Download presentation
Presentation is loading. Please wait.

1
The Anatomy of a Large- Scale Hypertextual Web Search Engine Sergey Brin, Lawrence Page CS Department Stanford University Presented by Md. Abdus Salam CSE Department University of Texas at Arlington

2
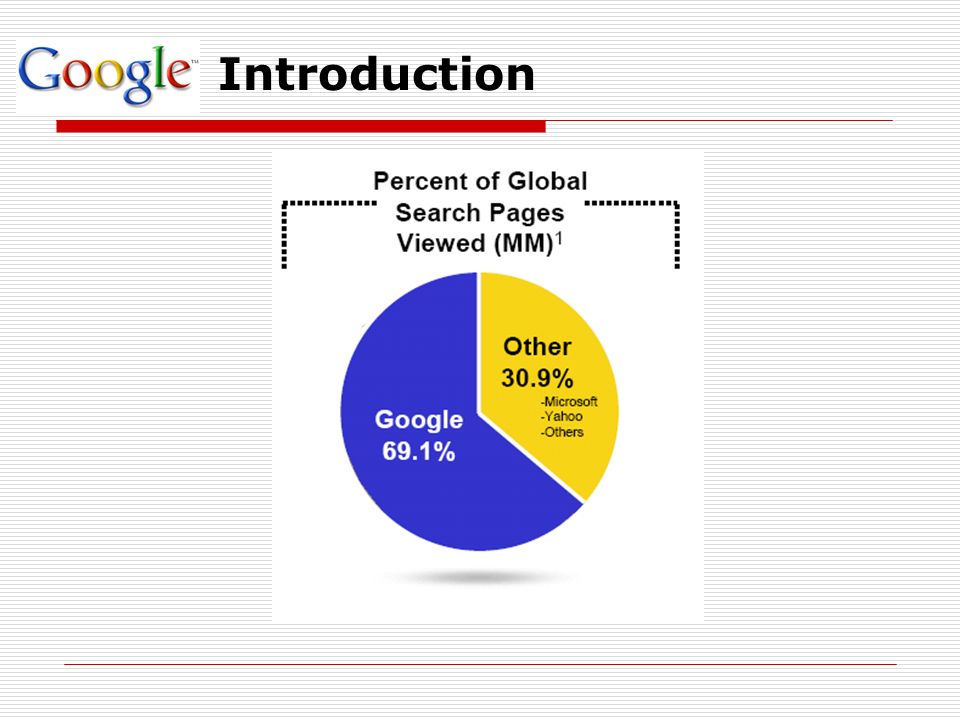
Introduction

4
Google ’ s Mission To organize the world ’ s information and make it universally accessible and useful Scaling with the web Improved Search Quality Academic Search Engine Research

5
System Features It makes use of the link structure of the Web to calculate a quality ranking for each web page, called PageRank PageRank is a trademark of Google. The PageRank process has been patented. Google utilizes link to improve search results

6
PageRank PageRank is a link analysis algorithm which assigns a numerical weighting to each Web page, with the purpose of "measuring" relative importance. Based on the hyperlinks map An excellent way to prioritize the results of web keyword searches

7
Simplified PageRank algorithm Assume four web pages: A, B,C and D. Let each page would begin with an estimated PageRank of 0.25. L(A) is defined as the number of links going out of page A. The PageRank of a page A is given as follows: A B C D A B C D
 is defined as the number of links going out of page A. The PageRank of a page A is given as follows: A B C D A B C D.")
8
PageRank algorithm including damping factor Assume page A has pages B, C, D..., which point to it. The parameter d is a damping factor which can be set between 0 and 1. Usually set d to 0.85. The PageRank of a page A is given as follows:

9
Intuitive Justification A "random surfer" who is given a web page at random and keeps clicking on links, never hitting "back “, but eventually gets bored and starts on another random page. The probability that the random surfer visits a page is its PageRank. The d damping factor is the probability at each page the "random surfer" will get bored and request another random page. A page can have a high PageRank If there are many pages that point to it Or if there are some pages that point to it, and have a high PageRank.

10
Anchor Text Yahoo! Besides the text of a hyperlink (anchor text) is associated with the page that the link is on, it is also associated with the page the link points to. anchors often provide more accurate descriptions of web pages than the pages themselves. anchors may exist for documents which cannot be indexed by a text-based search engine, such as images, programs, and databases.
 is associated with the page that the link is on, it is also associated with the page the link points to. anchors often provide more accurate descriptions of web pages than the pages themselves. anchors may exist for documents which cannot be indexed by a text-based search engine, such as images, programs, and databases..")
11
Other Features It has location information for all hits. Google keeps track of some visual presentation details such as font size of words. Words in a larger or bolder font are weighted higher than other words. Full raw HTML of pages is available in a repository

12
Architecture Overview

13
Major Data Structures BigFiles virtual files spanning multiple file systems and are addressable by 64 bit integers. Repository contains the full HTML of every web page. Document Index keeps information about each document. Lexicon two parts – a list of the words and a hash table of pointers. Hit Lists a list of occurrences of a particular word in a particular document including position, font, and capitalization information. Forward Index stored in a number of barrels Inverted Index consists of the same barrels as the forward index, except that they have been processed by the sorter.

14
Google Architecture Contains full html of every web page. Each document is prefixed by docID, length, and URL. Uncompresses and parses documents. Stores link information in anchors file. Converts relative URLs into absolute URLs. Stores each link and text surrounding link. Keeps track of URLs that have and need to be crawled Multiple crawlers run in parallel. Each crawler keeps its own DNS lookup cache and ~300 open connections open at once. Compresses and stores web pages

15
Google Architecture DocID keyed index where each entry includes info such as pointer to doc in repository, checksum, statistics, status, etc. Also contains URL info if doc has been crawled. If not just contains URL. Maps absolute URLs into docIDs stored in Doc Index. Stores anchor text in “barrels”. Generates database of links (pairs of docIds). Parses & distributes hit lists into “barrels.” Partially sorted forward indexes sorted by docID. Each barrel stores hitlists for a given range of wordIDs. In-memory hash table that maps words to wordIds. Contains pointer to doclist in barrel which wordId falls into. Creates inverted index whereby document list containing docID and hitlists can be retrieved given wordID.
. Parses & distributes hit lists into barrels. Partially sorted forward indexes sorted by docID. Each barrel stores hitlists for a given range of wordIDs. In-memory hash table that maps words to wordIds. Contains pointer to doclist in barrel which wordId falls into. Creates inverted index whereby document list containing docID and hitlists can be retrieved given wordID..")
16
Google Architecture 2 kinds of barrels. Short barrell which contain hit list which include title or anchor hits. Long barrell for all hit lists. New lexicon keyed by wordID, inverted doc index keyed by docID, and PageRanks used to answer queries List of wordIds produced by Sorter and lexicon created by Indexer used to create new lexicon used by searcher. Lexicon stores ~14 million words.

17
Crawling the Web Google has a fast distributed crawling system. A single URLserver serves lists of URLs to a number of crawlers. Both the URLserver and the crawlers are implemented in Python. Each crawler keeps roughly 300 connections open at once. At peak speeds, the system can crawl over 100 web pages per second using four crawlers. This amounts to roughly 600K per second of data. Each crawler maintains its own DNS cache so it does not need to do a DNS lookup before crawling each document.

18
Indexing the Web Parsing Any parser which is designed to run on the entire Web must handle a huge array of possible errors. Indexing Documents into Barrels After each document is parsed, it is encoded into a number of barrels. Every word is converted into a wordID by using an in- memory hash table -- the lexicon. Once the words are converted into wordID's, their occurrences in the current document are translated into hit lists and are written into the forward barrels. Sorting the sorter takes each of the forward barrels and sorts it by wordID to produce an inverted barrel for title and anchor hits and a full text inverted barrel.

19
Google Query Evaluation 1.Parse the query. 2.Convert words into wordIDs. 3.Seek to the start of the doclist in the short barrel for every word. 4.Scan through the doclists until there is a document that matches all the search terms. 5.Compute the rank of that document for the query. 6.If we are in the short barrels and at the end of any doclist, seek to the start of the doclist in the full barrel for every word and go to step 4. 7.If we are not at the end of any doclist go to step 4. 8.Sort the documents that have matched by rank and return the top k.

20
Single Word Query Ranking Hitlist is retrieved for single word Each hit can be one of several types: title, anchor, URL, large font, small font, etc. Each hit type is assigned its own weight Type-weights make up vector of weights Number of hits of each type is counted to form count-weight vector Dot product of type-weight and count-weight vectors is used to compute IR score IR score is combined with PageRank to compute final rank

21
Multi-word Query Ranking Similar to single-word ranking except now must analyze proximity of words in a document Hits occurring closer together are weighted higher than those farther apart Each proximity relation is classified into 1 of 10 bins ranging from a “phrase match” to “not even close” Each type and proximity pair has a type-prox weight Counts converted into count-weights Take dot product of count-weights and type- prox weights to computer for IR score

22
Scalability Cluster architecture combined with Moore’s Law make for high scalability. At time of writing: ~ 24 million documents indexed in one week ~518 million hyperlinks indexed Four crawlers collected 100 documents/sec

23
Key Optimization Techniques Each crawler maintains its own DNS lookup cache Use flex to generate lexical analyzer with own stack for parsing documents Parallelization of indexing phase In-memory lexicon Compression of repository Compact encoding of hit lists for space saving Indexer is optimized so it is just faster than the crawler so that crawling is the bottleneck Document index is updated in bulk Critical data structures placed on local disk Overall architecture designed avoid to disk seeks wherever possible

24
Storage Requirements At the time of publication, Google had the following statistical breakdown for storage requirements:

25
Results and Performance The version of Google when this paper was written, answered most queries in between 1 and 10 seconds. The table shows some samples search time from that version of Google. They were repeated to show the speedups resulting from cached IO.

26
Conclusion Google is designed to be a scalable search engine. The primary goal is to provide high quality search results over a rapidly growing World Wide Web. Google employs a number of techniques to improve search quality including page rank, anchor text, and proximity information. Google is a complete architecture for gathering web pages, indexing them, and performing search queries over them.

27
Google bomb Because of the PageRank, a page will be ranked higher if the sites that link to that page use consistent anchor text.anchor text A Google bomb is created if a large number of sites link to the page in this manner. search term "more evil than Satan himself" the Microsoft homepage as the top result.Microsoft

28
Problems All Shopping, All the Time – Searching for “flowers”, more than 90% of the top results are online florists. Skewed Synonyms – If “apple” is searched, the top results would be related to apple computers. Book Learning – People are implicitly pushed toward information stored in articles and away from information stored in books.

29
The Future “ The ultimate search engine would understand exactly what you mean and give back exactly what you want. ” - Larry Page

30
Web Search For A Planet The Google Cluster Architecture Luiz Andre Barroso Jeffrey Dean Urs Holzle Google Presented by Md. Abdus Salam CSE Department University of Texas at Arlington

31
Basic Cluster Design Insights Reliability in software rather than server-class hardware. Commodity PCs used to build high-end computing cluster at a low end prices. Example: $278,000 – 176x 2GHz Xeon, 176GB RAM, 7TB HDD $758,000 – 8x 2GHZ Xeon, 64GB RAM, 8TB HDD Design is tailored for best aggregate request throughput, not peak server response time – individual request parallelization

32
Serving a Google Query 1.Pre-phase: Browser requests e.g. http://www.google.com/search?q=edu+session DNS-based load-balancing selects cluster according to the geographical location of the user & actual cluster utilization The rest of the evaluation is entirely local to the that cluster 2.Phase 1: Index servers... Parse the query Perform spell-check and fork Ad task Convert words into WORDIDs Choose inverted Barrel(s) using Lexicon Barrel index is formed by number of servers whose data are randomly distributed and replicated (full index/index shards) so search is highly parallelizable Inverted barrel maps each query word to a matching list of documents (Hit list) Index servers determine a set of relevant documents by intersecting the hit lists of the individual query words A relevance score for each document is also computed which determines the order of the result in the output page
 using Lexicon Barrel index is formed by number of servers whose data are randomly distributed and replicated (full index/index shards) so search is highly parallelizable Inverted barrel maps each query word to a matching list of documents (Hit list) Index servers determine a set of relevant documents by intersecting the hit lists of the individual query words A relevance score for each document is also computed which determines the order of the result in the output page.")
33
Serving a Google Query 3.Phase 2: Document servers... For each DOCID compute actual title, URL and query-specific document summary (matched words context). Document servers are used to dispatch this completion – also documents are randomly distributed and replicated, so the completion is highly parallelizable
. Document servers are used to dispatch this completion – also documents are randomly distributed and replicated, so the completion is highly parallelizable.")
34
Cluster Design Principles Software reliability Use replication for better request throughput and availability Price/performance beats peak performance Using commodity PCs reduces the cost of computation

35
Bonus

36
Stanford lab (around 1996)
")
37
The Original Google Storage: 10x4GB (1996)
")
38
Google San Francisco (2004)
")
39
A cluster of coolness Google History

40
Google Results Page Per Day

41
References Sergey Brin, Lawrence Page; The Anatomy of a Large-Scale Hypertextual Web Search Engine; 1998 Luiz André Barroso, Jeffrey Dean and Urs Hoelzle:Web Search for a Planet: The Google Cluster Architecture; 2003 http://www-db.stanford.edu/pub/voy/museum/pictures http://www-db.stanford.edu/pub/voy/museum/pictures www.e-mental.com/dvorka/ppt/googleClusterInnards.ppt www.e-mental.com/dvorka/ppt/googleClusterInnards.ppt www.cis.temple.edu/~vasilis/Courses/CIS664/Papers/An- google.ppt www.cis.temple.edu/~vasilis/Courses/CIS664/Papers/An- google.ppt www.cs.uvm.edu/~xwu/kdd/PageRank.ppt www.cs.uvm.edu/~xwu/kdd/PageRank.ppt

42
Thanks!

Similar presentations





 The Anatomy of a Large-Scale Hypertextual Web Search Engine.>")


 Wolfgang Hürst, Albert-Ludwigs-University.>")





 Presenter: Scott White.>")
>")
 - Jeff Dean, Google's Systems Lab:>")


