Download presentation
Presentation is loading. Please wait.

1
Hadoop & Cheetah

2
Key words Cluster data center – Lots of machines thousands Node a server in a data center – Commodity device fails very easily Slot a fraction of a server – Allows you to share a server among many jos Job an application that the user wants to run – There are multiple of these in the data center Task/Worker a fraction of a job – Allows you to achieve parallelism

3
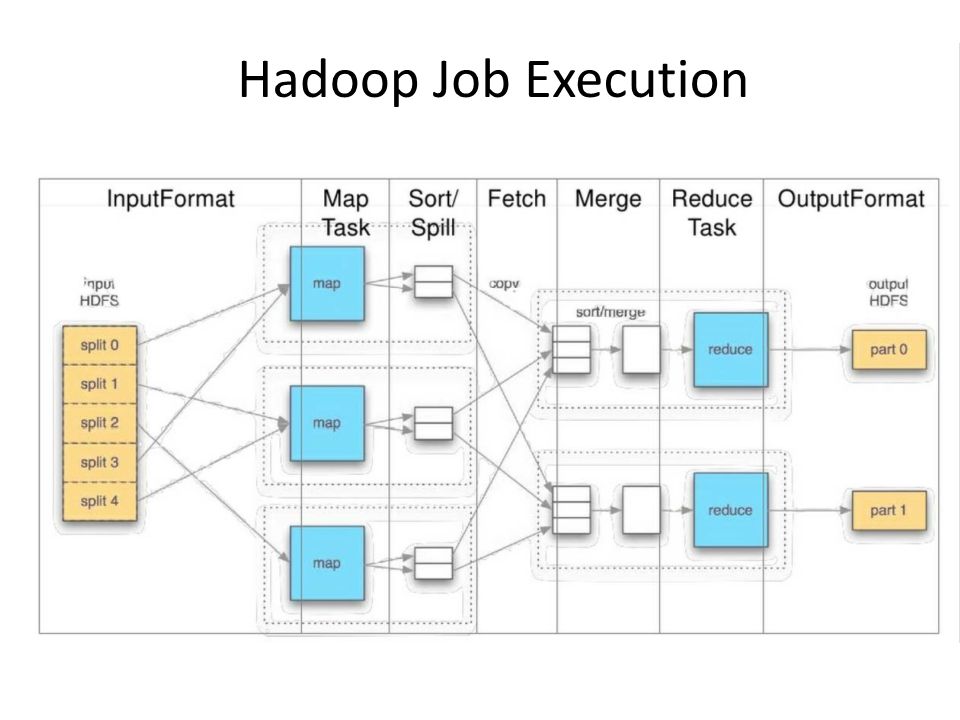
Hadoop Exploit large amount of resources easily Manages and automates – Failure recovery – Scale of WSC Dealing with hardware idiosyncrasies – Resource Management/Sharing

6
Map-Reduce paradigm Master – Runs a scheduling algo to place tasks on a slot Scheduling allows for sharing – Runs failure detection and resolution algorithms – Monitors job progress and speeds up the job – Partitions user data into chunks – Determines the number of tasks (Maps and Reduce) Speed: more workers faster, ideally more workers than machines for parallelism State: master tracks O(M*R) state and makes O(M+R) scheduling decisions Worker: runs reduce or map task
 Speed: more workers faster, ideally more workers than machines for parallelism State: master tracks O(M*R) state and makes O(M+R) scheduling decisions Worker: runs reduce or map task")
7
Map Input Output: a list of Takes a key-value pair does some preprocessing and creates another key-value pair. The output is segregated into N different files. – One for each reducers – The output is stored on local disk in temporary storage

8
Reduce Input: a pair Output: a pair Aggregates information from multiple mappers 3 stages: – Shuffle: transfer data from all map to reduce – Sort: sort the data that was transferred – Reduce: aggregate the data Output is stored: – In persistent storage.

9
Combine Ideally similar to reduce EXCEPT – run on the same node as the map – Run on only the data a mapper creates – Preliminary aggregation to reduce amount of data transferred

10
Example Task “hello world. Goodbye world. Hello hadoop goodbye hadoop”

12
Failure Recovery Worker failure – Detecting: keep-alive pings – Resolution: restart all task currently running For completed tasks: – If Map restart – If Reduce do nothing: output stored in external memory. Master failure – Periodically store master data structures – If master fails roll back to last stored structure.

13
Dealing with hardware Performance issues Locality – Place task on node where data is stored – Else try to place task close to data Straggler detection and mitigation – If a task is running really slow – Restart the task – 44% worse without this.

14
Resource Management/Sharing Cluster Scheduler Shares the resource – Decides which job should run when and where – Sharing algorithms FIFO: no real sharing Fair-scheduler: each user is given a number of tokens – The user’s job must get at least token number of slots Capacity Scheduler – Each job as a queue: task serviced in FIFO manner – Determine number of cluster slots to allocate to each queue

15
Problems How do determine an effective partition algorithm? Will hash always work? How do you determine the optimal # of reducers? What is optimal scheduling? Resource sharing algorithms.

16
Cheetah Relational data ware-houses – Highly optimized for storing and querying relational data. – Hard to scale to 100s,1000s of nodes MapReduce – Handles failures & scale to 1000s node – Lacks a declarative query inter-face Users have to write code to access the data May result in redundant code Requires a lot of effort & technical skills. How do you get the best of both worlds?

17
Main Challenges With Hadoop, it is hard to: – Perform SQL like joins Developers need to track: – Location of tables on disks (HDFS) Hard to get good performance out of vanila hadoop – Need to go through crafty coding to get good performance
 Hard to get good performance out of vanila hadoop – Need to go through crafty coding to get good performance")
18
Architecture Simple yet efficient Open:also provide a simple, non-SQL interface

19
Query MR Job Query is sent to the node that runs Query Driver Query Driver Query MapReduce job Each node in the Hadoop cluster provides a data access primitive (DAP) interface
 interface")
20
Performance Optimizations Data Storage & Compression MapReduce Job Configuration MultiQuery Optimization Exploiting Materialized Views LowLatency Query Optimization

21
Storage Format Text (in CSV format) – Simplest storage format & commonly used in web access logs. Serialized java object Row-based binary array – Commonly used in row-oriented database systems Columnar binary array Storage format -huge impact on both compression ratio and query performance. In Cheetah, we store data in columnar format whenever possible

22
Columnar Compression Compression type for each column set is dynamically determined based on data in each cell ETL phase- best compression method is chosen After one cell is created, it is further compressed using GZIP.

23
MapReduce Job Configuration # of map tasks - based on the # of input files & number of blocks per file. # of reduce tasks -supplied by the job itself & has a big impact on performance. query output – Small:map phase dominates total cost. – Large:it is mandatory to have sufficient number of reducers to partition the work. Heuristics – #of reducers is proportional to the number of group by columns in the query. – if the group by column includes some column with very large cardinality, we increase # of reducers as well.

24
MultiQuery Optimization In Cheetah allow users to simultaneously submit multiple queries & execute them in a single batch, as long as these queries have the same FROM and DATES clauses

25
Map Phase Shared scanner-shares the scan of the fact tables & joins to the dimension tables Scanner will attach a query ID to each output row Output from different aggregation operators will be merged into a single output stream.

26
Reduce Phase Split the input rows based on their query Ids Send them to the corresponding query operators.

27
Exploiting Materialized Views(1) Definition of Materialized Views – Each materialized view only includes the columns in the face table, i.e., excludes those on the dimension tables. – It is partitioned by date Both columns referred in the query reside on the fact table, Impressions Resulting virtual view has two types of columns - group by columns & aggregate columns.

28
Exploiting Materialized Views(2) View Matching and Query Rewriting – To make use of materialized view Refer virtual view that corresponds to same fact table that materialized view is defined upon. Non-aggregate columns referred in the SELECT and WHERE clauses in the query must be a subset of the materialized view’s group by columns Aggregate columns must be computable from the materialized view’s aggregate columns.

29
Replace the virtual view in the query with the matching materialized view

30
LowLatency Query Optimization Current Hadoop implementation has some non- trivial overhead itself – Ex:job start time,JVM start time Problem :For small queries, this becomes a significant extra overhead. – In query translation phase: if size of the input file is small it may choose to directly read the file from HDFS and then process the query locally.

31
Questions

Similar presentations













 How MapReduce Works (in Hadoop) Shivnath Babu.>")







