Download presentation
Presentation is loading. Please wait.

1
ADITI BHAUMICK ab3585

2
To use reinforcement learning algorithm with function approximation. Feature-based state representations using a broad characterization of the level of congestion as low, medium or high are implemented. Reinforcement Learning is used as it allows the optimal strategy for signal timing to be learnt without assuming any models of the system.

3
On high-dimensional state action spaces, function approximation techniques are used to achieve computational efficiency. A form of Reinforcement learning called Q Learning is used to develop a Traffic Light Control algorithm that incorporates function approximation.

4
The Q TLC-FA is implemented. A number of other algorithms were also implemented in order to compare the Q Learning with function approximation algorithm. The algorithms are implemented on an open source Java based software called the Green Light District. The single stage cost function is k(s,a) and r1= s1= 0.5 is set.
 and r1= s1= 0.5 is set..")
7
The basis for the new form of algorithm developed is the Markov Decision Process framework. A stochastic process {Xn} that takes values in a set S is called a MDP if its evolution is governed by a control valued sequence { Zn}. The Q-Bellman Equation or the Bellman Equation of optimality is defined as:

8
The Q Learning based TLC with Function Approximation updates a parameter θ which is a d- dimensional quantity. Here instead of solving a system in [ SXA(S)], a system in only d variables is solved.
], a system in only d variables is solved..")
9
The metrics used for this algorithm are: The number of lanes, N The thresholds on queue lengths L1 and L2 The threshold on elapsed time T1 None of these metrics are dependent on the full state representation of the entire network.

10
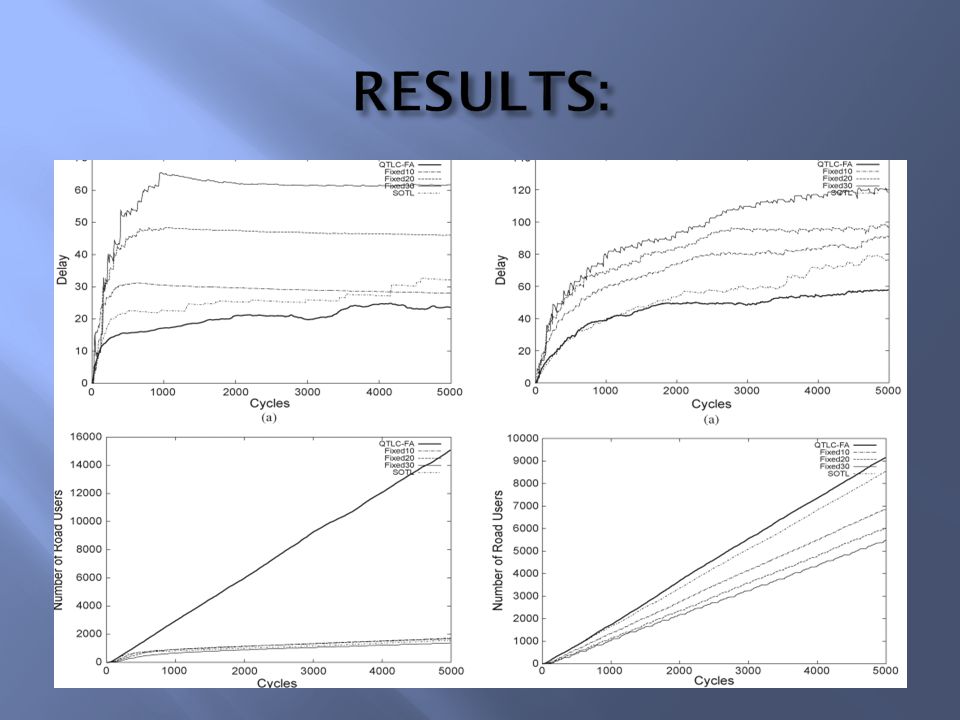
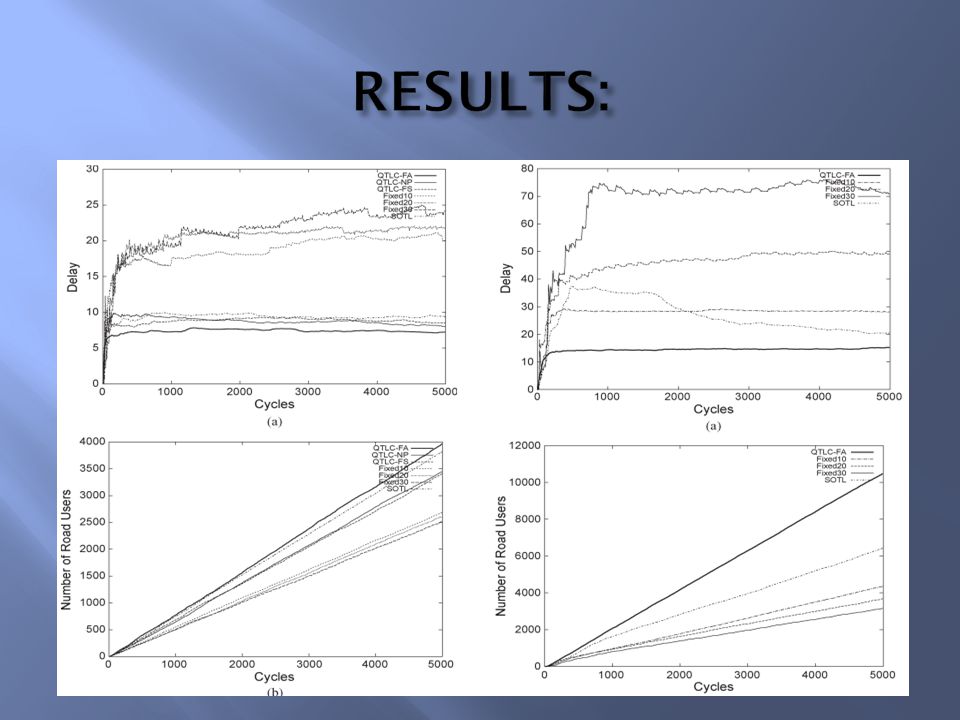
The QTLC-FA Algorithm outperforms all the other algorithms it is compared with. Future work would involve the application of other efficient RL algorithms with function approximation. Effects of driver behavior could also be incorporated into the framework.

Similar presentations




>")
, Motoaki KAWANABE (2), Takeshi MORI (1), Shin-ich MAEDA (1), Shin.>")





>")
 Li, Hailin.>")


, M, is a model of a stochastic, dynamic, controllable, rewarding process given by: M = 〈 S, A,T,R.>")



