.37940 6.57954 24.00 493.10.000 Roys.52771 There is at least one significant relationship between the two sets of measures. With 6 and 4 measures in the two sets, there are a maximum of 4 possible sets of linear combinations that can be formed.

29
Eigenvalues and Canonical Correlations Root No. Eigenvalue Pct. Cum. Pct. Canon Cor. Sq. Cor 1 1.117 82.672 82.672.726.528 2.176 13.050 95.722.387.150 3.050 3.706 99.428.218.048 4.008.572 100.000.088.008 RcRc Rc2Rc2

30
Dimension Reduction Analysis Roots Wilks L. F Hypoth. DF Error DF Sig. of F 1 TO 4.37940 6.57954 24.00 493.10.000 2 TO 4.80331 2.15996 15.00 392.40.007 3 TO 4.94500 1.02566 8.00 286.00.417 4 TO 4.99233.37087 3.00 144.00.774 Two of the four possible sets of linear combinations are significant.

31
Standardized canonical coefficients for DEPENDENT variables Function No. Variable 1 2 3 4 TRUST -.543.317 -.390 1.082 SATIS -.364 -.936.103 -.816 CROSS -.186.148 1.160.057 TOTAL -.239.721 -.672 -.597 Outcomes: Trust in the salesperson Satisfaction with the salesperson Cross-sell Total insurance sales

32
Correlations between DEPENDENT and canonical variables Function No. Variable 1 2 3 4 TRUST -.879 -.065 -.155.447 SATIS -.804 -.530 -.048 -.265 CROSS -.540.399.731 -.124 TOTAL -.546.645 -.145 -.515 Outcomes: Trust in the salesperson Satisfaction with the salesperson Cross-sell Total insurance sales

33
Standardized canonical coefficients for COVARIATES CAN. VAR. COVARIATE 1 2 3 4 APPEAR -.268 -.561.342.552 LIFE -.164.833 -.467.138 STATUS -.156.128.906 -.007 INTERACT -.049 -.379.361 -.853 MUTUAL -.128.749 -.209 -.441 COOP -.603 -.773 -.566.408 Relationship Characteristics: Appearance similarity Lifestyle similarity Status similarity Interaction intensity Mutual disclosure Cooperative intentions

34
Correlations between COVARIATES and canonical variables CAN. VAR. Covariate 1 2 3 4 APPEAR -.589 -.003.402.445 LIFE -.674.531.095.155 STATUS -.622.267.660.052 INTERACT -.517 -.209.196 -.739 MUTUAL -.729.319 -.182 -.345 COOP -.855 -.263 -.353 -.120 Relationship Characteristics: Appearance similarity Lifestyle similarity Status similarity Interaction intensity Mutual disclosure Cooperative intentions

35
Remaining issues: How much variance is really accounted for? How easily does the procedure capitalize on chance?

36
How much variance is really accounted for? Reliance on the canonical correlations for evidence of variance accounted for across sets of variables can be misleading. Each linear combination only captures a portion of the variance in its own set. That needs to be taken into account when judging the variance accounted for across sets.

37
The squared canonical correlation indicates the shared variance between linear combinations from the two sets.

38
Each linear combination accounts for only a portion of the variance in the variables in its set.

39
Redundancy Index Redundancy = [Mean of (loadings) 2 ] x R c 2 Provides the shared variance that can be explained by the canonical function Redundancy provided for both IV and DV variates, but DV variate of more interest Both loadings and R c 2 must be high to get high redundancy Proportion of variance in the variables of the opposite set that is accounted for by the linear combination.
![Redundancy Index Redundancy = [Mean of (loadings) 2 ] x R c 2 Provides the shared variance that can be explained by the canonical function Redundancy provided for both IV and DV variates, but DV variate of more interest Both loadings and R c 2 must be high to get high redundancy Proportion of variance in the variables of the opposite set that is accounted for by the linear combination.](http://images.slideplayer.com/23/6825412/slides/slide_39.jpg "Redundancy Index Redundancy = [Mean of (loadings) 2 ] x R c 2 Provides the shared variance that can be explained by the canonical function Redundancy provided for both IV and DV variates, but DV variate of more interest Both loadings and R c 2 must be high to get high redundancy Proportion of variance in the variables of the opposite set that is accounted for by the linear combination.")
40
Fader and Lodish (1990) collected data for 331 different grocery products. They sought relations between what they called structural variables and promotional variables. The structural variables were characteristics not likely to be changed by short-term promotional activities. The promotional variables represented promotional activities. The major goal was to determine if different promotional activities were associated with different types of grocery products.

41
Structural variables (X): PENETPercentage of households making at least one category purchase PCYCLEAverage interpurchase time PRICEAverage dollars spent in the category per purchase occasion PVTSHCombined market share for all private-label and generic products PURHHAverage number of purchase occasions per household during the year
: PENETPercentage of households making at least one category purchase PCYCLEAverage interpurchase time PRICEAverage dollars spent in the category per purchase occasion PVTSHCombined market share for all private-label and generic products PURHHAverage number of purchase occasions per household during the year")
42
Promotional variables (Y): FEATPercent of volume sold on feature (advertised in local newspaper) DISPPercent of volume sold on display (e.g., end of aisle) PCUTPercent of volume sold at a temporary reduced price SCOUPPercent of volume purchased using a retailer’s store coupon MCOUPPercent of volume purchased using a manufacturer’s coupon
: FEATPercent of volume sold on feature (advertised in local newspaper) DISPPercent of volume sold on display (e.g., end of aisle) PCUTPercent of volume sold at a temporary reduced price SCOUPPercent of volume purchased using a retailer’s store coupon MCOUPPercent of volume purchased using a manufacturer’s coupon")
43
MANOVA penet purhh pcycle price pvtsh with feat disp pcut scoup mcoup /print signif(multiv dimenr eigen stepdown univ hypoth) error(cor) /discrim raw stan cor alpha(1). Canonical correlation analysis must be obtained using syntax statements in SPSS: SPSS syntax

44
PENET PURHHPCYCLEPRICEPVTSHFEATDISPPCUTSCOUPMCOUP BEER 62.311.1465.16.419322711 WINE 42.95.8594.581.01426801 FRESH BREAD98.626.6211.3039.41241512 CUPCAKES 27.42.5601.113.54101014 Structural variables (X): PENETPercentage of households making at least one category purchase PCYCLEAverage interpurchase time PRICEAverage dollars spent in the category per purchase occasion PVTSHCombined market share for all private-label and generic products PURHHAverage number of purchase occasions per household during the year Promotional variables (Y): FEATPercent of volume sold on feature (advertised in local newspaper) DISPPercent of volume sold on display (e.g., end of aisle) PCUTPercent of volume sold at a temporary reduced price SCOUPPercent of volume purchased using a retailer’s store coupon MCOUPPercent of volume purchased using a manufacturer’s coupon
: PENETPercentage of households making at least one category purchase PCYCLEAverage interpurchase time PRICEAverage dollars spent in the category per purchase occasion PVTSHCombined market share for all private-label and generic products PURHHAverage number of purchase occasions per household during the year Promotional variables (Y): FEATPercent of volume sold on feature (advertised in local newspaper) DISPPercent of volume sold on display (e.g., end of aisle) PCUTPercent of volume sold at a temporary reduced price SCOUPPercent of volume purchased using a retailer’s store coupon MCOUPPercent of volume purchased using a manufacturer’s coupon")
45
Raw canonical coefficients for COVARIATES Function No. COVARIATE 1 2 3 4 5 FEAT.083 -.151 -.058 -.232.215 DISP.044.011.108.091.074 PCUT.021.199.037.079 -.247 SCOUP -.015 -.385 -.788 1.124 -.268 MCOUP.022 -.079.043 -.003 -.057 The same coefficients exist for the other set of variables.

46
Test Name Value Approx. F Hypoth. DF Error DF Sig. of F Pillais.73057 11.12256 25.00 1625.00.000 Hotellings 1.09732 14.01931 25.00 1597.00.000 Wilks.41262 12.85124 25.00 1193.96.000 Roys.41271 These tests indicate whether there is any significant relationship between the two sets of variables. They do not indicate how many of those sets of linear combinations are significant. With 5 variables in each set, there are up to 5 sets of linear combinations that could be derived. This test tells us that at least the first one is significant.

47
Eigenvalues and Canonical Correlations Root No. Eigenvalue Pct. Cum. Pct. Canon Cor. Sq. Cor 1.703 64.040 64.040.642.413 2.305 27.790 91.830.483.234 3.075 6.877 98.708.265.070 4.013 1.198 99.906.114.013 5.001.094 100.000.032.001 The canonical correlations are extracted in decreasing size. At each step they represent the largest correlation possible between linear combinations in the two sets, provided the linear combinations are independent of any previously derived linear combinations.

48
Dimension Reduction Analysis Roots Wilks L. F Hypoth. DF Error DF Sig. of F 1 TO 5.41262 12.85124 25.00 1193.96.000 2 TO 5.70257 7.53593 16.00 984.36.000 3 TO 5.91682 3.17374 9.00 786.25.001 4 TO 5.98600 1.14582 4.00 648.00.334 5 TO 5.99897.33534 1.00 325.00.563 Procedures for testing the significance of the canonical correlations can be applied sequentially. At each step, the test indicates whether there is any remaining significant relationships between the two sets. In this case, three sets of linear combinations can be formed.

49
As in principal components, identifying the number of significant sets of linear combinations is just the beginning. The nature of those linear combinations must also be determined. This requires interpreting the canonical weights and loadings.

50
Raw canonical coefficients for DEPENDENT variables Function No. Variable 1 2 3 4 5 PENET.036 -.018.016.016.011 PURHH -.073 -.013 -.175.072 -.329 PCYCLE -.012 -.031 -.019.049 -.020 PRICE.198 -.838 -.417 -.299.305 PVTSH.000.024 -.061.002.039 The linear combinations can be formed using the variables in their original metrics. Sometimes this makes it easier to understand the role a particular variable plays because the metric is well understood.

51
Standardized canonical coefficients for DEPENDENT variables Function No. Variable 1 2 3 4 5 PENET 1.066 -.527.484.483.326 PURHH -.307 -.055 -.737.304 -1.382 PCYCLE -.262 -.695 -.417 1.104 -.455 PRICE.208 -.883 -.439 -.315.321 PVTSH.000.359 -.898.024.576 The standardized canonical coefficients are the weights applied to standardized variables to create the new linear combinations. Structural variables (X): PENETPercentage of households making at least one category purchase PCYCLEAverage interpurchase time PRICEAverage dollars spent in the category per purchase occasion PVTSHCombined market share for all private-label and generic products PURHHAverage number of purchase occasions per household during the year
: PENETPercentage of households making at least one category purchase PCYCLEAverage interpurchase time PRICEAverage dollars spent in the category per purchase occasion PVTSHCombined market share for all private-label and generic products PURHHAverage number of purchase occasions per household during the year.")
52
Correlations between DEPENDENT and canonical variables Function No. Variable 1 2 3 4 5 PENET.956.114 -.042.223 -.145 PURHH.555.148 -.389 -.207 -.690 PCYCLE -.582 -.320.060.697.263 PRICE -.011 -.769 -.285 -.569.059 PVTSH.336.465 -.705.245.337 The loadings provide information about the bivariate relationship between each variable and each linear combination. Structural variables (X): PENETPercentage of households making at least one category purchase PCYCLEAverage interpurchase time PRICEAverage dollars spent in the category per purchase occasion PVTSHCombined market share for all private-label and generic products PURHHAverage number of purchase occasions per household during the year
: PENETPercentage of households making at least one category purchase PCYCLEAverage interpurchase time PRICEAverage dollars spent in the category per purchase occasion PVTSHCombined market share for all private-label and generic products PURHHAverage number of purchase occasions per household during the year.")
53
Standardized canonical coefficients for COVARIATES CAN. VAR. COVARIATE 1 2 3 4 5 FEAT.637 -1.160 -.448 -1.780 1.649 DISP.318.077.770.653.532 PCUT.164 1.530.281.611 -1.898 SCOUP -.014 -.362 -.740 1.056 -.252 MCOUP.202 -.728.400 -.029 -.523 Promotional variables (Y): FEATPercent of volume sold on feature(advertised in local newspaper) DISPPercent of volume sold on display (e.g., end of aisle) PCUTPercent of volume sold at a temporary reduced price SCOUPPercent of volume purchased using a retailer’s store coupon MCOUPPercent of volume purchased using a manufacturer’s coupon
: FEATPercent of volume sold on feature(advertised in local newspaper) DISPPercent of volume sold on display (e.g., end of aisle) PCUTPercent of volume sold at a temporary reduced price SCOUPPercent of volume purchased using a retailer’s store coupon MCOUPPercent of volume purchased using a manufacturer’s coupon.")
54
Correlations between COVARIATES and canonical variables CAN. VAR. Covariate 1 2 3 4 5 FEAT.939.073 -.293 -.157.046 DISP.730.136.384.412.362 PCUT.896.321 -.184 -.063 -.238 SCOUP.617 -.167 -.614.462 -.024 MCOUP.156 -.717.427 -.069 -.523 Promotional variables (Y): FEATPercent of volume sold on feature(advertised in local newspaper) DISPPercent of volume sold on display (e.g., end of aisle) PCUTPercent of volume sold at a temporary reduced price SCOUPPercent of volume purchased using a retailer’s store coupon MCOUPPercent of volume purchased using a manufacturer’s coupon
: FEATPercent of volume sold on feature(advertised in local newspaper) DISPPercent of volume sold on display (e.g., end of aisle) PCUTPercent of volume sold at a temporary reduced price SCOUPPercent of volume purchased using a retailer’s store coupon MCOUPPercent of volume purchased using a manufacturer’s coupon.")
55
Variance in dependent variables explained by canonical variables CAN. VAR. Pct Var DE Cum Pct DE Pct Var CO Cum Pct CO 1 33.462 33.462 13.810 13.810 2 18.895 52.357 4.415 18.226 3 14.708 67.065 1.032 19.258 4 19.263 86.328.250 19.508 5 13.672 100.000.014 19.522 Variance in covariates explained by canonical variables CAN. VAR. Pct Var DE Cum Pct DE Pct Var CO Cum Pct CO 1 21.654 21.654 52.467 52.467 2 3.127 24.781 13.382 65.849 3 1.159 25.940 16.521 82.371 4.108 26.048 8.337 90.708 5.010 26.058 9.292 100.000 Average Squared Loading Correlations between DEPENDENT and canonical variables Function No. Variable 1 PENET.956 PURHH.555 PCYCLE -.582 PRICE -.011 PVTSH.336 ( L 2 i,1 )/i Average squared loadings (33.462) times the squared canonical correlation (.413) = Redundancy
/i Average squared loadings (33.462) times the squared canonical correlation (.413) = Redundancy.")
56
Interpretation: Average squared loading The canonical variate extracts XX% of the variance in variable a, b, and c –Example: The canonical variate extracts 33.46% of the variance in percent of households making at least one purchase, average interpurchase time, average $ spent on category, and average # of purchase occasions/household yearly

57
Interpretation: Redundancy Redundancy is 13.81% Indicates that the promotional variate extracts 13.81% of the variance in structural variables (purchase decisions)
")
58
Variance in dependent variables explained by canonical variables CAN. VAR. Pct Var DE Cum Pct DE Pct Var CO Cum Pct CO 1 33.462 33.462 13.810 13.810 2 18.895 52.357 4.415 18.226 3 14.708 67.065 1.032 19.258 4 19.263 86.328.250 19.508 5 13.672 100.000.014 19.522 Variance in covariates explained by canonical variables CAN. VAR. Pct Var DE Cum Pct DE Pct Var CO Cum Pct CO 1 21.654 21.654 52.467 52.467 2 3.127 24.781 13.382 65.849 3 1.159 25.940 16.521 82.371 4.108 26.048 8.337 90.708 5.010 26.058 9.292 100.000 Average squared loading Redundancy

59
Interpretation: Average squared loading The canonical variate extracts XX% of the variance in variable a, b, and c –Example: The canonical variate extracts 52.47% of the variance in percent of volume sold on feature, percent of volume sold on display, percent of volume sold at a temp reduced price, percent of volume and purchase with retail coupon.

60
Interpretation: Redundancy Redundancy is 21.54% Indicates that the structural (purchase decision) variate extracts 13.81% of the variance in promotional variables
 variate extracts 13.81% of the variance in promotional variables")
61
Any given loading can be squared to indicate the proportion of the variance in that variable that is accounted for by that canonical variate. The sum of the squared loadings for a given variable indicates the total proportion of variance accounted for by the collection of canonical variates. The average of the squared loadings for a canonical variate is the adequacy coefficient and indicates the proportion of variance in the collection of variables that is accounted for by the canonical variate. The redundancy coefficient is the proportion of variance in a set of variables that is accounted for by a linear combination from the other set. The sum of the redundancy coefficients gives the total proportion of variance in one set that is accounted for by the other set. These will usually be different values for each set.

Similar presentations