Download presentation
Presentation is loading. Please wait.

1
Application Development On AWS MOULIKRISHNA KOPPOLU CHANDAN SINGH RANA

2
Proposals Recommender System 1. Amazon Ec2 2. Hadoop 3. Mahout 4. Amazon review Dataset Analytical System 1. Amazon EMR 2. Amazon Ec2 3. Hive 4. S3

3
Dataset (Amazon Review Dataset) Arts Jewelery Automotives Baby Products
 Arts Jewelery Automotives Baby Products")
4
Recommender System Implementation

5
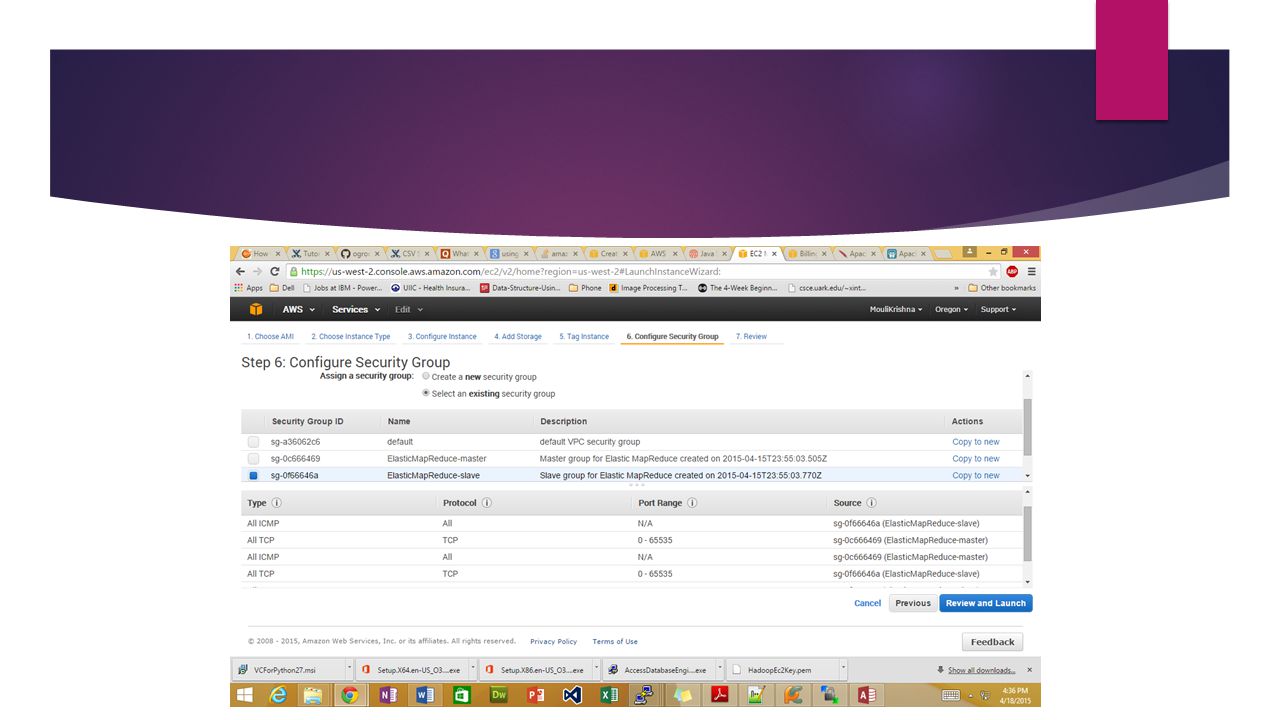
EC2 Set up Launch 3 EC2 micro instances for 3-node Hadoop setup Choose Amazon Machine Image (Ubuntu14.04 LTS) Set up parameters like the storage, number of instances, security parameters. Create a key-pair group for all three EC2 instances to allow access to them through a client like putty Download the key and set up putty for all three instances using instance’s hostname and the key

10
Recommender System Implementation

11
Download Hadoop 1.2.1 Configure Hadoop on all three instances Start all services from the master node, which in turn runs corresponsding services on both secondary master node and slave node Test the Hadoop working by running a sample Map-Reduce job on master node. [Command : Hadoop jar hadoopexamples-1.2.1.jar pi 10 100000 ]

12
Recommender System Implementation

13
Download mahout 0.9 on master node Mahout 0.9 only works with Hadoop 1.X versions. Mahout 1.10 is available for Hadoop 2.X but with completely different setup.

14
Recommender System Implementation

16
Upload the Amazon review data set in the form of csv. To run a recommender job on mahout, the dataset should not have any string literals. So the csv file is converted into a set of integers. Using mahout recommender jar, run the recommendation job using command hadoop jar /home/ubuntu/mahout-distribution-0.9/mahout-core-0.9-job.jar org.apache.mahout.cf.taste.hadoop.item.RecommenderJob -s SIMILARITY_COOCCURRENCE --input u.data --output output

17
Results

19
Analytical system Steps involved: 1. Set up S3 bucket instance 2. Set up emr cluster 3. Set up hive program as a job in emr 4. Create table and Upload the data into the hive table using hiveQL

24
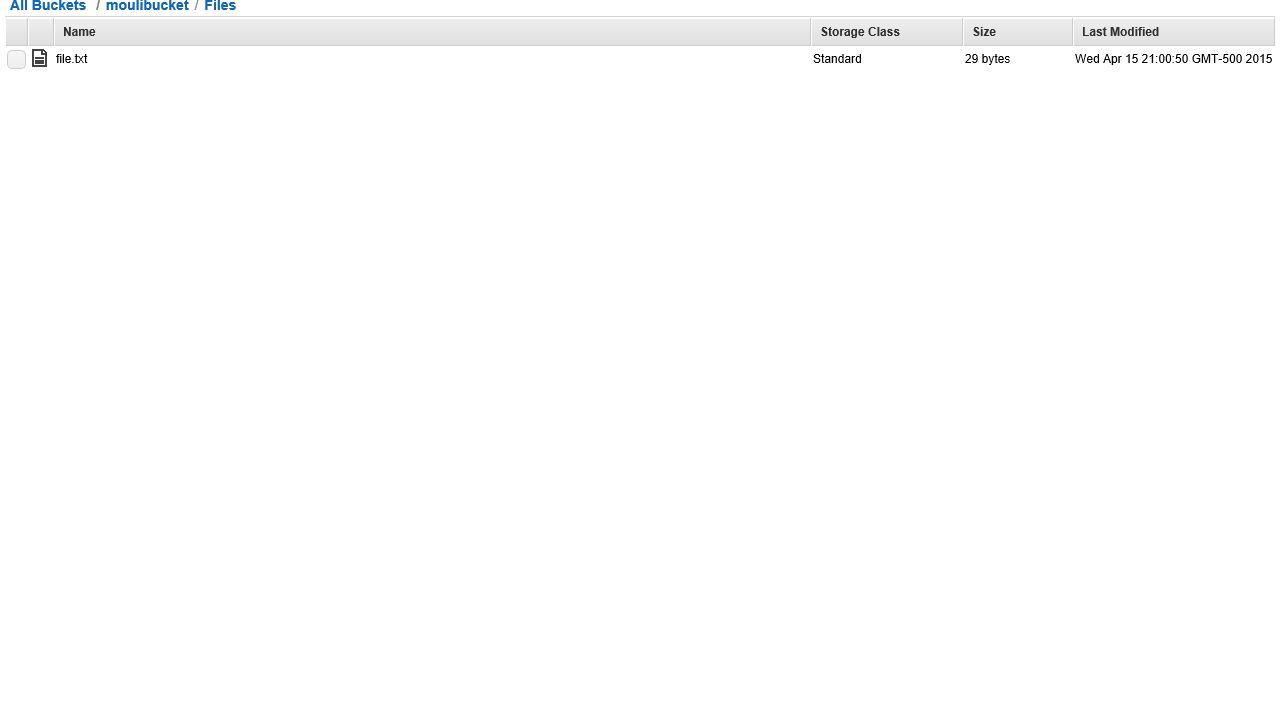
Sample HiveQl query CREATE EXTERNAL TABLE IF NOT EXISTS sampledb( name STRING, course STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "," lines terminated by '\n' LOCATION 's3://moulibucket/Files';
 ROW FORMAT DELIMITED FIELDS TERMINATED BY , lines terminated by \n LOCATION s3://moulibucket/Files ;")
32
THANK YOU!

Similar presentations