Download presentation
Presentation is loading. Please wait.

1
PAKDD'15 DATA MINING COMPETITION: GENDER PREDICTION BASED ON E-COMMERCE DATA Team members: Maria Brbic, Dragan Gamberger, Jan Kralj, Matej Mihelcic, Matija Piskorec, Tomislav Smuc

2
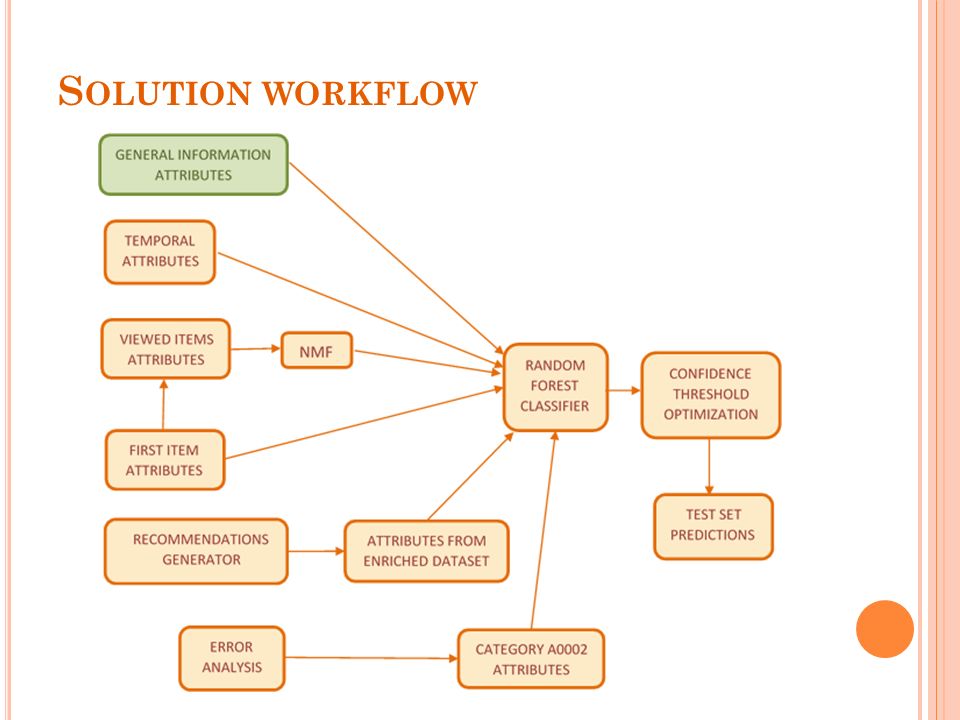
OVERVIEW Team name: gambi Final score: 0.8102 (12. position) Crucial part of the work: how to construct good features? Feature construction process: 1. Features containing general information 2. Construction from the time slot information 3. Construction from the information about the viewed items 4. Construction from the dataset enriched using recommendation algorithms 5. Construction from the error analysis
 Crucial part of the work: how to construct good features. Feature construction process: 1. Features containing general information 2. Construction from the time slot information 3. Construction from the information about the viewed items 4. Construction from the dataset enriched using recommendation algorithms 5. Construction from the error analysis.")
3
S OLUTION WORKFLOW

5
GENERAL INFORMATION FEATURES Number of items viewed during the session Duration of the session Some sessions had unreasonable length Assumption: some users forgot to log out Too long sessions got missing value Number of items divided by duration

6
S OLUTION WORKFLOW

7
TEMPORAL FEATURES Day of the week, month, year 7 features for the day of the week Extra binary features for Saturday and Sunday Extra binary features for the beginning of the month, middle and end Month Christmas time Five or less days before Christmas Hour Exact hour (24 features) Binary features: working hours, morning, evening, night The percentage of males in a given time slot
 Binary features: working hours, morning, evening, night The percentage of males in a given time slot")
8
S OLUTION WORKFLOW

9
VIEWED ITEMS FEATURES Single categories One feature for each category ID appearing in at least 3 distinct sessions Categories pairs and triplets One feature for each pair/triplet of categories appearing in at least 3 distinct sessions calculated as the number of joint appearances Ordered pairs of categories Number of times category i precedes category j at the distance k or less (for k=1,2,3) First category Category that was viewed first in the session for A,B,C hierarchy levels
 First category Category that was viewed first in the session for A,B,C hierarchy levels")
10
VIEWED ITEMS FEATURES Rare categories Categories appearing in less than three instances One feature for each hierarchy level belonging to the specific parent category calculated as a sum of all rare categories Due to the sparsity of generated features (0.15% of the elements wer non-zero) we performed non-negative matrix factorization (NMF) on merged train and test set 100 factors from NMF were then used as features
 we performed non-negative matrix factorization (NMF) on merged train and test set 100 factors from NMF were then used as features")
11
S OLUTION WORKFLOW

12
DATA ENRICHMENT Idea: to enrich data by using recommendation algorithms Weighted item k-NN with 10 nearest neighbours was used to predict new items For each session we recommended 4 new items with top ranked scores Recommendations for sessions containing only items unique to the sessions were ignored New features constructed from this more abundant set of items For each category all appearances of distinct items that were viewed only by a predefined percentage of females/males were summed

13
S OLUTION WORKFLOW

14
ERROR ANALYSIS We extracted instances labelled as males that were misclassified on a cross-validation The main source of errors: products in A00002 category and its subcategories New feature for sessions with A00002 category calculated as the percentage of males that viewed the same B product from A00002 category in the same time slot If there were more B products from A00002 category, only the first one was taken into account The number of sessions in which the B product in a given time slot appeared had to be greater than one Sessions without A00002 category got missing value for feature value

15
CLASSIFICATION We used 642 features in total Classification algorithm: Random Forest with 1000 trees After obtaining predictions we optimized the threshold to predict more males accurately on the cost of females misclassification Using 10-fold cross-validation results we checked where to put a threshold on a classifier confidence Chosen threshold was then used on the test set predictions Cross validation score: 0.822, 0.862 after optimization Preliminary evaluation score: 0.8235 Final evaluation score: 0.8102

16
CLASSIFICATION We also analyzed the importance of each generated feature The most important features are temporal and NMF features

17
THANK YOU FOR YOUR ATTENTION!

Similar presentations











 Given -> A set of classified examples “instances” Produce -> A way of classifying new examples.>")



 in a sequence. a new classifier should focus on those cases which were incorrectly classified.>")
, Tree and Forest>")


