Download presentation
Presentation is loading. Please wait.

2
File Concept Access Methods Directory Structure File-System Mounting File Sharing File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management

3
To explain the function of file systems To describe the interfaces to file systems To discuss file-system design tradeoffs, including access methods, file sharing, file locking, and directory structures To explore file-system protection

4
Contiguous logical address space Types: Data numeric character binary Program

5
None - sequence of words, bytes Simple record structure Lines Fixed length Variable length Complex Structures Formatted document Relocatable load file Can simulate last two with first method by inserting appropriate control characters Who decides: Operating system Program

6
Name – only information kept in human-readable form Identifier – unique tag (number) identifies file within file system Type – needed for systems that support different types Location – pointer to file location on device Size – current file size Protection – controls who can do reading, writing, executing Time, date, and user identification – data for protection, security, and usage monitoring Information about files are kept in the directory structure, which is maintained on the disk
 identifies file within file system Type – needed for systems that support different types Location – pointer to file location on device Size – current file size Protection – controls who can do reading, writing, executing Time, date, and user identification – data for protection, security, and usage monitoring Information about files are kept in the directory structure, which is maintained on the disk")
7
File is an abstract data type Create Write Read Reposition within file Delete Truncate Open(F i ) – search the directory structure on disk for entry F i, and move the content of entry to memory Close (F i ) – move the content of entry F i in memory to directory structure on disk
 – search the directory structure on disk for entry F i, and move the content of entry to memory Close (F i ) – move the content of entry F i in memory to directory structure on disk")
8
Several pieces of data are needed to manage open files: File pointer: pointer to last read/write location, per process that has the file open File-open count: counter of number of times a file is open – to allow removal of data from open-file table when last processes closes it Disk location of the file: cache of data access information Access rights: per-process access mode information

9
Provided by some operating systems and file systems Mediates access to a file Mandatory or advisory: Mandatory – access is denied depending on locks held and requested Advisory – processes can find status of locks and decide what to do

10
import java.io.*; import java.nio.channels.*; public class LockingExample { public static final boolean EXCLUSIVE = false; public static final boolean SHARED = true; public static void main(String arsg[]) throws IOException { FileLock sharedLock = null; FileLock exclusiveLock = null; try { RandomAccessFile raf = new RandomAccessFile("file.txt", "rw"); // get the channel for the file FileChannel ch = raf.getChannel(); // this locks the first half of the file - exclusive exclusiveLock = ch.lock(0, raf.length()/2, EXCLUSIVE); /** Now modify the data... */ // release the lock exclusiveLock.release();
![import java.io.*; import java.nio.channels.*; public class LockingExample { public static final boolean EXCLUSIVE = false; public static final boolean SHARED = true; public static void main(String arsg[]) throws IOException { FileLock sharedLock = null; FileLock exclusiveLock = null; try { RandomAccessFile raf = new RandomAccessFile( file.txt , rw ); // get the channel for the file FileChannel ch = raf.getChannel(); // this locks the first half of the file - exclusive exclusiveLock = ch.lock(0, raf.length()/2, EXCLUSIVE); /** Now modify the data...](http://images.slideplayer.com/20/6040478/slides/slide_10.jpg "*/ // release the lock exclusiveLock.release();.")
11
// this locks the second half of the file - shared sharedLock = ch.lock(raf.length()/2+1, raf.length(), SHARED); /** Now read the data... */ // release the lock sharedLock.release(); } catch (java.io.IOException ioe) { System.err.println(ioe); }finally { if (exclusiveLock != null) exclusiveLock.release(); if (sharedLock != null) sharedLock.release(); }
; } catch (java.io.IOException ioe) { System.err.println(ioe); }finally { if (exclusiveLock != null) exclusiveLock.release(); if (sharedLock != null) sharedLock.release(); }.")
13
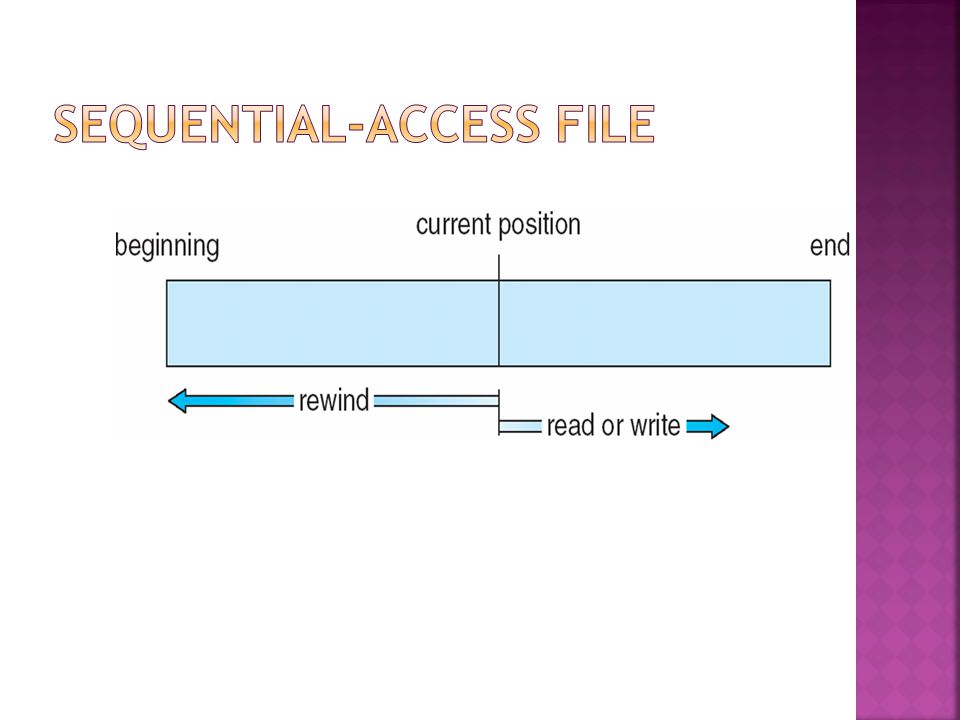
Sequential Access read next write next reset no read after last write (rewrite) Direct Access read n write n position to n read next write next rewrite n n = relative block number
 Direct Access read n write n position to n read next write next rewrite n n = relative block number")
17
A collection of nodes containing information about all files F 1 F 2 F 3 F 4 F n Directory Files Both the directory structure and the files reside on disk Backups of these two structures are kept on tapes

18
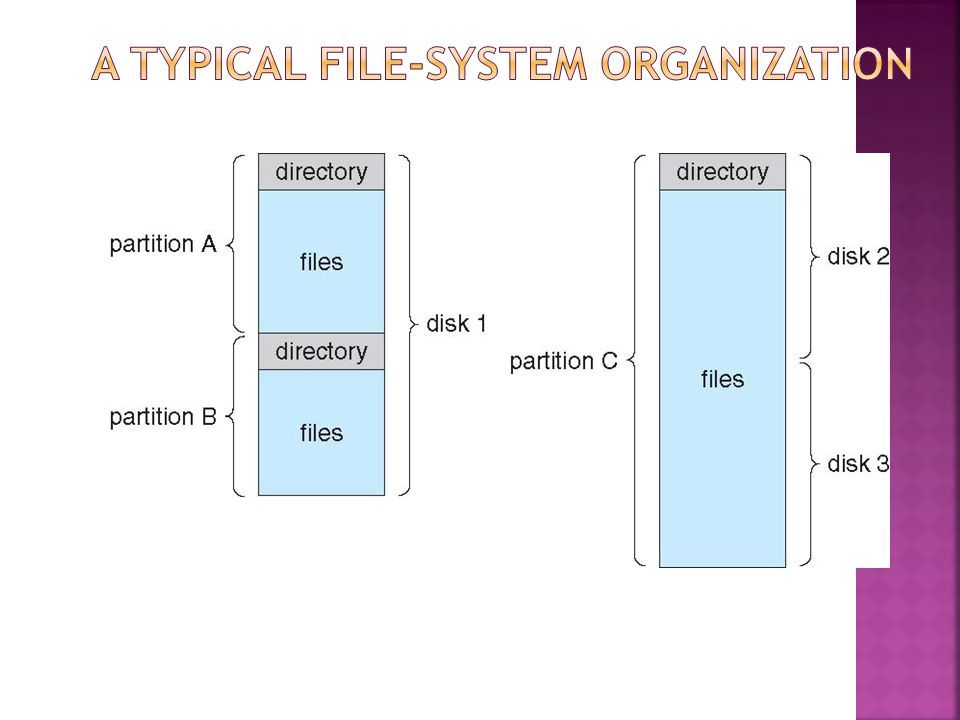
Disk can be subdivided into partitions Disks or partitions can be RAID protected against failure Disk or partition can be used raw – without a file system, or formatted with a file system Partitions also known as minidisks, slices Entity containing file system known as a volume Each volume containing file system also tracks that file system’s info in device directory or volume table of contents As well as general-purpose file systems there are many special-purpose file systems, frequently all within the same operating system or computer

20
Search for a file Create a file Delete a file List a directory Rename a file Traverse the file system

21
Efficiency – locating a file quickly Naming – convenient to users Two users can have same name for different files The same file can have several different names Grouping – logical grouping of files by properties, (e.g., all Java programs, all games, …)
")
22
A single directory for all users Naming problem Grouping problem

23
Separate directory for each user Path name Can have the same file name for different user Efficient searching No grouping capability

25
Efficient searching Grouping Capability Current directory (working directory) cd /spell/mail/prog type list
 cd /spell/mail/prog type list")
26
Absolute or relative path name Creating a new file is done in current directory Delete a file rm Creating a new subdirectory is done in current directory mkdir Example: if in current directory /mail mkdir count mail progcopyprtexpcount Deleting “mail” deleting the entire subtree rooted by “mail”

27
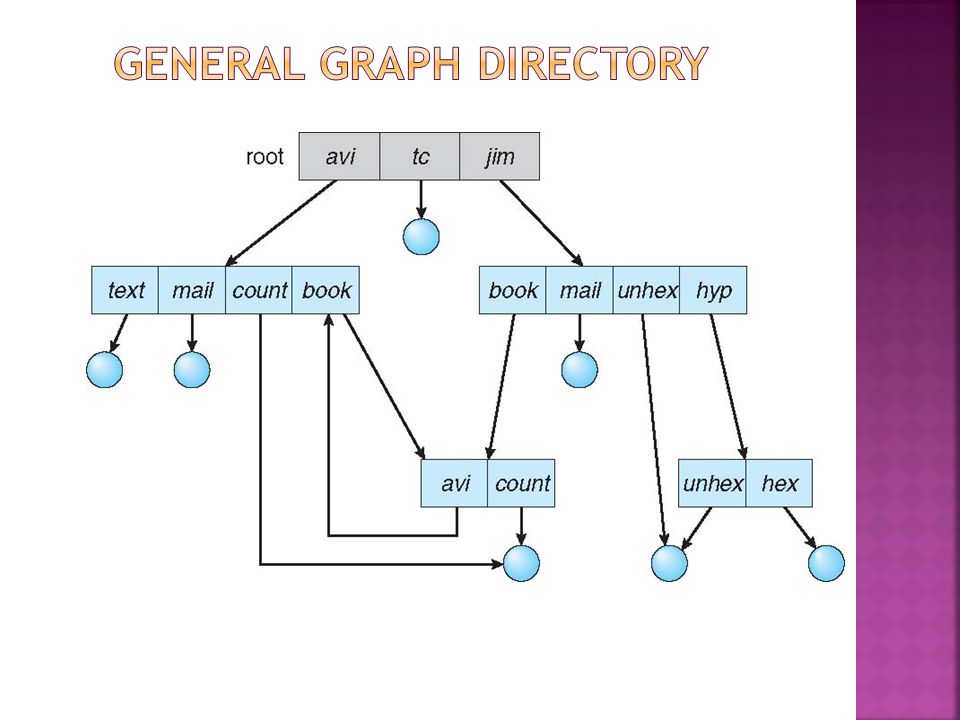
Have shared subdirectories and files

28
Two different names (aliasing) If dict deletes list dangling pointer Solutions: Backpointers, so we can delete all pointers Variable size records a problem Backpointers using a daisy chain organization Entry-hold-count solution New directory entry type Link – another name (pointer) to an existing file Resolve the link – follow pointer to locate the file
 If dict deletes list dangling pointer Solutions: Backpointers, so we can delete all pointers Variable size records a problem Backpointers using a daisy chain organization Entry-hold-count solution New directory entry type Link – another name (pointer) to an existing file Resolve the link – follow pointer to locate the file")
30
How do we guarantee no cycles? Allow only links to file not subdirectories Garbage collection Every time a new link is added use a cycle detection algorithm to determine whether it is OK

31
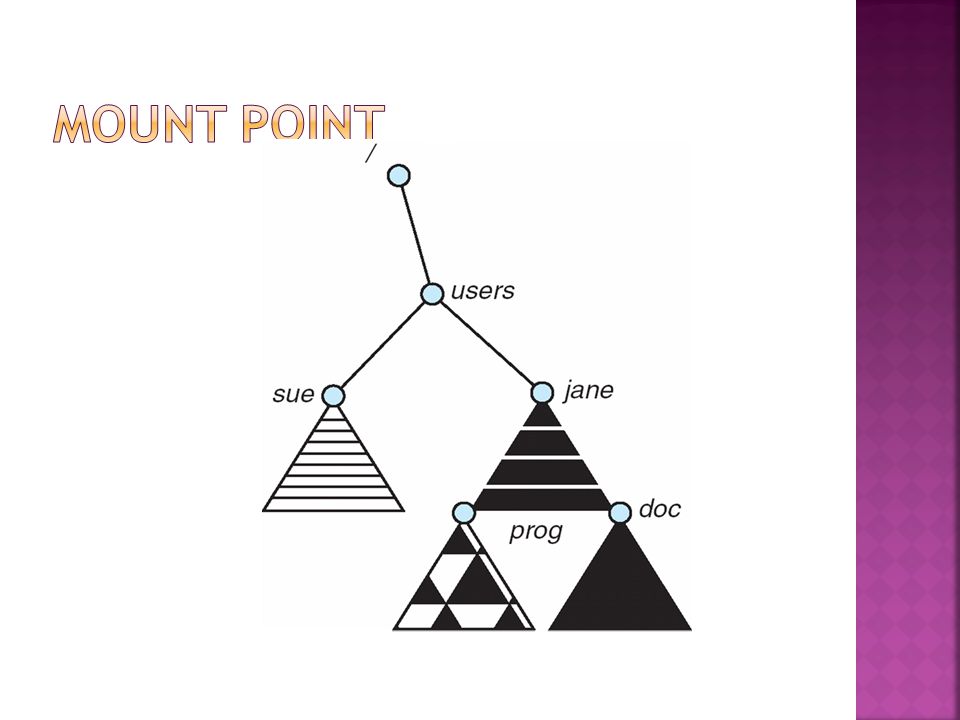
A file system must be mounted before it can be accessed A unmounted file system (i.e., Fig. 11- 11(b)) is mounted at a mount point
) is mounted at a mount point.")
34
Sharing of files on multi-user systems is desirable Sharing may be done through a protection scheme On distributed systems, files may be shared across a network Network File System (NFS) is a common distributed file-sharing method
 is a common distributed file-sharing method")
35
User IDs identify users, allowing permissions and protections to be per-user Group IDs allow users to be in groups, permitting group access rights

36
Uses networking to allow file system access between systems Manually via programs like FTP Automatically, seamlessly using distributed file systems Semi automatically via the world wide web Client-server model allows clients to mount remote file systems from servers Server can serve multiple clients Client and user-on-client identification is insecure or complicated NFS is standard UNIX client-server file sharing protocol CIFS is standard Windows protocol Standard operating system file calls are translated into remote calls Distributed Information Systems (distributed naming services) such as LDAP, DNS, NIS, Active Directory implement unified access to information needed for remote computing
 such as LDAP, DNS, NIS, Active Directory implement unified access to information needed for remote computing")
37
Remote file systems add new failure modes, due to network failure, server failure Recovery from failure can involve state information about status of each remote request Stateless protocols such as NFS include all information in each request, allowing easy recovery but less security

38
Consistency semantics specify how multiple users are to access a shared file simultaneously Similar to Ch 7 process synchronization algorithms Tend to be less complex due to disk I/O and network latency (for remote file systems Andrew File System (AFS) implemented complex remote file sharing semantics Unix file system (UFS) implements: Writes to an open file visible immediately to other users of the same open file Sharing file pointer to allow multiple users to read and write concurrently AFS has session semantics Writes only visible to sessions starting after the file is closed
 implemented complex remote file sharing semantics Unix file system (UFS) implements: Writes to an open file visible immediately to other users of the same open file Sharing file pointer to allow multiple users to read and write concurrently AFS has session semantics Writes only visible to sessions starting after the file is closed")
39
File owner/creator should be able to control: what can be done by whom Types of access Read Write Execute Append Delete List

40
Mode of access: read, write, execute Three classes of users RWX a) owner access 7 1 1 1 RWX b) group access 6 1 1 0 RWX c) public access1 0 0 1 Ask manager to create a group (unique name), say G, and add some users to the group. For a particular file (say game) or subdirectory, define an appropriate access. ownergrouppublic chmod761game Attach a group to a file chgrp G game
 or subdirectory, define an appropriate access. ownergrouppublic chmod761game Attach a group to a file chgrp G game.")
41
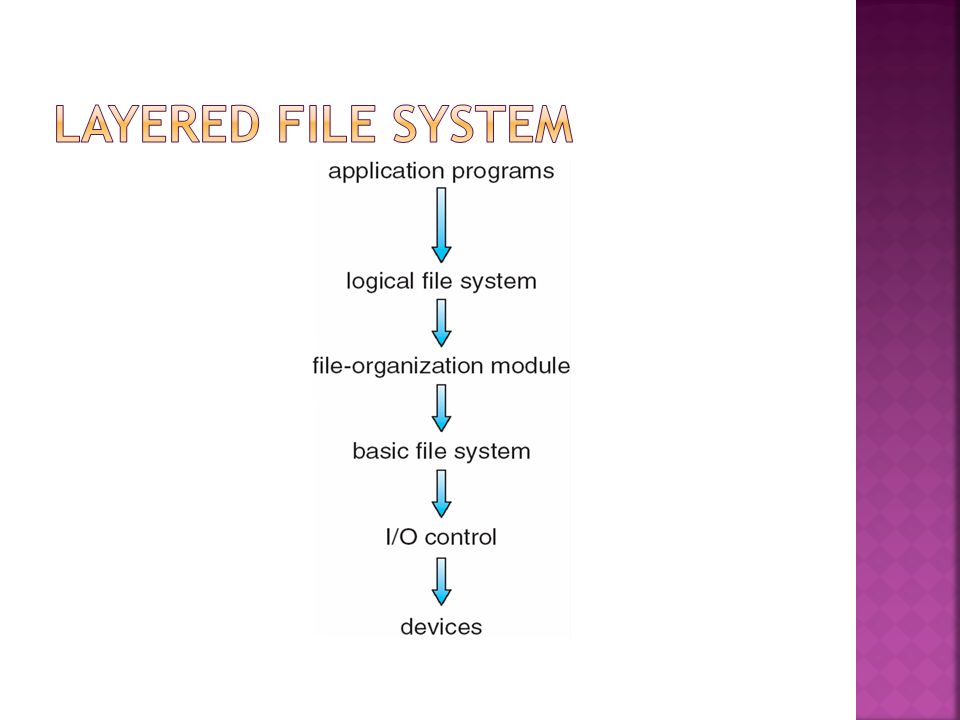
File structure Logical storage unit Collection of related information File system resides on secondary storage (disks) Provided user interface to storage, mapping logical to physical Provides efficient and convenient access to disk by allowing data to be stored, located retrieved easily Disk provides in-place rewrite and random access I/O transfers performed in blocks of sectors (usually 512 bytes) File control block – storage structure consisting of information about a file Device driver controls the physical device File system organized into layers
 Provided user interface to storage, mapping logical to physical Provides efficient and convenient access to disk by allowing data to be stored, located retrieved easily Disk provides in-place rewrite and random access I/O transfers performed in blocks of sectors (usually 512 bytes) File control block – storage structure consisting of information about a file Device driver controls the physical device File system organized into layers")
43
Device drivers manage I/O devices at the I/O control layer Given commands like “read drive1, cylinder 72, track 2, sector 10, into memory location 1060” outputs low- level hardware specific commands to hardware controller n Basic file system given command like “retrieve block 123” translates to device driver n Also manages memory buffers and caches (allocation, freeing, replacement) n Buffers hold data in transit n Caches hold frequently used data n File organization module understands files, logical address, and physical blocks n Translates logical block # to physical block # n Manages free space, disk allocation
 n Buffers hold data in transit n Caches hold frequently used data n File organization module understands files, logical address, and physical blocks n Translates logical block # to physical block # n Manages free space, disk allocation")
44
n Logical file system manages metadata information n Translates file name into file number, file handle, location by maintaining file control blocks (inodes in Unix) n Directory management n Protection n Layering useful for reducing complexity and redundancy, but adds overhead and can decrease performance n Logical layers can be implemented by any coding method according to OS designer n Many file systems, sometimes many within an operating system n Each with its own format (CD-ROM is ISO 9660; Unix has UFS, FFS; Windows has FAT, FAT32, NTFS as well as floppy, CD, DVD Blu-ray, Linux has more than 40 types, with extended file system ext2 and ext3 leading; plus distributed file systems, etc) n New ones still arriving – ZFS, GoogleFS, Oracle ASM, FUSE
 n Directory management n Protection n Layering useful for reducing complexity and redundancy, but adds overhead and can decrease performance n Logical layers can be implemented by any coding method according to OS designer n Many file systems, sometimes many within an operating system n Each with its own format (CD-ROM is ISO 9660; Unix has UFS, FFS; Windows has FAT, FAT32, NTFS as well as floppy, CD, DVD Blu-ray, Linux has more than 40 types, with extended file system ext2 and ext3 leading; plus distributed file systems, etc) n New ones still arriving – ZFS, GoogleFS, Oracle ASM, FUSE")
45
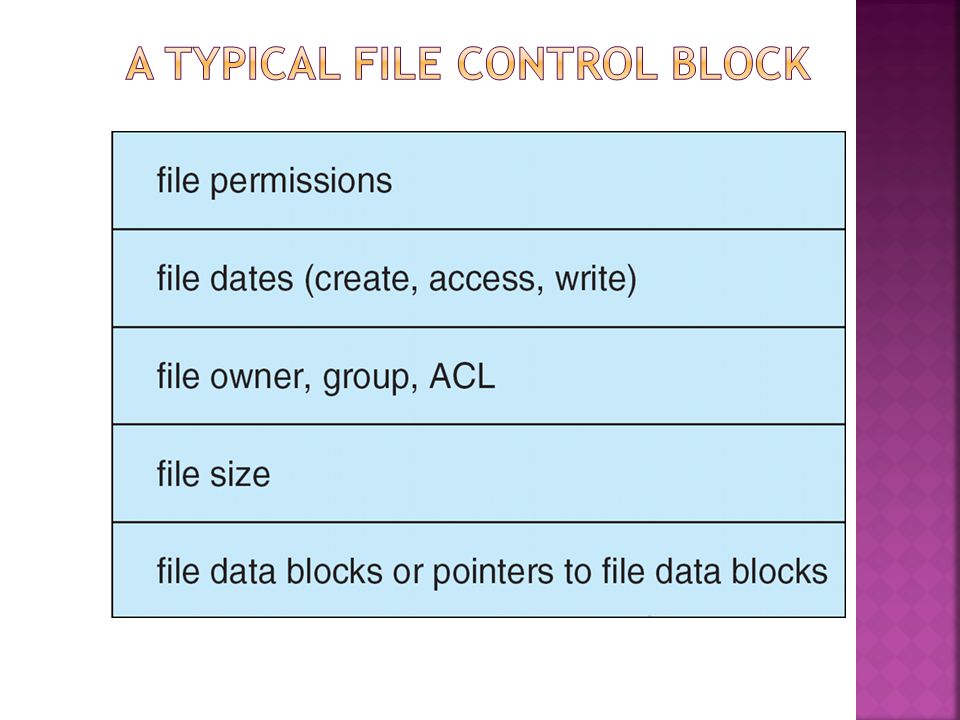
We have system calls at the API level, but how do we implement their functions? On-disk and in-memory structures Boot control block contains info needed by system to boot OS from that volume Needed if volume contains OS, usually first block of volume Volume control block (superblock, master file table) contains volume details Total # of blocks, # of free blocks, block size, free block pointers or array Directory structure organizes the files Names and inode numbers, master file table Per-file File Control Block (FCB) contains many details about the file Inode number, permissions, size, dates NFTS stores into in master file table using relational DB structures
 contains volume details Total # of blocks, # of free blocks, block size, free block pointers or array Directory structure organizes the files Names and inode numbers, master file table Per-file File Control Block (FCB) contains many details about the file Inode number, permissions, size, dates NFTS stores into in master file table using relational DB structures.")
47
Mount table storing file system mounts, mount points, file system types The following figure illustrates the necessary file system structures provided by the operating systems Figure 12-3(a) refers to opening a file Figure 12-3(b) refers to reading a file Plus buffers hold data blocks from secondary storage Open returns a file handle for subsequent use Data from read eventually copied to specified user process memory address
 refers to opening a file Figure 12-3(b) refers to reading a file Plus buffers hold data blocks from secondary storage Open returns a file handle for subsequent use Data from read eventually copied to specified user process memory address")
49
Partition can be a volume containing a file system (“cooked”) or raw – just a sequence of blocks with no file system Boot block can point to boot volume or boot loader set of blocks that contain enough code to know how to load the kernel from the file system Or a boot management program for multi-os booting Root partition contains the OS, other partitions can hold other Oses, other file systems, or be raw Mounted at boot time Other partitions can mount automatically or manually At mount time, file system consistency checked Is all metadata correct? If not, fix it, try again If yes, add to mount table, allow access

50
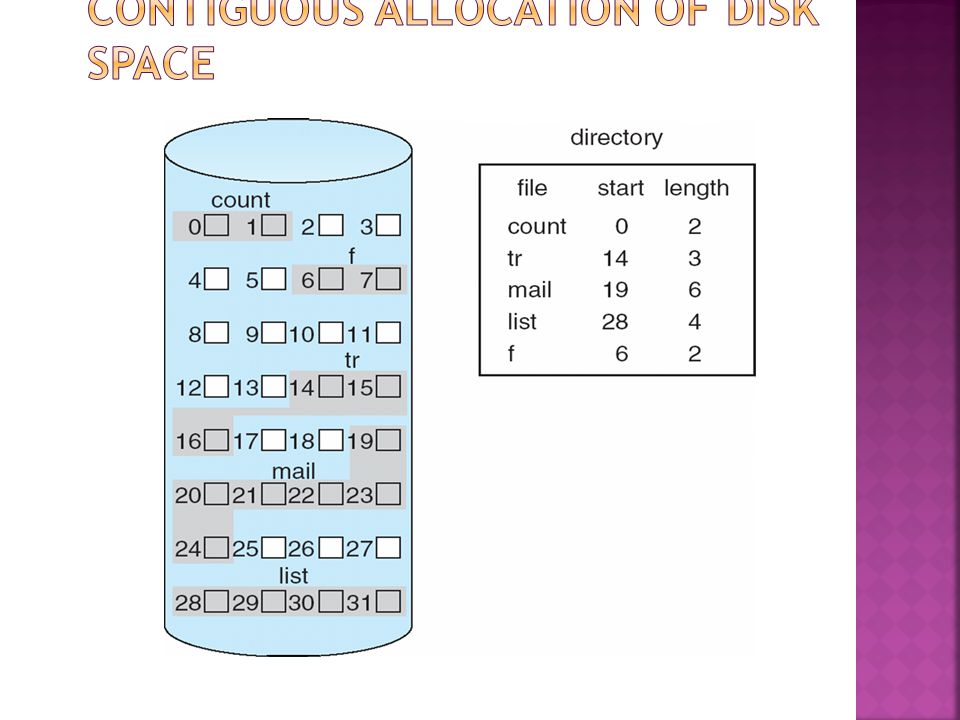
An allocation method refers to how disk blocks are allocated for files: Contiguous allocation – each file occupies set of contiguous blocks Best performance in most cases Simple – only starting location (block #) and length (number of blocks) are required Problems include finding space for file, knowing file size, external fragmentation, need for compaction off-line (downtime) or on-line
 and length (number of blocks) are required Problems include finding space for file, knowing file size, external fragmentation, need for compaction off-line (downtime) or on-line")
51
Mapping from logical to physical LA/512 Q R Block to be accessed = Q + starting address Displacement into block = R

53
Many newer file systems (i.e., Veritas File System) use a modified contiguous allocation scheme Extent-based file systems allocate disk blocks in extents An extent is a contiguous block of disks Extents are allocated for file allocation A file consists of one or more extents
 use a modified contiguous allocation scheme Extent-based file systems allocate disk blocks in extents An extent is a contiguous block of disks Extents are allocated for file allocation A file consists of one or more extents")
54
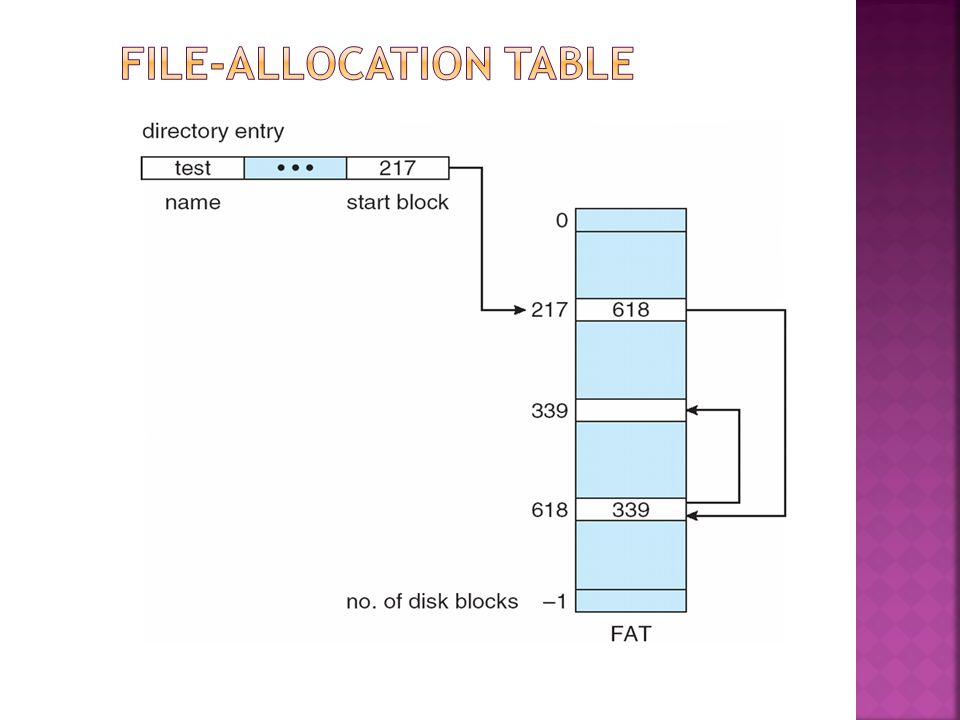
Linked allocation – each file a linked list of blocks File ends at nil pointer No external fragmentation Each block contains pointer to next block No compaction, external fragmentation Free space management system called when new block needed Improve efficiency by clustering blocks into groups but increases internal fragmentation Reliability can be a problem Locating a block can take many I/Os and disk seeks FAT (File Allocation Table) variation Beginning of volume has table, indexed by block number Much like a linked list, but faster on disk and cacheable New block allocation simple
 variation Beginning of volume has table, indexed by block number Much like a linked list, but faster on disk and cacheable New block allocation simple")
55
Each file is a linked list of disk blocks: blocks may be scattered anywhere on the disk pointer block =

56
Mapping Block to be accessed is the Qth block in the linked chain of blocks representing the file. Displacement into block = R + 1 LA/511 Q R

59
Indexed allocation Each file has its own index block(s) of pointers to its data blocks Logical view index table
 of pointers to its data blocks Logical view index table")
61
Need index table Random access Dynamic access without external fragmentation, but have overhead of index block Mapping from logical to physical in a file of maximum size of 256K bytes and block size of 512 bytes. We need only 1 block for index table LA/512 Q R Q = displacement into index table R = displacement into block

62
Mapping from logical to physical in a file of unbounded length (block size of 512 words) Linked scheme – Link blocks of index table (no limit on size) LA / (512 x 511) Q1Q1 R1R1 Q 1 = block of index table R 1 is used as follows: R 1 / 512 Q2Q2 R2R2 Q 2 = displacement into block of index table R 2 displacement into block of file:
 Linked scheme – Link blocks of index table (no limit on size) LA / (512 x 511) Q1Q1 R1R1 Q 1 = block of index table R 1 is used as follows: R 1 / 512 Q2Q2 R2R2 Q 2 = displacement into block of index table R 2 displacement into block of file:")
63
Two-level index (4K blocks could store 1,024 four-byte pointers in outer index -> 1,048,567 data blocks and file size of up to 4GB) LA / (512 x 512) Q1Q1 R1R1 Q 1 = displacement into outer-index R 1 is used as follows: R 1 / 512 Q2Q2 R2R2 Q 2 = displacement into block of index table R 2 displacement into block of file:
 LA / (512 x 512) Q1Q1 R1R1 Q 1 = displacement into outer-index R 1 is used as follows: R 1 / 512 Q2Q2 R2R2 Q 2 = displacement into block of index table R 2 displacement into block of file:")
64
outer-index index table file

65
Note: More index blocks than can be addressed with 32-bit file pointer

66
Best method depends on file access type Contiguous great for sequential and random Linked good for sequential, not random Declare access type at creation -> select either contiguous or linked Indexed more complex Single block access could require 2 index block reads then data block read Clustering can help improve throughput, reduce CPU overhead

67
Adding instructions to the execution path to save one disk I/O is reasonable Intel Core i7 Extreme Edition 990x (2011) at 3.46Ghz = 159,000 MIPS http://en.wikipedia.org/wiki/Instructions_per_second Typical disk drive at 250 I/Os per second 159,000 MIPS / 250 = 630 million instructions during one disk I/O Fast SSD drives provide 60,000 IOPS 159,000 MIPS / 60,000 = 2.65 millions instructions during one disk I/O
 at 3.46Ghz = 159,000 MIPS Typical disk drive at 250 I/Os per second 159,000 MIPS / 250 = 630 million instructions during one disk I/O Fast SSD drives provide 60,000 IOPS 159,000 MIPS / 60,000 = 2.65 millions instructions during one disk I/O")
68
File system maintains free-space list to track available blocks/clusters (Using term “block” for simplicity) Bit vector or bit map (n blocks) … 012n-1 bit[i] = 1 block[i] free 0 block[i] occupied Block number calculation (number of bits per word) * (number of 0-value words) + offset of first 1 bit CPUs have instructions to return offset within word of first “1” bit
![ File system maintains free-space list to track available blocks/clusters (Using term block for simplicity) Bit vector or bit map (n blocks) … 012n-1 bit[i] = 1 block[i] free 0 block[i] occupied Block number calculation (number of bits per word) * (number of 0-value words) + offset of first 1 bit CPUs have instructions to return offset within word of first 1 bit](http://images.slideplayer.com/20/6040478/slides/slide_68.jpg " File system maintains free-space list to track available blocks/clusters (Using term block for simplicity) Bit vector or bit map (n blocks) … 012n-1 bit[i] = 1 block[i] free 0 block[i] occupied Block number calculation (number of bits per word) * (number of 0-value words) + offset of first 1 bit CPUs have instructions to return offset within word of first 1 bit")
69
Bit map requires extra space Example: block size = 4KB = 2 12 bytes disk size = 2 40 bytes (1 terabyte) n = 2 40 /2 12 = 2 28 bits (or 256 MB) if clusters of 4 blocks -> 64MB of memory Easy to get contiguous files Linked list (free list) Cannot get contiguous space easily No waste of space No need to traverse the entire list (if # free blocks recorded)
 n = 2 40 /2 12 = 2 28 bits (or 256 MB) if clusters of 4 blocks -> 64MB of memory Easy to get contiguous files Linked list (free list) Cannot get contiguous space easily No waste of space No need to traverse the entire list (if # free blocks recorded)")
71
Grouping Modify linked list to store address of next n-1 free blocks in first free block, plus a pointer to next block that contains free-block-pointers (like this one) Counting Because space is frequently contiguously used and freed, with contiguous-allocation allocation, extents, or clustering Keep address of first free block and count of following free blocks Free space list then has entries containing addresses and counts
 Counting Because space is frequently contiguously used and freed, with contiguous-allocation allocation, extents, or clustering Keep address of first free block and count of following free blocks Free space list then has entries containing addresses and counts")
72
Space Maps Used in ZFS Consider meta-data I/O on very large file systems Full data structures like bit maps couldn’t fit in memory - > thousands of I/Os Divides device space into metaslab units and manages metaslabs Given volume can contain hundreds of metaslabs Each metaslab has associated space map Uses counting algorithm But records to log file rather than file system Log of all block activity, in time order, in counting format Metaslab activity -> load space map into memory in balanced-tree structure, indexed by offset Replay log into that structure Combine contiguous free blocks into single entry

73
Efficiency dependent on: Disk allocation and directory algorithms Types of data kept in file’s directory entry Pre-allocation or as-needed allocation of metadata structures Fixed-size or varying-size data structures

74
Performance Keeping data and metadata close together Buffer cache – separate section of main memory for frequently used blocks Synchronous writes sometimes requested by apps or needed by OS No buffering / caching – writes must hit disk before acknowledgement Asynchronous writes more common, buffer-able, faster Free-behind and read-ahead – techniques to optimize sequential access Reads frequently slower than writes

75
A page cache caches pages rather than disk blocks using virtual memory techniques and addresses Memory-mapped I/O uses a page cache Routine I/O through the file system uses the buffer (disk) cache This leads to the following figure
 cache This leads to the following figure")
77
A unified buffer cache uses the same page cache to cache both memory-mapped pages and ordinary file system I/O to avoid double caching n But which caches get priority, and what replacement algorithms to use?

79
Consistency checking – compares data in directory structure with data blocks on disk, and tries to fix inconsistencies Can be slow and sometimes fails Use system programs to back up data from disk to another storage device (magnetic tape, other magnetic disk, optical) Recover lost file or disk by restoring data from backup
 Recover lost file or disk by restoring data from backup")
80
Log structured (or journaling) file systems record each metadata update to the file system as a transaction All transactions are written to a log A transaction is considered committed once it is written to the log (sequentially) Sometimes to a separate device or section of disk However, the file system may not yet be updated The transactions in the log are asynchronously written to the file system structures When the file system structures are modified, the transaction is removed from the log If the file system crashes, all remaining transactions in the log must still be performed Faster recovery from crash, removes chance of inconsistency of metadata
 file systems record each metadata update to the file system as a transaction All transactions are written to a log A transaction is considered committed once it is written to the log (sequentially) Sometimes to a separate device or section of disk However, the file system may not yet be updated The transactions in the log are asynchronously written to the file system structures When the file system structures are modified, the transaction is removed from the log If the file system crashes, all remaining transactions in the log must still be performed Faster recovery from crash, removes chance of inconsistency of metadata")
81
Need to protect: Pointer to free list Bit map Must be kept on disk Copy in memory and disk may differ Cannot allow for block[i] to have a situation where bit[i] = 1 in memory and bit[i] = 0 on disk Solution: Set bit[i] = 1 in disk Allocate block[i] Set bit[i] = 1 in memory
![ Need to protect: Pointer to free list Bit map Must be kept on disk Copy in memory and disk may differ Cannot allow for block[i] to have a situation where bit[i] = 1 in memory and bit[i] = 0 on disk Solution: Set bit[i] = 1 in disk Allocate block[i] Set bit[i] = 1 in memory](http://images.slideplayer.com/20/6040478/slides/slide_81.jpg " Need to protect: Pointer to free list Bit map Must be kept on disk Copy in memory and disk may differ Cannot allow for block[i] to have a situation where bit[i] = 1 in memory and bit[i] = 0 on disk Solution: Set bit[i] = 1 in disk Allocate block[i] Set bit[i] = 1 in memory")
Similar presentations




















. 2 File-System Interface File Concept Access Methods Directory Structure File System Mounting File Sharing Protection.>")










