Download presentation
Presentation is loading. Please wait.

1
Google MapReduce Simplified Data Processing on Large Clusters Jeff Dean, Sanjay Ghemawat Google, Inc. Presented by Conroy Whitney 4 th year CS – Web Development http://labs.google.com/papers/mapreduce.html

2
Outline Motivation MapReduce Concept Map? Reduce? Example of MapReduce problem Reverse Web-Link Graph MapReduce Cluster Environment Lifecycle of MapReduce operation Optimizations to MapReduce process Conclusion MapReduce in Googlicious Action

3
Motivation: Large Scale Data Processing Many tasks composed of processing lots of data to produce lots of other data Want to use hundreds or thousands of CPUs... but this needs to be easy! MapReduce provides User-defined functions Automatic parallelization and distribution Fault-tolerance I/O scheduling Status and monitoring

4
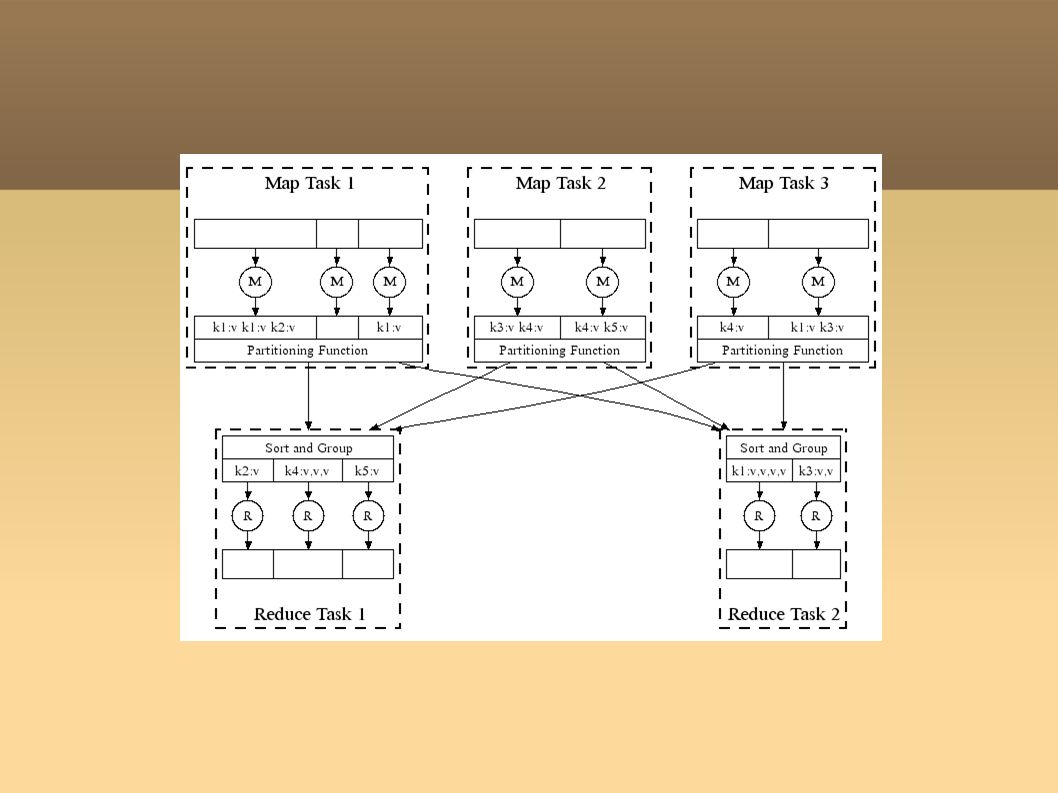
Programming Concept Map Perform a function on individual values in a data set to create a new list of values Example: square x = x * x map square [1,2,3,4,5] returns [1,4,9,16,25] Reduce Combine values in a data set to create a new value Example: sum = (each elem in arr, total +=) reduce [1,2,3,4,5] returns 15 (the sum of the elements)
![Programming Concept Map Perform a function on individual values in a data set to create a new list of values Example: square x = x * x map square [1,2,3,4,5] returns [1,4,9,16,25] Reduce Combine values in a data set to create a new value Example: sum = (each elem in arr, total +=) reduce [1,2,3,4,5] returns 15 (the sum of the elements)](http://images.slideplayer.com/22/6409305/slides/slide_4.jpg "Programming Concept Map Perform a function on individual values in a data set to create a new list of values Example: square x = x * x map square [1,2,3,4,5] returns [1,4,9,16,25] Reduce Combine values in a data set to create a new value Example: sum = (each elem in arr, total +=) reduce [1,2,3,4,5] returns 15 (the sum of the elements)")
5
Example: Reverse Web-Link Graph Find all pages that link to a certain page Map Function Outputs pairs for each link to a target URL found in a source page For each page we know what pages it links to Reduce Function Concatenates the list of all source URLs associated with a given target URL and emits the pair: For a given web page, we know what pages link to it

6
Additional Examples Distributed grep Distributed sort Term-Vector per Host Web Access Log Statistics Document Clustering Machine Learning Statistical Machine Translation

7
Performance Boasts Distributed grep 10 10 100-byte files (~1TB of data) 3-character substring found in ~100k files ~1800 workers 150 seconds start to finish, including ~60 seconds startup overhead Distributed sort Same files/workers as above 50 lines of MapReduce code 891 seconds, including overhead Best reported result of 1057 seconds for TeraSort benchmark
 3-character substring found in ~100k files ~1800 workers 150 seconds start to finish, including ~60 seconds startup overhead Distributed sort Same files/workers as above 50 lines of MapReduce code 891 seconds, including overhead Best reported result of 1057 seconds for TeraSort benchmark")
8
Typical Cluster 100s/1000s of Dual-Core, 2-4GB Memory Limited internal bandwidth Temporary storage on local IDE disks Google File System (GFS) Distributed file system for permanent/shared storage Job scheduling system Jobs made up of tasks Master-Scheduler assigns tasks to Worker machines
 Distributed file system for permanent/shared storage Job scheduling system Jobs made up of tasks Master-Scheduler assigns tasks to Worker machines")
9
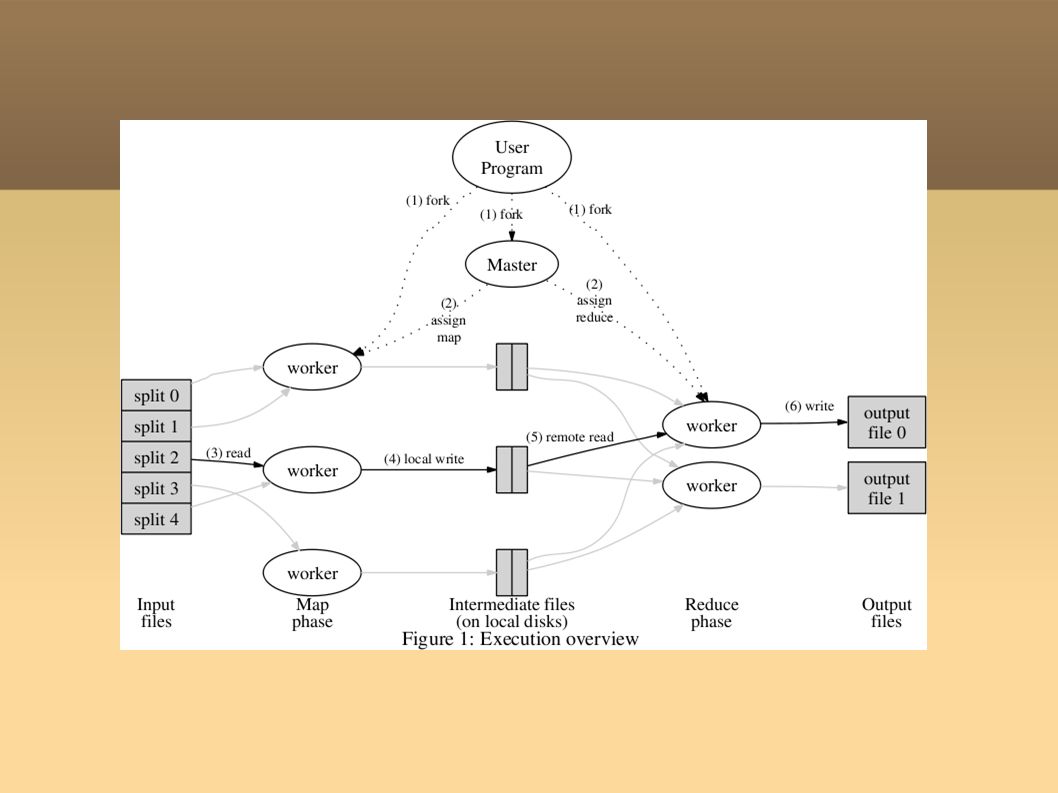
Execution Initialization Split input file into 64MB sections (GFS) Read in parallel by multiple machines Fork off program onto multiple machines One machine is Master Master assigns idle machines to either Map or Reduce tasks Master Coordinates data communication between map and reduce machines
 Read in parallel by multiple machines Fork off program onto multiple machines One machine is Master Master assigns idle machines to either Map or Reduce tasks Master Coordinates data communication between map and reduce machines")
11
Map-Machine Reads contents of assigned portion of input-file Parses and prepares data for input to map function (e.g. read from HTML) Passes data into map function and saves result in memory (e.g. ) Periodically writes completed work to local disk Notifies Master of this partially completed work (intermediate data)
 Passes data into map function and saves result in memory (e.g. ) Periodically writes completed work to local disk Notifies Master of this partially completed work (intermediate data).")
13
Reduce-Machine Receives notification from Master of partially completed work Retrieves intermediate data from Map-Machine via remote-read Sorts intermediate data by key (e.g. by target page) Iterates over intermediate data For each unique key, sends corresponding set through reduce function Appends result of reduce function to final output file (GFS)
 Iterates over intermediate data For each unique key, sends corresponding set through reduce function Appends result of reduce function to final output file (GFS).")
15
Worker Failure Master pings workers periodically Any machine who does not respond is considered “dead” Both Map- and Reduce-Machines Any task in progress gets needs to be re-executed and becomes eligible for scheduling Map-Machines Completed tasks are also reset because results are stored on local disk Reduce-Machines notified to get data from new machine assigned to assume task

16
Skipping Bad Records Bugs in user code (from unexpected data) cause deterministic crashes Optimally, fix and re-run Not possible with third-party code When worker dies, sends “last gasp” UDP packet to Master describing record If more than one worker dies over a specific record, Master issues yet another re-execute command Tells new worker to skip problem record
 cause deterministic crashes Optimally, fix and re-run Not possible with third-party code When worker dies, sends last gasp UDP packet to Master describing record If more than one worker dies over a specific record, Master issues yet another re-execute command Tells new worker to skip problem record")
17
Backup Tasks Some “Stragglers” not performing optimally Other processes demanding resources Bad Disks (correctable errors) Slow down I/O speeds from 30MB/s to 1MB/s CPU cache disabled ?! Near end of phase, schedule redundant execution of in-process tasks First to complete “wins”

18
Locality Network Bandwidth scarce Google File System (GFS) Around 64MB file sizes Redundant storage (usually 3+ machines) Assign Map-Machines to work on portions of input-files which they already have on local disk Read input file at local disk speeds Without this, read speed limited by network switch
 Around 64MB file sizes Redundant storage (usually 3+ machines) Assign Map-Machines to work on portions of input-files which they already have on local disk Read input file at local disk speeds Without this, read speed limited by network switch")
19
Conclusion Complete rewrite of the production indexing system 20+ TB of data indexing takes 5-10 MapReduce operations indexing code is simpler, smaller, easier to understand Fault Tolerance, Distribution, Parallelization hidden within MapReduce library Avoids extra passes over the data Easy to change indexing system Improve performance of indexing process by adding new machines to cluster

Similar presentations

>")








 OSDI 2004 Shimin Chen DISC Reading Group.>")









