Download presentation
Presentation is loading. Please wait.

1
C-Store: Column Stores over Solid State Drives Jianlin Feng School of Software SUN YAT-SEN UNIVERSITY Jun 19, 2009

2
Solid State Drives (SSDs) vs. Hard Disk Drives (HDDs) HDDs (traditional magnetic hard drives) perform sequential reads much faster than random reads. The traditional wisdom is to avoid random I/O as much as possible. SSDs perform random reads more than 100x faster than HDDs, and offer comparable sequential read and write performance. SSDs’ random write performance is much worse than random read performance.
 HDDs (traditional magnetic hard drives) perform sequential reads much faster than random reads. The traditional wisdom is to avoid random I/O as much as possible. SSDs perform random reads more than 100x faster than HDDs, and offer comparable sequential read and write performance. SSDs’ random write performance is much worse than random read performance..")
3
Characteristics of HDD and SSD (NAND Flash)
")
4
How to leverage the fast random reads of SSDs? Avoid reading unnecessary attributes during selections and projections. The idea of Column store. Reduce I/O requirements during join by minimizing passes over related tables. Minimize the I/O needed to fetch attribute values by late materialization.

5
Page Layouts: NSM vs PAX NSM: traditional row store. PAX: A hybrid approach of row store and column store. each page is divided into n minipages. Each minipage stores the values of a column contiguously.

6
FlashScan Operator It is a scan operator that leverages the PAX layout to improve selections and projections on flash SSDs. Basic ideas: Once a page is brought into main memory, read only the minipages of the attributes that are in need. The goal is to reduce memory bandwidth. The cache line is 128 Bytes long, suggesting ideally a minipage should take the same size.

7
An Example Running of FlashScan Consider a scan that simply project the 1 st and 3 rd column of the relation in Figure 3. For each page, FlashScan initially reads the minipage of the 1 st column And then “seeks” to the start of the 3 rd minipage and read it. Then it “seeks” again to the first minipage of the next page. This procedure continues over the entire relation, resulting in a random access pattern.

8
Processing Random Reads in a Batch Mode In general, every “seek” results in a random read. FlashScan coalesces the reads and performs one random access of SSD for each set of contiguous minipages.

9
Implementing FlashScan in Postgres Divide every page into dense-packed minipages. Modify the buffer manager and bulk loader to work with the PAX page layout. A page in the buffer pool may be partially full containing only the minipages transferred by FlashScan. Make FlashScan output tuples in row-format. i.e., tuple reconstruction.

10
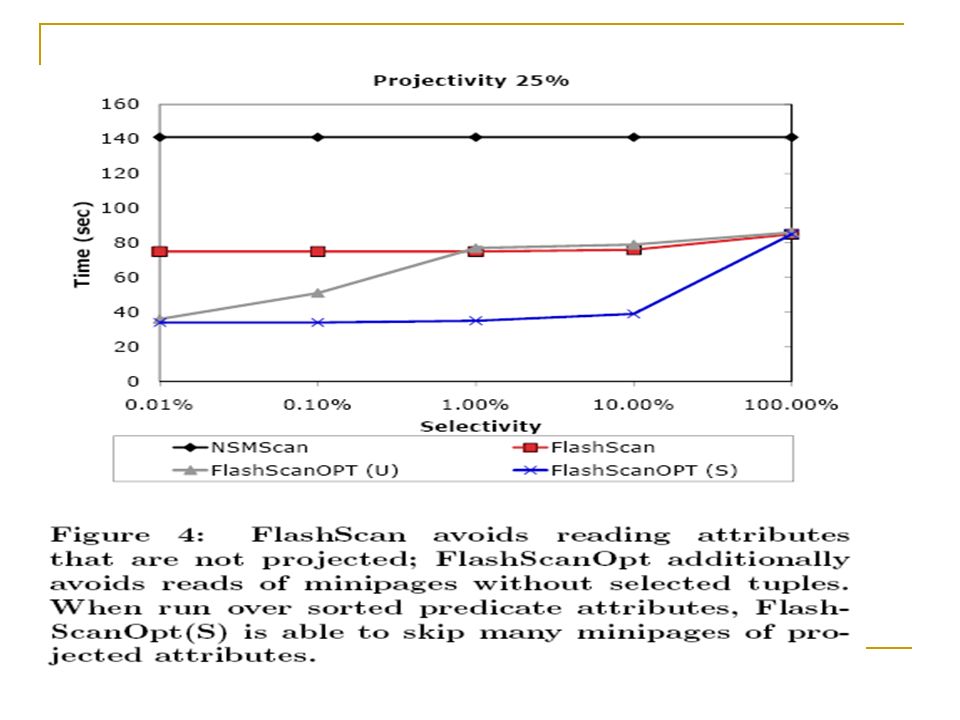
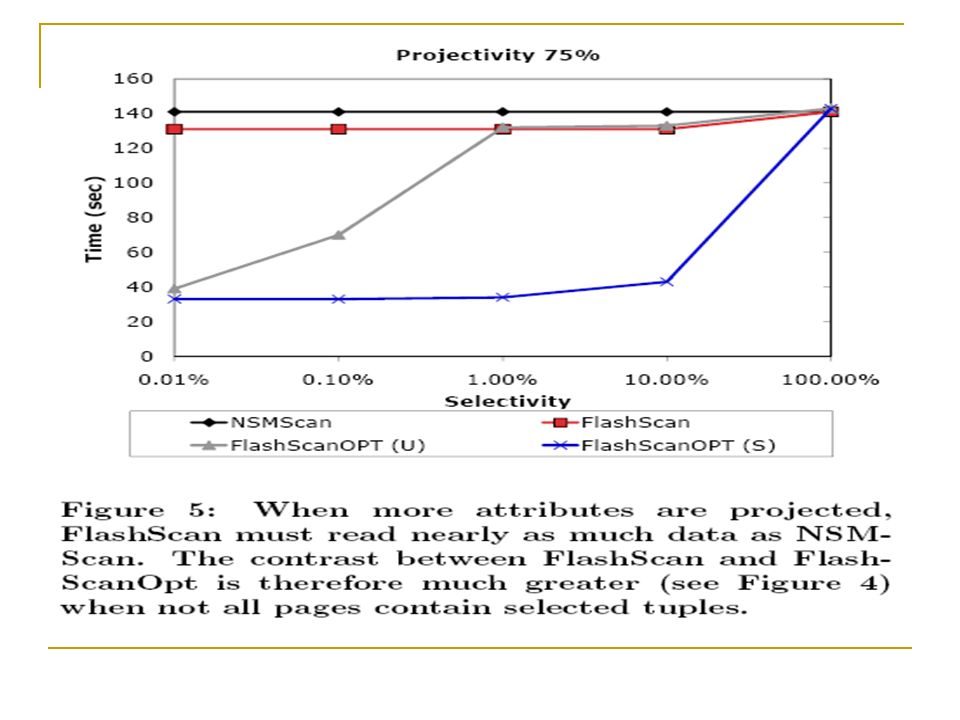
Optimization for Selection Predicates The technique Read only the minipages that satisfying the selection conditions. This technique is beneficial for highly selective conditions and for selection conditions that are applied to sorted or partially sorted attributes.

13
FlashScan and Column Stores FlashScan needs to “seek” between minipages. Column stores need to “seek” between columns. Column stores on HDDs read a large portion of a single column at a time to amortize the “seek” overhead. If a column store is built on SSDs, it should have similar behavior as FlashScan. This assertion needs experimental validation. And a PAX-based system can be easily integrated with a row-store DBMS. So we have no need to build a column store on SSDs?

14
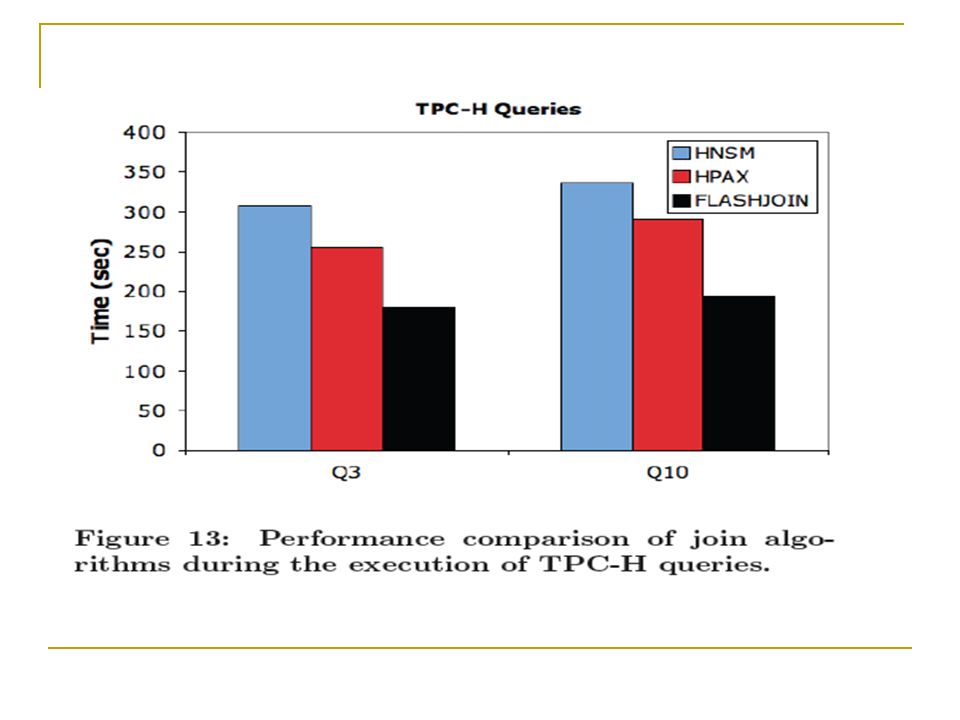
Overview of FlashJoin FlashJoin is a multi-way equi-join algorithm. It is implemented as a pipeline stylized binary joins. Each binary join in the pipeline consists of two separate operators: a join kernel a fetch kernel.

15
An Example of FlashJoin Using Late Materialization

16
Join Kernel The join kernel leverages FlashScan to fetch only the join attributes needed from base relations. i.e., FlashJoin uses late materialization. Hence the join kernel needs less memory, which may lead to less passes for computing the join. The join kernel computes the join and output a join index. For example, Join 2 in previous slide produces a join index containing three RIDs (id1, id2, id3) pointing to rows of R1, R2, and R3.
 pointing to rows of R1, R2, and R3..")
17
Fetch Kernel The fetch kernel uses the join index to do tuple reconstruction. i.e., retrieve values of projected attributes for tuples in the join result. A naïve strategy is to do tuple reconstruction in a tuple-at-a-time fashion. If several tuples belonging to the same page, that page may be read several times. This is not a problem if we have enough memory.

18
An Optimization in Fetch Kernel Makes multiple passes over the join index to fetch attributes in row order from one relation at a time. In each pass, the join index is sorted based on the RIDs of the current relation R to be scanned. Then, it retrieves the needed attributes from that relation R for each tuple and augments the join index with those attributes.

19
Why Does the Fetching in Row Order? Sorting ensures that once a minipage from a relation has been accessed, it will not need to accessed again. Thus placing minimal demands on the buffer pool. However sorting does not ensure sequential access to the underlying relation. Because pages corresponding to the sorted RIDs can be far apart. Hence this optimization is better performed on SSDs than on HDDs.

21
Conclusion SSDs consititute a significant shift in hardware characteristics. comparable to large CPU caches and many-core processors. SSDs can improve performance for read- most applications. A column-based page data layout is shown to be a natural choice for speeding up selections and projections on SSDs.

22
References Dimitris Tsirogiannis, Stavros Harizopoulos, Mehul A. Shah, Janet L. Wiener, and Goetz Graefe. Query Processing Techniques for Solid State Drives. In SIGMOD, 2009.Query Processing Techniques for Solid State Drives

Similar presentations


>")



, rating INT, age REAL) Maintenances (sin INT, planeId INT, day.>")



 and a real system. –Optimize for CPU, space, and logging. But things have changed drastically! Hardware trend:>")








