Download presentation
Presentation is loading. Please wait.

1
Structured Prediction and Active Learning for Information Retrieval
Presented at Microsoft Research Asia August 21st, 2008 Yisong Yue Cornell University Joint work with: Thorsten Joachims (advisor), Filip Radlinski, Thomas Finley, Robert Kleinberg, Josef Broder
, Filip Radlinski, Thomas Finley, Robert Kleinberg, Josef Broder.")
2
Outline Structured Prediction Active Learning Complex Retrieval Goals
Structural SVMs (Supervised Learning) Active Learning Learning From Real Users Multi-armed Bandit Problems
 Active Learning. Learning From Real Users. Multi-armed Bandit Problems.")
3
Supervised Learning Find function from input space X to output space Y
such that the prediction error is low. Microsoft announced today that they acquired Apple for the amount equal to the gross national product of Switzerland. Microsoft officials stated that they first wanted to buy Switzerland, but eventually were turned off by the mountains and the snowy winters… x y 1 GATACAACCTATCCCCGTATATATATTCTATGGGTATAGTATTAAATCAATACAACCTATCCCCGTATATATATTCTATGGGTATAGTATTAAATCAATACAACCTATCCCCGTATATATATTCTATGGGTATAGTATTAAATCAGATACAACCTATCCCCGTATATATATTCTATGGGTATAGTATTAAATCACATTTA x y -1 x y 7.3

4
Examples of Complex Output Spaces
Natural Language Parsing Given a sequence of words x, predict the parse tree y. Dependencies from structural constraints, since y has to be a tree. S VP NP Det N V y The dog chased the cat x 4

5
Examples of Complex Output Spaces
Part-of-Speech Tagging Given a sequence of words x, predict sequence of tags y. Dependencies from tag-tag transitions in Markov model. Similarly for other sequence labeling problems, e.g., RNA Intron/Exon Tagging. The rain wet the cat x Det N V y 5

6
Examples of Complex Output Spaces
Multi-class Labeling Sequence Alignment Grammar Trees & POS Tagging Markov Random Fields Clustering Information Retrieval (Rankings) Average Precision & NDCG Listwise Approaches Diversity More Complex Goals
 Average Precision & NDCG. Listwise Approaches. Diversity. More Complex Goals.")
7
Information Retrieval
Input: x (feature representation of a document/query pair) Conventional Approach Real valued retrieval functions f(x) Sort by f(xi) to obtain ranking Training Method Human-labeled data (documents labeled by relevance) Learn f(x) using relatively simple criterion Computationally convenient Works pretty well (but we can do better)
 Conventional Approach. Real valued retrieval functions f(x) Sort by f(xi) to obtain ranking. Training Method. Human-labeled data (documents labeled by relevance) Learn f(x) using relatively simple criterion. Computationally convenient. Works pretty well (but we can do better)")
8
Conventional SVMs Input: x (high dimensional point)
Target: y (either +1 or -1) Prediction: sign(wTx) Training: subject to: The sum of slacks upper bounds the accuracy loss
 Prediction: sign(wTx) Training: subject to: The sum of slacks upper bounds the accuracy loss.")
9
Pairwise Preferences SVM
Such that: References: R. Herbrich, T. Graepel, K. Obermayer. “Support Vector Learning for Ordinal Regression.” In Proceedings of ICANN 1999. T. Joachims, “A Support Vector Method for Multivariate Performance Measures.” In Proceedings of ICML ( Large Margin Ordinal Regression [Herbrich et al., 1999] Can be reduced to time [Joachims, 2005] Pairs can be reweighted to more closely model IR goals [Cao et al., 2006]

10
Mean Average Precision
Consider rank position of each relevance doc K1, K2, … KR Compute for each K1, K2, … KR Average precision = average of Ex: has AvgPrec of MAP is Average Precision across multiple queries/rankings

11
Optimization Challenges
Rank-based measures are multivariate Cannot decompose (additively) into document pairs Need to exploit other structure Defined over rankings Rankings do not vary smoothly Discontinuous w.r.t model parameters Need some kind of relaxation/approximation
 into document pairs. Need to exploit other structure. Defined over rankings. Rankings do not vary smoothly. Discontinuous w.r.t model parameters. Need some kind of relaxation/approximation.")
12
[Y & Burges; 2007] References:
Y. Yue, C. Burges. “On Using Simultaneous Perturbation Stochastic Approximation on Learning to Rank; and, the Empirical Optimality of LambdaRank.” Microsoft Research Technical Report, MSR-TR , 2007. [Y & Burges; 2007]
![[Y & Burges; 2007] References:](http://slideplayer.com/slide/678329/1/images/12/%5BY+%26+Burges%3B+2007%5D+References%3A.jpg "Y. Yue, C. Burges. On Using Simultaneous Perturbation Stochastic Approximation on Learning to Rank; and, the Empirical Optimality of LambdaRank. Microsoft Research Technical Report, MSR-TR , [Y & Burges; 2007]")
13
Optimization Approach
Approximations / Smoothing Directly define gradient LambdaRank [Burges et al., 2006] Gaussian smoothing SoftRank GP [Guiver & Snelson, 2008] Upper bound relaxations Exponential Loss w/ Boosting AdaRank [Xu et al., 2007] Hinge Loss w/ Structural SVMs [Chapelle et al., 2007] SVM-map [Yue et al., 2007]

14
Structured Prediction
Let x be a structured input (candidate documents) Let y be a structured output (ranking) Use a joint feature map to encode the compatibility of predicting y for given x. Captures all the structure of the prediction problem Consider linear models: after learning w, we can make predictions via
 Let y be a structured output (ranking) Use a joint feature map to encode. the compatibility of predicting y for given x. Captures all the structure of the prediction problem. Consider linear models: after learning w, we can make predictions via.")
15
Linear Discriminant for Ranking
Let x = (x1,…xn) denote candidate documents (features) Let yjk = {+1, -1} encode pairwise rank orders Feature map is linear combination of documents. Prediction made by sorting on document scores wTxi
 denote candidate documents (features) Let yjk = {+1, -1} encode pairwise rank orders. Feature map is linear combination of documents. Prediction made by sorting on document scores wTxi.")
16
Linear Discriminant for Ranking
Using pairwise preferences is common in IR So far, just reformulated using structured prediction notation. But we won’t decompose into independent pairs Treat the entire ranking as a structured object Allows for optimizing average precision

17
Structural SVM Standard objective function:
Let x denote a structured input (candidate documents) Let y denote a structured output (ranking) Standard objective function: Constraints are defined for each incorrect labeling y’ over the set of documents x. References: Y. Yue, T. Finley, F. Radlinski, T. Joachims. “A Support Vector Method for Optimizing Average Precision.” In Proceedings of SIGIR ( [Y, Finley, Radlinski, Joachims; SIGIR 2007]
 Let y denote a structured output (ranking) Standard objective function: Constraints are defined for each incorrect labeling y’ over the set of documents x. References: Y. Yue, T. Finley, F. Radlinski, T. Joachims. A Support Vector Method for Optimizing Average Precision. In Proceedings of SIGIR ( [Y, Finley, Radlinski, Joachims; SIGIR 2007]")
18
Structural SVM for MAP Minimize subject to where ( yjk = {-1, +1} )
and Sum of slacks is smooth upper bound on MAP loss. References: Y. Yue, T. Finley, F. Radlinski, T. Joachims. “A Support Vector Method for Optimizing Average Precision.” In Proceedings of SIGIR ( [Y, Finley, Radlinski, Joachims; SIGIR 2007]

19
Too Many Constraints! For Average Precision, the true labeling is a ranking where the relevant documents are all ranked in the front, e.g., An incorrect labeling would be any other ranking, e.g., This ranking has Average Precision of about 0.8 with (y’) ¼ 0.2 Intractable number of rankings, thus an intractable number of constraints!
 ¼ 0.2. Intractable number of rankings, thus an intractable number of constraints!")
20
Structural SVM Training
Original SVM Problem Intractable number of constraints Most are dominated by a small set of “important” constraints Structural SVM Approach Repeatedly finds the next most violated constraint… …until set of constraints is a good approximation. [Tsochantaridis et al., 2005]

21
Structural SVM Training
Original SVM Problem Intractable number of constraints Most are dominated by a small set of “important” constraints Structural SVM Approach Repeatedly finds the next most violated constraint… …until set of constraints is a good approximation. [Tsochantaridis et al., 2005]

22
Structural SVM Training
Original SVM Problem Intractable number of constraints Most are dominated by a small set of “important” constraints Structural SVM Approach Repeatedly finds the next most violated constraint… …until set of constraints is a good approximation. [Tsochantaridis et al., 2005]

23
Structural SVM Training
Original SVM Problem Intractable number of constraints Most are dominated by a small set of “important” constraints Structural SVM Approach Repeatedly finds the next most violated constraint… …until set of constraints is a good approximation. [Tsochantaridis et al., 2005]

24
Finding Most Violated Constraint
A constraint is violated when Finding most violated constraint reduces to Highly related to inference/prediction:

25
Finding Most Violated Constraint
Observations MAP is invariant on the order of documents within a relevance class Swapping two relevant or non-relevant documents does not change MAP. Joint SVM score is optimized by sorting by document score, wTxj Reduces to finding an interleaving between two sorted lists of documents

26
Finding Most Violated Constraint
Start with perfect ranking Consider swapping adjacent relevant/non-relevant documents ►

27
Finding Most Violated Constraint
Start with perfect ranking Consider swapping adjacent relevant/non-relevant documents Find the best feasible ranking of the non-relevant document ►

28
Finding Most Violated Constraint
Start with perfect ranking Consider swapping adjacent relevant/non-relevant documents Find the best feasible ranking of the non-relevant document Repeat for next non-relevant document ►

29
Finding Most Violated Constraint
Start with perfect ranking Consider swapping adjacent relevant/non-relevant documents Find the best feasible ranking of the non-relevant document Repeat for next non-relevant document Never want to swap past previous non-relevant document ►

30
Finding Most Violated Constraint
Start with perfect ranking Consider swapping adjacent relevant/non-relevant documents Find the best feasible ranking of the non-relevant document Repeat for next non-relevant document Never want to swap past previous non-relevant document Repeat until all non-relevant documents have been considered ►

32
Structural SVM for MAP Treats rankings as structured objects
Optimizes hinge-loss relaxation of MAP Provably minimizes the empirical risk Performance improvement over conventional SVMs Relies on subroutine to find most violated constraint Computationally compatible with linear discriminant

33
Need for Diversity (in IR)
Ambiguous Queries Users with different information needs issuing the same textual query “Jaguar” At least one relevant result for each information need Learning Queries User interested in “a specific detail or entire breadth of knowledge available” [Swaminathan et al., 2008] Results with high information diversity References: A Swaminathan, C. Mathew and D. Kirovski. “Essential Pages.” MSR Technical Report, 2008.

34
Query: “Jaguar” Top of First Page Bottom of First Page Result #18
Results From 11/27/2007

35
Learning to Rank Current methods Benefits: Drawbacks:
Real valued retrieval functions f(q,d) Sort by f(q,di) to obtain ranking Benefits: Know how to perform learning Can optimize for rank-based performance measures Outperforms traditional IR models Drawbacks: Cannot account for diversity During prediction, considers each document independently
 Sort by f(q,di) to obtain ranking. Benefits: Know how to perform learning. Can optimize for rank-based performance measures. Outperforms traditional IR models. Drawbacks: Cannot account for diversity. During prediction, considers each document independently.")
36
Example Choose K documents with maximal information coverage.
For K = 3, optimal set is {D1, D2, D10}

37
Diversity via Set Cover
Documents cover information Assume information is partitioned into discrete units. Documents overlap in the information covered. Selecting K documents with maximal coverage is a set cover problem NP-complete in general Greedy has (1-1/e) approximation [Khuller et al., 1997]
 approximation [Khuller et al., 1997]")
38
Diversity via Subtopics
Current datasets use manually determined subtopic labels E.g., “Use of robots in the world today” Nanorobots Space mission robots Underwater robots Manual partitioning of the total information Relatively reliable Use as training data

39
Weighted Word Coverage
Use words to represent units of information More distinct words = more information Weight word importance Does not depend on human labeling Goal: select K documents which collectively cover as many distinct (weighted) words as possible Greedy selection yields (1-1/e) bound. Need to find good weighting function (learning problem).
 words as possible. Greedy selection yields (1-1/e) bound. Need to find good weighting function (learning problem).")
40
Example V1 1 V2 2 V3 3 V4 4 V5 5 V1 V2 V3 V4 V5 D1 X D2 D3 Iter 1 12
Document Word Counts Word Benefit V1 1 V2 2 V3 3 V4 4 V5 5 V1 V2 V3 V4 V5 D1 X D2 D3 Marginal Benefit D1 D2 D3 Best Iter 1 12 11 10 Iter 2

41
Example V1 1 V2 2 V3 3 V4 4 V5 5 V1 V2 V3 V4 V5 D1 X D2 D3 Iter 1 12
Document Word Counts Word Benefit V1 1 V2 2 V3 3 V4 4 V5 5 V1 V2 V3 V4 V5 D1 X D2 D3 Marginal Benefit D1 D2 D3 Best Iter 1 12 11 10 Iter 2 -- 2 3

42
Related Work Comparison
Essential Pages [Swaminathan et al., 2008] Uses fixed function of word benefit Depends on word frequency in candidate set Our goals Automatically learn a word benefit function Learn to predict set covers Use training data Minimize subtopic loss No prior ML approach (to our knowledge)
")
43
Linear Discriminant x = (x1,x2,…,xn) - candidate documents
y – subset of x V(y) – union of words from documents in y. Discriminant Function: (v,x) – frequency features (e.g., ¸10%, ¸20%, etc). Benefit of covering word v is then wT(v,x) [Y, Joachims; ICML 2008]
 – union of words from documents in y. Discriminant Function: (v,x) – frequency features (e.g., ¸10%, ¸20%, etc). Benefit of covering word v is then wT(v,x) [Y, Joachims; ICML 2008]")
44
Linear Discriminant Does NOT reward redundancy
Benefit of each word only counted once Greedy has (1-1/e)-approximation bound Linear (joint feature space) Allows for SVM optimization [Y, Joachims; ICML 2008]
-approximation bound. Linear (joint feature space) Allows for SVM optimization. [Y, Joachims; ICML 2008]")
45
More Sophisticated Discriminant
Documents “cover” words to different degrees A document with 5 copies of “Microsoft” might cover it better than another document with only 2 copies. Use multiple word sets, V1(y), V2(y), … , VL(y) Each Vi(y) contains only words satisfying certain importance criteria. [Y, Joachims; ICML 2008]
, V2(y), … , VL(y) Each Vi(y) contains only words satisfying certain importance criteria. [Y, Joachims; ICML 2008]")
46
More Sophisticated Discriminant
Separate i for each importance level i. Joint feature map is vector composition of all i Greedy has (1-1/e)-approximation bound. Still uses linear feature space. [Y, Joachims; ICML 2008]
-approximation bound. Still uses linear feature space. [Y, Joachims; ICML 2008]")
47
Weighted Subtopic Loss
Example: x1 covers t1 x2 covers t1,t2,t3 x3 covers t1,t3 Motivation Higher penalty for not covering popular subtopics Mitigates effects of label noise in tail subtopics # Docs Loss t1 3 1/2 t2 1 1/6 t3 2 1/3

48
Structural SVM Input: x (candidate set of documents)
Target: y (subset of x of size K) Same objective function: Constraints for each incorrect labeling y’. Score of best y at least as large as incorrect y’ plus loss Finding most violated constraint also set cover problem
 Same objective function: Constraints for each incorrect labeling y’. Score of best y at least as large as incorrect y’ plus loss. Finding most violated constraint also set cover problem.")
49
TREC Experiments TREC 6-8 Interactive Track Queries
Documents labeled into subtopics. 17 queries used, considered only relevant docs decouples relevance problem from diversity problem 45 docs/query, 20 subtopics/query, 300 words/doc

50
TREC Experiments 12/4/1 train/valid/test split
Approx 500 documents in training set Permuted until all 17 queries were tested once Set K=5 (some queries have very few documents) SVM-div – uses term frequency thresholds to define importance levels SVM-div2 – in addition uses TFIDF thresholds
 SVM-div – uses term frequency thresholds to define importance levels. SVM-div2 – in addition uses TFIDF thresholds.")
51
TREC Results Method Loss Random 0.469 Okapi 0.472 Unweighted Model
0.471 Essential Pages 0.434 SVM-div 0.349 SVM-div2 0.382 Methods W / T / L SVM-div vs Ess. Pages 14 / 0 / 3 ** SVM-div2 vs Ess. Pages 13 / 0 / 4 SVM-div vs SVM-div2 9 / 6 / 2

52
Can expect further benefit from having more training data.

53
IR as Structured Prediction
As a general approach: Structured prediction encapsulates goals of IR Recent work have demonstrated the benefit of using structured prediction. Future directions: Apply to more general retrieval paradigms XML retrieval

54
XML Retrieval Can retrieve information at different scopes
Individual documents Smaller components of documents Larger clusters of documents Issues of objective function & diversity still apply Complex performance measures Inter-component dependencies [Image src:

55
Blog Retrieval Special case of XML retrieval
Query: “High Energy Physics” Return a blog feed? Return blog front page? Return individual blog posts? Optimizing for MAP? Diversity?

56
Active Learning Batch Learning Active Learning:
Learns a model using pre-collected training data Assumes training data representative of unseen data Most studied machine learning paradigm Very successful in wide range of applications Includes most work on structured prediction Active Learning: Can be applied directly to live users Representative of real users Removes cost of human labeled training data Time / Money / Reliability

57
Implicit Feedback Users provide feedback while searching
What results they click on How they reformulate queries The length of time from issuing query to clicking on a result Geographical User-specific data Personal search history Age / gender / profession / etc.

58
Presentation Bias in Click Results
[Granka et al., 2004]

59
Biased Implicit Feedback
Users biased towards top of rankings Passive collection results in very biased training data No feedback for relevant documents outside top 10 Most prior work focus on passive collection Our goals Use active learning methods to gather unbiased implicit feedback Still present good results to users while learning Learn “on the fly”

60
Preferences Between Rankings
Interleave two rankings into one ranking Users click more on documents from better ranking. [Radlinski et al., 2008]

61
Active Learning Approach
Leverage ranking preference test Compare relative quality of competing retrieval functions Not biased towards any specific rank position Avoid showing users poor results Quickly determine bad rankings Algorithm must learn “online” Formulate as a multi-armed bandit problem

62
Dueling Bandits Problem
Given bandits (retrieval functions) r1, …, rN Each time step compares two bandits Comparison is noisy Some probability of saying worse bandit is better Each comparison independent Choose pair (rt,rt’) to minimize regret: (% users who prefer best bandit over chosen ones) [Broder, Kleinberg, Y; work in progress]
 r1, …, rN. Each time step compares two bandits. Comparison is noisy. Some probability of saying worse bandit is better. Each comparison independent. Choose pair (rt,rt’) to minimize regret: (% users who prefer best bandit over chosen ones) [Broder, Kleinberg, Y; work in progress]")
63
Regret Minimization If regret is sublinear in T (e.g., log T)
Then average regret (over time) tends to 0 Want average regret to approach 0 quickly RT should be as small as possible [Broder, Kleinberg, Y; work in progress]
 tends to 0. Want average regret to approach 0 quickly. RT should be as small as possible. [Broder, Kleinberg, Y; work in progress]")
64
Results Let ε be the differentiability of top two (r*,r**)
P(r* > r**) = ½ + ε Known lower bound: Interleaved Filter achieves regret Information theoretically optimal (up to constant factors) [Broder, Kleinberg, Y; work in progress]
 = ½ + ε. Known lower bound: Interleaved Filter achieves regret. Information theoretically optimal. (up to constant factors) [Broder, Kleinberg, Y; work in progress]")
65
Assumptions Strong Stochastic Transitivity
For three bandits ri > rj > rk : Stochastic Triangle Inequality Satisfied by many standard generative models E.g., Logistic/Bradley-Terry (K=2)
")
66
Interleaved Filter Choose candidate bandit at random ►

67
Interleaved Filter Choose candidate bandit at random
Make noisy comparisons (Bernoulli trial) against all other bandits in turn Maintain mean and confidence interval ►
 against all other bandits in turn. Maintain mean and confidence interval. ►")
68
Interleaved Filter Choose candidate bandit at random
Make noisy comparisons (Bernoulli trial) against all other bandits in turn… Maintain mean and confidence interval …until another bandit is better With confidence 1 – δ ►
 against all other bandits in turn… Maintain mean and confidence interval. …until another bandit is better. With confidence 1 – δ. ►")
69
Interleaved Filter Choose candidate bandit at random
Make noisy comparisons (Bernoulli trial) against all other bandits in turn… Maintain mean and confidence interval …until another bandit is better With confidence 1 – δ Repeat process with new candidate Remove all empirically worse bandits ►
 against all other bandits in turn… Maintain mean and confidence interval. …until another bandit is better. With confidence 1 – δ. Repeat process with new candidate. Remove all empirically worse bandits. ►")
70
Interleaved Filter Choose candidate bandit at random
Make noisy comparisons (Bernoulli trial) against all other bandits in turn… Maintain mean and confidence interval …until another bandit is better With confidence 1 – δ Repeat process with new candidate Remove all empirically worse bandits Continue until 1 candidate left ►
 against all other bandits in turn… Maintain mean and confidence interval. …until another bandit is better. With confidence 1 – δ. Repeat process with new candidate. Remove all empirically worse bandits. Continue until 1 candidate left. ►")
71
Regret Analysis Stops comparing at 1 – δ confidence
Concludes one bandit is better Appropriate choice of δ ** leads to 1 - 1/T probability of finding r* Regret is 0 whenever we choose r* Only accumulate regret when finding r* ** δ = N-2T-1

72
Naïve Approach In deterministic case, O(N) comparisons to find max
Extend to noisy case: Maintain current candidate Run comparisons against 1 other bandit until 1 – δ confidence Take better bandit as candidate Repeat until all bandits considered Problem: If current candidate awful Many comparisons to determine which awful bandit is better Incur high regret for each comparison

73
Naïve vs Interleaved Filter
Naïve performs poorly due to matches between two awful bandits Too many comparisons Accumulates high regret Interleaved Filter bounds matches using bounds on current candidate vs best Stops when better bandit found Regret bounded

74
Naïve vs Interleaved Filter
But Naïve concentrates on 2 bandits at any point in time Interleaved Filter compares 1 bandit vs rest simultaneously Should experience N2 blowup in regret … or at least N log N

75
Regret Analysis Define a round to be all the time steps for
a particular candidate bandit O(log N) rounds total w.h.p. Define a match to be all the comparisons between two bandits in a round O(N) matches in each round At most O(N log N) total matches End of each round Remove empirically inferior bandits “Constant fraction” of bandits removed after each round
 rounds total w.h.p. Define a match to be all the comparisons. between two bandits in a round. O(N) matches in each round. At most O(N log N) total matches. End of each round. Remove empirically inferior bandits. Constant fraction of bandits removed. after each round.")
76
Regret Analysis O(log N) rounds played
“Constant fraction” of bandits removed at end of each round O(N) total matches w.h.p. Each match incurs regret Expected regret:
 total matches w.h.p. Each match incurs regret. Expected regret:")
77
Dueling Bandits Problem
Uses a natural (and simple) regret formulation Captures preference for the best possible retrieval function Consistent with unbiased ranking preference feedback [Radlinski et al., 2008] Online/Bandit formulation of finding the max w/ noisy compares Interleaved Filter achieves best possible regret bound - Logarithmic in T - Linear in N
 regret formulation. Captures preference for the best possible retrieval function. Consistent with unbiased ranking preference feedback. [Radlinski et al., 2008] Online/Bandit formulation of finding the max w/ noisy compares. Interleaved Filter achieves best possible regret bound. - Logarithmic in T. - Linear in N.")
78
Related Work Other forms of implicit feedback
Preferences between documents within a ranking Other active learning techniques Bandit algorithm for minimizing abandonment [Radlinski et al., 2008] Active exploration of pairwise document preferences [Radlinski et al., 2007] These approaches cannot generalize across queries Most learning approaches use passive collection Susceptible to presentation bias

79
Moving Forward Limitations Future directions
Assumes users preferences are static Interleaved filter first explores, then commits Assumes a finite set of ranking functions Should assume a continuous parameter space Future directions Use Interleaved Filter as an optimization engine Collect finite sample from continuous parameter space Look at completely new problem formulations Progress towards live user studies

80
Summary Structured prediction for complex retrieval problems
Rank-based performance measures Diversity Potentially much more! Active learning using unbiased implicit feedback Learn directly from users (cheaper & more accurate) Active learning for structured prediction models? Thanks to Tie-Yan Liu and Hang Li
 Active learning for structured prediction models Thanks to Tie-Yan Liu and Hang Li.")
81
Extra Slides

82
SVM-map

83
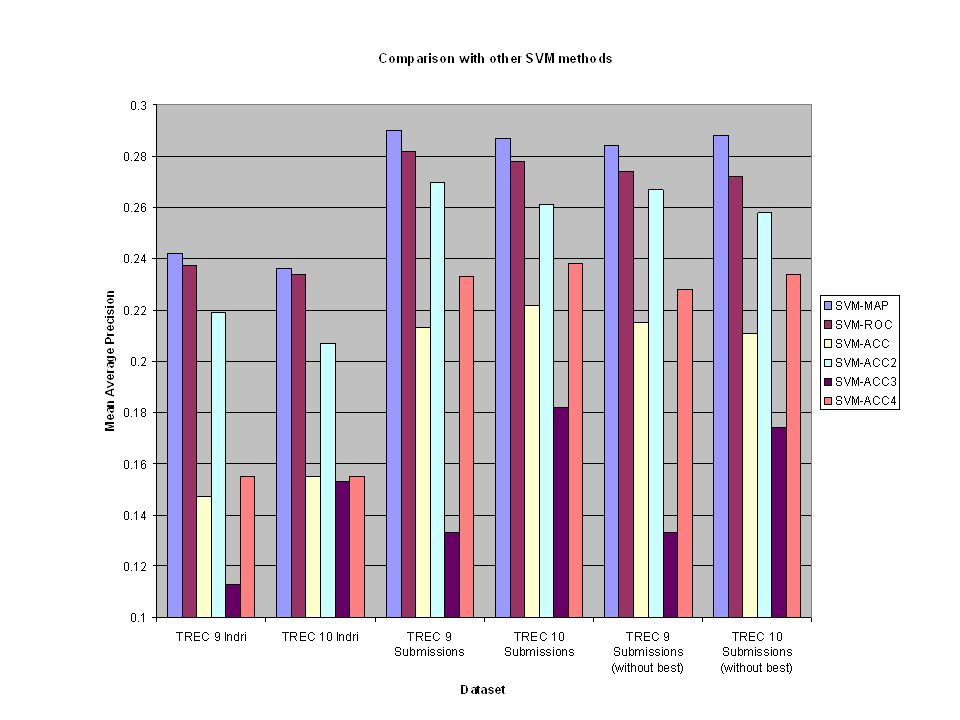
Experiments Used TREC 9 & 10 Web Track corpus.
Features of document/query pairs computed from outputs of existing retrieval functions. (Indri Retrieval Functions & TREC Submissions) Goal is to learn a recombination of outputs which improves mean average precision.
 Goal is to learn a recombination of outputs which improves mean average precision.")
86
SVM-div

87
Essential Pages x = (x1,x2,…,xn) - set of candidate documents for a query y – a subset of x of size K (our prediction). Benefit of covering word v with document xi Importance of covering word v Intuition: Frequent words cannot encode information diversity. Infrequent words do not provide significant information [Swaminathan et al., 2008]

88
Finding Most Violated Constraint
Encode each subtopic as an additional “word” to be covered. Use greedy prediction to find approximate most violated constraint.

89
Approximate Constraint Generation
Theoretical guarantees no longer hold. Might not find an epsilon-close approximation to the feasible region boundary. Performs well in practice.

90
Approximate constraint generation seems to work perform well.

91
Synthetic Dataset Trec dataset very small
Synthetic dataset so we can vary retrieval size K 100 queries 100 docs/query, 25 subtopics/query, 300 words/doc 15/10/75 train/valid/test split

92
Consistently outperforms Essential Pages

93
Interleaved Filter

94
Lower Bound Example All suboptimal bandits roughly equivalent
comparisons to differentiate best from suboptimal Pay Θ(ε) regret for each comparison Accumulated regret over all comparisons is at least
 regret for each comparison. Accumulated regret over all comparisons is at least.")
95
Per-Match Regret Number of comparisons in match ri vs rj :
ε1i > εij : round ends before concluding ri > rj ε1i < εij : conclude ri > rj before round ends, remove rj Pay ε1i + ε1j regret for each comparison By triangle inequality ε1i + ε1j ≤ (2K+1)max{ε1i , εij} Thus by stochastic transitivity accumulated regret is
max{ε1i , εij} Thus by stochastic transitivity accumulated regret is.")
96
Number of Rounds Assume all superior bandits have
equal prob of defeating candidate Worst case scenario under transitivity Model this as a random walk rj transitions to each ri (i < j) with equal probability Compute total number of steps before reaching r1 (i.e., r*) Can show O(log N) w.h.p. using Chernoff bound
 with equal probability. Compute total number of steps before reaching r1 (i.e., r*) Can show O(log N) w.h.p. using Chernoff bound.")
97
Total Matches Played O(N) matches played in each round
Naïve analysis yields O(N log N) total However, all empirically worse bandits are also removed at the end of each round Will not participate in future rounds Assume worst case that inferior bandits have ½ chance of being empirically worse Can show w.h.p. that O(N) total matches are played over O(log N) rounds
 total. However, all empirically worse bandits. are also removed at the end of each round. Will not participate in future rounds. Assume worst case that inferior bandits have ½ chance of. being empirically worse. Can show w.h.p. that O(N) total matches are played. over O(log N) rounds.")
98
Removing Inferior Bandits
At conclusion of each round Remove any empirically worse bandits Intuition: High confidence that winner is better than incumbent candidate Empirically worse bandits cannot be “much better” than incumbent candidate Can show that winner is also better than empirically worse bandits with high confidence Preserves 1-1/T confidence overall that we’ll find the best bandit

Similar presentations

















 2.Ranked retrieval 3.Probabilistic retrieval.>")
 and joint work with Marko Krznaric (MK) Data Types.>")


>")