Download presentation
Presentation is loading. Please wait.

1
Regression for Data Mining Mgt. 2206 – Introduction to Analytics Matthew Liberatore Thomas Coghlan

2
Learning Objectives To understand the application of regression analysis in data mining Linear/nonlinear Logistic (Logit) To understand the key statistical measures of fit To learn how to run and interpret regression analyses using SAS Enterprise Miner software
 To understand the key statistical measures of fit To learn how to run and interpret regression analyses using SAS Enterprise Miner software")
3
Analysis of Association In business problems interests often go beyond the statistical testing of differences (e.g., female versus male preferences) Often interested in degree of association between variables. Regression is one of the techniques that helps uncover those relations.

4
Linear Regression Analysis Analysis of the strength of the linear relationship between predictor (independent) variables and outcome (dependent/criterion) variables. In two dimensions (one predictor, one outcome variable) data can be plotted on a scatter diagram. E ( y ) = 0 1 (x) Expected value of y (outcome) Intercept Term coefficient Predictor variable
 data can be plotted on a scatter diagram. E ( y ) = 0 1 (x) Expected value of y (outcome) Intercept Term coefficient Predictor variable.")
5
Estimation Process Regression Model y = 0 + 1 x + Regression Equation E ( y ) = 0 + 1 x Unknown Parameters 0, 1 Sample Data: x y x 1 y 1...... x n y n b 0 and b 1 provide estimates of 0 and 1 Estimated Regression Equation Sample Statistics b 0, b 1

6
Positive Linear Relationship Simple Linear Regression Equation: Positive Linear Relationship E ( y ): Outcome x : Predictor Slope 1 is positive Regression line Intercept 0
: Outcome x : Predictor Slope 1 is positive Regression line Intercept 0")
7
E ( y ): Outcome x: Predictor Slope 1 is negative Regression line Intercept 0 Negative Linear Relationship Simple Linear Regression Equation: Negative Linear Relationship
: Outcome x: Predictor Slope 1 is negative Regression line Intercept 0 Negative Linear Relationship Simple Linear Regression Equation: Negative Linear Relationship")
8
E ( y ): Outcome x: Predictor No Relationship Simple Linear Regression Equation: No Relationship
: Outcome x: Predictor No Relationship Simple Linear Regression Equation: No Relationship")
9
E(y)E(y)E(y)E(y) x Slope 1 is 0 Regression line Intercept 0 No Relationship Simple Linear Regression Equation: No Relationship
E(y)E(y)E(y) x Slope 1 is 0 Regression line Intercept 0 No Relationship Simple Linear Regression Equation: No Relationship")
10
E ( y ): Outcome x: Predictor Intercept 0 Parabolic Relationship Simple Linear Regression Equation: Parabolic Relationship
: Outcome x: Predictor Intercept 0 Parabolic Relationship Simple Linear Regression Equation: Parabolic Relationship")
11
Example List Variables we have Determine a DV of interest Is there a way to predict DV?

12
Least Squares Method Least Squares Criterion: minimize error (distance between actual data & estimated line) where: y i = observed value of the dependent variable for the ith observation for the ith observation ^ y i = estimated value of the dependent variable for the ith observation for the ith observation
 where: y i = observed value of the dependent variable for the ith observation for the ith observation ^ y i = estimated value of the dependent variable for the ith observation for the ith observation")
13
Slope for the Estimated Regression Equation Least Squares Method

14
y - Intercept for the Estimated Regression Equation y - Intercept for the Estimated Regression Equation Least Squares Method where: x i = value of independent variable for ith observation observation n = total number of observations _ y = mean value for dependent variable _ x = mean value for independent variable y i = value of dependent variable for ith observation observation

15
Least Squares Estimation Procedure Least Squares Criterion: The sum of the vertical deviations (y axis) of the points from the line is minimal. Predicted Line Actual Data

16
Example: Kwatts vs. Temp TempKwatts 59.29,730 61.99,750 55.110,180 66.210,230 52.110,800 69.911,160 46.812,530 76.813,910 79.715,110 79.315,690 80.217,020 83.317,880

17
Is the Relationship Linear?

18
Example Results Let X = Temp, Y = Kwatts Y = 319.04 + 185.27 X

19
Coefficient of Determination How “strong” is relationship between predictor & outcome? (Fraction of observed variance of outcome variable explained by the predictor variables). Relationship Among SST, SSR, SSE where: SST = total sum of squares SST = total sum of squares SSR = sum of squares due to regression SSR = sum of squares due to regression SSE = sum of squares due to error SSE = sum of squares due to error SST = SSR + SSE
. Relationship Among SST, SSR, SSE where: SST = total sum of squares SST = total sum of squares SSR = sum of squares due to regression SSR = sum of squares due to regression SSE = sum of squares due to error SSE = sum of squares due to error SST = SSR + SSE.")
20
Coefficient of Determination ( r 2 ) where: SSR = sum of squares due to regression SST = total sum of squares r 2 = SSR/SST
 where: SSR = sum of squares due to regression SST = total sum of squares r 2 = SSR/SST")
21
Kwatts vs. Temp Example dfSS Regression158784708.31 Residual1038696916.69 Total1197481625 r 2 = 0.603033734 Does the linear regression provide a good fit?

22
Assumptions About the Error Term 1. The error is a random variable with mean of zero. 2. The variance of , denoted by 2, is the same for all values of the independent variable. all values of the independent variable. 3. The values of are independent. 4. The error is a normally distributed random variable. variable.

23
Significance Test for Regression Is the value of 1 zero? Two tests are commonly used: Two tests are commonly used: t Test and F Test Both the t test and F test require an estimate of the Both the t test and F test require an estimate of the variance ( 2 ) of the error ( . As in most of our statistical work, we are working with As in most of our statistical work, we are working with a sample, not the population, so we use mean square error ( s 2 ).
 of the error ( . As in most of our statistical work, we are working with As in most of our statistical work, we are working with a sample, not the population, so we use mean square error ( s 2 )..")
24
An Estimate of Testing for Significance where: s 2 = MSE = SSE/( n 2)
")
25
Testing for Significance An Estimate of To estimate we take the square root of 2. To estimate we take the square root of 2. The resulting s is called the standard error of The resulting s is called the standard error of the estimate. the estimate.

26
1 Hypotheses: Coefficient ( 1 ) is 0 (no relationship between predictor & outcome) Calculating t Statistic: Testing for Significance: t Test
 is 0 (no relationship between predictor & outcome) Calculating t Statistic: Testing for Significance: t Test")
27
1. Determine if 2. Specify the level of significance. 3. Select the test statistic. =.05 4. State the rejection rule. Reject if p -value 3.182 (with 3 degrees of freedom) Testing for Significance: t Test
 Testing for Significance: t Test.")
28
nSame Hypotheses: nDifferent Test Statistic: Alternative Test: F Test F = MSR/MSE

29
Reject if: p-value F Reject if: p-value F Testing for Significance: F Test where : F is based on an F distribution with 1 degree of freedom in the numerator and n - 2 degrees of freedom in the denominator F = MSR/MSE

30
1. Determine if 2. Specify the level of significance. 3. Select the test statistic. =.05 4. State the rejection rule. Reject if p -value 10.13 ( with 1 d.f. in numerator and 3 d.f. in denominator) 3 d.f. in denominator) Testing for Significance: F Test F = MSR/MSE
 3 d.f. in denominator) Testing for Significance: F Test F = MSR/MSE.")
31
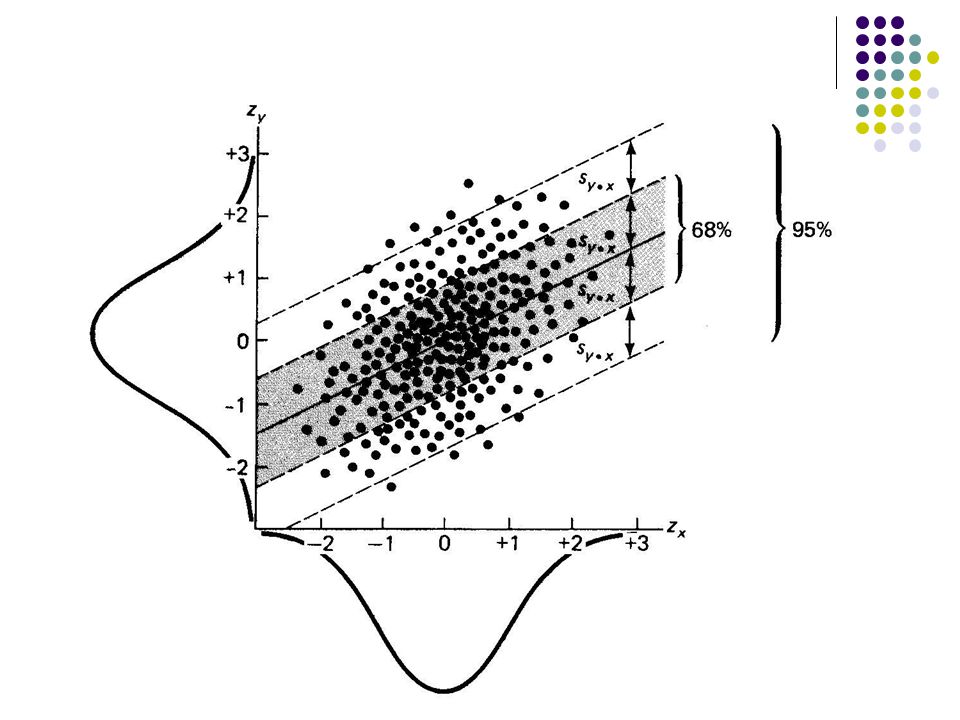
Standard Error of the Estimate Standard Error of Estimate has properties analogous to those of standard deviation. How “good” is our “fit”? Interpretation is similar: ~68% of outcomes/predictions within one s est. ~95% of outcomes/predictions within two s est.

33
Kwatts vs. Temp Example ANOVA dfSSMSFSignificance F Regression158784708.3158784708.3115.190.002972726 Residual1038696916.693869691.669 Total1197481625 CoefficientsStandard Errort StatP-value Intercept319.04141243260.4128110.0978530730.923982528 Temp185.270207347.534790593.8975707060.002972726 Is the regression model statistically significant? Is the coefficient of Temp significant?

34
Cautions about Interpreting Significance Tests Statistical significance does not mean linear relationship between x and y. Statistical significance does not mean linear relationship between x and y. Relationship between x and y does not mean a cause-and-effect relationship is present between x and y. Relationship between x and y does not mean a cause-and-effect relationship is present between x and y.

35
SAS Enterprise Miner These results can be obtained using Excel or using a data mining package such as SAS Enterprise Miner 5.3 Using SAS Enterprise Miner requires the following steps: Convert your data (usually in an Excel file) into a SAS data file Using SAS 9.1 Create a project in Enterprise Miner Within the project: Create a data source using your SAS data file Create a diagram that includes a data node and a regression node and a multiplot node for graphs Run the model in the diagram and review the results
 into a SAS data file Using SAS 9.1 Create a project in Enterprise Miner Within the project: Create a data source using your SAS data file Create a diagram that includes a data node and a regression node and a multiplot node for graphs Run the model in the diagram and review the results")
36
Creating a SAS data file from an Excel file: open SAS 9.1. Select File then Import Data

37
This opens the import wizard. Since the source file is from Excel, click Next. Then click Browse to find the TempKWatts.xls file

38
Since the data are on sheet1$, click Next. Then enter SASUSER as the Library and TEMPKILOWATTL as the Member. Then click Next

39
Now click Finish to create your file

40
Open SAS Enterprise Miner 5.3. Enter the user name and password provided

41
The Enterprise Window below opens. Select New Project

42
The Create New Project dialog box appears. Select the General tab, then type the short name of the project, e.g., KWattTemp0. Keep the default path.

43
In the Startup code tab, enter: libname Ktemps "C:\Documents and Settings\mliberat\My Documents\My SAS Files\9.1\EM_Projects"; This code will be run each time you open the project

44
The Enterprise Miner application window opens

45
Right-click on Data Source, opening the wizard. Source is SAS table, so click Next

46
Browse the SAS libraries to find the SAS table Tempkilowattl found in the SASuser Library (previously created)
")
47
Click Next twice. Note that the Table properties shows that we have two variables with 12 observations

48
The next step controls how Enterprise Miner organizes metadata for the variables in your data. Select advanced, then click next (you can view/change the settings if you click Customize before clicking Next)
.")
49
Change Role of KWatts to target (outcome variable); change Level of both KWatts and Temp to interval (continuous values); then click Next (Other levels are possible, such as binary). You can click on Explore if you wish to look at some basic stats – we will do this later

50
Here Role relates to the role of the data set (raw, train, validate, score); raw is fine for our analysis of data, so click Finish
; raw is fine for our analysis of data, so click Finish")
51
Tempkilowattl now appears under Data Sources in the top left panel called the Project Panel

52
We need to create a Diagram for our model. Right-click on Diagrams, then enter TempKwatts0 in the dialog box. Now the left panel shows TempKwatts0 as a Diagram, and the right- hand panel is called the Diagram Workspace. Icons can be dragged and dropped onto the Diagram Workspace.

53
Now add an Input Data Node to the Diagram. From the Data Sources list in the Project Panel drag and drop the Data Source TempKwatts0 onto the Diagram Workspace. Note that when input data node is highlighted, various properties are displayed on the left-hand panel.

54
If you wish to see the properties of any or all of the variables, highlight the input data node; then on the left hand Properties Panel under Train, click on the box to the right of Variables; in the screen that opens control-click on KWatts and Temp; then click on Explore in the lower right

55
Frequency distributions for the variables and the raw data are provided. Right-clicking on observations in the lower-left panel will show where they appear in the bar charts. Cancel when finished.

56
Click on the Explore tab found over the Diagram Workspace, and then drag and drop the Multiplot icon onto the field. Using your cursor, draw a directed arrow from the TempKwattsl icon to the Multiplot icon. With the Multiplot icon highlighted, its properties are found in the left-hand Properties Panel.

57
Right-click on the Multiplot icon and select Run. After the run is completed select Results from the Run Status window.

58
Various charts are available as shown below. Descriptive statistics for each variable are given in the lower pane.

59
Click on the Model tab and drag the Regression icon onto the Model field. Connect the Tempkwattsl icon to the Regression icon. Highlight the Regression icon and on the Property Panel change Regression Type to linear regression.

60
Run the Regression and select Results. Starting from the upper left and going clockwise, these windows show the fit between target and predicted in percentile terms, the various fit statistics, model output (estimates, F and t stats, R- square), and the two effects (intercept and slope – bars represent size and color represents direction)
, and the two effects (intercept and slope – bars represent size and color represents direction).")
61
For a given percentile, the Target Mean is the actual (or estimated value based on actuals), or what you are trying to predict; the Mean for Predicted is the forecasted values, or the predictions (or estimated values based on forecasts). The results are shown from highest to lowest forecasted values. The distances between the curves shows how well the model predicts the actual data.

62
A variety of fit statistics are provided. These include SSE, MSE=SSE/(n-2), ASE=SSE/n, RMSE=SQRT(MSE), RASE=SQRT(SSE), FPE = MSE (n+p+1)/n, MAX = largest error in terms of absolute value, where n = no. of observations, p=no. of variables in model (one in our case). Schwartz’s Bayesian Criterion and Akaike’s Information Criterion are used for model selection (comparing one model to another). Schwartz’s adjusts the residual squared error for the number of parameters estimated, while Akaike’s is a relative measure of information lost from fitting the model.
, ASE=SSE/n, RMSE=SQRT(MSE), RASE=SQRT(SSE), FPE = MSE (n+p+1)/n, MAX = largest error in terms of absolute value, where n = no. of observations, p=no. of variables in model (one in our case). Schwartz’s Bayesian Criterion and Akaike’s Information Criterion are used for model selection (comparing one model to another). Schwartz’s adjusts the residual squared error for the number of parameters estimated, while Akaike’s is a relative measure of information lost from fitting the model..")
63
Kwatts vs. Temp Example 2 Another approach to modeling the relationship between Kwatts and Temp is to use a nonlinear regression This is easily accomplished in Enterprise Miner – highlight the regression node, then in the left hand panel select yes for polynomial terms We use the default of two terms Is the fit any better???

65
Multiple Regression Consider the following data relating family size and income to food expenditures: familyfood $income $ family size 15.228 3 25.126 3 35.632 2 44.624 1 511.354 4 68.159 2 77.844 3 85.830 2 95.140 1 101882 6 114.942 3 1211.858 4 135.228 1 144.820 5 157.942 3 166.447 1 1720112 6 1813.785 5 195.131 2 202.926 2

66
Multiple Regression We can run this problem in Enterprise Miner using the same approach followed with the previous example On our model field we have placed the data source called foodexpenditures, and also both Multiplot and StatExplore found under the Explore tab above the model field Highlight foodexpenditures, then in the left-hand panel under Training, find variables and click on the box to the right to open up the variables Change the role of family to rejected (it is just the number of the observation) and change the level of food_ to target, and income_, food_, and fam_size to interval, then click OK
 and change the level of food_ to target, and income_, food_, and fam_size to interval, then click OK")
67
Foodexpenditures Model

68
Highlight the StatExplore node, right-click to Run, then select Results. Correlations between the input variables and the target are provided, along with basic statistics. The input variables are ordered by the size of the correlations. Now close out the results window and run the regression node and obtain results

69
Starting from the upper left and going clockwise, these windows show the fit between target and predicted in percentile terms, the various fit statistics, model output (estimates, F and t stats, R-square), and the three effects (intercept and slopes for the two input variables with bars represent size and color represents direction). The model is significant and is a good fit with the data.

70
What happens in regression analysis when the target variable is binary? There are many situations when the target variable is binary – some examples: whether a customer will or will not receive credit whether a customer will or will not response to a promotion Whether a firm will go bankrupt in a year Whether a student will pass an exam!!!

71
Passing an Exam Data Student idOutcomeStudy Hours 103 2134 3017 406 5012 6115 7126 8129 9014 10158 1102 12131 13126 14011

72
Running a linear regression to predict pass/don’t pass as a function of hours of study provides a model that doesn’t correctly model the data. The data are given in exampassing.xls

73
The Enterprise Miner results show a poor fit on a percentile basis between predicted and target – another modeling approach is needed.

74
Similar to linear regression, two main differences Y (outcome or response) is categorical Yes/No Approve/Reject Responded/Did not respond Result is expressed as a probability of being in either group. Logistic Regression

75
Comparing the Logistic & Linear Regression Models

76
Logisitic regression p = Prob(y=1|x) = exp(a+bx)/[1+exp(a+bx)] 1-p =1/[1+exp(a+bx)] ln [p/(1-p)] = a + bx where: exp or e is the exponential function (e=2.71828…) ln is the natural logarithm (ln(e) = 1) p is probability that the event y occurs given x, and can range between 0 and 1 p/(1-p) is the "odds ratio" ln[p/(1-p)] is the log odds ratio, or "logit" all other components of the regression model are the same
![Logisitic regression p = Prob(y=1|x) = exp(a+bx)/[1+exp(a+bx)] 1-p =1/[1+exp(a+bx)] ln [p/(1-p)] = a + bx where: exp or e is the exponential function (e= …) ln is the natural logarithm (ln(e) = 1) p is probability that the event y occurs given x, and can range between 0 and 1 p/(1-p) is the odds ratio ln[p/(1-p)] is the log odds ratio, or logit all other components of the regression model are the same](http://images.slideplayer.com/18/6184086/slides/slide_76.jpg "Logisitic regression p = Prob(y=1|x) = exp(a+bx)/[1+exp(a+bx)] 1-p =1/[1+exp(a+bx)] ln [p/(1-p)] = a + bx where: exp or e is the exponential function (e= …) ln is the natural logarithm (ln(e) = 1) p is probability that the event y occurs given x, and can range between 0 and 1 p/(1-p) is the odds ratio ln[p/(1-p)] is the log odds ratio, or logit all other components of the regression model are the same")
77
Odds Ratio Frequently used Related to probability of an event as follows: Odds Ratio = p/(1-p) Example: Probability of firm going bankrupt =.25 Odds firm will go bankrupt =.25/(1-.25) = 1/3 or 3 to 1 This is how sports books calculate odds (e.g., if odds of VU winning a championship are 2:1, probability is 1/3 ln [p/(1-p)] = a + bx means that as x increases by 1, the natural log of the odds ratio increases by b, or the odds ratio increase by a factor of exp(b)
![Odds Ratio Frequently used Related to probability of an event as follows: Odds Ratio = p/(1-p) Example: Probability of firm going bankrupt =.25 Odds firm will go bankrupt =.25/(1-.25) = 1/3 or 3 to 1 This is how sports books calculate odds (e.g., if odds of VU winning a championship are 2:1, probability is 1/3 ln [p/(1-p)] = a + bx means that as x increases by 1, the natural log of the odds ratio increases by b, or the odds ratio increase by a factor of exp(b)](http://images.slideplayer.com/18/6184086/slides/slide_77.jpg "Odds Ratio Frequently used Related to probability of an event as follows: Odds Ratio = p/(1-p) Example: Probability of firm going bankrupt =.25 Odds firm will go bankrupt =.25/(1-.25) = 1/3 or 3 to 1 This is how sports books calculate odds (e.g., if odds of VU winning a championship are 2:1, probability is 1/3 ln [p/(1-p)] = a + bx means that as x increases by 1, the natural log of the odds ratio increases by b, or the odds ratio increase by a factor of exp(b)")
78
Probability, Odds Ratio, LN of Odds Ratio

79
Running the exam data: Change regression type from linear regression to logistic regression Highlight the data node; on left-hand panel under Train open variables and change the level of outcome to binary

80
Results show a much better fit (upper left) and only one misclassification (lower right – a false negative).
 and only one misclassification (lower right – a false negative).")
81
The results show that the odds ratio = p(1-p) = exp(- 8.4962+0.4949x). For every additional hour of study the odds ratio increases by a factor of exp(0.4949)= 1.640
=")
82
Understanding Response Rate and Lift To better understand the top left chart, change cumulative lift to cumulative % response. The observations are ranked by the predicted probability of response (highest to lowest) for each observation (from the fitted model).
 for each observation (from the fitted model)..")
83
Understanding Response Rate and Lift Since the first 6 passes were correctly classified, the cumulative % response is 100% through the 40 th percentile. At the 50 th percentile the next observation with the highest predicted probability is a non-response, so the cumulative response drops to 6/7 or 85.7%. The 8 th ranked observation, between the 55 th and 60 th percentile, is a positive response, so the cumulative % response is about 7/8 or 87%. Since there are no more positive responses after the 60 th percentile, the cumulative response rate will drop to 50%. The chart compares how well the cumulative ranked predictions lead to a match between actual and predicted responses

84
Understanding Response Rate and Lift Lift calculates the ratio of the actual response rate (passing) of the top n% of the ranked observations to the overall response rate. Cumulative lift is likewise defined. At the 50 th percentile, the cumulative % response is 88.7%, the cumulative base response is 50%, for a lift of 1.7142.

85
On the Properties Panel, click on Exported Data to see the predicted probabilities and response for each observation and compare to the actual response.

86
Logistic regression uses maximum likelihood (and not sum of squared errors) to estimate the model parameters. The results below show that the model is highly significant based on a chi-square test. The Wald chi-square statistic tests whether an effect is significant or not.

87
Bankruptcy Prediction To predict bankruptcy a year in advance, you might collect: working capital/total assets (WC/TA) retained earnings/total assets (RE/TA) earnings before interest and taxes/total assets (EBIT/TA) market value of equity/total debt (MVE/TD) sales/total assets (S/TA)
 retained earnings/total assets (RE/TA) earnings before interest and taxes/total assets (EBIT/TA) market value of equity/total debt (MVE/TD) sales/total assets (S/TA)")
88
Bankruptcy Training Data FirmWC/TARE/TAEBIT/TAMVE/TDS/TABR/NB 10.01650.11920.20350.8131.67021 20.14150.38680.06810.57551.05791 30.58040.33310.0810.57551.05791 40.23040.2960.12250.41023.08091 50.36840.39130.05240.16581.15331 60.15270.33440.07830.77361.50461 70.11260.30710.08391.34291.57361 80.01410.23660.09050.58631.46511 90.2220.17970.15260.34591.72371 100.27760.25670.16420.29681.89041 110.26890.17290.02870.12240.92770 120.2039-0.04760.12630.89651.04570 130.5056-0.19510.20260.5381.95140 140.17590.13430.09460.19551.92180 150.35790.15150.08120.19911.45820 160.28450.20380.01710.33571.32580 170.12090.2823-0.01130.31572.32190 180.12540.19560.00790.20731.4890 190.17770.08910.06950.19241.68710 200.24090.1660.07460.25161.85240

89
Bankruptcy Example Using the BankruptTrain.xls data create a SAS data file called bankrupt BR_NB: role is target and level is binary Firm: role is rejected and level is nominal (it is simply the firm number) Remaining five financial ratio variables: role is input and level is interval
 Remaining five financial ratio variables: role is input and level is interval")
90
Create a diagram named bankrupt1. Drag and drop the data node onto the model. Highlight the data node and on the left hand panel under variables click on the box to its right to see the variables data

91
From the Explore tab drag and drop the StatExplore node onto the diagram and link it to the bankrupt node. Highlight the StatExplore node, right-click and run it, and obtain results. On top, correlations between the five input variables and the target are shown via bars ordered from largest to smallest. Below the mean variable score for bankrupt vs. non- bankrupt observations is shown.

92
From the Model tab drag and drop the regression node onto the diagram and connect it to the bankrupt node. Highlight the regression node and run, and obtain the results

93
The results show that the model fits the data very well with highly significant overall chi square statistic, low error values, and 0 misclassifications. Cumulative lift shows that for the top 50% of observations that are bankrupt, they are twice as likely to be classified as bankrupt.

94
Scoring Once you have specified a model you might wish to apply it to new data whose outcome is unknown -- make predictions This can be easily accomplished in Enterprise Miner using scoring Convert the data set BankruptScore.xls to a SAS file called bankruptscore. The role of this data is score.

95
Bankruptcy Scoring Data FirmWC/TARE/TAEBIT/TA MVE/TD S/TA A0.17590.13430.0956 0.1955 1.9218 B0.37320.3483-0.0013 0.3483 1.8223 C0.17250.32380.104 0.8847 0.5576 D0.1630.35550.011 0.373 2.8307 E0.19040.20110.1329 0.558 1.6623 F0.11230.22880.01 0.1884 2.7186 G0.07320.35260.0587 0.2349 1.7432 H0.26530.26830.0235 0.5118 1.835 I0.1070.07870.0433 0.1083 1.2051 J0.29210.2390.9673 0.3402 0.9277

96
Drag and drop the bankruptscore data node to the bankrupt1 diagram. From the Assess tab, drag and drop the Score node into the diagram. Link the regression and bankruptscore nodes together and connect them to the Score node.

97
Run the Score node and obtain the Results. Of the 10 firms, 6 are predicted to become bankrupt.

98
For details about the individual predictions, highlight the Score node and on the left-hand panel click on the square to the right of Exported Data. Then in the box that appears click on the row whose Port entry is Score. Then click on Explore.

99
The lower portion of the output is shown below. The predictions are given, along with the probabilities of the firm becoming bankrupt or not.

100
Regression Using Selection Models When there are a number of possible input variables, procedures are available to sort through them and include those that have a certain level of statistical significance SAS Enterprise Miner 5.3 offers three selection methods: Backward Forward Stepwise

101
Regression Using Selection Models Backward: training begins with all candidate effects in the model and removes effects until the stay significance level or the stop criterion is met Forward: training begins with no candidate effects in the model and adds effects until the entry significance level or the stop criterion is met. Stepwise: training begins as in the forward model but may remove effects already in the model. This continues until the stay significance level or the stop criterion is met Note that the default significance levels (p values) values are 0.05 and no stop criteria (such as maximum number of steps in the regression) are set
 values are 0.05 and no stop criteria (such as maximum number of steps in the regression) are set.")
102
Regression Using Selection Models – Bankruptcy Model To select stepwise regression for the bankruptcy model, highlight the regression node and in the properties panel under Selection Model choose Stepwise. The default significance level of 0.05 is used

103
Regression Using Selection Models – Bankruptcy Model Interestingly, the Training Model only uses RE/TA as a predictor There are 3 misclassifications (.15 rate) in this set vs. 0 in the original model The results are very different: the original model with all 5 input variables predicted bankruptcy for G, E, C, and J, while the stepwise model predicted B, C, D, F, G, H, and J would become bankrupt. Changing the significance levels to 0.1 (to make it easier for input variables to enter/leave the stepwise model) produces the same results
 produces the same results.")
Similar presentations