Download presentation
Presentation is loading. Please wait.

1
Protocol-Dependent Message-Passing Performance on Linux Clusters Dave Turner – Xuehua Chen – Adam Oline This work is funded by the DOE MICS office. http://www.scl.ameslab.gov/

2
Inefficiencies in the communication system Applications MPI native layer internal buses driver & NIC switch fabric Poor MPI usage No mapping 50% bandwidth 2-3x latency OS bypass TCP tuning PCI Memory Hardware limits Driver tuning Topological bottlenecks

4
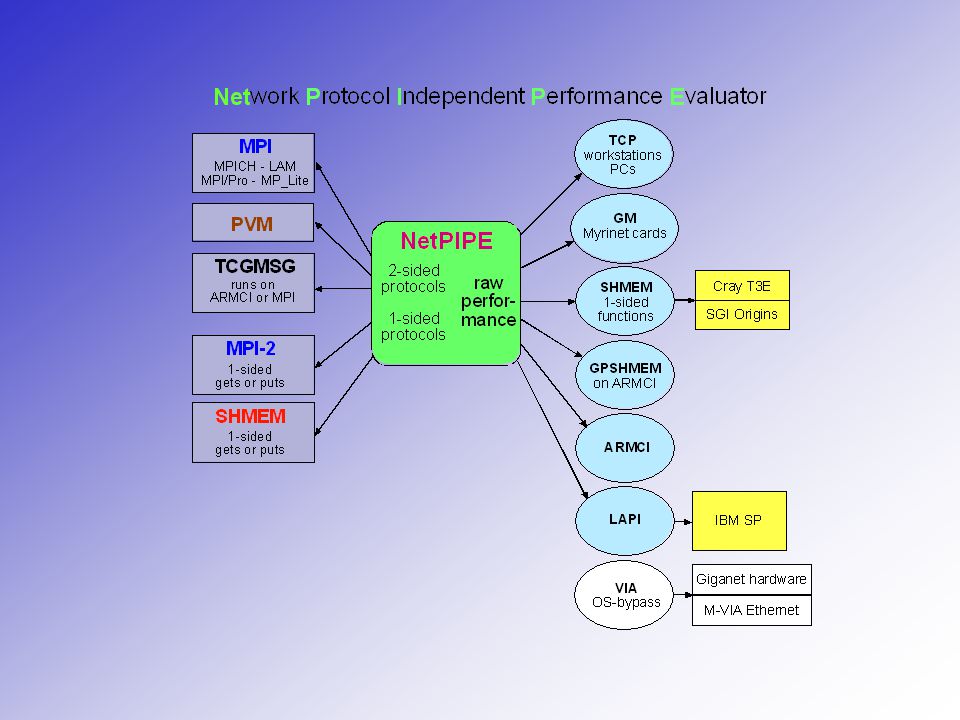
The NetPIPE utility NetPIPE does a series of ping-pong tests between two nodes. Message sizes are chosen at regular intervals, and with slight perturbations, to fully test the communication system for idiosyncrasies. Latencies reported represent half the ping-pong time for messages smaller than 64 Bytes. Measuring the overhead of message-passing protocols. Help in tuning the optimization parameters of message-passing libraries. Identify dropouts in networking hardware. Optimizing driver and OS parameters (socket buffer sizes, etc.). Some typical uses What is not measured NetPIPE can measure the load on the CPU using getrusage, but this was not done here. The effects from the different methods for maintaining message progress. Scalability with system size.
. Some typical uses What is not measured NetPIPE can measure the load on the CPU using getrusage, but this was not done here. The effects from the different methods for maintaining message progress. Scalability with system size..")
5
A NetPIPE example: Performance on a Cray T3E Raw SHMEM delivers: 2600 Mbps 2-3 us latency Cray MPI originally delivered: 1300 Mbps 20 us latency MP_Lite delivers: 2600 Mbps 9-10 us latency New Cray MPI delivers: 2400 Mbps 20 us latency The top of the spikes are where the message size is divisible by 8 Bytes.

6
The network hardware and computer test-beds Linux PC test-bed Two 1.8 GHz P4 computers 768 MB PC133 memory 32-bit 33 MHz PCI bus RedHat 7.2 Linux 2.4.7-10 Alpha Linux test-bed Two 500 MHz dual-processor Compaq DS20s 1.5 GB memory 32/64-bit 33 MHz PCI bus RedHat 7.1 Linux 2.4.17 PC SMP test-bed 1.7 GHz dual-processor Xeon 1.0 GB memory RedHat 7.3 Linux 2.4.18-3smp All measurements were done back-to-back except for the Giganet hardware, which went through an 8-port switch.

7
MPICH MPICH 1.2.3 release Uses the p4 device for TCP. P4_SOCKBUFSIZE must be increased to ~256 kBytes. Rendezvous threshold can be changed in the source code. MPICH-2.0 will be out soon! Developed by Argonne National Laboratory and Mississippi State University.

8
LAM/MPI LAM 6.5.6-4 release from the RedHat 7.2 distibution. Must lamboot the daemons. -lamd directs messages through the daemons. -O avoids data conversion for homogeneous systems. No socket buffer size tuning. No threshold adjustments. Currently developed at Indiana University. http://www.lam-mpi.org/

9
MPI/Pro MPI/Pro 1.6.3-1 release Easy to install RPM Requires rsh, not ssh -tcp_long 128 kBytes gets rid of most of the dip at the rendezvous threshold. Other parameters didn’t help. Thanks to MPI Software Technology for supplying the MPI/Pro software for testing. http://www.mpi-softtech.com/

10
The MP_Lite message-passing library A light-weight MPI implementation Highly efficient for the architectures supported Designed to be very user-friendly Ideal for performing message-passing research http://www.scl.ameslab.gov/Projects/MP_Lite/

11
PVM PVM 3.4.3 release from the RedHat 7.2 distribution. Uses XDR encoding and the pvmd daemons by default. pvm_setopt(PvmRoute, PvmRouteDirect) bypasses the pvmd daemons. pvm_initsend(PvmDataInPlace) avoids XDR encoding for homogeneous systems. Developed at Oak Ridge National Laboratory. http://www.csm.ornl.gov/pvm/
 bypasses the pvmd daemons. pvm_initsend(PvmDataInPlace) avoids XDR encoding for homogeneous systems. Developed at Oak Ridge National Laboratory.")
12
Performance on Netgear GA620 Fiber Gigabit Ethernet cards between two PCs All libraries do reasonably well on this mature card and driver. MPICH and PVM suffer from an extra memory copy. LAM/MPI, MPI/Pro, and MPICH have dips at the rendezvous threshold due to the large 180 us latency. Tunable thresholds would easily eliminate this minor drop in performance. Netgear GA620 fiber GigE 32/64-bit 33/66 MHz AceNIC driver

13
Performance on TrendNet and Netgear GA622T Gigabit Ethernet cards between two Linux PCs Both cards are very sensitive to the socket buffer sizes. MPICH and MP_Lite do well because they adjust the socket buffer sizes. Increasing the default socket buffer size in the other libraries, or making it an adjustable parameter, would fix this problem. More tuning of the ns83820 driver would also fix this problem. TrendNet TEG-PCITX copper GigE 32-bit 33/66 MHz ns83820 driver

14
Performance on SysKonnect Gigabit Ethernet cards between Compaq DS20s running Linux The SysKonnect cards using a 9000 Byte MTU provides a more challenging environment. MP_Lite delivers nearly all the 900 Mbps performance. LAM/MPI again suffers due to the smaller socket buffer sizes. MPICH suffers from the extra memory copy. PVM suffers from both. SysKonnect SK-9843-SX fiber GigE 32/64-bit 33/66 MHz sk98lin driver

15
Performance on Myrinet cards between two Linux PCs MPICH-GM and MPI/Pro- GM both pass almost all the performance of GM through to the application. SCore claims to provide better performance, but is not quite ready for prime time yet. IP-GM IP-GM provides little benefit over TCP on Gigabit Ethernet, and at a much greater cost. Myrinet PCI64A-2 SAN card 66 MHz RISC with 2 MB memory

16
Performance on VIA Giganet hardware and on SysKonnect GigE cards using M-VIA between two Linux PCs MPI/Pro, MVICH, and MP_Lite all provide 800 Mbps bandwidth on the Giganet hardware, but MPI/Pro has a longer latency of 42 us compared with 10 us for the others. The M-VIA 1.2b2 performance is roughly at the same level that raw TCP provides. The M-VIA 1.2b3 release has not been tested, nor has using jumbo frames. Giganet CL1000 cards through an 8-port CL5000 switch http://www.nersc.gov/research/ftg/{via,mvich}/

17
SMP message-passing performance on a dual-processor Compaq DS20 running Alpha Linux With the data starting in main memory.

18
SMP message-passing performance on a dual-processor Compaq DS20 running Alpha Linux With the data starting in cache.

19
SMP message-passing performance on a dual-processor Xeon running Linux With the data starting in main memory.

20
SMP message-passing performance on a dual-processor Xeon running Linux With the data starting in cache.

21
One-sided Puts between two Linux PCs MP_Lite is SIGIO based, so MPI_Put() and MPI_Get() finish without a fence. LAM/MPI has no message progress, so a fence is required. ARMCI uses a polling method, and therefore does not require a fence. An MPI-2 implementation of MPICH is under development. An MPI-2 implementation of MPI/Pro is under development. Netgear GA620 fiber GigE 32/64-bit 33/66 MHz AceNIC driver

22
Conclusions Most message-passing libraries do reasonably well if properly tuned. All need to have the socket buffer sizes and thresholds user-tunable. Optimizing the network drivers would also correct some of the problems. There is still much room for improvement for SMP and 1-sided communications. Future Work All network cards should be tested on a 64-bit 66 MHz PCI bus to put more strain on the message-passing libraries. Testing within real applications is vital to verify NetPIPE results, test scalability of the implementation methods, investigate loading of the CPU, and study the effects of the various approaches to maintaining message progress. Score should be compared to GM. VIA and Infinaband modules are needed for NetPIPE.

23
Protocol-Dependent Message-Passing Performance on Linux Clusters Dave Turner – Xuehua Chen – Adam Oline turner@ameslab.gov http://www.scl.ameslab.gov/

Similar presentations









>")









