Download presentation
Presentation is loading. Please wait.

1
CS344: Introduction to Artificial Intelligence Vishal Vachhani M.Tech, CSE Lecture 34-35: CLIR and Ranking, Crawling and Indexing in IR

2
Road Map Cross Lingual IR Motivation CLIA architecture CLIA demo Ranking Various Ranking methods Nutch/lucene Ranking Learning a ranking function Experiments and results

3
Cross Lingual IR Motivation Information unavailability in some languages Language barrier Definition: Cross-language information retrieval (CLIR) is a subfield of information retrieval dealing with retrieving information written in a language different from the language of the user's query (wikipedia) Example: A user may ask query in Hindi but retrieve relevant documents written in English.
 is a subfield of information retrieval dealing with retrieving information written in a language different from the language of the user s query (wikipedia) Example: A user may ask query in Hindi but retrieve relevant documents written in English.")
4
4 Why CLIR? Query in Tamil English Document System Marathi Document search English Document Snippet Generation and Translation

5
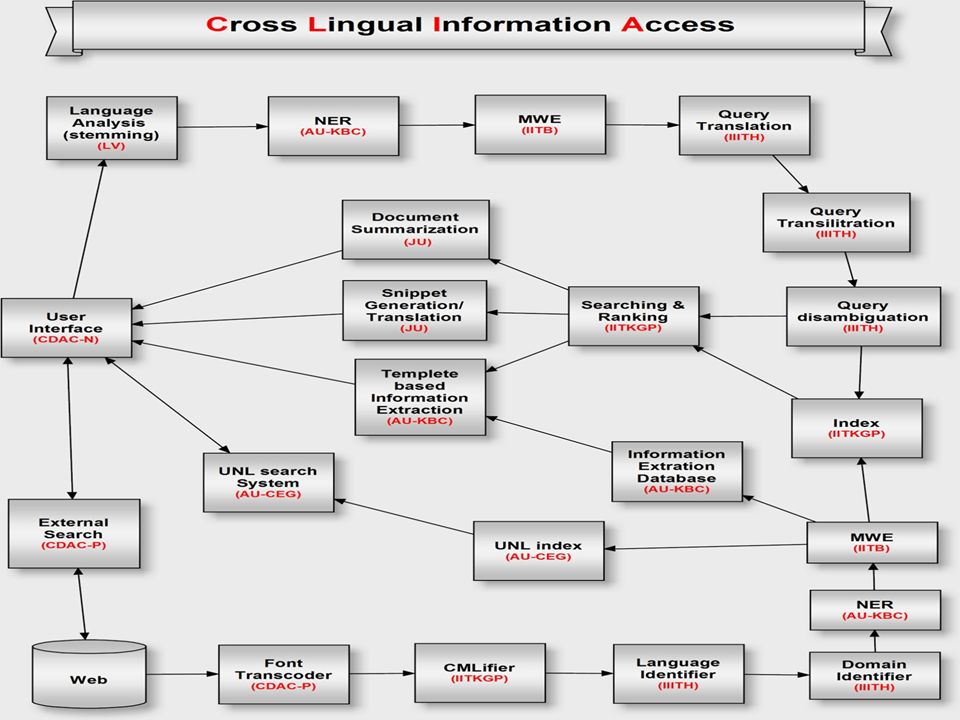
Cross Lingual Information Access Cross Lingual Information Access (CLIA) A web portal supporting monolingual and cross lingual IR in 6 Indian languages and English Domain : Tourism It supports : Summarization of web documents Snippet translation into query language Temple based information extraction The CLIA system is publicly available at http://www.clia.iitb.ac.in/clia-beta-ext
 A web portal supporting monolingual and cross lingual IR in 6 Indian languages and English Domain : Tourism It supports : Summarization of web documents Snippet translation into query language Temple based information extraction The CLIA system is publicly available at")
7
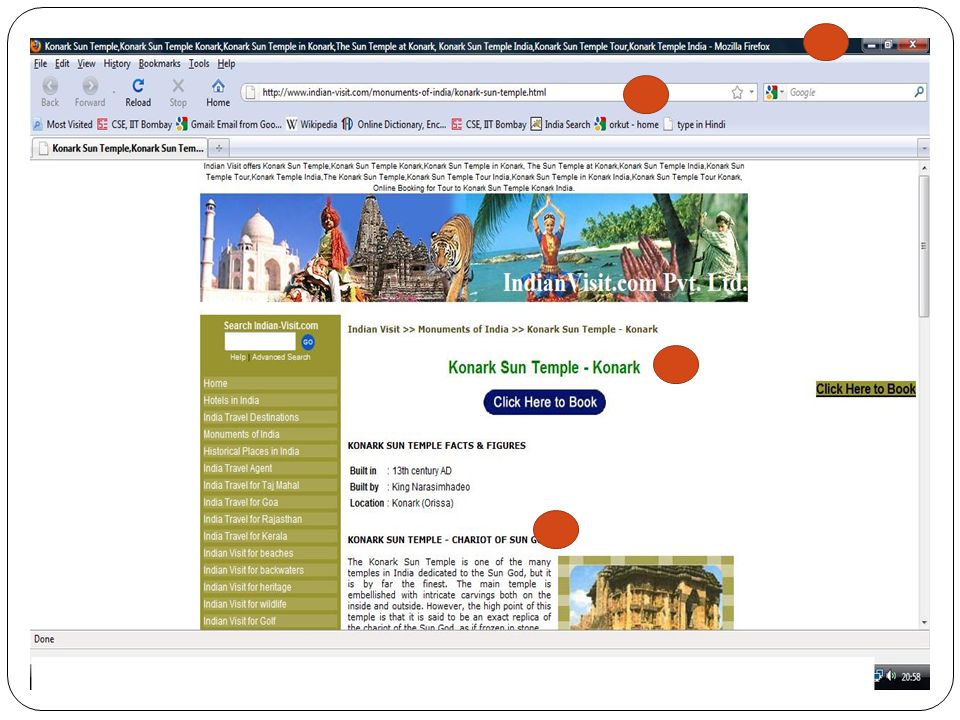
CLIA Demo

8
Various Ranking methods Vector Space Model Lucene, Nutch, Lemur, etc Probabilistic Ranking Model Classical spark John’s ranking (Log ODD ratio) Language Model Ranking using Machine Learning Algo SVM, Learn to Rank, SVM-Map, etc Link analysis based Ranking Page Rank, Hubs and Authorities, OPIC, etc
 Language Model Ranking using Machine Learning Algo SVM, Learn to Rank, SVM-Map, etc Link analysis based Ranking Page Rank, Hubs and Authorities, OPIC, etc")
9
Nutch Ranking CLIA is built on top on Nutch – A open source web search engine. It is based on Vector space model

10
Link analysis Calculates the importance of the pages using web graph Node: pages Edge: hyperlinks between pages Motivation: link analysis based score is hard to manipulate using spamming techniques Plays an important role in web IR scoring function Page rank Hub and Authority Online Page Importance Computation (OPIC) Link analysis score is used along with the tf-idf based score We use OPIC score as a factor in CLIA.
 Link analysis score is used along with the tf-idf based score We use OPIC score as a factor in CLIA.")
12
Learning a ranking function How much weight should be given to different part of the web documents while ranking the documents? A ranking function can be learned using following method Machine learning algorithms: SVM, Max-entropy Training A set of query and its some relevant and non-relevant docs for each query A set of features to capture the similarity of docs and query In short, learn the optimal value of features Ranking Use a Trained model and generate score by combining different feature score for the documents set where query words appears Sort the document by using score and display to user

13
Extended Features for Web IR 1. Content based features – Tf, IDF, length, co-ord, etc 2. Link analysis based features – OPIC score – Domains based OPIC score 3. Standard IR algorithm based features – BM25 score – Lucene score – LM based score 4. Language categories based features – Named Entity – Phrase based features

14
Content based Features

15
Details of features Feature NoDescriptions 1Length of body 2length of title 3length of URL 4length of Anchor 5-14C1-C10 for Title of the page 15-24C1-C10 for Body of the page 25-34C1-C10 for URL of the page 35-44C1-C10 for Anchor of the page 45OPIC score 46Domain based classification score

16
Details of features(Cont) Feature NoDescriptions 48BM25 Score 49Lucene score 50Language Modeling score 51 -54Named entity weight for title, body, anchor, url 55-58Multi-word weight for title, body, anchor, url 59-62Phrasal score for title, body, anchor, url 63-66Co-ord factor for title, body, anchor, url 71Co-ord factor for H1 tag of web document
 Feature NoDescriptions 48BM25 Score 49Lucene score 50Language Modeling score Named entity weight for title, body, anchor, url 55-58Multi-word weight for title, body, anchor, url 59-62Phrasal score for title, body, anchor, url 63-66Co-ord factor for title, body, anchor, url 71Co-ord factor for H1 tag of web document")
17
Experiments and results MAP Nutch Ranking0.2267 0.26670.2137 DIR with Title + content0.69330.640.59110.3444 DIR with URL+ content0.720.620.53330.3449 DIR with Title + URL + content0.720.65330.560.36 DIR with Title+URL+content+anchor0.730.660.580.3734 DIR with Title+URL+ content + anchor+ NE feature 0.760.630.60.4

18
Crawling, Indexing

19
Outline Nutch Overview Crawler in CLIA system Data structure Crawler in CLIA Indexing Types of index and indexing tools Searching Command line API Searching through GUI Demo

20
Crawler The crawler system is driven by the Nutch crawl tool, and a family of related tools to build and maintain several types of data structures, including the web database, a set of segments, and the index.

21
Crawler Data Structure Web Database (webdb) persistent data structure for web graph being crawled. Stores pages and links Segment A collection of pages fetched and indexed by the crawler in a single run Index Inverted index of all of the pages the system has retrieved

22
Crawler Initial URLs GeneratorFetcher Segment Webpages/files Web Parser generate Injector CrawlDB read/write CrawlDBTool update get read/write

23
Crawl command Aimed for intranet-scale crawling A front end to other, lower-level tools It performs crawling and indexing Create a URLS directory and put URLs list in it. Command $NUTCH_HOME/bin/nutch crawl urlDir [Options] Options -dir: the directory to put the crawl in. -depth: the link depth from the root page that should be crawled. -threads: the number of threads that will fetch in parallel. -topN: number of total pages to be crawled. Example bin/nutch crawl urls -dir crawldir -depth 3 -topN 10

24
Inject command Inject root URLs into the WebDB Command $NUTCH_HOME/bin/nutch inject : Path to the Crawl Database directory : Path to the directory containing flat text url files

25
Generate command Generates a new Fetcher Segment from the Crawl Database Command: $NUTCH_HOME/bin/nutch generate [-topN ] [-numFetchers ] : Path to the crawldb directory. : Path to the directory where the Fetcher Segments are created. [-topN ]: Selects the top ranking URLs for this segment [-numFetchers ]: The number of fetch partitions.
![Generate command Generates a new Fetcher Segment from the Crawl Database Command: $NUTCH_HOME/bin/nutch generate [-topN ] [-numFetchers ] : Path to the crawldb directory.](http://images.slideplayer.com/21/6292973/slides/slide_25.jpg ": Path to the directory where the Fetcher Segments are created. [-topN ]: Selects the top ranking URLs for this segment [-numFetchers ]: The number of fetch partitions..")
26
Fetch command Runs the Fetcher on a segment Command : $NUTCH_HOME/bin/nutch Fetch [-threads ] [- noParsing] : Path to the segment to fetch [-threads ]: The number of fetcher threads to run [-noParsing]: Disables automatic parsing of the segment's data
![Fetch command Runs the Fetcher on a segment Command : $NUTCH_HOME/bin/nutch Fetch [-threads ] [- noParsing] : Path to the segment to fetch [-threads ]: The number of fetcher threads to run [-noParsing]: Disables automatic parsing of the segment s data](http://images.slideplayer.com/21/6292973/slides/slide_26.jpg "Fetch command Runs the Fetcher on a segment Command : $NUTCH_HOME/bin/nutch Fetch [-threads ] [- noParsing] : Path to the segment to fetch [-threads ]: The number of fetcher threads to run [-noParsing]: Disables automatic parsing of the segment s data")
27
Parse command Runs ParseSegment on a segment. Command $NUTCH_HOME/bin/nutch parse : Path to the segment to parse.

28
Updatedb command Updates the Crawl DB with information obtained from the Fetcher Command : $NUTCH_HOME/bin/nutch updatedb : Path to the crawl database. : Path to the segment that has been fetched.

29
Index and Indexing Sequential Search is bad (Not Scalable) Indexing – the creation of a data structure that facilitates fast, random access to information stored in it. Types of Index Forward Index Inverted Index Full Inverted Index

30
Forward Index It stores a list of words for each documents Example D 1 =“it is what it is.” D 2 =“what is it.” D 3 =“it is a banana” DocumentWords 1It, is, what 2What, is, it 3It, is, a, banana

31
Inverted Index It stores a list of documents for each word WordDocuments a3 banana3 is1,2,3 it1,2,3 What1,2

32
Full Inverted Index It is used to support phrase search. Query: “What is it” WordDocuments a{(3.2)} banana{(3,3)} is{(1,1),(1,4),(2,1),(3,1)} it{(1,0),(2,2),(3,0)} What{(1,2),(2,0)}
} banana{(3,3)} is{(1,1),(1,4),(2,1),(3,1)} it{(1,0),(2,2),(3,0)} What{(1,2),(2,0)}.")
33
Invertlink command Updates the Link Database with linking information from a segment Command: $NUTCH_HOME/bin/nutch invertlink (-dir segmentsDir | segment1 segment2...) : Path to the link database. : Path to the segment that has been fetched. A directory or more than one segment may be specified.

34
Index command Creates an index of a segment using information from the crawldb and the linkdb to score pages in the index Command : $NUTCH_HOME/bin/nutch index... : Path to the directory where the index will be created : Path to the crawl database directory : Path to the link database directory : Path to the segment that has been fetched More then one segment may be specified

35
Dedup command Removes duplicate pages from a set of segment indexes Command: $NUTCH_HOME/bin/nutch dedup : Path to directories containing indexes

36
Merge command Merges several segment indexes Command: $NUTCH_HOME/bin/nutch merge... : Path to a directory where the merged index will be created. : Path to a directory containing indexes to merge. More then one directory may be specified.

37
Configuring CLIA crawler Configure file: $NUTCH/conf/nutch-site.xml Required user parameters http.agent.name http.agent.description http.agent.url http.agent.email Optional user parameters http.proxy.host http.proxy.port

38
Configuring CLIA crawler Configure file: $NUTCH/conf/crawl-urlfilters.txt Regular expression to filter URLs during crawling E.g. To ignore files with certain suffix: -\.(gif|exe|zip|ico)$ To accept host in a certain domain +^http://([a-z0-9]*\.)*apache.org/ change the following line @ 26 line of crawl-urlfileters.txt #skip everything else +.
$ To accept host in a certain domain +^ change the following line 26 line of crawl-urlfileters.txt #skip everything else +..")
39
Searching and Indexing Indexer (Lucene) Segments Index Searcher (Lucene) GUI CrawlDBLinkDB (Tomcat)
 Segments Index Searcher (Lucene) GUI CrawlDBLinkDB (Tomcat)")
40
Crawl Directory Structure Crawldb Contains the information about every URL known to Nutch Linkdb contains the list of known links to each URL Segment crawl_generate names a set of urls to be fetched crawl_fetch contains the status of fetching each url content contains the content of each url parse_text contains the parsed text of each url parse_data contains outlinks and metadata parsed from each url crawl_parse contains the outlink urls, used to update the crawldb Index Contains Lucene-format indexes.

41
Searching Configure file: $NUTCH/conf/nutch-default.xml Change the following property: searcher.dir – complete path to you crawl folder Command line searching API $NUTCH_HOME/bin/nutch org.apache.nutch.searcher.NutchBean queryString

42
Searching Create clia-alpha-test.war file using “ant war” Deploy clia-alpha-test.war file in tomcat webapp directory http://localhost:8080/clia-alpha-test/

43
Thanks

Similar presentations
 2.Ranked retrieval 3.Probabilistic retrieval.>")


















 Jayalekshmy S. Nair (08305056)>")