Download presentation
Presentation is loading. Please wait.

1
Chapter 5 Sampling and Statistics Math 6203 Fall 2009 Instructor: Ayona Chatterjee

2
5.1 Sampling and Statistics Typical statistical problem: – We have a random variable X with pdf f(x) or pmf p(x) unknown. Either f(x) and p(x) are completely unknown. Or the form of f(x) or p(x) is known down to the parameter θ, where θ may be a vector. Here we will consider the second option. Example: X has an exponential distribution with θ unknown.
 and p(x) are completely unknown. Or the form of f(x) or p(x) is known down to the parameter θ, where θ may be a vector. Here we will consider the second option. Example: X has an exponential distribution with θ unknown..")
3
Since θ is unknown, we want to estimate it. Estimation is based on a sample. We will formalize the sampling plan: – Sampling with replacement. Each draw is independent and X’s have the same distribution. – Sampling without replacement. Each draw is not independent but X’s still have the same distribution.

4
Random Sample The random variables X 1, X 2, …., X n constitute a random sample on the random variable X if they are independent and each has the same distribution as X. We will abbreviate this by saying that X 1, X 2, …., X n are iid; i.e. independent and identically distributed. – The joint pdf can be given as

5
Statistic Suppose the n random variables X 1, X 2, …., X n constitute a sample from the distribution of a random variable X. Then any function T=T(X 1, X 2, …., X n ) of the sample is called a statistic. A statistic, T=T(X 1, X 2, …., X n ), may convey information about the unknown parameter θ. We call the statistics a point estimator of θ.
 of the sample is called a statistic. A statistic, T=T(X 1, X 2, …., X n ), may convey information about the unknown parameter θ. We call the statistics a point estimator of θ..")
6
5.2 Order Statistics

7
Notation Let X 1, X 2, ….X n denote a random sample from a distribution of the continuous type having a pdf f(x) that has a support S = (a, b), where -∞≤ a< x< b ≤ ∞. Let Y 1 be the smallest of these X i, Y 2 the next X i in order of magnitude,…., and Y n the largest of the X i. That is Y 1 < Y 2 < …<Y n represent X 1, X 2, ….X n, when the latter is arranged in ascending order of magnitude. We call Y i the ith order statistic of the random sample X 1, X 2, ….X n.

8
Theorem 5.2.1 Let Y 1 < Y 2 < …<Y n denote the n order statistics based on the random sample X 1, X 2, ….X n from a continuous distribution with pdf f(x) and support (a,b). Then the joint pdf of Y 1, Y 2, ….Y n is given by,

9
Note The joint pdf of any two order statistics, say Y i < Y j can be written as

10
Note Y n - Y 1 is called the range of the random sample. (Y 1 + Y n )/2 is called the mid-range If n is odd then Y (n+1)/2 is called the median of the random sample
/2 is called the mid-range If n is odd then Y (n+1)/2 is called the median of the random sample.")
11
5.4 MORE ON CONFIDENCE INTERVALS

12
The Statistical Problem We have a random variable X with density f(x,θ), where θ is unknown and belongs to the family of parameters Ω. We estimate θ with some statistics T, where T is a function of the random sample X 1, X 2, ….X n. It is unlikely that value of T gives the true value of θ. – If T has a continuous distribution then P(T= θ)=0. What is needed is an estimate of the error of estimation. – By how much did we miss θ?
=0. What is needed is an estimate of the error of estimation. – By how much did we miss θ .")
13
Central Limit Theorem Let θ 0 denote the true, unknown value of the parameter θ. Suppose T is an estimator of θ such that Assume that σ T 2 is known.

14
Note When σ is unknown we use s(sample standard deviation) to estimate it. We have a similar interval as obtained before with the σ replaced with s t. Note t is the value of the statistic T.

15
Confidence Interval for Mean μ Let X 1, X 2, ….X n be a random sample from the distribution with unknown mean μ and unknown standard deviation σ.

16
Note We can find confidence intervals for any confidence level. Let Z α/2 as the upper α/2 quantile of a standard normal variable. Then the approximate (1- α)100% confidence interval for θ 0 is
100% confidence interval for θ 0 is.")
17
Confidence Interval for Proportions Let X be a Bernoulli random variable with probability of success p. Let X 1, X 2, ….X n be a random sample from the distribution of X. Then the approximate (1- α)100% confidence interval for p is
100% confidence interval for p is.")
18
5.5 Introduction to Hypothesis Testing

19
Introduction Our interest centers on a random variable X which has density function f(x,θ), where θ belongs to Ω. Due to theory or preliminary experiment, suppose we believe that

20
The hypothesis H 0 is referred to as the null hypothesis while H 1 is referred to as the alternative hypothesis. The null hypothesis represents ‘no change’. The alternative hypothesis is referred to the as research worker’s hypothesis.

21
Error in Hypothesis Testing The decision rule to take H 0 or H 1 is based on a sample X 1, X 2, ….X n from the distribution of X and hence the decision could be wrong. True State of Nature DecisionH o is trueH 1 is true Reject H o Type I ErrorCorrect Decision Accept H o Correct DecisionType II Error

22
The goal is to select a critical region from all possible critical regions which minimizes the probabilities of these errors. In general this is not possible, the probabilities of these errors have a see-saw effect. – Example if the critical region is Φ, then we would never reject the null so the probability of type I error would be zero but then probability of type II error would be 1. Type I error is considered the worse of the two.

23
Critical Region We fix the probability of type I error and we try and select a critical region that minimizes type II error. We saw critical region C is of size α if Over all critical regions of size α, we want to consider critical regions which have lower probabilities of Type II error.

24
We want to maximize The probability on the right hand side is called the power of the test at θ. It is the probability that the test detects the alternative θ when θ belongs to w 1 is the true parameter. So maximizing power is the same as minimizing Type II error.

25
Power of a test We define the power function of a critical region to be Hence given two critical regions C 1 and C 2 which are both of size α, C 1 is better than C 2 if

26
Note Hypothesis of the form H 0 : p = p 0 is called simple hypothesis. Hypothesis of the form H 1 : p < p 0 is called a composite hypothesis. Also remember α is called the significance level of the test associated with that critical region.

27
Test Statistics for Mean

28
5.7 Chi-Square Tests

29
Introduction Originally proposed by Karl Pearson in 1900 Used to check for goodness of fit and independence.

30
Goodness of fit test Consider the simple hypothesis – H 0 : p 1 =p 10, p 2 =p 20, …, p k-1 =p k-1,0 If the hypothesis H 0 is true, the random variable Has an approximate chi-square distribution with k-1 degrees of freedom.

31
Test for Independence Let the result of a random experiment be classified by two attributes. Let A i denote the outcomes of the first kind and B j denote the outcomes for the second kind. Let p ij = P(A i B j ) The random experiment is said to be repeated n independent times and X ij will denote the frequencies of an event in A i B j
 The random experiment is said to be repeated n independent times and X ij will denote the frequencies of an event in A i B j.")
33
The random variable Has an approximate chi-square distribution with (a-1)(b-1) degrees of freedom provided n is large.
(b-1) degrees of freedom provided n is large.")
Similar presentations
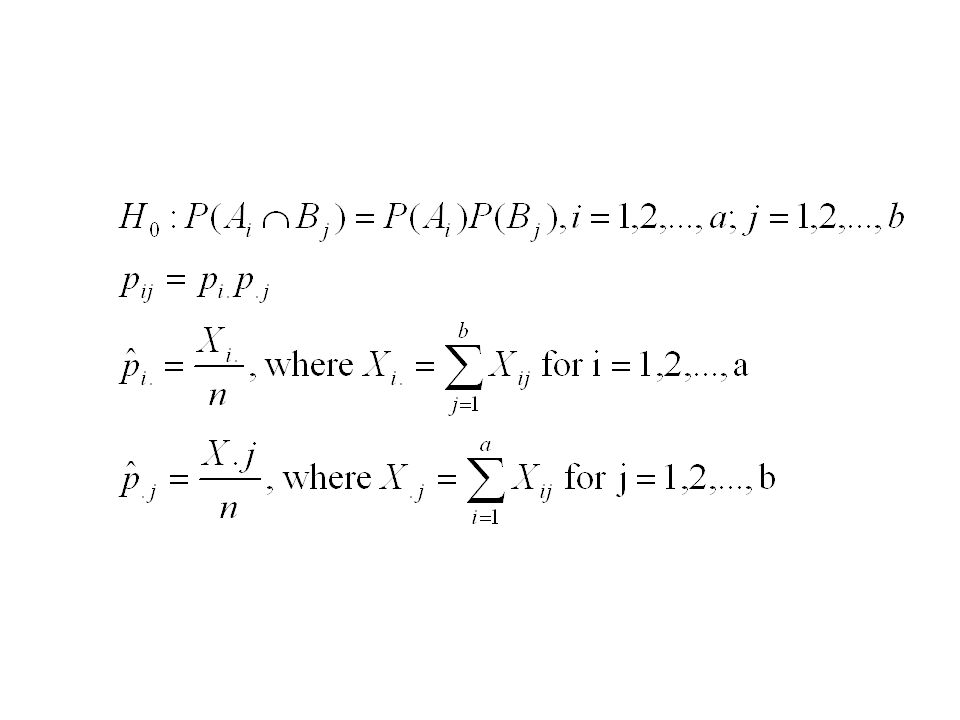


 There are two types of hypothesis : 1) Simple hypothesis :A statistical.>")
 values must be estimated before.>")
>")














