Download presentation
Presentation is loading. Please wait.

1
Christopher D. Carothers
ROSS: Parallel Discrete-Event Simulations on Near Petascale Supercomputers Christopher D. Carothers Department of Computer Science Rensselaer Polytechnic Institute Sponsors: NSF CAREER, NeTS, PetaApps, ANL/ALCF

2
Motivation Why Parallel Discrete-Event Simulation (DES)?
Large-scale systems are difficult to understand Analytical models are often constrained Parallel DES simulation offers: Dramatically shrinks model’s execution-time Prediction of future “what-if” systems performance Potential for real-time decision support Minutes instead of days Analysis can be done right away Example models: national air space (NAS), ISP backbone(s), distributed content caches, next generation supercomputer systems. After networking. Need nms after main motivation is to advance simulations Why do we need simulation Code red firewall, prototyping and rapid development.
, ISP backbone(s), distributed content caches, next generation supercomputer systems. After networking. Need nms after main motivation is to advance simulations Why do we need simulation Code red firewall, prototyping and rapid development.")
3
Ex: Movies over the Internet
Suppose we want to model 1 million home ISP customers downloading a 2 GB movie How long to compute? Assume a nominal 100K ev/sec seq. simulator Assume on avg. each packet takes 8 hops 2GB movies yields 2 trillion 1K data packets. @ 8 hops yields 16+ trillion events 16+ trillion 100K ev/sec Over 1,900 days!!! Or 5+ years!!! Need massively parallel simulation to make tractable

4
Outline Intro to DES Time Warp and other PDES Schemes
Reverse Computation Blue Gene/L & /P ROSS Implementation ROSS Performance Results PHOLD & PCS Observations on PDES Performance Future Directions

5
Discrete Event Simulation (DES)
Discrete event simulation: computer model for a system where changes in the state of the system occur at discrete points in simulation time. Fundamental concepts: system state (state variables) state transitions (events) A DES computation can be viewed as a sequence of event computations, with each event computation is assigned a (simulation time) time stamp Each event computation can modify state variables schedule new events
 state transitions (events) A DES computation can be viewed as a sequence of event computations, with each event computation is assigned a (simulation time) time stamp. Each event computation can. modify state variables. schedule new events.")
6
DES Computation Unprocessed events are stored in a pending list
example: air traffic at an airport events: aircraft arrival, landing, departure arrival 8:00 schedules processed event current event unprocessed event departure 9:15 arrival 9:30 landed 8:05 schedules simulation time Unprocessed events are stored in a pending list Events are processed in time stamp order

7
Discrete Event Simulation System
model of the physical system Simulation Application state variables code modeling system behavior I/O and user interface software Simulation Executive event list management managing advances in simulation time calls to schedule events calls to event handlers independent of the simulation application

8
Event-Oriented World View
Event handler procedures state variables Arrival Event { … } Landed Event { … } Departure Event { … } Integer: InTheAir; Integer: OnTheGround; Boolean: RunwayFree; Simulation application Pending Event List (PEL) 9:00 9:16 10:10 Now = 8:45 Simulation executive Event processing loop While (simulation not finished) E = smallest time stamp event in PEL Remove E from PEL Now := time stamp of E call event handler procedure
 9:00. 9:16. 10:10. Now = 8:45. Simulation executive. Event processing loop. While (simulation not finished) E = smallest time stamp event in PEL. Remove E from PEL. Now := time stamp of E. call event handler procedure.")
9
Ex: Air traffic at an Airport
Model aircraft arrivals and departures, arrival queueing Single runway model; ignores departure queueing R = time runway is used for each landing aircraft (const) G = time required on the ground before departing (const) State Variables Now: current simulation time InTheAir: number of aircraft landing or waiting to land OnTheGround: number of landed aircraft RunwayFree: Boolean, true if runway available Model Events Arrival: denotes aircraft arriving in air space of airport Landed: denotes aircraft landing Departure: denotes aircraft leaving
 G = time required on the ground before departing (const) State Variables. Now: current simulation time. InTheAir: number of aircraft landing or waiting to land. OnTheGround: number of landed aircraft. RunwayFree: Boolean, true if runway available. Model Events. Arrival: denotes aircraft arriving in air space of airport. Landed: denotes aircraft landing. Departure: denotes aircraft leaving.")
10
Arrival Events R = time runway is used for each landing aircraft
New aircraft arrives at airport. If the runway is free, it will begin to land. Otherwise, the aircraft must circle, and wait to land. R = time runway is used for each landing aircraft G = time required on the ground before departing Now: current simulation time InTheAir: number of aircraft landing or waiting to land OnTheGround: number of landed aircraft RunwayFree: Boolean, true if runway available Arrival Event: InTheAir := InTheAir+1; If (RunwayFree) RunwayFree:=FALSE; Schedule Landed Now + R;
 RunwayFree:=FALSE; Schedule Landed Now + R;")
11
Landed Event An aircraft has completed its landing.
R = time runway is used for each landing aircraft G = time required on the ground before departing Now: current simulation time InTheAir: number of aircraft landing or waiting to land OnTheGround: number of landed aircraft RunwayFree: Boolean, true if runway available Landed Event: InTheAir:=InTheAir-1; OnTheGround:=OnTheGround+1; Schedule Departure Now + G; If (InTheAir>0) Schedule Landed Now + R; Else RunwayFree := TRUE;
 Schedule Landed Now + R; Else. RunwayFree := TRUE;")
12
Departure Event An aircraft now on the ground departs for a new dest.
R = time runway is used for each landing aircraft G = time required on the ground before departing Now: current simulation time InTheAir: number of aircraft landing or waiting to land OnTheGround: number of landed aircraft RunwayFree: Boolean, true if runway available Departure Event: OnTheGround := OnTheGround - 1;

13
Execution Example R=3 G=4 State Variables InTheAir OnTheGround
Simulation Time State Variables RunwayFree InTheAir 1 2 3 4 5 6 7 8 9 10 11 true R=3 G=4 Time Event 1 Arrival F1 3 Arrival F2 Now=0 Processing: false 1 Time Event 4 Landed F1 3 Arrival F2 Arrival F1 Now=1 2 Time Event 4 Landed F1 Arrival F2 Now=3 Time Event Depart F2 Now=11 1 Time Event 11 Depart F2 Depart F1 Now=8 2 true Time Event 8 Depart F1 11 Depart F2 Landed F2 Now=7 1 Landed F1 Now=4 Time Event 8 Depart F1 7 Landed F2

14
Summary DES computation is sequence of event computations
Modify state variables Schedule new events DES System = model + simulation executive Data structures Pending event list to hold unprocessed events State variables Simulation time clock variable Program (Code) Main event processing loop Event procedures Events processed in time stamp order
 Main event processing loop. Event procedures. Events processed in time stamp order.")
15
Outline Intro to DES Time Warp and other PDES Schemes
Reverse Computation Blue Gene/L & /P ROSS Implementation ROSS Performance Results PHOLD & PCS Observations on PDES Performance Future Directions

16
parallel time-stepped simulation:
How to Synchronize Parallel Simulations? parallel time-stepped simulation: lock-step execution PE 1 PE 2 PE 3 barrier Virtual Time parallel discrete-event simulation: must allow for sparse, irregular event computations Problem: events arriving in the past Solution: Time Warp processed event “straggler” event

17
Local Control Mechanism: Global Control Mechanism:
Massively Parallel Discrete-Event Simulation Via Time Warp Local Control Mechanism: error detection and rollback Global Control Mechanism: compute Global Virtual Time (GVT) V i r t u a l T m e V i r t u a l T m e (1) undo state D’s (2) cancel “sent” events collect versions of state / events & perform I/O operations that are < GVT GVT LP 1 LP 2 LP 3 LP 1 LP 2 LP 3 processed event unprocessed event “straggler” event “committed” event
 V. i. r. t. u. a. l. T. m. e. V. i. r. t. u. a. l. T. m. e. (1) undo. state D’s. (2) cancel. sent events. collect versions. of state / events. & perform I/O. operations. that are < GVT. GVT. LP 1. LP 2. LP 3. LP 1. LP 2. LP 3. processed event. unprocessed event. straggler event. committed event.")
18
Whew …Time Warp sounds expensive are there other PDES Schemes?…
“Non-rollback” options: Called “Conservative” because they disallow out of order event execution. Deadlock Avoidance NULL Message Algorithm Deadlock Detection and Recovery

19
Deadlock Avoidance Using Null Messages
Null Message Algorithm (executed by each LP): Goal: Ensure events are processed in time stamp order and avoid deadlock WHILE (simulation is not over) wait until each FIFO contains at least one message remove smallest time stamped event from its FIFO process that event send null messages to neighboring LPs with time stamp indicating a lower bound on future messages sent to that LP (current time plus minimum transit time between airports) END-LOOP Variation: LP requests null message when FIFO becomes empty Fewer null messages Delay to get time stamp information
: Goal: Ensure events are processed in time stamp order and avoid deadlock. WHILE (simulation is not over) wait until each FIFO contains at least one message. remove smallest time stamped event from its FIFO. process that event. send null messages to neighboring LPs with time stamp indicating a lower bound on future messages sent to that LP (current time plus minimum transit time between airports) END-LOOP. Variation: LP requests null message when FIFO becomes empty. Fewer null messages. Delay to get time stamp information.")
20
The Time Creep Problem 9 8 JFK (waiting on ORD) ORD on SFO) SFO on JFK) 15 10 7 ORD: process time stamp 7 message 7 5.5 JFK: timestamp = 5.5 Null messages: 6.0 SFO: timestamp = 6.0 7.5 SFO: timestamp = 7.5 6.5 ORD: timestamp = 6.5 7.0 JFK: timestamp = 7.0 Five null messages to process a single event! Assume minimum delay between airports is 3 units of time JFK initially at time 5 0.5 Many null messages if minimum flight time is small!

21
Livelock Can Occur! Suppose the minimum delay between airports is zero! 9 8 JFK (waiting on ORD) 7 ORD on SFO) SFO on JFK) 15 10 5.0 5.0 5.0 5.0 Livelock: un-ending cycle of null messages where no LP can advance its simulation time There cannot be a cycle where for each LP in the cycle, an incoming message with time stamp T results in a new message sent to the next LP in the cycle with time stamp T (zero lookahead cycle)
 SFO. on JFK) Livelock: un-ending cycle of null messages where no LP can advance its simulation time. There cannot be a cycle where for each LP in the cycle, an incoming message with time stamp T results in a new message sent to the next LP in the cycle with time stamp T (zero lookahead cycle)")
22
Lookahead The null message algorithm relies on a “prediction” ability referred to as lookahead “ORD at simulation time 5, minimum transit time between airports is 3, so the next message sent by ORD must have a time stamp of at least 8” Lookahead is a constraint on LP’s behavior Link lookahead: If an LP is at simulation time T, and an outgoing link has lookahead Li, then any message sent on that link must have a time stamp of at least T+Li LP Lookahead: If an LP is at simulation time T, and has a lookahead of L, then any message sent by that LP must will have a time stamp of at least T+L Equivalent to link lookahead where the lookahead on each outgoing link is the same

23
Lookahead and the Simulation Model
Lookahead is clearly dependent on the simulation model could be derived from physical constraints in the system being modeled, such as minimum simulation time for one entity to affect another (e.g., a weapon fired from a tank requires L units of time to reach another tank, or maximum speed of the tank places lower bound on how soon it can affect another entity) could be derived from characteristics of the simulation entities, such as non-preemptable behavior (e.g., a tank is traveling north at 30 mph, and nothing in the federation model can cause its behavior to change over the next 10 minutes, so all output from the tank simulator can be generated immediately up to time “local clock + 10 minutes”) could be derived from tolerance to temporal inaccuracies (e.g., users cannot perceive temporal difference of 100 milliseconds, so messages may be timestamped 100 milliseconds into the future). simulations may be able to precompute when its next interaction with another simulation will be (e.g., if time until next interaction is stochastic, pre-sample random number generator to determine time of next interaction). Lookahead changes as LP topology changes which can have a profound impact on the performance of network models (wired or wireless).
 could be derived from characteristics of the simulation entities, such as non-preemptable behavior (e.g., a tank is traveling north at 30 mph, and nothing in the federation model can cause its behavior to change over the next 10 minutes, so all output from the tank simulator can be generated immediately up to time local clock + 10 minutes ) could be derived from tolerance to temporal inaccuracies (e.g., users cannot perceive temporal difference of 100 milliseconds, so messages may be timestamped 100 milliseconds into the future). simulations may be able to precompute when its next interaction with another simulation will be (e.g., if time until next interaction is stochastic, pre-sample random number generator to determine time of next interaction). Lookahead changes as LP topology changes which can have a profound impact on the performance of network models (wired or wireless).")
24
Why is Lookahead Important?
LP A LP B LP C LP D Logical Time problem: limited concurrency each LP must process events in time stamp order LTA possible message OK to process event not OK to process yet without lookahead possible message OK to process with lookahead LTA+LA Each LP A using logical time declares a lookahead value LA; the time stamp of any event generated by the LP must be ≥ LTA+ LA Lookahead is used in virtually all conservative synch. protocols Essential to allow concurrent processing of events Lookahead is necessary to allow concurrent processing of events with different time stamps (unless optimistic event processing is used)
")
25
Null Message Algorithm: Speed Up
toroid topology message density: 4 per LP 1 millisecond computation per event vary time stamp increment distribution ILAR=lookahead / average time stamp increment Conservative algorithms live or die by their lookahead!

26
Deadlock Detection & Recovery
Algorithm A (executed by each LP): Goal: Ensure events are processed in time stamp order: WHILE (simulation is not over) wait until each FIFO contains at least one message remove smallest time stamped event from its FIFO process that event END-LOOP No null messages Allow simulation to execute until deadlock occurs Provide a mechanism to detect deadlock Provide a mechanism to recover from deadlocks
: Goal: Ensure events are processed in time stamp order: WHILE (simulation is not over) wait until each FIFO contains at least one message. remove smallest time stamped event from its FIFO. process that event. END-LOOP. No null messages. Allow simulation to execute until deadlock occurs. Provide a mechanism to detect deadlock. Provide a mechanism to recover from deadlocks.")
27
Deadlock Recovery Deadlock recovery: identify “safe” events (events that can be processed w/o violating local causality), deadlock state Assume minimum delay between airports is 3 9 8 JFK (waiting on ORD) 7 ORD on SFO) 10 SFO on JFK) Which events are safe? Time stamp 7: smallest time stamped event in system Time stamp 8, 9: safe because of lookahead constraint Time stamp 10: OK if events with the same time stamp can be processed in any order No lookahead creep!
 7. ORD. on SFO) 10. SFO. on JFK) Which events are safe Time stamp 7: smallest time stamped event in system. Time stamp 8, 9: safe because of lookahead constraint. Time stamp 10: OK if events with the same time stamp can be processed in any order. No lookahead creep!")
28
Preventing LA Creep Using Next Event Time Info
9 8 JFK (waiting on ORD) 7 ORD on SFO) SFO on JFK) 15 10 Observation: smallest time stamped event is safe to process Lookahead creep avoided by allowing the synchronization algorithm to immediately advance to (global) time of the next event Synchronization algorithm must know time stamp of LP’s next event Each LP guarantees a logical time T such that if no additional events are delivered to LP with TS < T, all subsequent messages that LP produces have a time stamp at least T+L (L = lookahead)
 7. ORD. on SFO) SFO. on JFK) Observation: smallest time stamped event is safe to process. Lookahead creep avoided by allowing the synchronization algorithm to immediately advance to (global) time of the next event. Synchronization algorithm must know time stamp of LP’s next event. Each LP guarantees a logical time T such that if no additional events are delivered to LP with TS < T, all subsequent messages that LP produces have a time stamp at least T+L (L = lookahead)")
29
No Free Lunch for PDES! Time Warp State saving overheads
Null message algorithm Lookahead creep problem No zero lookahead cycles allowed Lookahead Essential for concurrent processing of events for conservative algorithms Has large effect on performance need to program it Deadlock Detection and Recovery Smallest time stamp event safe to process Others may also be safe (requires additional work to determine this) Use time of next event to avoid lookahead creep, but hard to compute at scale… Can we avoid some of these overheads and complexities??
 Use time of next event to avoid lookahead creep, but hard to compute at scale… Can we avoid some of these overheads and complexities")
30
Outline Intro to DES Time Warp and other PDES Schemes
Reverse Computation Blue Gene/L & /P ROSS Implementation ROSS Performance Results PHOLD & PCS Observations on PDES Performance Future Directions

31
Our Solution: Reverse Computation...
Use Reverse Computation (RC) automatically generate reverse code from model source undo by executing reverse code Delivers better performance negligible overhead for forward computation significantly lower memory utilization Original Code Compiler Modified Code Reverse Code
 automatically generate reverse code from model source. undo by executing reverse code. Delivers better performance. negligible overhead for forward computation. significantly lower memory utilization. Original Code. Compiler. Modified Code. Reverse Code.")
32
Ex: Simple Network Switch
Original N if( qlen < B ) qlen++ delays[qlen]++ else lost++ B on packet arrival... if( qlen < B ) b1 = 1 qlen++ delays[qlen]++ else b1 = 0 lost++ Forward if( b1 == 1 ) delays[qlen]-- qlen-- else lost-- Reverse
 qlen++ delays[qlen]++ else. lost++ B. on packet arrival... if( qlen < B ) b1 = 1. qlen++ delays[qlen]++ else. b1 = 0. lost++ Forward. if( b1 == 1 ) delays[qlen]-- qlen-- else. lost-- Reverse.")
33
Benefits of Reverse Computation
State size reduction from B+2 words to 1 word e.g. B=100 => 100x reduction! Negligible overhead in forward computation removed from forward computation moved to rollback phase Result significant increase in speed significant decrease in memory How?...

34
Beneficial Application Properties
1. Majority of operations are constructive e.g., ++, --, etc. 2. Size of control state < size of data state e.g., size of b1 < size of qlen, sent, lost, etc. 3. Perfectly reversible high-level operations gleaned from irreversible smaller operations e.g., random number generation

35
Rules for Automation... Generation rules, and upper-bounds on bit requirements for various statement types

36
Destructive Assignment...
Destructive assignment (DA): examples: x = y; x %= y; requires all modified bytes to be saved Caveat: reversing technique for DA’s can degenerate to traditional incremental state saving Good news: certain collections of DA’s are perfectly reversible! queueing network models contain collections of easily/perfectly reversible DA’s queue handling (swap, shift, tree insert/delete, … ) statistics collection (increment, decrement, …) random number generation (reversible RNGs)
: examples: x = y; x %= y; requires all modified bytes to be saved. Caveat: reversing technique for DA’s can degenerate to traditional incremental state saving. Good news: certain collections of DA’s are perfectly reversible! queueing network models contain collections of easily/perfectly reversible DA’s. queue handling (swap, shift, tree insert/delete, … ) statistics collection (increment, decrement, …) random number generation (reversible RNGs)")
37
Reversing an RNG? double RNGGenVal(Generator g) { long k,s; double u; u = 0.0; s = Cg [0][g]; k = s / 46693; s = * (s - k * 46693) - k * 25884; if (s < 0) s = s ; Cg [0][g] = s; u = u e-10 * s; s = Cg [1][g]; k = s / 10339; s = * (s - k * 10339) - k * 870; if (s < 0) s = s ; Cg [1][g] = s; u = u e-10 * s; if (u < 0) u = u + 1.0; s = Cg [2][g]; k = s / 15499; s = * (s - k * 15499) - k * 3979; if (s < 0.0) s = s ; Cg [2][g] = s; u = u e-10 * s; if (u >= 1.0) u = u - 1.0; s = Cg [3][g]; k = s / 43218; s = * (s - k * 43218) - k * 24121; if (s < 0) s = s ; Cg [3][g] = s; u = u e-10 * s; if (u < 0) u = u + 1.0; return (u); } Observation: k = s / is a Destructive Assignment Result: RC degrades to classic state-saving…can we do better?
![Reversing an RNG double RNGGenVal(Generator g) { long k,s; double u; u = 0.0; s = Cg [0][g]; k = s / 46693;](http://slideplayer.com/slide/6392115/22/images/37/Reversing+an+RNG+double+RNGGenVal%28Generator+g%29+%7B+long+k%2Cs%3B+double+u%3B+u+%3D+0.0%3B+s+%3D+Cg+%5B0%5D%5Bg%5D%3B+k+%3D+s+%2F+46693%3B.jpg "s = * (s - k * 46693) - k * 25884; if (s < 0) s = s ; Cg [0][g] = s; u = u e-10 * s; s = Cg [1][g]; k = s / 10339; s = * (s - k * 10339) - k * 870; if (s < 0) s = s ; Cg [1][g] = s; u = u e-10 * s; if (u < 0) u = u + 1.0; s = Cg [2][g]; k = s / 15499; s = * (s - k * 15499) - k * 3979; if (s < 0.0) s = s ; Cg [2][g] = s; u = u e-10 * s; if (u >= 1.0) u = u - 1.0; s = Cg [3][g]; k = s / 43218; s = * (s - k * 43218) - k * 24121; if (s < 0) s = s ; Cg [3][g] = s; u = u e-10 * s; if (u < 0) u = u + 1.0; return (u); } Observation: k = s / is a Destructive Assignment Result: RC degrades to classic state-saving…can we do better")
38
RNGs: A Higher Level View
The previous RNG is based on the following recurrence…. xi,n = aixi,n-1 mod mi where xi,n one of the four seed values in the Nth set, mi is one the four largest primes less than 231, and ai is a primitive root of mi. Now, the above recurrence is in fact reversible…. inverse of ai modulo mi is defined, bi = aimi-2 mod mi Using bi, we can generate the reverse recurrence as follows: xi,n-1 = bixi,n mod mi

39
Reverse Code Efficiency...
Property... Non-reversibility of indvidual steps DO NOT imply that the computation as a whole is not reversible. Can we automatically find this “higher-level” reversibility? Other Reversible Structures Include... Circular shift operation Insertion & deletion operations on trees (i.e., priority queues). Reverse computation is well-suited for small grain event models!
. Reverse computation is well-suited for small grain event models!")
40
RC Applications PDES applications include: B Non-DES include:
Wireless telephone networks Distributed content caches Large-scale Internet models – TCP over AT&T backbone Leverges RC “swaps” Hodgkin-Huxley neuron models Plasma physics models using PIC Non-DES include: Debugging PISA – Reversible instruction set architecture for low power computing Quantum computing if( qlen < B ) qlen++ delays[qlen]++ else lost++ B packet arrival... Original if( b1 == 1 ) delays[qlen]-- qlen-- lost-- Reverse b1 = 1 b1 = 0 Forward
 qlen++ delays[qlen]++ else. lost++ B. packet arrival... Original. if( b1 == 1 ) delays[qlen]-- qlen-- lost-- Reverse. b1 = 1. b1 = 0. Forward.")
41
Outline Intro to DES Time Warp and other PDES Schemes
Reverse Computation Blue Gene/L & /P ROSS Implementation ROSS Performance Results PHOLD & PCS Observations on PDES Performance Future Directions

42
Target Systems: Blue Gene/L & /P
Configuration: BG/L nodes: 2x700 MHz PPC cores BG/P nodes: 4x850 MHz PPC cores Dediciated compute and I/O nodes (32:1 or 8:1). 3-D torus P2P network Additional barrier, collective, I/O and ethernet networks Can partition system into dedicated slices from 32 nodes to whole systems Properties for GOOD scaling: Balanced architecture between network(s) and processor speed Exclusive access to network and process Exceptionally low OS jitter Collective overheads not adversely impacted at large nodes counts 1 rack of IBM Blue Gene/L
. 3-D torus P2P network. Additional barrier, collective, I/O and ethernet networks. Can partition system into dedicated slices from 32 nodes to whole systems. Properties for GOOD scaling: Balanced architecture between network(s) and processor speed. Exclusive access to network and process. Exceptionally low OS jitter. Collective overheads not adversely impacted at large nodes counts. 1 rack of IBM Blue Gene/L.")
43
Blue Gene /L Layout

44
Blue Gene/L SoC

45
Blue Gene/L Network

46
Blue Gene /P Layout

47
Blue Gene/P Architectual Highlights
Scaled performance via density and frequency increase 2x performance increase via doubling the processors per node. 1.2x from frequency increase: 700 MHz 850 MHz. Enhanced function 4-way SMP 3 modes: SMP/ DUAL/ VNM L2, L3 changed for SMP mode DMA for torus, remote put-get, user prog. memory prefetch Enhanced 64-bit performance counters via PPC450 core Double Hummer FPU and networks are the same..except.. Better Network 2.4x more bandwidth, lower latency Torus and Tree neworks 10x higher Ethernet I/O bandwidth 72K nodes in 72 racks for 1 PF peak performance Low power via aggressive power management

48
Blue Gene: L vs. P

49
Blue Gene /P Compute Card

50
Outline Intro to DES Time Warp and other PDES Schemes
Reverse Computation Blue Gene/L & /P ROSS Implementation ROSS Performance Results PHOLD & PCS Observations on PDES Performance Future Directions

51
Local Control Implementation
MPI_ISend/MPI_Irecv used to send/recv off core events Event & Network memory is managed directly. Pool is startup Event list keep sorted using a Splay Tree (logN) LP-2-Core mapping tables are computed and not stored to avoid the need for large global LP maps. Local Control Mechanism: error detection and rollback V i r t u a l T m e (1) undo state D’s (2) cancel “sent” events LP 1 LP 2 LP 3
 LP-2-Core mapping tables are computed and not stored to avoid the need for large global LP maps. Local Control Mechanism: error detection and rollback. V. i. r. t. u. a. l. T. m. e. (1) undo. state D’s. (2) cancel. sent events. LP 1. LP 2. LP 3.")
52
Global Control Implementation
GVT (kicks off when memory is low): Each core counts #sent, #recv Recv all pending MPI msgs. MPI_Allreduce Sum on (#sent - #recv) If #sent - #recv != 0 goto 2 Compute local core’s lower bound time-stamp (LVT). GVT = MPI_Allreduce Min on LVTs Algorithms needs efficient MPI collective LC/GC can be very sensitive to OS jitter Global Control Mechanism: compute Global Virtual Time (GVT) V i r t u a l T m e collect versions of state / events & perform I/O operations that are < GVT GVT LP 1 LP 2 LP 3 So, how does this translate into Time Warp performance on BG/L & BG/P?
: Each core counts #sent, #recv. Recv all pending MPI msgs. MPI_Allreduce Sum on (#sent - #recv) If #sent - #recv != 0 goto 2. Compute local core’s lower bound time-stamp (LVT). GVT = MPI_Allreduce Min on LVTs. Algorithms needs efficient MPI collective. LC/GC can be very sensitive to OS jitter. Global Control Mechanism: compute Global Virtual Time (GVT) V. i. r. t. u. a. l. T. m. e. collect versions. of state / events. & perform I/O. operations. that are < GVT. GVT. LP 1. LP 2. LP 3. So, how does this translate into Time Warp performance on BG/L & BG/P")
53
Outline Intro to DES Time Warp and other PDES Schemes
Reverse Computation Blue Gene/L & /P ROSS Implementation ROSS Performance Results PHOLD & PCS Observations on PDES Performance Future Directions

54
Performance Results: Setup
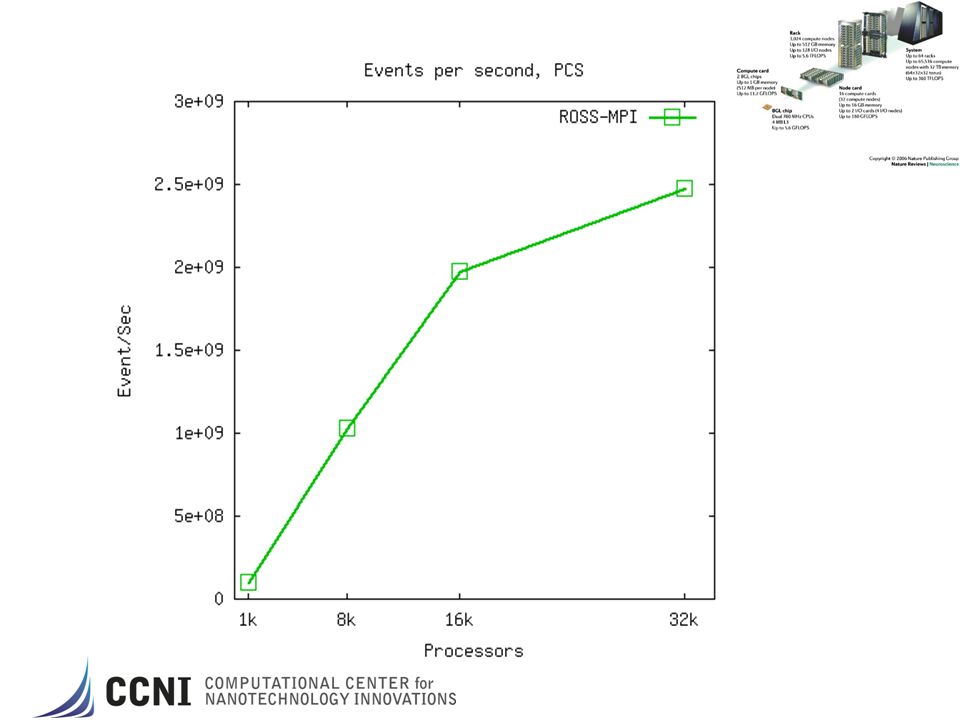
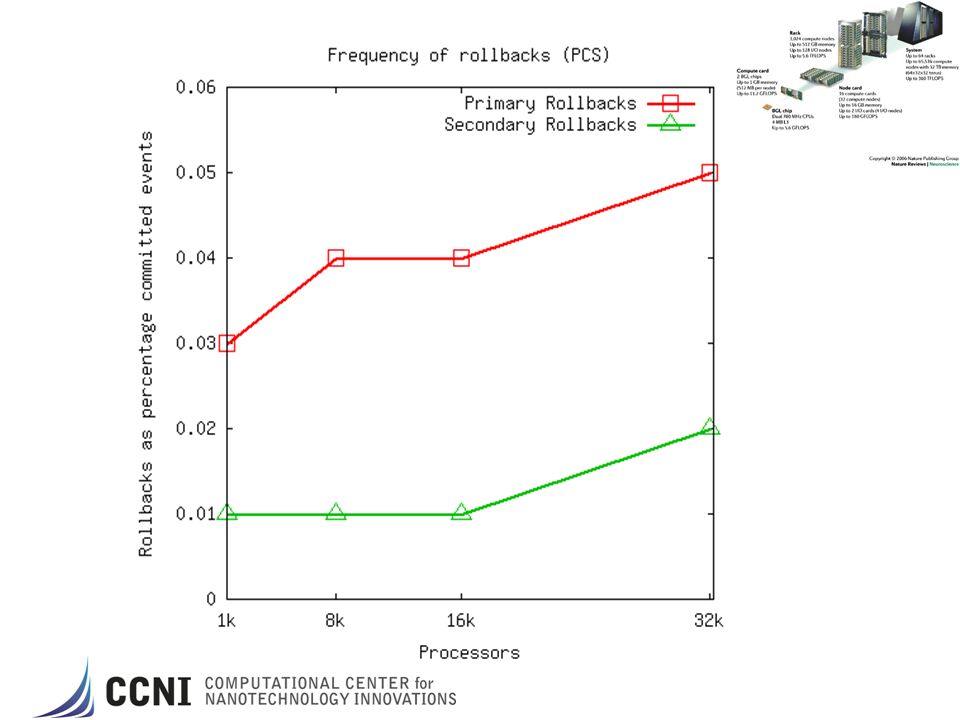
PHOLD Synthetic benchmark model 1024x1024 grid of LPs Each LP has 10 initial events Event routed randomly among all LPs based on a configurable “percent remote” parameter Time stamps are exponentially distributed with a mean of 1.0 (i.e., lookahead is 0). PCS – Personal Communications Services Network Cell phone call network model NxN grid Cell phone modeled as events, LPs are the “grid” region spaces. Call arrivals, service time and mobility are all exponentially distributed 4096x4096 grid of LPS w/ 10 initial cell phones per LP. Measures call blocking statistics ROSS parameters GVT_Interval number of times thru “scheduler” loop before computing GVT. Batch number of local events to process before “check” network for new events. Batch X GVT_Interval events processed per GVT epoch KPs kernel processes that hold the aggregated processed event lists for LPs to lower search overheads for fossil collection of “old” events. Send/Recv Buffers – number of network events for “sending” or “recv’ing”. Used as a flow control mechanism.
. PCS – Personal Communications Services Network. Cell phone call network model. NxN grid. Cell phone modeled as events, LPs are the grid region spaces. Call arrivals, service time and mobility are all exponentially distributed. 4096x4096 grid of LPS w/ 10 initial cell phones per LP. Measures call blocking statistics. ROSS parameters. GVT_Interval number of times thru scheduler loop before computing GVT. Batch number of local events to process before check network for new events. Batch X GVT_Interval events processed per GVT epoch. KPs kernel processes that hold the aggregated processed event lists for LPs to lower search overheads for fossil collection of old events. Send/Recv Buffers – number of network events for sending or recv’ing . Used as a flow control mechanism.")
55
PHOLD on 8192 BG/L cores

56
PHOLD on 8192 BG/L cores

57
PHOLD on 8192 BG/L cores

58
PHOLD on 8192 BG/L cores

59
7.5 billion ev/sec for 10% remote on 32,768 cores!!
Stable performance across processor configurations attributed to near noiseless OS…

60
12.27 billion ev/sec for 10% remote on 65,536 cores!!

61
Rollback Efficiency = 1 - Erb /Enet

64
Outline Intro to DES Parallel DES via Time Warp Reverse Computation
Blue Gene/L & /P Implementation Performance Results PHOLD & PCS Observations on PDES Performance Future Directions

65
History of PHOLD Performance
Year Author Event-Rate (ER) Processor Efficiency ER/(MHz * cores) 1995* Fujimoto 101,000 158 1996* Hao 95,000 238 2000* Carothers, Bauer, Pearce 375,000 186 2005* Chen & Szymanski 228 Million 221 2006* Bauer & Carothers 10 Million 63 2007 Perumalla 210 Million 37 2009 Bauer, Carothers & Holder 12.26 Billion 220 *These results are not completely comparable which explains large variation in event rate and processor efficiency
 Processor Efficiency. ER/(MHz * cores) 1995* Fujimoto. 101, * Hao. 95, * Carothers, Bauer, Pearce. 375, * Chen & Szymanski. 228 Million * Bauer & Carothers. 10 Million Perumalla. 210 Million Bauer, Carothers & Holder Billion *These results are not completely comparable which explains large variation in event rate and processor efficiency.")
66
Movies over the Internet Revisited
Suppose we want to model 1 million home ISP customers over AT&T downloading a 2 GB movie How long to compute with massively parallel DES? 16+ trillion 1 Billion ev/sec … ~4.5 hours!!

67
Observations… ROSS on Blue Gene indicates billion-events per second model are feasible today! Yields significant TIME COMPRESSION of current models.. LP to PE mapping less of a concern… Past systems where very sensitive to this ~90 TF systems can yield “Giga-scale” event rates. Tera-event models require teraflop systems. Assumes most of event processing time is spent in event-list management (splay tree enqueue/dequeue). Potential: 10 PF supercomputers will be able to model near peta-event systems 100 trillion to 1 quadrillion events in less than 1.4 to 14 hours Current “testbed” emulators don’t come close to this for Network Modeling and Simulation..
. Potential: 10 PF supercomputers will be able to model near peta-event systems. 100 trillion to 1 quadrillion events in less than 1.4 to 14 hours. Current testbed emulators don’t come close to this for Network Modeling and Simulation..")
68
Outline Intro to DES Parallel DES via Time Warp Reverse Computation
Blue Gene/L & /P Implementation Performance Results PHOLD & TLM Observations on PDES Performance Future Directions

69
Future Models Enabled by X-Scale Computing
Discrete “transistor” level models for whole multi-core architectures… Potential for more rapid improvements in processor technology… Model nearly whole U.S. Internet at packet level… Potential to radically improve overall QoS for all Model all C4I network/systems for a whole theatre of war faster than real-time many time over.. Enables the real-time“active” network control..

70
Future Models Enabled by X-Scale Computing
Realistic discrete model the human brain 100 billion neurons w/ 100 trillion synapes (e.g. connections – huge fan-out) Potential for several exa-events per run Detailed “discrete” agent-based model for every human on the earth for.. gobal economic modeling pandemic flu/disease modeling food / water / energy usage modeling…
 Potential for several exa-events per run. Detailed discrete agent-based model for every human on the earth for.. gobal economic modeling. pandemic flu/disease modeling. food / water / energy usage modeling…")
71
ROSS Website… GOTO: odin.cs.rpi.edu

Similar presentations