Download presentation
Presentation is loading. Please wait.

1
Patrick-André Savard, Philippe Gournay and Roch Lefebvre Université de Sherbrooke, Québec, Canada

2
Problem description Prior art ◦ Synchronized overlap-add w/fixed syn. (SOLAFS) ◦ Improved phase vocoder Hybrid time-scale modification ◦ High level algorithm ◦ Classification ◦ Main algorithm ◦ Mode transition Performance evaluation ◦ Classification performance ◦ Subjective testing results
 ◦ Improved phase vocoder Hybrid time-scale modification ◦ High level algorithm ◦ Classification ◦ Main algorithm ◦ Mode transition Performance evaluation ◦ Classification performance ◦ Subjective testing results.")
3
What is time-scale modification? Subject of interest: ◦ Subjective quality of time-scaled signals Existing methods: ◦ Time vs frequency approaches ◦ High quality results on specific types of signals TSM applied to various signal types ◦ Can be speech, music, or mixed-type signals There is a need for a more “universal” method

4
Input Signal Output Signal SaSa SsSs W LEN delay

5
Based on the block- by-block STFT analysis/synthesis model STFT phases are updated so as to preserve instantaneous frequencies STFT amplitudes are preserved STFT modification Improvements Peak-detection Compute inst. freq.for peaks Define regions of influence Update peak phases Apply phase- lock.to ROIs STFT modification stage FFT IFFT Overlap-add and gain control N RaRa RsRs

6
Uses a frame-by- frame model Each frame goes through a classifier Signals identified as monophonic are processed using SOLAFS Signals identified as polyphonic or noisy are processed using the phase vocoder

7
Goal: ◦ Discriminate monophonic/polyphonic/noise signals Method used: ◦ Test the maximum of the normalized cross- correlation (C.C.) measure in SOLAFS for each analysis window Music Signal Speech Signal UnvoicedVoiced Voiced speech: High C.C. Music: Low to medium C.C. Unvoiced speech: Low & high C.C.

8
SOLAFS processing R max <T xcorr Default method: SOLAFS Switches to phase vocoder when R max <T xcorr Constraint on minimum length of a SOLAFS synthesis segment Frame 1 Frame 2 SOLAFS processing R max <T xcorr SOLAFS processing Phase vocoder processing Frame 1 Frame 2 discarded

9
Phase vocoder initialization: Synthesis padded with input samples Initialization based on matching input/output samples Gain control: More padding needed Synthesis further padded and windowed to reproduce a phase vocoder output Last SOLAFS synthesis window Output signal padded with input samples Initialization based on matching input/output samples Previously padded synthesis More padding using input samples Resulting synthesis is windowed First phase vocoder synthesis window overlaps coherently

10
Current frame’s first analysis window is out of phase with current output signal Assume that the current input frame contains a stationary signal First input window is one phase vocoder analysis step ahead First SOLAFS segment is OLA at the last phase vocoder synthesis step SOLAFS synthesis samples (after the first OLA region) replace synthesis samples obtained by the phase vocoder Previous frame Current frame Synthesis signal (before transition) First SOLAFS synthesis window Subsequent SOLAFS synthesis windows Current frame’s first analysis window (not in phase with current output)Approximately in phase with current output
 replace synthesis samples obtained by the phase vocoder Previous frame Current frame Synthesis signal (before transition) First SOLAFS synthesis window Subsequent SOLAFS synthesis windows Current frame’s first analysis window (not in phase with current output)Approximately in phase with current output")
11
Signal length =1 second T max =0.6 Unvoiced speech is successfully detected Triggers phase vocoder processing

12
Signal length = 25 seconds T max =0.6 Classification results: 91 % phase vocoder 9 % SOLAFS

13
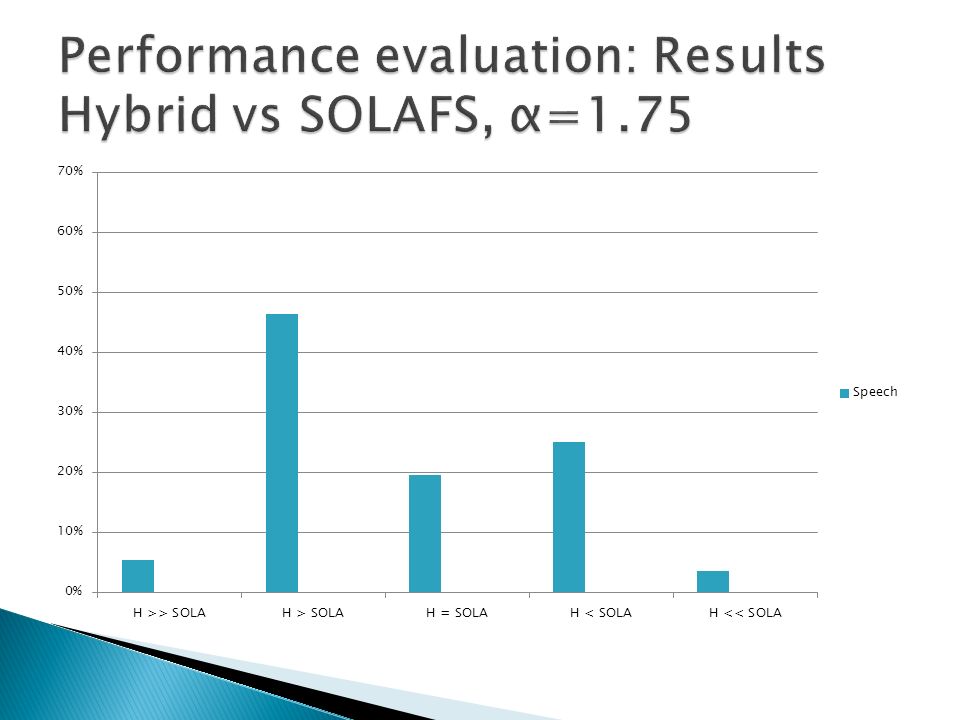
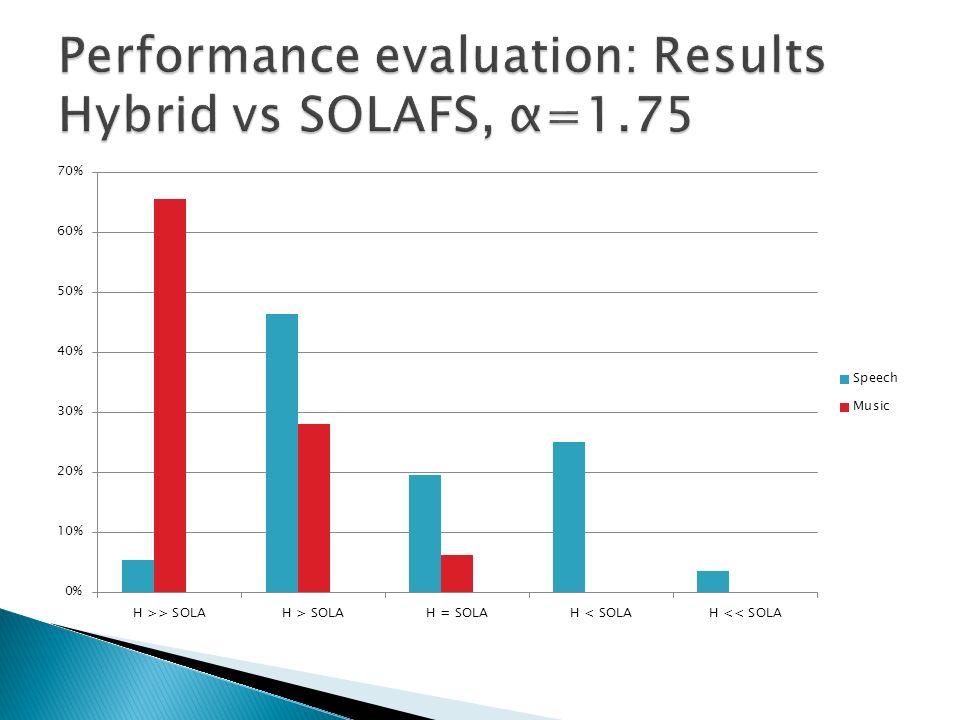
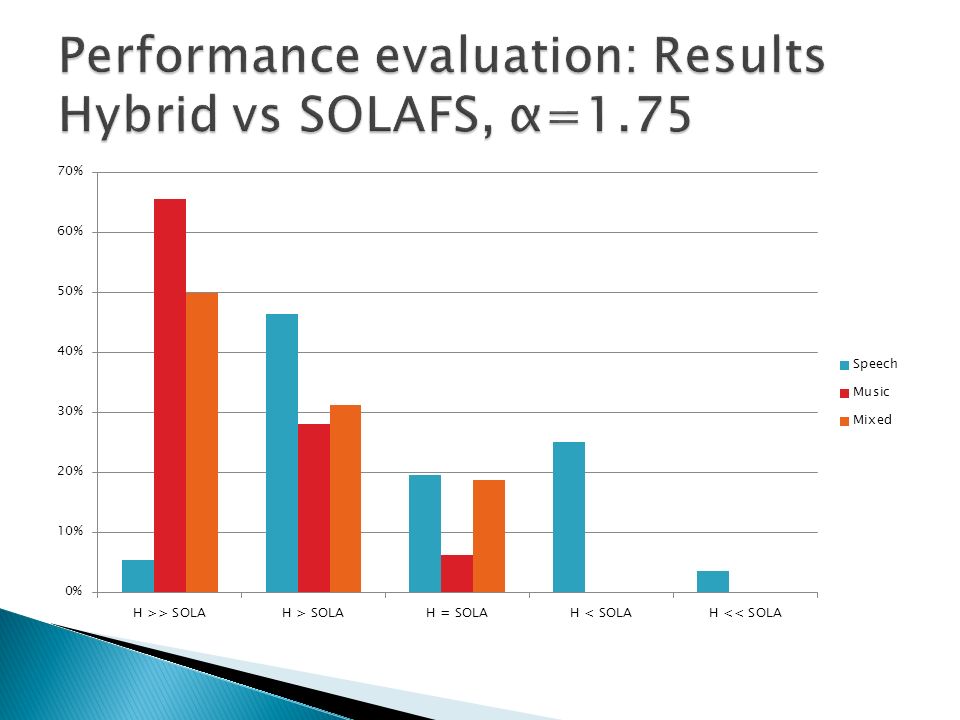
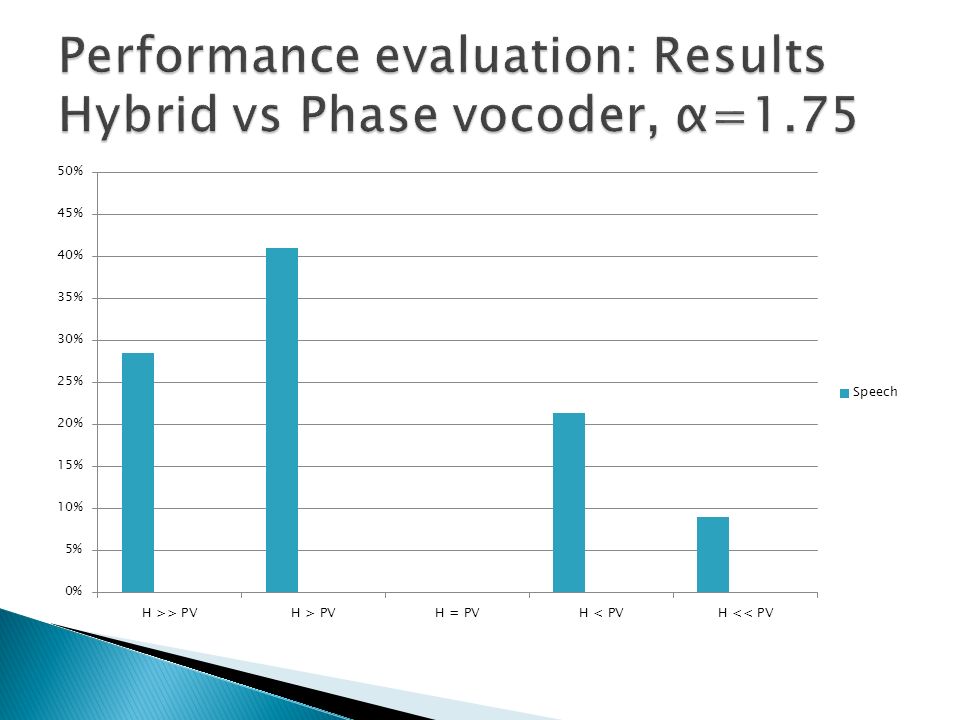
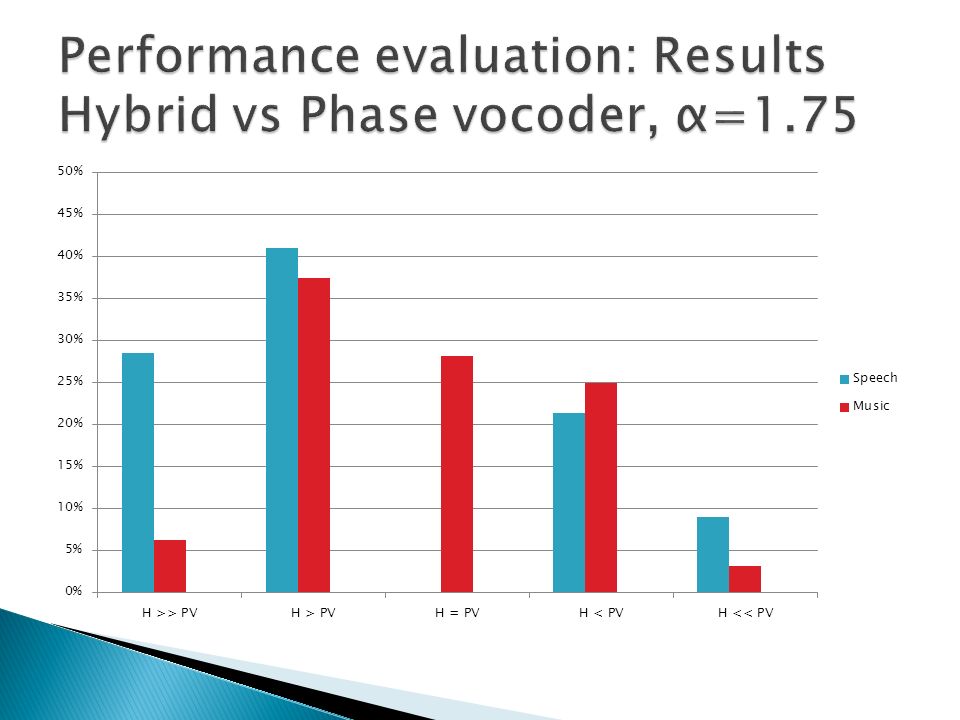
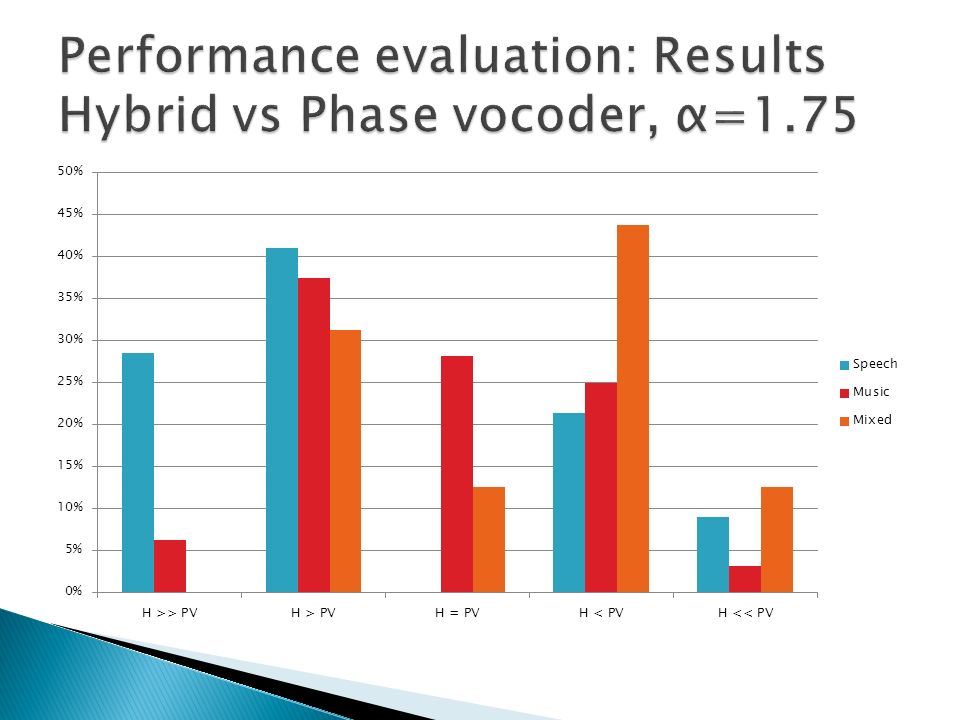
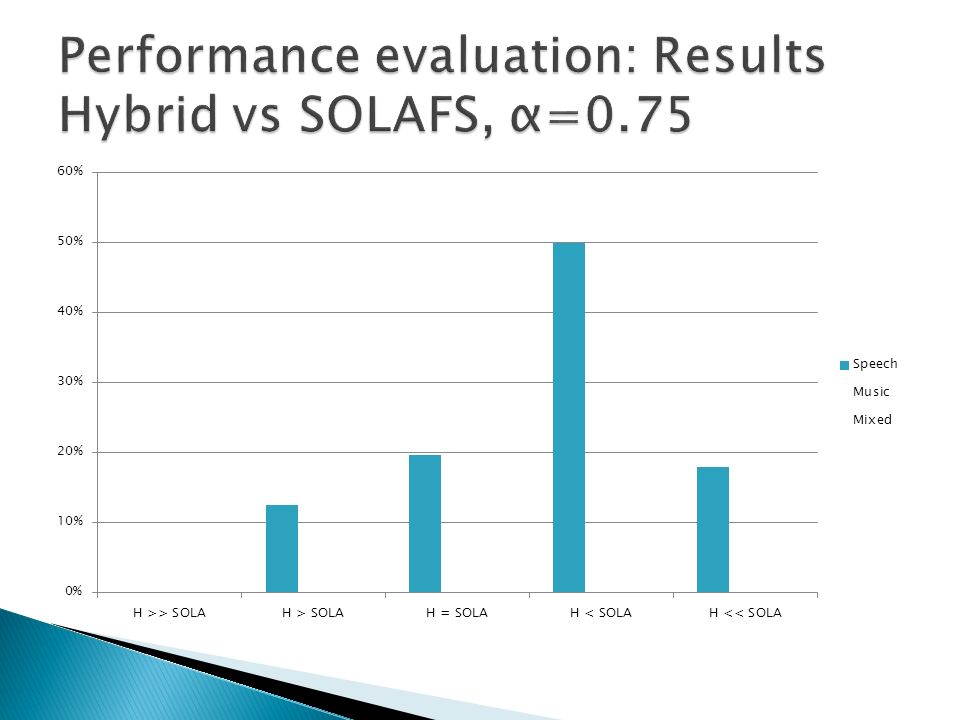
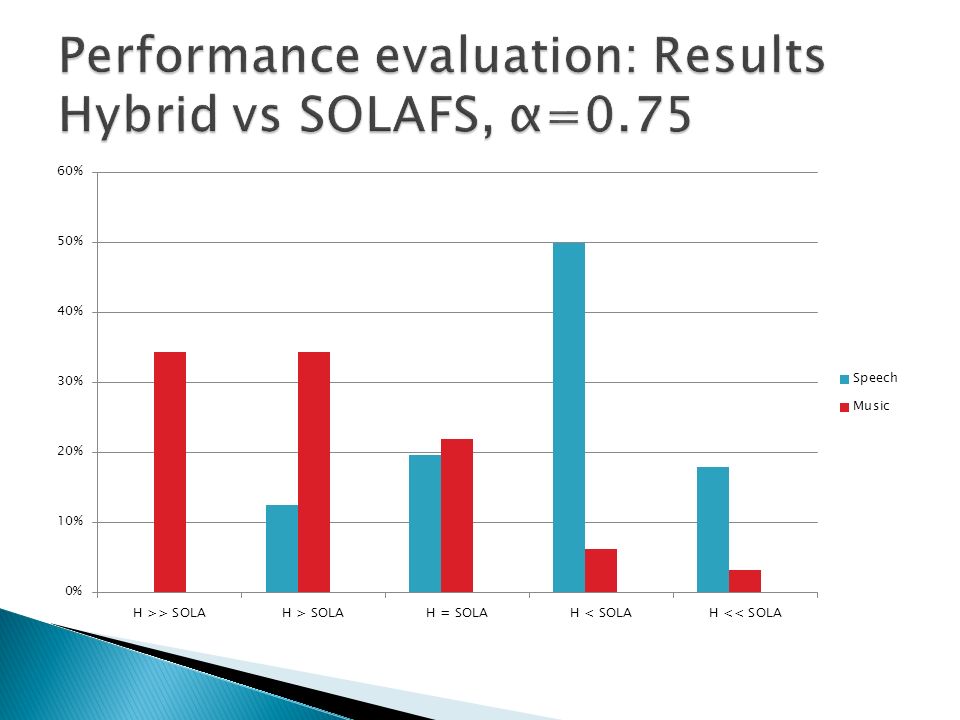
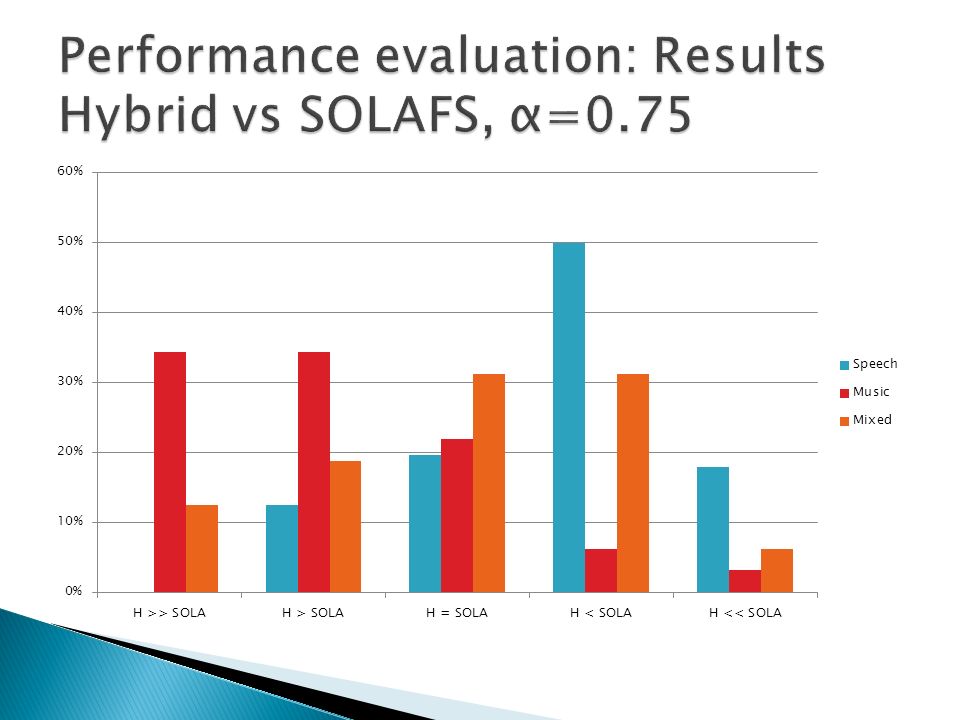
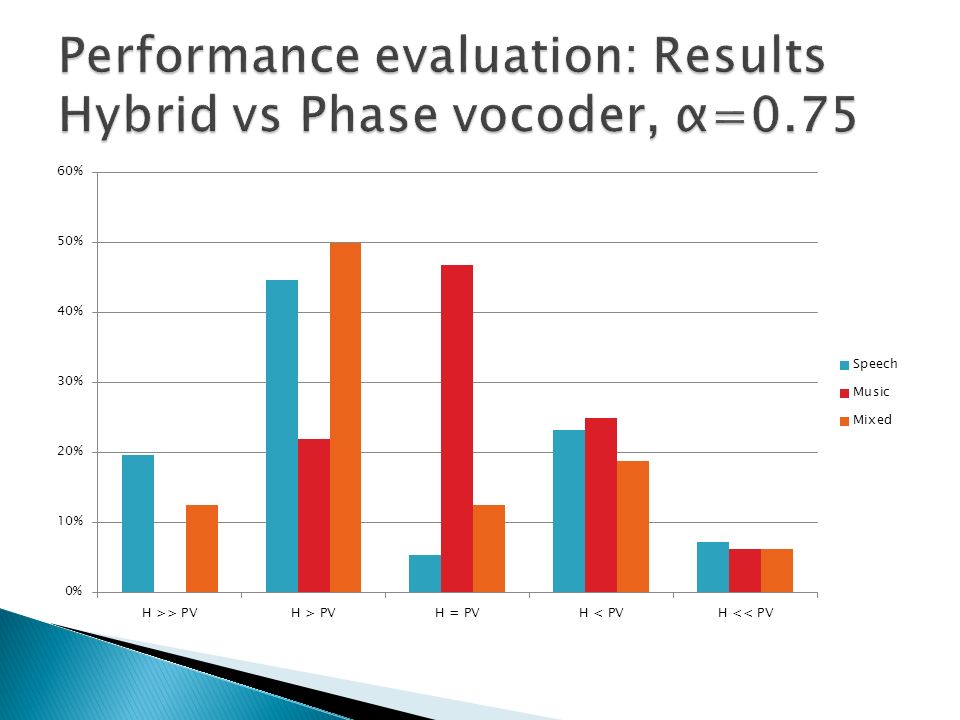
A/B method Speech, music and mixed content (speech over music) samples tested Hybrid method compared to stand-alone techniques Comparisons performed on compressed and expanded signals Eight listeners took part of the test Samples evaluated using a 5 step scale
 samples tested Hybrid method compared to stand-alone techniques Comparisons performed on compressed and expanded signals Eight listeners took part of the test Samples evaluated using a 5 step scale")
26
A hybrid TSM method is presented ◦ Uses a frame-by-frame classification stage ◦ Selects the best method based on the input signal monophonic/polyphonic/noise character ◦ Mode transitions High quality results are obtained ◦ Using speech, music and mixed-content signals Future work ◦ Refine the classification criterion ◦ Use of phase flexibility to improve phase coherence would improve phase vocoder to SOLAFS transitions

27
Contact: P-A.Savard@USherbrooke.caP-A.Savard@USherbrooke.ca

Similar presentations


![Www.fakengineer.com [1] AN ANALYSIS OF DIGITAL WATERMARKING IN FREQUENCY DOMAIN.](/1/277349/big_thumb.jpg "Www.fakengineer.com [1] AN ANALYSIS OF DIGITAL WATERMARKING IN FREQUENCY DOMAIN.>")

, pressure.>")









![Block Convolution: overlap-save method Input Signal x[n]: arbitrary length Impulse response of the filter h[n]: lenght P Block Size: N we take.](/14/4463505/big_thumb.jpg "Block Convolution: overlap-save method Input Signal x[n]: arbitrary length Impulse response of the filter h[n]: lenght P Block Size: N we take.>")




 R.C. Maher ECEN4002/5002 DSP Laboratory Spring 2003.>")
 at low TSM factor Wong, P.H.W.; Au, O.C.; Wong, J.W.C.; Lau, W.H.B. TENCON '97.>")
