Download presentation
Presentation is loading. Please wait.

1
By Ravi Shankar Dubasi Sivani Kavuri A Popularity-Based Prediction Model for Web Prefetching

2
What is Web Latency? What is Web Caching? How does Web Caching help in reducing Web Latency? What is Web Prefetching? How does Web Prefetching help in reducing Web Latency? Does Web Prefetching really decrease Web Latency!!!!

3
Combining Caching and Prefetching. Performance Improvement. Why Prediction Models? What are Prediction Models? How aggressive Prefetching is? How aggressive Prefetching can be?

4
PPM (Prediction by Partial Match) Model Slight variations to this model.. Model proposed by Xin Chen and Xiaodong Zhang. POPULARITY BASED PREDICTION MODEL

5
Log files

6
Access Session: ENTER EXIT URL

7
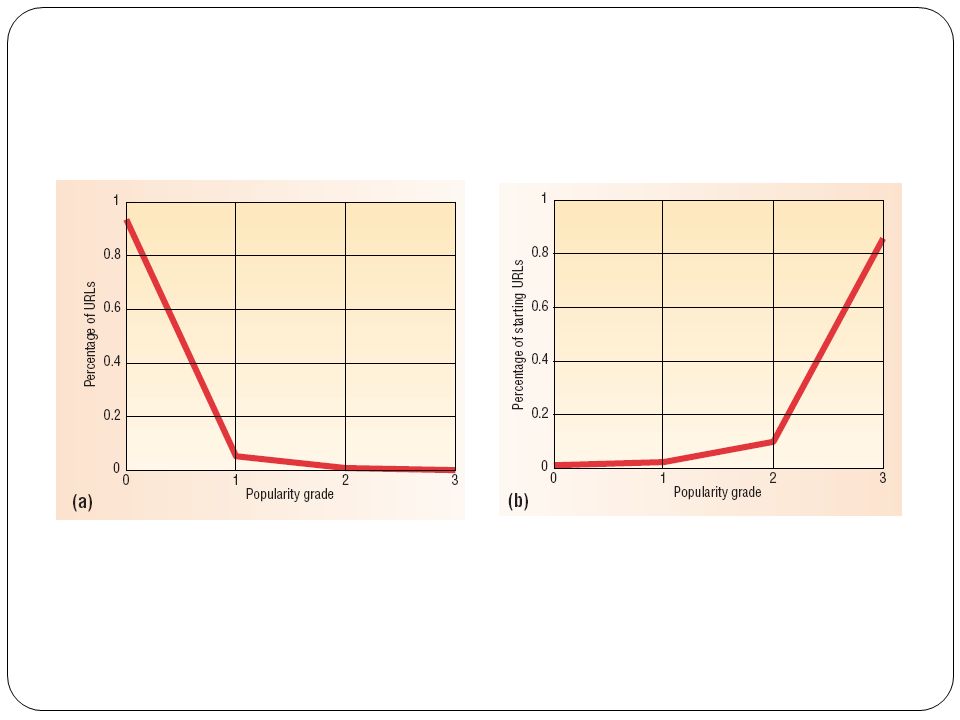
3 Major Regularities: Regularity 1: Majority Clients start their access session from popular URLs of a server. However, majority of URLs in a server are not popular files. Regularity 2: Majority Long access sessions are headed by popular URLs. Regularity 3: The accessing paths in majority access sessions start from popular URLs, move to less popular URLs, and exit from the least URLs. The accessing paths in minority access sessions start from less popular URLs, and remain in the same type of URLs, and exit from the least popular URLs.

8
Popularity of URLs How to determine popularity of URLs? How do we grade the URLs? How to determine Relative Popularity? Grade 3 : 10<RP≤100% Grade 2 : 1<RP≤10% Grade 1 : 0.1%<RP≤1% Grade 0 : RP≤0.1%

9
Distribution of Popularity Grades To examine relationship between URL popularity and access session Divided each trace into 4 session groups Regularity 1 is observed Observations Paying special attention to popular URLs which are only a small % Is this advantageous???? Paying small attention to less popular URLs which can be large What about this???

11
Popularity and session length Day 79 traces 86% of access sessions started from popular URLs, moved to less popular URLs and exited from the least popular URLs Regularity 2 is observed The average popularity grade decreases as the session length increases. Observations Clients starting with less popular URLs tend to surf among URLs with the same popularity.

13
3 Prediction Models 1. Standard model 2. LRS model (longest repeating sequence) 3. Popularity-based model (All models are evaluated here according to the 92 day evaluation period) (All models use the Markov Tree representation)
 (All models use the Markov Tree representation).")
14
Standard Model Node 0 represents the root of the forest When Client access URL the model builds a new tree with root A The Counter is set to 1 The counter is incremented every time that URL is accessed in the session The process continues till we complete all the sessions Every path from root node to leaf node represents the URL session for at least one client

15
0 A/2B/2C/2A’/2 B’/2 C’/2 B/2 C/2 A’/1 B’/1 C’/1 C/2 A’/1 B’/1 C’/1 A’/1 B’/1 C’/1 B’/2 C’/2 The Three Access Sequences are: {ABCA’B’C’} {ABC} {A’B’C’} STANDARD PPM

16
Advantages and Disadvantages: Easy to build (not complex) Prediction accuracy improves More Space required ( increases with increase in prediction order) (determined by Entropy analysis and emperical studies) Attempts for Space Optimization: Tree no longer resembles the regular surfing patterns Prediction accuracy low (short tree) Small height increase rapidly increases storage requirements.
 Prediction accuracy improves More Space required ( increases with increase in prediction order) (determined by Entropy analysis and emperical studies) Attempts for Space Optimization: Tree no longer resembles the regular surfing patterns Prediction accuracy low (short tree) Small height increase rapidly increases storage requirements.")
17
LRS Model LRS Model keeps the longest repeating subsequences stores only long branches with frequently accessed URLs The server builds the tree the same way as in standard PPM Scans each branch for non-repeating sequence Identifies and eliminates the non-repeating sequence The stored longest sequence is the frequently repeating sequence (at least one occurrence of one subsequence belongs to an independent access sessions)
")
18
0 A/2B/2C/2A’/2B’/2C’/2 B/2 C/2 A’/1 B’/1 C’/1 C/2 A’/1 B’/1 C’/1 A’/1 B’/1 C’/1 B’/2C’/2 The Three Access Sequences are: {ABCA’B’C’} {ABC} {A’B’C’}

19
Advantages and Disadvantages: LRS PPM model offers a lower storage requirements and higher prediction accuracy It has low hit rates ( because tree keeps only a small number of frequently accessed branches (popular) it ignores prefetching for less frequently accessed URLs (unpopular) so overall prefetching rate can be low) The Process is expensive ( To find the longest matching, the server must have all all previous URLs of current session, thus the server must maintain sessions and update them)
 it ignores prefetching for less frequently accessed URLs (unpopular) so overall prefetching rate can be low) The Process is expensive ( To find the longest matching, the server must have all all previous URLs of current session, thus the server must maintain sessions and update them)")
20
Popularity Based Prediction Model It uses only the most popular URLs as root nodes Each URL in a sequence is added only once to the tree unless the its Popularity grade is higher than the root node Maximum tree height is based on Available memory space Access session lengths Space Optimization is done to the completed tree based on: Relative access probability Absolute Number of accesses (RAP=Number of accesses to the URL/Number of accesses to the parent URL)
")
21
0 A/2 B/2 C/2 A’/1 A’/2 B’/2 C’/2 The Three Access Sequences are: {ABCA’B’C’} {ABC} {A’B’C’}

22
Advantages and Disadvantages: Space Optimization (since less number of nodes) High Prediction Accuracy (since it includes access information) For higher Thresholds --- HIT Ratio decreases (since unpopular files domination increases)
 High Prediction Accuracy (since it includes access information) For higher Thresholds --- HIT Ratio decreases (since unpopular files domination increases)")
23
OBSERVATIONS The Standard PPM model without limiting branch height. The LRS PPM model keeping the longest repeating subsequence. Popularity-based PPM model with space optimization. 1) In Standard PPM model without limiting height of each branch, Prediction accuracy is increased 2) In LRS PPM model keeping longest repeating sequence i.e removing independent access sessions, Space is saved 3) In Popularity-based PPM model space optimization considering relative access probability, Preserves Prediction accuracy
 In Standard PPM model without limiting height of each branch, Prediction accuracy is increased 2) In LRS PPM model keeping longest repeating sequence i.e removing independent access sessions, Space is saved 3) In Popularity-based PPM model space optimization considering relative access probability, Preserves Prediction accuracy.")
24
Integrating prediction model with prefetching and caching Cache memory is divided into 2 parts. Prefect buffer Cache memory Prefetching manager Cache manager PREDICTION ENGINE Constructs and updates prediction model (based on requests issued) Offers prediction independently to each client.
 Offers prediction independently to each client..")
25
Integrated Web Caching and Prefetching Model

26
PREDICTION ALGORITHM current_context [0] : root node of T; for length j=1 to m current_context [j]:=NULL; for every event R in S for length j= 0 to m { if current_context[j] has child node C representing event R { node C occurrence_count:=occurrence_count +1 ; current_context[j+1]:= node C; } else { construct child node C representing event R; node C occurence_count:=1; current_context[j+1]:=node C; } current_context[0]:= root node of T; }
![PREDICTION ALGORITHM current_context [0] : root node of T; for length j=1 to m current_context [j]:=NULL; for every event R in S for length j= 0 to m { if current_context[j] has child node C representing event R { node C occurrence_count:=occurrence_count +1 ; current_context[j+1]:= node C; } else { construct child node C representing event R; node C occurence_count:=1; current_context[j+1]:=node C; } current_context[0]:= root node of T; }](http://images.slideplayer.com/18/6203683/slides/slide_26.jpg "PREDICTION ALGORITHM current_context [0] : root node of T; for length j=1 to m current_context [j]:=NULL; for every event R in S for length j= 0 to m { if current_context[j] has child node C representing event R { node C occurrence_count:=occurrence_count +1 ; current_context[j+1]:= node C; } else { construct child node C representing event R; node C occurence_count:=1; current_context[j+1]:=node C; } current_context[0]:= root node of T; }")
27
PREFETCHING ALGORITHM LET S be the set of all objects currently in the prefetch buffer; LET P=Ø; //P is set of objects to be prefetched LET TotalSize = 0; // the total size of all objects in P LET j = 0; WHILE (j ≤ n) AND (TotalSize < SIZEOF (prefetch buffer)) IF (O(j) not in cache) AND (O(j) not in prefetch buffer) THEN Put O(j) into P ; LET TotalSize = TotalSize+SIZEOF(O(j)); j=j+1; END IF END WHILE LET M=S.P;
 AND (TotalSize < SIZEOF (prefetch buffer)) IF (O(j) not in cache) AND (O(j) not in prefetch buffer) THEN Put O(j) into P ; LET TotalSize = TotalSize+SIZEOF(O(j)); j=j+1; END IF END WHILE LET M=S.P;")
28
Simulation Parameters 1. Order of Prediction 2. Confidence 3. Previous requests 4. Number of predictions 5. Browsing session idle time 6. Client cache size 7. Client cache idle time

29
Performance Metrics 1. Usefulness of Predictions ( Hit ratio ) 2. Accuracy of Predictions 3. Network traffic 4. Space Optimization ( Model aims at maximizing first two metrics and minimizing last two metrics) Maximum size of prefetched files effect both hit ratios and network traffic. Large values »» more traffic »» high hit ratio
 Maximum size of prefetched files effect both hit ratios and network traffic. Large values »» more traffic »» high hit ratio.")
30
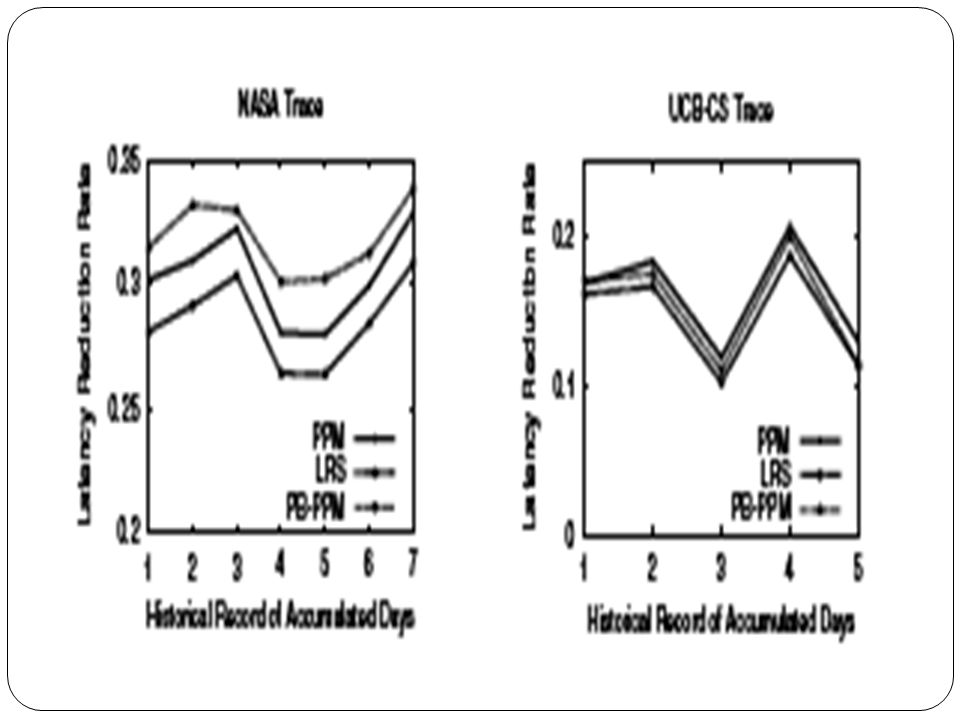
Hit Ratio Ratio between no. of requests that hit the browser or cache and the total no. of requests. Latency Reduction Average access latency time reduction per request. Space Required memory allocation measured by the no. of nodes for building a PPM model in the web server for prefetching. Traffic Increment Ratio between the total no. of transferred bytes and the total no. of useful bytes for the clients minus 1.

31
Hit ratio vs threshold

33
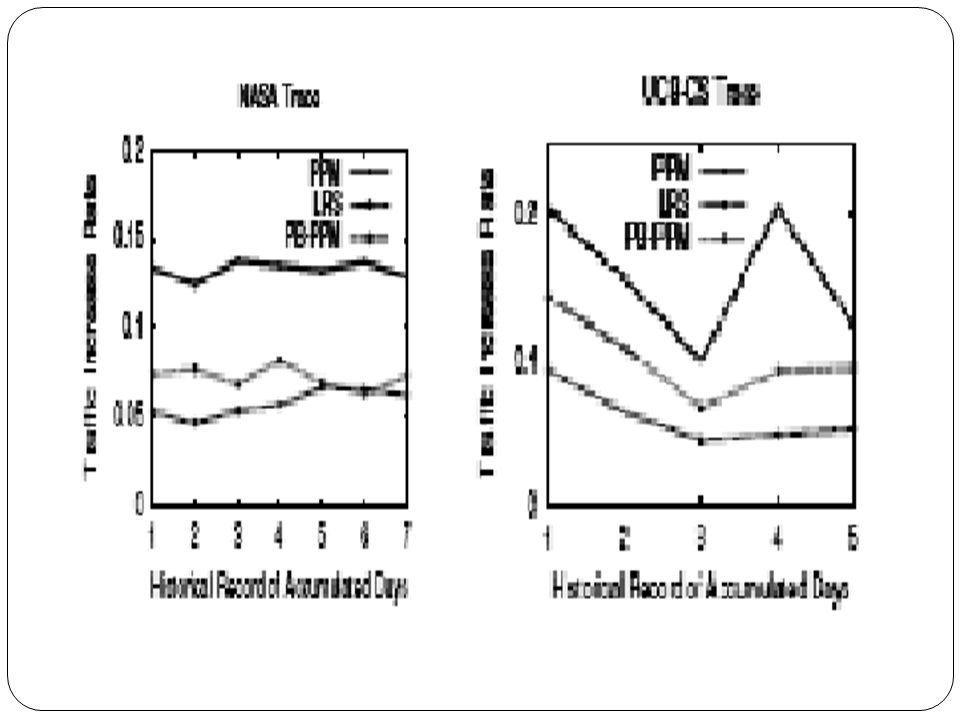
Traffic Increment Vs Threshold

35
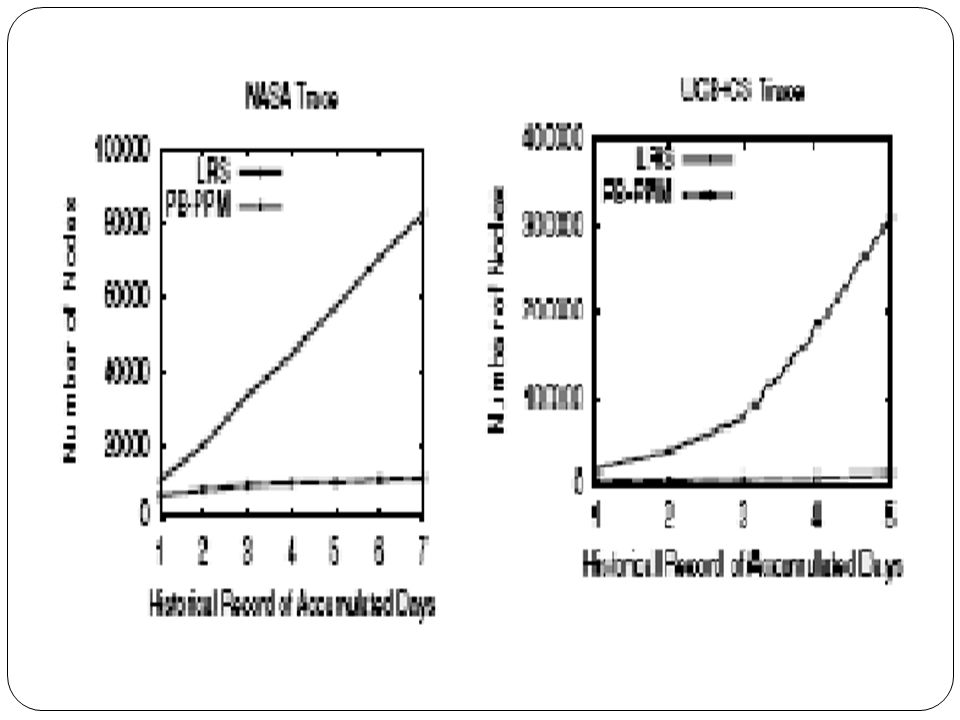
Number of Nodes Vs Number of Clients

38
CONCLUSIONS Effective web management approach. Makes searching and prefetching highly objective and highly efficient. Web prefetching can have both high prediction accuracy and a low space requirement.

39
FUTURE WORK To make the model more flexible. To find more elaborate ways of making predictions. Filtering out the effect of backward references. Extending prediction engine to accommodate more predictions.

Similar presentations












1 LEARNING OBJECTIVES Problems with simple indexing. Multilevel indexing: B-Tree. –B-Tree creation: insertion and deletion of nodes.>")









