Download presentation
Presentation is loading. Please wait.

1
Lecture 9: p-value functions and intro to Bayesian thinking Matthew Fox Advanced Epidemiology

2
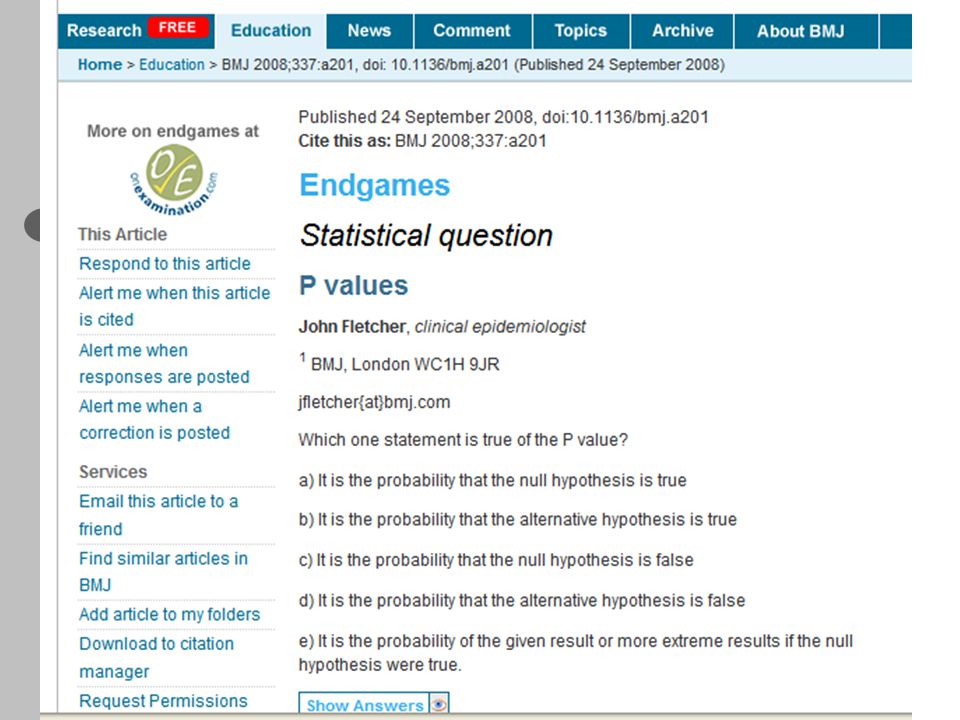
If you are a hypothesis tester, which pvalue is more likely to avoid a type I error P = 0.049 P = 0.005

3
What is the p-value fallacy?

4
If you go to the doctor with a set of symptoms, does the doctor develop a hypothesis and test it?

5
Anyone heard of Bayesian statistics?

6
After completing a study, would you rather know the probability of the data given the null hypothesis, or the probability of the null hypothesis given the data?

7
Last Session Randomization – Leads to average confounding, gives meaning to p-values – Provides a known distribution for all possible observed results – Observational data does not have average 0 confounding P-values – Probability under the null that a test statistic would be greater than or equal to its observed value, assuming no bias. – Not the probability of the data, the null, a significance level Confidence intervals – Calculated assuming infinite repetitions of the data – Don’t give a probability of containing the true value

9
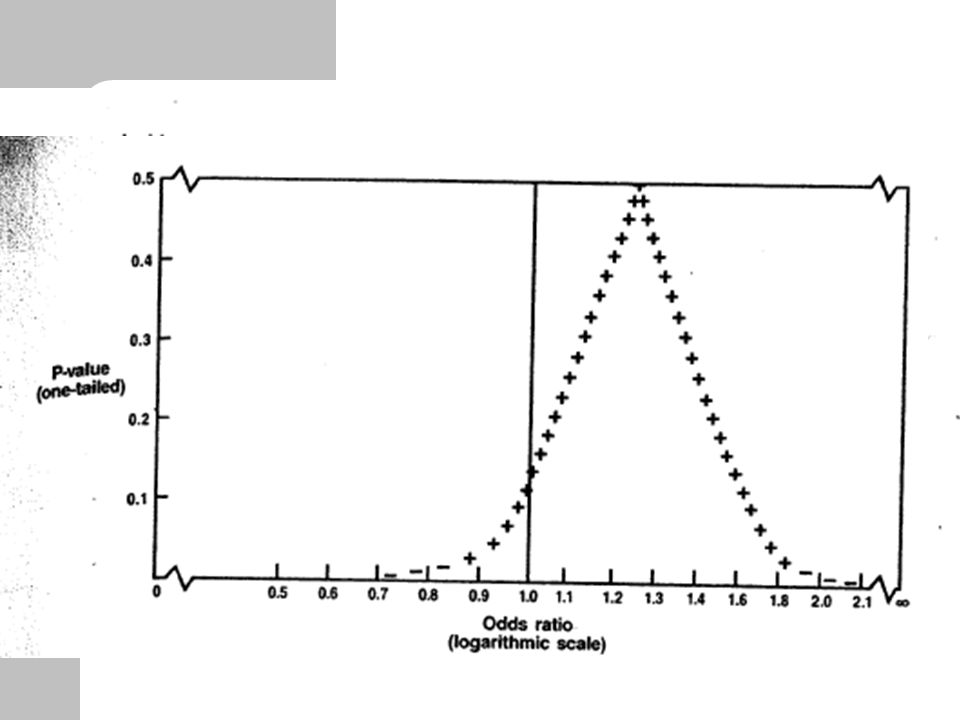
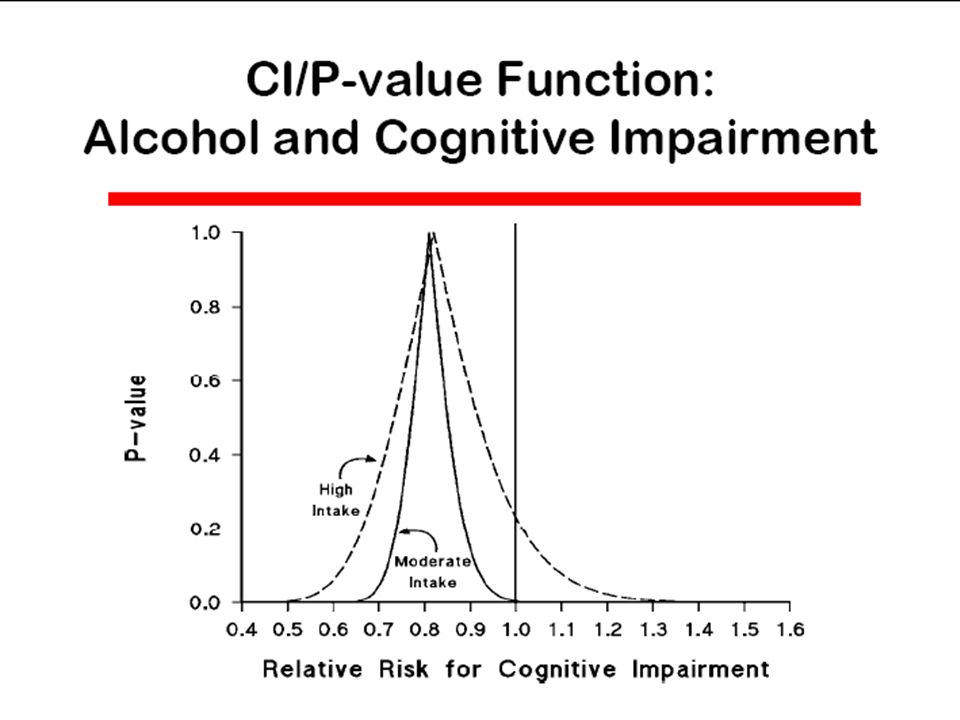
Today The p-value fallacy p-value functions – Shows p-values for the data at a range of hypotheses Bayesian statistics – The difference between Frequentists and Bayesians – Bayesian Theory – How to apply Bayes Theory in Practice

10
P-value fallacy P-value developed by Fisher as informal measure of compatibility of data with null – Provides no guidance on significance – Should be interpreted in light of what we know Hypothesis testing developed by Neyman, Pearson to minimize errors in the long run – P = 0.04 is no more evidence than p = 0.00001 Fallacy is that p-value can do both Jerzy Neyman Egon Pearson (not Karl, his father) RA Fisher
 RA Fisher")
11
Different goals The goal of epidemiology: – To measure precisely and accurately the effect of an exposure on a disease The goal of policy: – To make decisions Given our goal: – Why hypothesis testing? – Why compare to the null?

13
p-value functions (1) Recall that a p-value is: – “The probability under the test hypothesis (usually the null) that a test statistic would be ≥ to its observed value, assuming no bias.” We can calculate p-values under test hypotheses other than the null – Particularly easy if we use a normal approximation – If we assume we can fix the margins with observational data
 Recall that a p-value is: – The probability under the test hypothesis (usually the null) that a test statistic would be ≥ to its observed value, assuming no bias. We can calculate p-values under test hypotheses other than the null – Particularly easy if we use a normal approximation – If we assume we can fix the margins with observational data")
14
p-value functions (1)
")
15
p-value functions (2a) To calculate a test statistics (Z score) for a p-value, usually given:
 To calculate a test statistics (Z score) for a p-value, usually given:")
16
p-value functions (2b) Ln(1) = 0
 Ln(1) = 0")
17
p-value functions (3)
")
18
p-value functions (4) 2 Null pval 0.27 6.9 0.58 Point estimate LCLM UCLM
 2 Null pval Point estimate LCLM UCLM")
19
p-value functions (4)
")
21
Case-control study of spermicides and Down Syndrome

22
Interpretation

27
Introduction to Bayesian Thinking

28
What is the best estimate of the true effect of E on D? Given a disease D and An exposure E+ vs. unexposed E-: – The relative risk associating D w/ E+ (vs E-) = 2.0 – with 95% confidence interval 1.5 to 2.7 OK, but why did you say what you said? – Have no other info to go on
 = 2.0 – with 95% confidence interval 1.5 to 2.7 OK, but why did you say what you said. – Have no other info to go on.")
29
What is the best estimate of the true effect of E on D? Given a disease D and An exposure E+ vs. unexposed E-: – The relative risk associating D w/ E+ (vs E-) = 2.0 – with 95% confidence interval 0.5 to 8.0 Note that the width of the interval doesn’t affect the best estimate in this case
 = 2.0 – with 95% confidence interval 0.5 to 8.0 Note that the width of the interval doesn’t affect the best estimate in this case.")
30
What is the best estimate of the true effect of E on D? Given a disease D (breast cancer) and An exposure E+ (ever-smoking) vs. unexposed E- (never-smoking): – The relative risk associating D w/ E+ (vs E-) = 2.0 – with 95% confidence interval 1.0 to 4.0 Most previous studies of smoking and BC have shown no association
 and An exposure E+ (ever-smoking) vs. unexposed E- (never-smoking): – The relative risk associating D w/ E+ (vs E-) = 2.0 – with 95% confidence interval 1.0 to 4.0 Most previous studies of smoking and BC have shown no association.")
31
What is the best estimate of the true effect of E on D? Given a disease D (lung cancer) and An exposure E+ (ever-smoking) vs. unexposed E- (never-smoking): – The relative risk associating D w/ E+ (vs E-) = 2.0 – with 95% confidence interval 1.0 to 4.0 Most previous studies of smoking and LC have shown much larger effects
 and An exposure E+ (ever-smoking) vs. unexposed E- (never-smoking): – The relative risk associating D w/ E+ (vs E-) = 2.0 – with 95% confidence interval 1.0 to 4.0 Most previous studies of smoking and LC have shown much larger effects.")
32
What is the best estimate of the true probability of heads? Given a 100 flips of a fair coin flipped in a fair way Observed number of heads = 40 – The probability of heads equals 0.40 – with 95% confidence interval 0.304 to 0.496 Given what we know about a fair coin, why should this data override what we know? So why would we interpret our study data as if it existed in a vacuum?

33
The Monty Hall Problem

34
An alternative to frequentist statistics Something important about the data is not being captured by the p-value and confidence interval, or at least in the way they’re used What is missing is a measure of the evidence provided by the data Evidence is a property of data that makes us alter our beliefs

35
Frequentist statistics fail as measures of evidence The logical underpinning of frequentist statistics is that – “if an observation is rare under a hypothesis, then the observation can be used as evidence against the hypothesis.” Life is full of rare events we accord little attention – What makes us react is a plausible competing hypothesis under which the data are more probable

36
Frequentist statistics fail as measures of evidence Null p-value provides no information about the probability of alternatives to the null Measurement of evidence requires 3 things: The observations (data) 2 competing hypotheses (often null and alternative) The p-value incorporates data & 1 hypothesis usually the null
 2 competing hypotheses (often null and alternative) The p-value incorporates data & 1 hypothesis usually the null")
37
The likelihood as a measure of evidence Likelihood = c*Probability(data H) Data are fixed and hypotheses variable – p-values calculated with fixed (null) hypothesis and assuming data are randomly variable. Evidence supporting one hypothesis versus another = ratio of their likelihoods – Log of the ratio is an additive measure of support

38
Evidence versus belief The hypothesis with the higher likelihood is better supported by the evidence – But that does not make it more likely to be true. Belief also depends on prior knowledge, and can be incorporated w/ Bayes Theorem – It is the likelihood ratio that represents the data Priors can be subjective or empirical – But not arbitrary

39
Bayesian analysis (1) Given (1) the prior odds that a hypothesis is true, and (2) data to measure the effect – Update the prior odds using the data to calculate the posterior odds that the hypothesis is true. – A formal algorithm to accomplish what many do informally

40
Bayesian analysis (2) Prior odds times the likelihood ratio equals the posterior odds Only for people with an ignorant prior distribution (uniform) can we say that the frequentist 95% CI covers the true value with 95% certainty
 Prior odds times the likelihood ratio equals the posterior odds Only for people with an ignorant prior distribution (uniform) can we say that the frequentist 95% CI covers the true value with 95% certainty")
41
Bayesian analysis (3): Environmental tobacco smoke and breast cancer H1 = [OR = 2]; H0 = [OR = 1] Initially, the analyst has no preference (prior odds = 1)
![Bayesian analysis (3): Environmental tobacco smoke and breast cancer H1 = [OR = 2]; H0 = [OR = 1] Initially, the analyst has no preference (prior odds = 1)](http://images.slideplayer.com/19/5910587/slides/slide_41.jpg "Bayesian analysis (3): Environmental tobacco smoke and breast cancer H1 = [OR = 2]; H0 = [OR = 1] Initially, the analyst has no preference (prior odds = 1)")
42
Bayesian analysis (4): concepts Keep these concepts separate: – The hypotheses under comparison (e.g., RR=2 vs RR=1) – The prior odds (>1 favors 1 st hypothesis (RR=2), <1 favors the 2 nd hypothesis (RR=1)) – The estimate of effect for a study (this is the data used to modify the prior odds)
: concepts Keep these concepts separate: – The hypotheses under comparison (e.g., RR=2 vs RR=1) – The prior odds (>1 favors 1 st hypothesis (RR=2), <1 favors the 2 nd hypothesis (RR=1)) – The estimate of effect for a study (this is the data used to modify the prior odds)")
43
Bayesian analysis (5): concepts Keep these concepts separate: – The likelihood ratio (probability of data under 1 st hypothesis versus under 2 nd hypothesis. >1 favors 1 st hypothesis, <1 favors the 2 nd hypothesis) – The posterior odds (compares the hypotheses after observing the data. >1 favors 1 st hypothesis, <1 favors the 2 nd hypothesis)
 – The posterior odds (compares the hypotheses after observing the data. >1 favors 1 st hypothesis, <1 favors the 2 nd hypothesis).")
44
Bayesian analysis: H 1 = RR = 2.0 H 0 = RR = 1.0

45
http://statpages.org/bayes.html

46
Connection between p-values and the likelihood ratio

47
Bayesian intervals Bayesian intervals require specification of prior odds for entire distribution of hypotheses, not just two hypotheses – Distribution will look like a p-value function, but incorporate only prior knowledge. Update the distribution with data – Posterior distribution Choose interval limits

48
Priors

49
+ Sandler

50
+ Hirayama

51
+ Smith

52
+ Morabia

53
+ Johnson

54
Conclusion Pvalue fallacy – Cannot serve both the long run perspective and the individual study perspective Pvalue functions – Can help see the entire distribution of probabilities Bayesian analysis – Allows us to change our beliefs with new information and measure the probability of hypothesis

Similar presentations





 is sufficient for >")

>")















