Download presentation
Presentation is loading. Please wait.

1
Chapter 17 Shared-Memory Programming

2
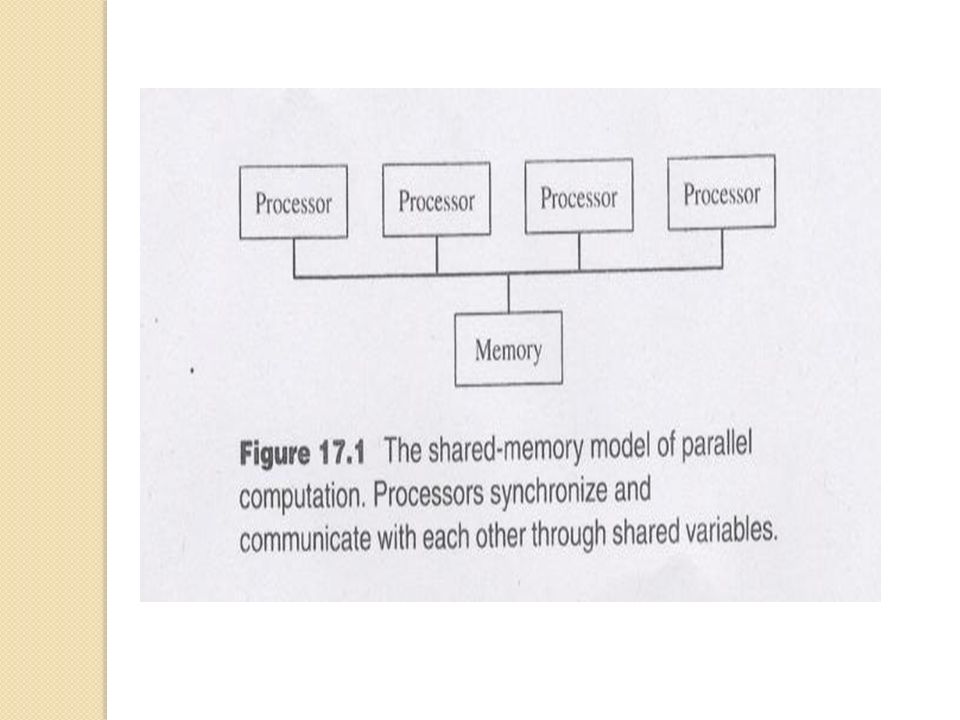
Introduction OpenMP is an application programming interface (API) for parallel programming on multiprocessors. It consists of a set of compiler directives and a library of support functions.

4
fork/join parallelism

5
Incremental parallelization – the process of transforming a sequential program into a parallel program one block of code at a time.

7
OpenMP compiler directives parallel for parallel for sections parallel sections critical single

8
OpenMP functions int omp_get_num_procs (void) int omp_get_num_threads (void) int omp_get_thread_num (void) void omp_set_num_threads (int t)
 int omp_get_num_threads (void) int omp_get_thread_num (void) void omp_set_num_threads (int t)")
9
Parallel for Loops for (i=first; I < size; I +=prime) marked [i] = 1;
![Parallel for Loops for (i=first; I < size; I +=prime) marked [i] = 1;](http://images.slideplayer.com/23/6540750/slides/slide_9.jpg "Parallel for Loops for (i=first; I < size; I +=prime) marked [i] = 1;")
10
parallel for Pragma Pragma: a compiler directive in C or C++ is called a pragma. It is short for “pragmatic information”. Syntax: #pragma omp e.g. #pragma omp parallel for for (i=first; I < size; I +=prime) marked [i] = 1;
 marked [i] = 1;.")
12
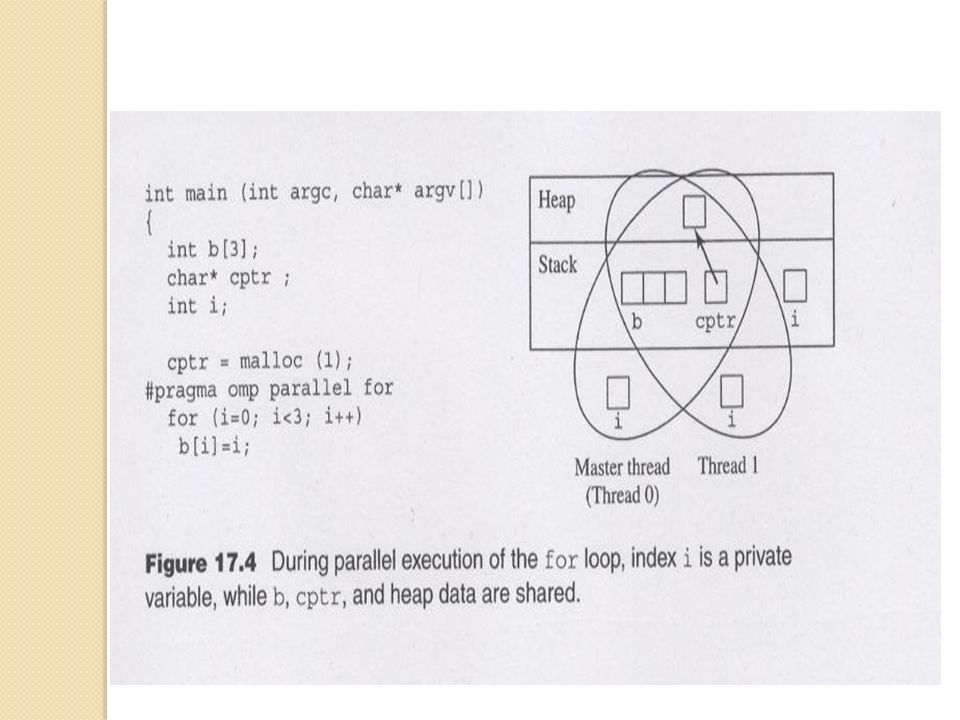
Execution context Every thread has its own execution context: an address space containing all of variables the thread may access. The execution context includes static variables, dynamically allocated data structures in the heap, and variables on the run-time stack. Shared variable Private variable

14
Declaring Private Variables private Clause (A clause is an optional component to a pragma) e.g. private ( ) # pragma omp parallel for private (j) for (i=0; i <= BLOCK_SIZE(id,p,n); i++) for (j=0; j < n; j++) a[i][j] = MIN (a[i][j], a[i][k] + tmp[j]);
 # pragma omp parallel for private (j) for (i=0; i <= BLOCK_SIZE(id,p,n); i++) for (j=0; j < n; j++) a[i][j] = MIN (a[i][j], a[i][k] + tmp[j]);.")
15
firstprivate Clause x[0] = complex_function(); #pragma omp parallel for private (j) firstprivate (x) for (i =0; i < n; i++) for (j = 1; j < 4; j++) x[j] = g(i, x[j-1]); answer [i] = x[1] – x[3];
![firstprivate Clause x[0] = complex_function(); #pragma omp parallel for private (j) firstprivate (x) for (i =0; i < n; i++) for (j = 1; j < 4; j++) x[j] = g(i, x[j-1]); answer [i] = x[1] – x[3];](http://images.slideplayer.com/23/6540750/slides/slide_15.jpg "firstprivate Clause x[0] = complex_function(); #pragma omp parallel for private (j) firstprivate (x) for (i =0; i < n; i++) for (j = 1; j < 4; j++) x[j] = g(i, x[j-1]); answer [i] = x[1] – x[3];")
16
lastprivate Clause #pragma omp parallel for private (j) lastprivate (x) For (I = 0; I < n; i++) { x[0] = 1.0; for (j = 1; j < 4; j++) x[j] = x[j-1] * (I + 1); sum_of_powers[i] = x[0] + x[1] + x[2] + x[3]; } N_cubed = x [3];
![lastprivate Clause #pragma omp parallel for private (j) lastprivate (x) For (I = 0; I < n; i++) { x[0] = 1.0; for (j = 1; j < 4; j++) x[j] = x[j-1] * (I + 1); sum_of_powers[i] = x[0] + x[1] + x[2] + x[3]; } N_cubed = x [3];](http://images.slideplayer.com/23/6540750/slides/slide_16.jpg "lastprivate Clause #pragma omp parallel for private (j) lastprivate (x) For (I = 0; I < n; i++) { x[0] = 1.0; for (j = 1; j < 4; j++) x[j] = x[j-1] * (I + 1); sum_of_powers[i] = x[0] + x[1] + x[2] + x[3]; } N_cubed = x [3];")
17
Critical Sections #pragma omp parallel for private (x) for (i = 0; i < n; i++) { x = (i+0.5)/n; area += 4.0/(1.0 + x*x); /* Race Condition! */ } pi = area/n;

19
#pragma omp parallel for private (x) for (i = 0; i < n; i++) { x = (i+0.5)/n; #pragma omp critical area += 4.0/(1.0 + x*x); } pi = area/n;
 for (i = 0; i < n; i++) { x = (i+0.5)/n; #pragma omp critical area += 4.0/(1.0 + x*x); } pi = area/n;")
20
Reductions Syntax: reduction ( : ) #pragma omp parallel for private (x) reduction (+:area) for (i = 0; i < n; i++) { x = (i+0.5)/n; area += 4.0/(1.0 + x*x); } pi = area/n;
 #pragma omp parallel for private (x) reduction (+:area) for (i = 0; i < n; i++) { x = (i+0.5)/n; area += 4.0/(1.0 + x*x); } pi = area/n;")
22
Performance Improvement Inverting Loops e.g. for (i = 1; i < m; i++) for (j = 0; j < n; j++) a[i][j] = 2 * a [i-1][j];
 for (j = 0; j < n; j++) a[i][j] = 2 * a [i-1][j];.")
24
#pragma parallel for private (i) for (j = 0; j < n; j++) for (i = 1; i < m; i++) a[i][j] = 2 * a [i-1][j];
![#pragma parallel for private (i) for (j = 0; j < n; j++) for (i = 1; i < m; i++) a[i][j] = 2 * a [i-1][j];](http://images.slideplayer.com/23/6540750/slides/slide_24.jpg "#pragma parallel for private (i) for (j = 0; j < n; j++) for (i = 1; i < m; i++) a[i][j] = 2 * a [i-1][j];")
25
Conditionally Executing Loops #pragma omp parallel for private (x) reduction (+:area) if (n > 5000) for (i = 0; i < n; i++) { x = (i+0.5)/n; area += 4.0/(1.0 + x*x); } pi = area/n;
 reduction (+:area) if (n > 5000) for (i = 0; i < n; i++) { x = (i+0.5)/n; area += 4.0/(1.0 + x*x); } pi = area/n;")
27
Scheduling Loops Syntax: Schedule ( [, ]) Schedule (static): A static allocation of about n/t contiguous iterations to each thread. Schedule (static, C): An interleaved allocation of chunks to tasks. Each chunk contains C contiguous iterations.
![Scheduling Loops Syntax: Schedule ( [, ]) Schedule (static): A static allocation of about n/t contiguous iterations to each thread.](http://images.slideplayer.com/23/6540750/slides/slide_27.jpg "Schedule (static, C): An interleaved allocation of chunks to tasks. Each chunk contains C contiguous iterations..")
28
Schedule (dynamic) : Iterations are dynamically allocated, one at a time, to threads. Schedule (dynamic, C) : A dynamic allocation of C iterations at a time to the tasks. Schedule (guided, C) : A dynamic allocation of iterations to tasks using the guided self-scheduling heuristic. Guided self-scheduling begins by allocating a large chunk size to each task and responds to further requests for chunks by allocating chunks of decreasing size. The size of the chunks decreases exponentially to a minimum chunk size of C.
 : A dynamic allocation of C iterations at a time to the tasks. Schedule (guided, C) : A dynamic allocation of iterations to tasks using the guided self-scheduling heuristic. Guided self-scheduling begins by allocating a large chunk size to each task and responds to further requests for chunks by allocating chunks of decreasing size. The size of the chunks decreases exponentially to a minimum chunk size of C..")
29
Schedule(guided): Guided self-scheduling with a minimum chunk size of 1. Schedule(runtime): The schedule type is chosen at run-time based on the value of environment variable OMP_SCHEDULE. e.g. setenv OMP_SCHEDULE “static, 1” would set the run-time schedule to be an interleaved allocation.
: The schedule type is chosen at run-time based on the value of environment variable OMP_SCHEDULE. e.g. setenv OMP_SCHEDULE static, 1 would set the run-time schedule to be an interleaved allocation..")
30
More General Data Parallelism

32
parallel Pragama

33
for Pragama

34
single Pragama

35
nowait Clause

36
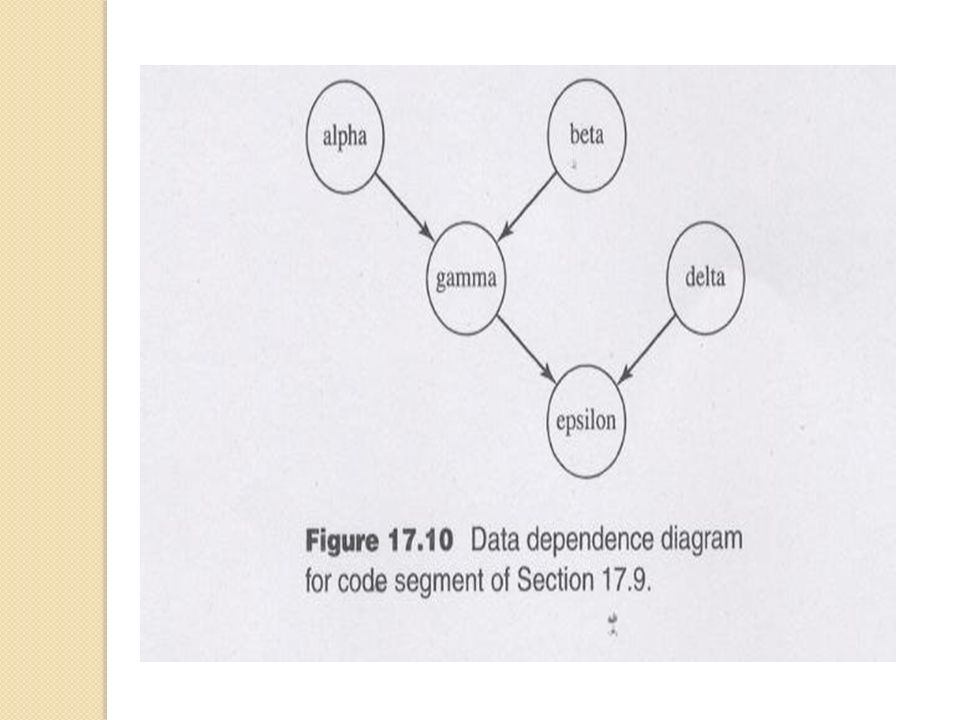
Functional Parallelism e.g. v = alpha(); w = beta(); x = gamma (v, w); y = delta (); printf (“%6.2f\n”, epsilon(x,y));
; w = beta(); x = gamma (v, w); y = delta (); printf ( %6.2f\n , epsilon(x,y));.")
38
#pragma omp parallel sections { #pragma omp section /* This pragma optional */ v = alpha(); #pragma omp section w = beta(); #pragma omp section y = delta (); } x = gamma (v, w); printf (“%6.2f\n”, epsilon(x,y));
; #pragma omp section w = beta(); #pragma omp section y = delta (); } x = gamma (v, w); printf ( %6.2f\n , epsilon(x,y));")
39
#pragma omp parallel { #pragma omp sections { #pragma omp section v = alpha(); #pragma omp section w = beta(); } #pragma omp sections { #pragma omp section x = gamma(v,w); #pragma omp section y = delta(); } printf (“%6.2f\n”, epsilon(x,y));
; #pragma omp section w = beta(); } #pragma omp sections { #pragma omp section x = gamma(v,w); #pragma omp section y = delta(); } printf ( %6.2f\n , epsilon(x,y));")
41
Example : Hello world Write a multithreaded program that prints “hello world”. #include “omp.h” void main() { #pragma omp parallel { int ID = 0; printf(“ hello(%d) ”, ID); printf(“ world(%d) \n”, ID); } }
 { #pragma omp parallel { int ID = 0; printf( hello(%d) , ID); printf( world(%d) \n , ID); } }.")
42
Example : Hello world Write a multithreaded program where each thread prints “hello world”. #include “omp.h” void main() { #pragma omp parallel { int ID = omp_get_thread_num(); printf(“ hello(%d) ”, ID); printf(“ world(%d) \n”, ID); } } OpenMP include file Parallel region with default number of threads End of the Parallel region Runtime library function to return a thread ID. Sample Output: hello(1) hello(0) world(1) world(0) hello (3) hello(2) world(3) world(2)
 { #pragma omp parallel { int ID = omp_get_thread_num(); printf( hello(%d) , ID); printf( world(%d) \n , ID); } } OpenMP include file Parallel region with default number of threads End of the Parallel region Runtime library function to return a thread ID. Sample Output: hello(1) hello(0) world(1) world(0) hello (3) hello(2) world(3) world(2).")
43
Experimentation Write a function that using sequential implementation of the matrix times vector product in C. Write a function that using OpenMP /MPI implementation of the matrix times vector product in C. Comparing the performance of the two functions.

Similar presentations










 Adapted from: o “MPI-Message.>")
![Open[M]ulti[P]rocessing Pthreads: Programmer explicitly define thread behavior openMP: Compiler and system defines thread behavior Pthreads: Library independent.](/14/4193414/big_thumb.jpg "Open[M]ulti[P]rocessing Pthreads: Programmer explicitly define thread behavior openMP: Compiler and system defines thread behavior Pthreads: Library independent.>")












 AE 216, Mon/Thurs 2-3:20 p.m. Pthreads (reading Chp 7.10) Prof. Chris Carothers Computer.>")


