Download presentation
Presentation is loading. Please wait.

1
National Centre for Text Mining: Activities in biotext mining John McNaught Deputy Director www.nactem.ac.uk

2
Outline Overview of NaCTeM, role in e- Infrastructure Quick tour of NaCTeM services/tools Some challenges for text mining in biology

3
UK National Centre for Text Mining (NaCTeM) 1 st national text mining centre in the world www.nactem.ac.ukwww.nactem.ac.uk Location: Manchester Interdisciplinary Biocentre (MIB) Remit: Provision of text mining services to support UK research Funded by: the JISC, BBSRC, EPSRC Initial focus: Biology
 1 st national text mining centre in the world Location: Manchester Interdisciplinary Biocentre (MIB) Remit: Provision of text mining services to support UK research Funded by: the JISC, BBSRC, EPSRC Initial focus: Biology")
4
Why is there a need in the UK for a national centre for text mining? Some researchers knew they wanted TM TM key component of e-Science UK policy to involve more researchers (from all domains) in doing e-science and e-research TM seen as key technology for researchers And one applicable in every domain (broad interest/support from major funding bodies)
 in doing e-science and e-research TM seen as key technology for researchers And one applicable in every domain (broad interest/support from major funding bodies).")
5
Embedding Text Mining within e-Science in the UK e-Science […] enables new research and increases productivity through shared e ‑ Infrastructure, the development of computational and logical models and new ways to discover and use the growing range of distributed and interoperable resources. It supports multidisciplinary and collaborative working and a culture that adopts the emerging methods. M. Atkinson (2007) Beyond e-Science
![Embedding Text Mining within e-Science in the UK e-Science […] enables new research and increases productivity through shared e ‑ Infrastructure, the development of computational and logical models and new ways to discover and use the growing range of distributed and interoperable resources.](http://images.slideplayer.com/23/6623483/slides/slide_5.jpg "It supports multidisciplinary and collaborative working and a culture that adopts the emerging methods. M. Atkinson (2007) Beyond e-Science.")
6
e-Research Infrastructure Access to information, data resources, distributed computing essential for bio- scientists e-Infrastructure provides services and facilities enabling advanced research Deploying e-Infrastructure increases the pace and efficiency of new research methods and techniques

7
E-Infrastructure and Text Mining: for whom? End-users Software engineers Generic tool developers Service and resource providers Workflow developers Text miners BLAST, Swiss-Prot,

8
What users want to do with their data (minimally) Easier access to data Share data with their peers Annotate data with metadata Manage data across locations Integrate data within workflows, Web Services Aids for semantic metadata creation; enriching data with related metadata e.g. experimental results TEXT MINING CAN SUPPORT USERS

9
METABOLIC MODEL IN SBML CREATE MODEL VISUALISE STORE MODEL IN DB RUN BASE MODEL SENSITIVITY ANALYSES SCAN PARAMETER SPACE COMPARE WITH ‘REAL’ DATA DIFFERENT METABOLIC MODEL IN SBML TEXT MINING ANNOTATE STORE NEW MODEL IN DB COMPARE MODELS STORE DIFFERENCES AS NEW MODEL IN DB SYSTEMS BIOLOGY WORKFLOWS – D.B.KELL, MCISB

10
Science is data-driven “the current scientific literature, were it to be presented in semantically accessible form, contains huge amounts of undiscovered science” Peter Murray-Rust, Data-driven science

11
What do we provide and build? Resources: lexica, terminologies, thesauri, grammars, annotated corpora Tools: tokenisers, taggers, chunkers, parsers, NE recognisers, semantic analysers Services Proof of concept: evolving to large scale Grid-enabled services Service provision through Customised solutions

12
A complex problem TM involves Many components (converters, analysers, miners, visualisers,...) Many resources (grammars, ontologies, lexicons, terminologies, thesauri, CVs) Many combinations of components and resources for different applications Many different user requirements and scenarios, training needs Need to be active in all areas to effectively support researchers
 Many resources (grammars, ontologies, lexicons, terminologies, thesauri, CVs) Many combinations of components and resources for different applications Many different user requirements and scenarios, training needs Need to be active in all areas to effectively support researchers")
13
Development strategy Re-use tools where possible Forge strategic relationships (UTokyo, IBM) Use integration framework (UIMA) Develop generic TM tools Customise for specific domains/scenarios (MCISB, pharmas) While actively engaging with user communities (requirements, evaluation) Encapsulate in services
 Use integration framework (UIMA) Develop generic TM tools Customise for specific domains/scenarios (MCISB, pharmas) While actively engaging with user communities (requirements, evaluation) Encapsulate in services")
14
How do we provide services? Modes of use Demonstrators: for small-scale online use Batch mode: upload data, get email with link to download site when job done Web Services Embedding text mining Web Services into Workflows Some services are compositions of tools Individual tools to process user data

15
Services based on pre-processed collections Pre-process (analyse and index) popular collections MEDLINE Evolving to handle full text (UKPMC) Provide advanced search interfaces to these Based on user scenarios Rapid results for end-user Regular up-dating of analyses carried out
 popular collections MEDLINE Evolving to handle full text (UKPMC) Provide advanced search interfaces to these Based on user scenarios Rapid results for end-user Regular up-dating of analyses carried out")
16
NaCTeM services and tools TerMine AcroMine MEDIE InfoPubMed KLEIO FACTA

19
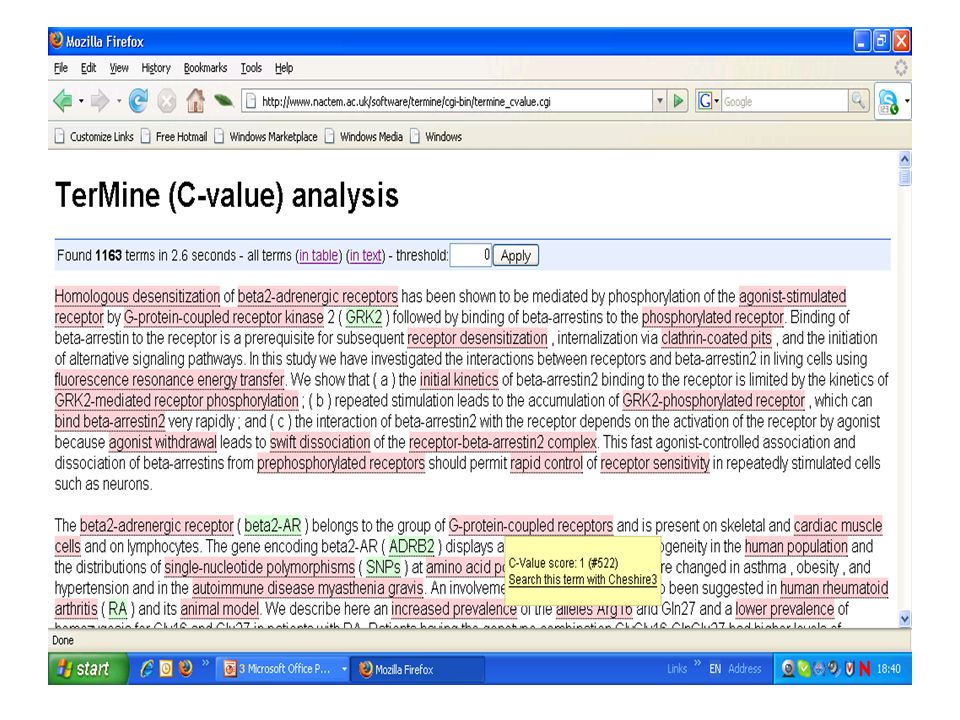
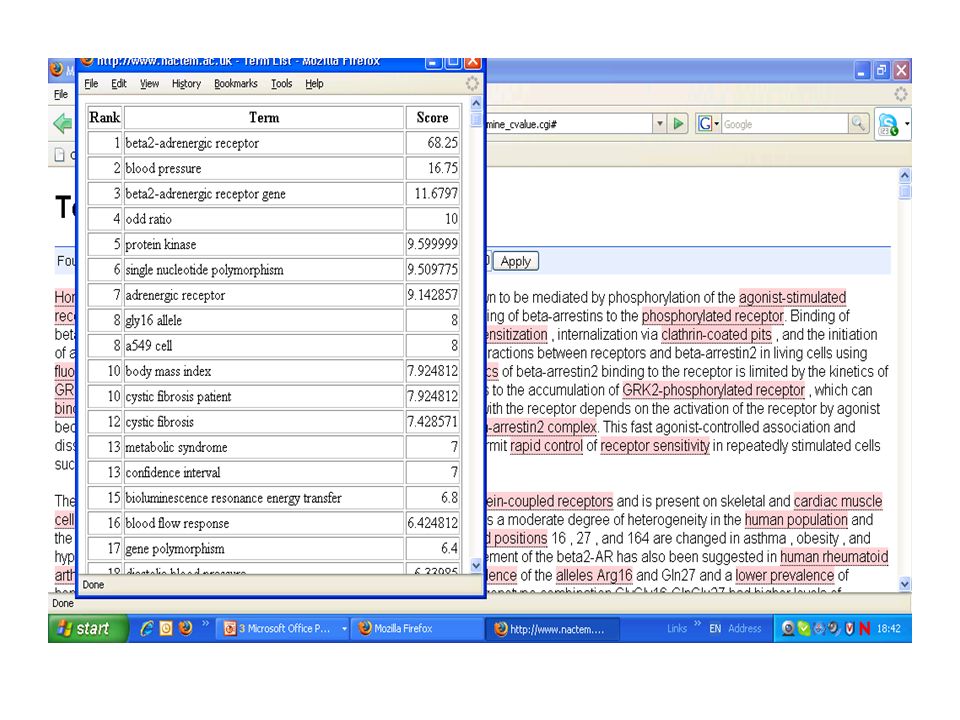
TerMine C-value is a hybrid technique; extracts multi- word terms; language independent Combines linguistic filters and statistics total frequency of occurrence of string in corpus frequency of string as part of longer candidate terms (nested terms) number of these longer candidate terms length of string (in number of words) Frantzi, K., Ananiadou, S. & Mima, H. (2000) International Journal of Digital Libraries 3(2)
 International Journal of Digital Libraries 3(2).")
21
The importance of acronym recognition Acronyms are among the most productive type of term variation Acronyms are used more frequently than full terms 5,477 documents could be retrieved by using the acronym JNK while only 3,773 documents could be retrieved by using its full term, c-jun N-terminal kinase [Wren et al. 05] No rules or exact patterns for the creation of acronyms from their full form

22
Top 20 acronyms in MEDLINE

23
http://www.nactem.ac.uk/software/acromine/
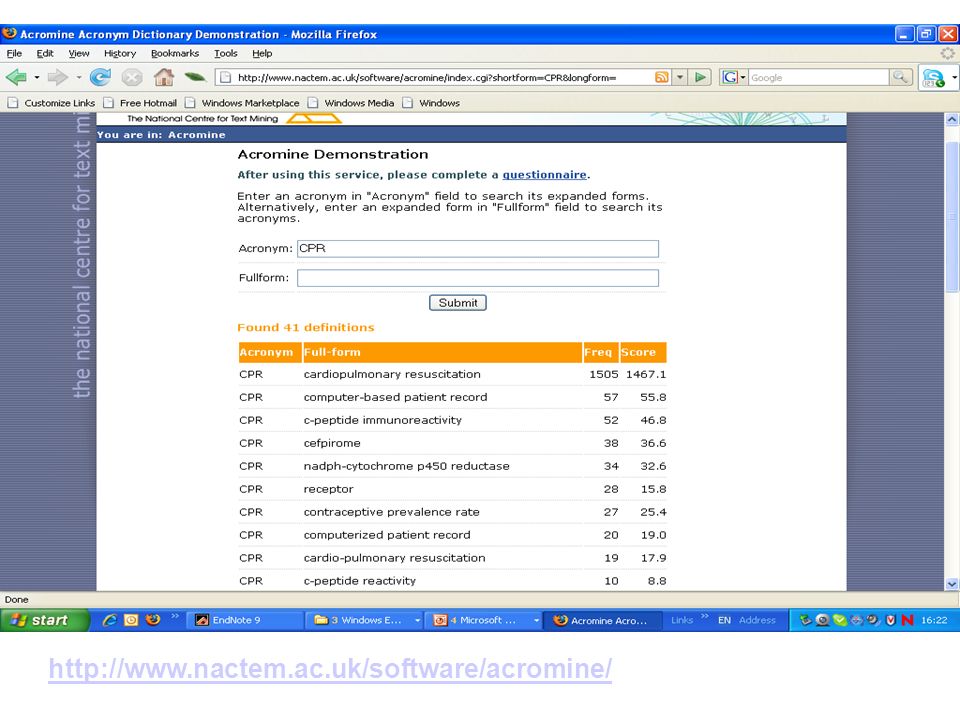
24
MEDIE An interactive intelligent IR system retrieving events Performs a semantic search System components GENIA tagger Enju (HPSG parser) Dictionary-based named entity recognition
 Dictionary-based named entity recognition")
25
http://www-tsujii.is.s.u-tokyo.ac.jp/medie/

26
Semantic structure CRP measurement does NP 13 VP 17 VP 15 SoSo NP 1 DT 2 A VP 16 AV 19 not VP 21 VP 22 exclude NP 25 NP 24 AJ 26 deep NP 28 NP 29 vein NP 31 thrombosis serum NP 4 AJ 5 normal NP 7 NP 8 NP 10 NP 11 ARG1 MOD ARG1 ARG2 ARG1 ARG2 ARG1 MOD Predicate argument relations

27
Abstraction of surface expressions

28
Info-PubMed An interactive IE system and an efficient PubMed search tool, helping users to find information about biomedical entities such as genes, proteins,and the interactions between them. System components MEDIE Extraction of protein-protein interactions Multi-window interface on a browser

29
Info-PubMed

30
KLEIO Semantically enriched information retrieval system for biology Offers textual and metadata searches across MEDLINE Provides enhanced searching functionality by leveraging terminology management technologies http://www.nactem.ac.uk/software/kleio/

31
KLEIO architecture

32
32 different ABC acronyms in MEDLINE...

33
Exploit named entity recognition to focus search

34
See detail, link to BioDBs and other resources

35
Refine query to human

36
FACTA: finding associated concepts

37
Nicotine and AD

38
Challenges for TM in Biology Terminology, terminology, terminology Named entities: same name, different species Linking forms with concepts Event extraction Corpus annotation (who does it with what accuracy and can they agree) (scientific argumentation, opinion mining)
 (scientific argumentation, opinion mining)")
39
Tackling terminology: BOOTStrep EC collaborative project: Resource building for TM Reusable lexical, terminological, conceptual resources for biological domain (gene regulation) Tool-based methodology to create and maintain resources as fully automatically as possible Process BioDBs for terms then find variants in text Relations (including facts) among entities extracted by side-effect of text analysis Raw fact store built up as process texts for resource building
 Tool-based methodology to create and maintain resources as fully automatically as possible Process BioDBs for terms then find variants in text Relations (including facts) among entities extracted by side-effect of text analysis Raw fact store built up as process texts for resource building")
40
BOOTStrep BioLexicon TypeEntriesVariants cell8421,400 chemicals19,637106,302 enzymes4,01611,674 diseases19,45733,161 genes/proteins1,640,6083,048,920 GO concepts25,21981,642 molecular role concepts8,85060,408 operons2,6723,145 protein complexes2,1042,647 protein domains16,84033,880 SO concepts1,4312,326 species482,992669,481 Transcr. factors160795

41
BOOTStrep BioLexicon Also contains Terminological verbs (759 base, 4,556 inflected forms) Terminological adjectives (1,258) Terminological adverbs (130) Nominalized verbs (1,771) Verbs have syntactic and semantic frames (entities they occur with) allows finer-grained analysis All items have associated linguistic info
 Terminological adjectives (1,258) Terminological adverbs (130) Nominalized verbs (1,771) Verbs have syntactic and semantic frames (entities they occur with) allows finer-grained analysis All items have associated linguistic info")
42
Challenge: Complex analysis currently requires highly customised solutions

43
Challenge: Dealing with full text Need to be able to handle very large amounts of text Other issues besides linguistic/NLP ones (already hard) Efficiency, scalability, distributed processing Porting TM tools to UK and European Grid environment
 Efficiency, scalability, distributed processing Porting TM tools to UK and European Grid environment")
44
Need for processing full texts Will allow researchers to discover hidden relationships from text that were not known before an abstract’s length is on average 3% of the entire article an abstract includes only 20% of the useful information that can be learned from text

45
Parallelising TM TM applications are data independent Scale linearly in an ideal world HPC implementation Scaled linearly to 100 processors Porting to DEISA to scale over 1000s processors to process TBs of data in reasonable time

46
TM of full texts for UK PubMed Central (UKPMC) Free archive of life sciences journals British Library, European Bioinformatics Institute & UManchester (NaCTeM, Mimas) Phase 3 tasks: integration of UKPMC in biomedical DB infrastructure with TM solutions for improved search and knowledge discovery
 Free archive of life sciences journals British Library, European Bioinformatics Institute & UManchester (NaCTeM, Mimas) Phase 3 tasks: integration of UKPMC in biomedical DB infrastructure with TM solutions for improved search and knowledge discovery")
47
NaCTeM in UKPMC TM “behind the scenes” on full texts Named entity recognition Link entities in texts to bioDB entries Fact extraction E.g., protein-protein interactions Add extracted info as semantic metadata Index for efficient access Semantic search capability Based on user needs, evaluation workshops

48
Challenge: Tool interoperability A plethora of NLP tools out there... Part-of-speech tagging: TnT tagger, Tree tagger, SVM Tool, GENIA… Chunking: YamCha, GENIA, … Named entity recognition: LingPipe, ABNER, Stanford NE Recognizer, GENIA, … Syntactic parsing: Enju, OpenNLP, Charniak parser, Collins parser… Semantic role labeling Shalmaneser Co-reference resolution...

49
So where is the problem? Increasing contents of annotation Increasing layers of annotation More applications of annotation Various annotation schemes tokensphrasesentities Predicate-arguments morphology syntaxsemanticsRDF Linguistics NLP Text Mining Semantic web TEIPTBXCESSciXML ?

50
Architecture for interoperability A good architecture should Accommodate various annotation schemas, formats of NLP tools. Provide a common exchange annotation schema. Facilitate easy communication between NLP tools. Extend to incorporate new tools Exchange schema Term extractor POS tagger Chunker Parser + tools UIMA PLATFORM http://incubator.apache.org/uima/

51
Uses of our tools and services Searching Metadata creation Controlled vocabularies Ontology building Data integration Linking repositories Database curation Reviewing Gene – disease mining Enriching pathway models Indexing Document classification …

52
NaCTeM phase II (2008-2011) TM supporting service provision Web Services Embedding TM within workflows Adaptive learning Integration of data / text mining Issues Full paper processing open access collections IPR in data derived via text mining Interoperability Education and training
 TM supporting service provision Web Services Embedding TM within workflows Adaptive learning Integration of data / text mining Issues Full paper processing open access collections IPR in data derived via text mining Interoperability Education and training")
53
NaCTeM phase II (2008-2011) Service exemplars Intelligent semantic searching for construction of biological networks Support for qualitative data analysis for social sciences Intelligent semantic search of gene-disease associations for health e-Research and e-Science Knowledge discovery Collaborative research E-publishing Personalised searching
 Service exemplars Intelligent semantic searching for construction of biological networks Support for qualitative data analysis for social sciences Intelligent semantic search of gene-disease associations for health e-Research and e-Science Knowledge discovery Collaborative research E-publishing Personalised searching")
54
Research feeding into services or adding to knowledge REFINE (BBSRC): enriching SBML models and integration of TM with visualisation ONDEX (BBSRC): aiding data integration Disease association mining (Pfizer, NHS)
: enriching SBML models and integration of TM with visualisation ONDEX (BBSRC): aiding data integration Disease association mining (Pfizer, NHS)")
55
ONDEX (BBSRC 2008-2011)
 ")
56
Acknowledgments Text Mining Team: 14 members NaCTeM funding agencies: Wellcome Trust Close collaboration with University of Tokyo

57
Acknowledgements User group Systems Biology Centres Middleware provider http://taverna.sourceforge.net http://taverna.sourceforge.net Usability and evaluation Service provision MIMAS

58
Further reading Visit out site at www.nactem.ac.uk for TM briefing paper and other publications on our workwww.nactem.ac.uk Book: Ananiadou, S. & McNaught, J. (eds) (2006) Text Mining for Biology and Biomedicine. Norwood, MA: Artech House.
 (2006) Text Mining for Biology and Biomedicine. Norwood, MA: Artech House..")
Similar presentations