Download presentation
Presentation is loading. Please wait.

1
ROSS: Parallel Discrete-Event Simulations on Near Petascale Supercomputers Christopher D. Carothers Department of Computer Science Rensselaer Polytechnic Institute chrisc@cs.rpi.edu

2
2 Outline Motivation for PDES Overview of HPC Platforms ROSS Implementation Performance Results Summary

3
Motivation Why Parallel Discrete-Event Simulation (DES)? –Large-scale systems are difficult to understand –Analytical models are often constrained Parallel DES simulation offers: –Dramatically shrinks model’s execution-time –Prediction of future “what-if” systems performance –Potential for real-time decision support Minutes instead of days Analysis can be done right away –Example models: national air space (NAS), ISP backbone(s), distributed content caches, next generation supercomputer systems.
, ISP backbone(s), distributed content caches, next generation supercomputer systems..")
4
Model a 10 PF Supercomputer Suppose we want to model a 10 PF supercomputer at the MPI message level How long excute DES model? –10% flop rate 1 PF sustained –@.2 bytes/sec per flop @ 1% usage 2 TB/sec –@ 1K size MPI msgs 2 billion msgs per simulated second –@ 8 hops per msg 16 billion “events” per simulated second –@ 1000 simulated seconds 16 trillion events for DES model –No I/O included !! –Nominal seq. DES simulator 100K events/sec 16 trillion events @ 100K ev/sec 5+ years!!! Need massively parallel simulation to make tractable

5
Blue Gene /L Layout CCNI “fen” 32K cores/ 16 racks 12 TB / 8 TB usable RAM ~1 PB of disk over GPFS Custom OS kernel

6
Blue Gene /P Layout ALCF/ANL “Intrepid” 163K cores/ 40 racks ~80TB RAM ~8 PB of disk over GPFS Custom OS kernel

7
Blue Gene: L vs. P

8
How to Synchronize Parallel Simulations? parallel time-stepped simulation: lock-step execution PE 1 PE 2 PE 3 barrier Virtual Time parallel discrete-event simulation: must allow for sparse, irregular event computations PE 1 PE 2 PE 3 Virtual Time Problem: events arriving in the past Solution: Time Warp processed event “straggler” event

9
Massively Parallel Discrete-Event Simulation Via Time Warp Local Control Mechanism: error detection and rollback LP 1 LP 2 LP 3 VirtualTimeVirtualTime undo state ’s (2) cancel “sent” events Global Control Mechanism: compute Global Virtual Time (GVT) LP 1 LP 2 LP 3 VirtualTimeVirtualTime GVT collect versions of state / events & perform I/O operations that are < GVT processed event “straggler” event unprocessed event “committed” event
 cancel sent events Global Control Mechanism: compute Global Virtual Time (GVT) LP 1 LP 2 LP 3 VirtualTimeVirtualTime GVT collect versions of state / events & perform I/O operations that are < GVT processed event straggler event unprocessed event committed event")
10
Our Solution: Reverse Computation... Use Reverse Computation (RC) –automatically generate reverse code from model source –undo by executing reverse code Delivers better performance –negligible overhead for forward computation –significantly lower memory utilization
 –automatically generate reverse code from model source –undo by executing reverse code Delivers better performance –negligible overhead for forward computation –significantly lower memory utilization.")
11
if( qlen < B ) qlen++ delays[qlen]++ else lost++ N B on packet arrival... Original if( b1 == 1 ) delays[qlen]-- qlen-- else lost-- Reverse if( qlen < B ) b1 = 1 qlen++ delays[qlen]++ else b1 = 0 lost++ Forward Ex: Simple Network Switch
![if( qlen < B ) qlen++ delays[qlen]++ else lost++ N B on packet arrival...](http://images.slideplayer.com/22/6392032/slides/slide_11.jpg "Original if( b1 == 1 ) delays[qlen]-- qlen-- else lost-- Reverse if( qlen < B ) b1 = 1 qlen++ delays[qlen]++ else b1 = 0 lost++ Forward Ex: Simple Network Switch.")
12
Beneficial Application Properties 1. Majority of operations are constructive –e.g., ++, --, etc. 2. Size of control state < size of data state –e.g., size of b1 < size of qlen, sent, lost, etc. 3. Perfectly reversible high-level operations gleaned from irreversible smaller operations –e.g., random number generation

13
Destructive assignment (DA): –examples: x = y; x %= y; –requires all modified bytes to be saved Caveat: –reversing technique for DA’s can degenerate to traditional incremental state saving Good news: –certain collections of DA’s are perfectly reversible! –queueing network models contain collections of easily/perfectly reversible DA’s queue handling (swap, shift, tree insert/delete, … ) statistics collection (increment, decrement, …) random number generation (reversible RNGs) Destructive Assignment...
 statistics collection (increment, decrement, …) random number generation (reversible RNGs) Destructive Assignment....")
14
RC Applications PDES applications include: –Wireless telephone networks –Distributed content caches –Large-scale Internet models – TCP over AT&T backbone Leverges RC “swaps” –Hodgkin-Huxley neuron models –Plasma physics models using PIC –Pose -- UIUC Non-DES include: –Debugging –PISA – Reversible instruction set architecture for low power computing –Quantum computing if( qlen < B ) qlen++ delays[qlen]++ else lost++ B packet arrival... Original if( b1 == 1 ) delays[qlen]-- qlen-- else lost-- Reverse if( qlen < B ) b1 = 1 qlen++ delays[qlen]++ else b1 = 0 lost++ Forward
![RC Applications PDES applications include: –Wireless telephone networks –Distributed content caches –Large-scale Internet models – TCP over AT&T backbone Leverges RC swaps –Hodgkin-Huxley neuron models –Plasma physics models using PIC –Pose -- UIUC Non-DES include: –Debugging –PISA – Reversible instruction set architecture for low power computing –Quantum computing if( qlen < B ) qlen++ delays[qlen]++ else lost++ B packet arrival...](http://images.slideplayer.com/22/6392032/slides/slide_14.jpg "Original if( b1 == 1 ) delays[qlen]-- qlen-- else lost-- Reverse if( qlen < B ) b1 = 1 qlen++ delays[qlen]++ else b1 = 0 lost++ Forward.")
15
Local Control Implementation Local Control Mechanism: error detection and rollback LP 1 LP 2 LP 3 VirtualTimeVirtualTime undo state ’s (2) cancel “sent” events MPI_ISend/MPI_Irecv used to send/recv off core events Event & Network memory is managed directly. –Pool is allocated @ startup Event list keep sorted using a Splay Tree (logN) LP-2-Core mapping tables are computed and not stored to avoid the need for large global LP maps.
 LP-2-Core mapping tables are computed and not stored to avoid the need for large global LP maps..")
16
Global Control Implementation GVT (kicks off when memory is low): 1.Each core counts #sent, #recv 2.Recv all pending MPI msgs. 3.MPI_Allreduce Sum on (#sent - #recv) 4.If #sent - #recv != 0 goto 2 5.Compute local core’s lower bound time-stamp (LVT). 6.GVT = MPI_Allreduce Min on LVTs Algorithms needs efficient MPI collective LC/GC can be very sensitive to OS jitter Global Control Mechanism: compute Global Virtual Time (GVT) LP 1 LP 2 LP 3 VirtualTimeVirtualTime GVT collect versions of state / events & perform I/O operations that are < GVT So, how does this translate into Time Warp performance on BG/L & BG/P?
 4.If #sent - #recv != 0 goto 2 5.Compute local core’s lower bound time-stamp (LVT). 6.GVT = MPI_Allreduce Min on LVTs Algorithms needs efficient MPI collective LC/GC can be very sensitive to OS jitter Global Control Mechanism: compute Global Virtual Time (GVT) LP 1 LP 2 LP 3 VirtualTimeVirtualTime GVT collect versions of state / events & perform I/O operations that are < GVT So, how does this translate into Time Warp performance on BG/L & BG/P .")
17
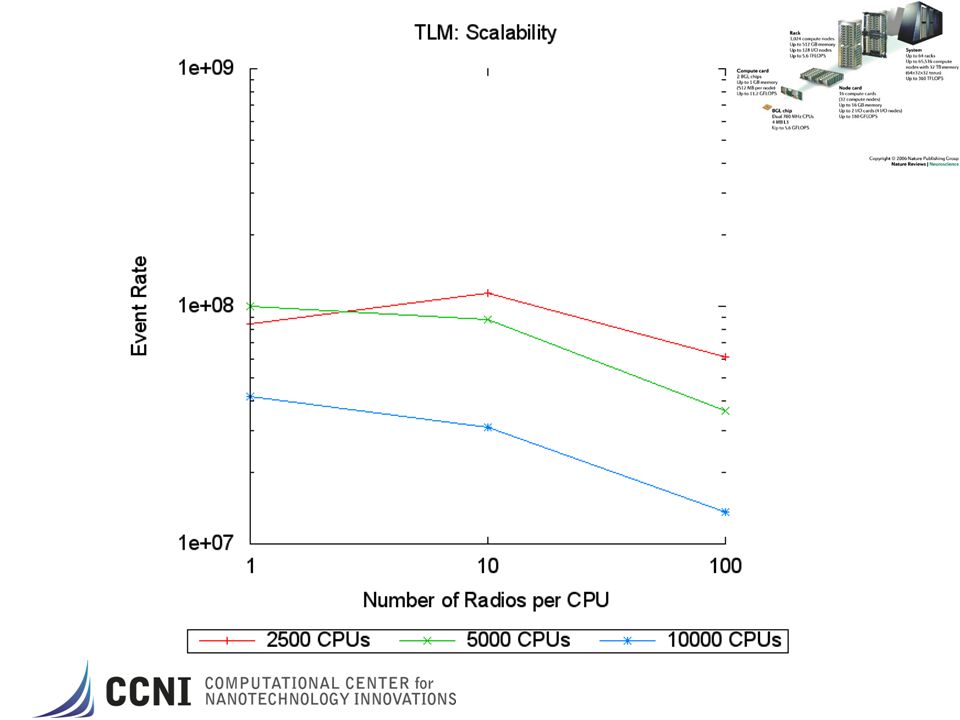
Performance Results: Setup PHOLD –Synthetic benchmark model –1024x1024 grid of LPs –Each LP has 10 initial events –Event routed randomly among all LPs based on a configurable “percent remote” parameter –Time stamps are exponentially distributed with a mean of 1.0 (i.e., lookahead is 0). TLM – Tranmission Line Matrix –Discrete electromagnetic propagation wave model –Used model the physical layer of MANETs –As accurate as previous “ray tracing” models, but dramatically faster… –Considers wave attenuation effects –Event populations grows cubically outward from the single “radio” source. ROSS parameters –GVT_Interval number of times thru “scheduler” loop before computing GVT. –Batch number of local events to process before “check” network for new events. Batch X GVT_Interval events processed per GVT epoch –KPs kernel processes that hold the aggregated processed event lists for LPs to lower search overheads for fossil collection of “old” events. –Send/Recv Buffers – number of network events for “sending” or “recv’ing”. Used as a flow control mechanism.

18
7.5 billion ev/sec for 10% remote on 32,768 cores!! 2.7 billion ev/sec for 100% remote on 32,768 cores!! Stable performance across processor configurations attributed to near noiseless OS…

19
Performance falls off after just 100 processors on a PS3 cluster w/ Gigabit Eithernet

20
12.27 billion ev/sec for 10% remote on 65,536 cores!! 4 billion ev/sec for 100% remote on 65,536 cores!!

21
Rollback Efficiency = 1 - E rb /E net

23
Model a 10 PF Supercomputer (revisited) Suppose we want to model a 10 PF supercomputer at the MPI message level How long excute parallel DES model? 16 trillion events @ 10 billion ev/sec ~27 mins

24
Observations… ROSS on Blue Gene indicates billion-events per second model are feasible today! –Yields significant TIME COMPRESSION of current models.. LP to PE mapping less of a concern… –Past systems where very sensitive to this ~90 TF systems can yield “Giga-scale” event rates. Tera-event models require teraflop systems. –Assumes most of event processing time is spent in event-list management (splay tree enqueue/dequeue). Potential: 10 PF supercomputers will be able to model near peta-event systems –100 trillion to 1 quadrillion events in less than 1.4 to 14 hours –Current “testbed” emulators don’t come close to this for Network Modeling and Simulation..
. Potential: 10 PF supercomputers will be able to model near peta-event systems –100 trillion to 1 quadrillion events in less than 1.4 to 14 hours –Current testbed emulators don’t come close to this for Network Modeling and Simulation...")
25
Future Models Enabled by X- Scale Computing Discrete “transistor” level models for whole multi-core architectures… –Potential for more rapid improvements in processor technology… Model nearly whole U.S. Internet at packet level… –Potential to radically improve overall QoS for all Model all C4I network/systems for a whole theatre of war faster than real-time many time over.. –Enables the real-time“active” network control..

26
Future Models Enabled by X-Scale Computing Realistic discrete model the human brain –100 billion neurons w/ 100 trillion synapes (e.g. connections – huge fan-out) –Potential for several exa-events per run Detailed “discrete” agent-based model for every human on the earth for.. –Global economic modeling –pandemic flu/disease modeling –food / water / energy usage modeling… But to get there investments must be made in code that are COMPLETELY parallel from start to finish!!
 –Potential for several exa-events per run Detailed discrete agent-based model for every human on the earth for.. –Global economic modeling –pandemic flu/disease modeling –food / water / energy usage modeling… But to get there investments must be made in code that are COMPLETELY parallel from start to finish!!.")
27
Thank you!! Additional Acknowledgments –David Bauer – HPTi –David Jefferson – LLNL for helping us get discretionary access to “Intrepid” @ ALCF –Sysadmins: Ray Loy (ANL), Tisha Stacey (ANL) and Adam Todorski (CCNI) ROSS Sponsers –NSF PetaApps, NeTS & CAREER programs –ALFC/ANL
, Tisha Stacey (ANL) and Adam Todorski (CCNI) ROSS Sponsers –NSF PetaApps, NeTS & CAREER programs –ALFC/ANL.")
Similar presentations















 connection request with specified QoS requirements (e.g., Bdw, Delay, Jitter, packet loss, path.>")



