Download presentation
Presentation is loading. Please wait.

1
Web Information Extraction 3 rd Oct 2007

2
Information Extraction (Slides based on those by Ray Mooney, Craig Knoblock, Dan Weld, Perry, Subbarao Kambhampati, Bing Liu)
")
3
Introduction The Web is perhaps the single largest data source in the world. Much of the Web (content) mining is about Data/information extraction from semi-structured objects and free text, and Integration of the extracted data/information Due to the heterogeneity and lack of structure, mining and integration are challenging tasks. This talk gives an overview.
 mining is about Data/information extraction from semi-structured objects and free text, and Integration of the extracted data/information Due to the heterogeneity and lack of structure, mining and integration are challenging tasks. This talk gives an overview..")
4
Introduction Web mining aims to develop new techniques to extract useful knowledge from the Web Web offers unprecedented opportunity and challenges to NLP Huge amount of information accessible Wide and diverse coverage Information of all types – structured table, text, multimedia data … Semi-structured (html) Linked Redundant
 Linked Redundant")
5
Noisy. main content, advertisement, navigation panel, copyright notices, … Surface Web and Deep Web Surface web: pages that can be browsed using q web browser Deep web: databases accessible through parameterized query interfaces Services. Dynamic Virtual Society. Interactions among people, organizations, and systems.

6
Information Extraction (IE) Identify specific pieces of information (data) in a unstructured or semi-structured textual document. Transform unstructured information in a corpus of documents or web pages into a structured database. Applied to different types of text: Newspaper articles Web pages Scientific articles Newsgroup messages Classified ads Medical notes

7
Information Extraction vs. NLP? Information extraction is attempting to find some of the structure and meaning in the hopefully template driven web pages. As IE becomes more ambitious and text becomes more free form, then ultimately we have IE becoming equal to NLP. Web does give one particular boost to NLP Massive corpora..

8
Subject: US-TN-SOFTWARE PROGRAMMER Date: 17 Nov 1996 17:37:29 GMT Organization: Reference.Com Posting Service Message-ID: SOFTWARE PROGRAMMER Position available for Software Programmer experienced in generating software for PC- Based Voice Mail systems. Experienced in C Programming. Must be familiar with communicating with and controlling voice cards; preferable Dialogic, however, experience with others such as Rhetorix and Natural Microsystems is okay. Prefer 5 years or more experience with PC Based Voice Mail, but will consider as little as 2 years. Need to find a Senior level person who can come on board and pick up code with very little training. Present Operating System is DOS. May go to OS-2 or UNIX in future. Please reply to: Kim Anderson AdNET (901) 458-2888 fax kimander@memphisonline.com Subject: US-TN-SOFTWARE PROGRAMMER Date: 17 Nov 1996 17:37:29 GMT Organization: Reference.Com Posting Service Message-ID: SOFTWARE PROGRAMMER Position available for Software Programmer experienced in generating software for PC- Based Voice Mail systems. Experienced in C Programming. Must be familiar with communicating with and controlling voice cards; preferable Dialogic, however, experience with others such as Rhetorix and Natural Microsystems is okay. Prefer 5 years or more experience with PC Based Voice Mail, but will consider as little as 2 years. Need to find a Senior level person who can come on board and pick up code with very little training. Present Operating System is DOS. May go to OS-2 or UNIX in future. Please reply to: Kim Anderson AdNET (901) 458-2888 fax kimander@memphisonline.com Sample Job Posting
 fax Subject: US-TN-SOFTWARE PROGRAMMER Date: 17 Nov :37:29 GMT Organization: Reference.Com Posting Service Message-ID: SOFTWARE PROGRAMMER Position available for Software Programmer experienced in generating software for PC- Based Voice Mail systems. Experienced in C Programming. Must be familiar with communicating with and controlling voice cards; preferable Dialogic, however, experience with others such as Rhetorix and Natural Microsystems is okay. Prefer 5 years or more experience with PC Based Voice Mail, but will consider as little as 2 years. Need to find a Senior level person who can come on board and pick up code with very little training. Present Operating System is DOS. May go to OS-2 or UNIX in future. Please reply to: Kim Anderson AdNET (901) fax Sample Job Posting.")
9
Extracted Job Template computer_science_job id: 56nigp$mrs@bilbo.reference.com title: SOFTWARE PROGRAMMER salary: company: recruiter: state: TN city: country: US language: C platform: PC \ DOS \ OS-2 \ UNIX application: area: Voice Mail req_years_experience: 2 desired_years_experience: 5 req_degree: desired_degree: post_date: 17 Nov 1996

10
Amazon Book Description …. The Age of Spiritual Machines : When Computers Exceed Human Intelligence by <a href="/exec/obidos/search-handle-url/index=books&field-author= Kurzweil%2C%20Ray/002-6235079-4593641"> Ray Kurzweil <img src="http://images.amazon.com/images/P/0140282025.01.MZZZZZZZ.gif" width=90 height=140 align=left border=0> List Price: $14.95 Our Price: $11.96 You Save: $2.99 (20%) …. The Age of Spiritual Machines : When Computers Exceed Human Intelligence by <a href="/exec/obidos/search-handle-url/index=books&field-author= Kurzweil%2C%20Ray/002-6235079-4593641"> Ray Kurzweil <img src="http://images.amazon.com/images/P/0140282025.01.MZZZZZZZ.gif" width=90 height=140 align=left border=0> List Price: $14.95 Our Price: $11.96 You Save: $2.99 (20%) …
 …. The Age of Spiritual Machines : When Computers Exceed Human Intelligence by <a href= /exec/obidos/search-handle-url/index=books&field-author= Kurzweil%2C%20Ray/ > Ray Kurzweil <img src= width=90 height=140 align=left border=0> List Price: $14.95 Our Price: $11.96 You Save: $2.99 (20%) ….")
11
Extracted Book Template Title: The Age of Spiritual Machines : When Computers Exceed Human Intelligence Author: Ray Kurzweil List-Price: $14.95 Price: $11.96 :

12
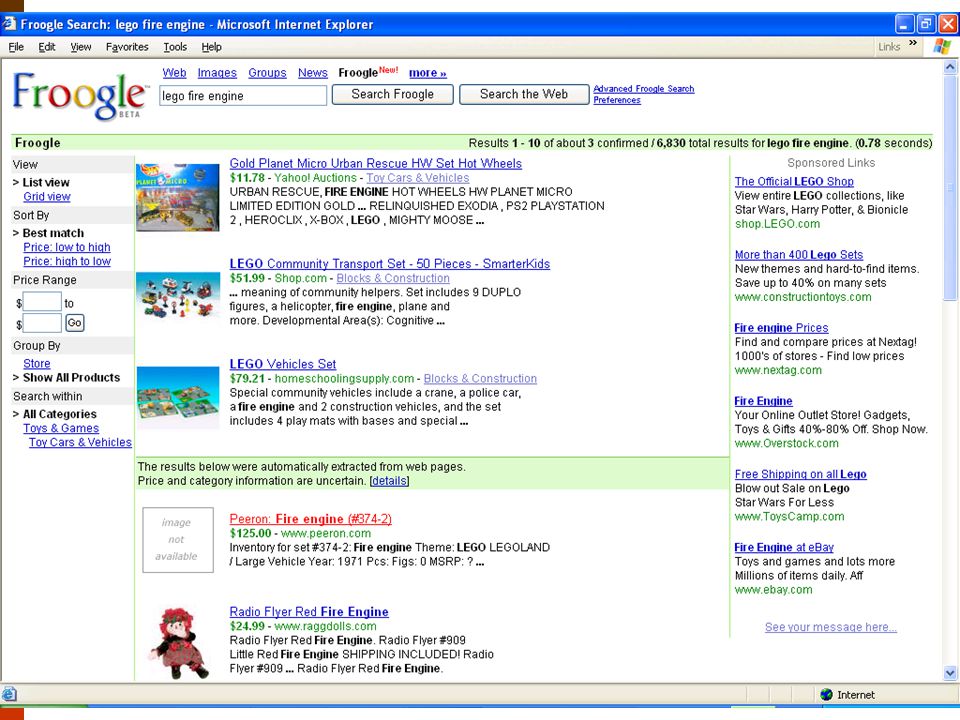
Product information/ Comparison shopping, etc. Need to learn to extract info from online vendors Can exploit uniformity of layout, and (partial) knowledge of domain by querying with known products Early e.g., Jango Shopbot (Etzioni and Weld) Gives convenient aggregation of online content Bug: originally not popular with vendors Make personal agents rather than web services? This seems to have changed (e.g., Froogle)
 knowledge of domain by querying with known products Early e.g., Jango Shopbot (Etzioni and Weld) Gives convenient aggregation of online content Bug: originally not popular with vendors Make personal agents rather than web services. This seems to have changed (e.g., Froogle).")
14
Commercial information… Need this price Title A book, Not a toy

15
Information Extraction Information extraction systems Find and understand the limited relevant parts of texts Clear, factual information (who did what to whom when?) Produce a structured representation of the relevant information: relations (in the DB sense) Combine knowledge about language and a domain Automatically extract the desired information E.g. Gathering earnings, profits, board members, etc. from company reports Learn drug-gene product interactions from medical research literature “Smart Tags” (Microsoft) inside documents
 inside documents.")
16
Using information extraction to populate knowledge bases http://protege.stanford.edu/

17
The European Commission said on Thursday it disagreed with German advice. Only France and Britain backed Fischler 's proposal. “What we have to be extremely careful of is how other countries are going to take Germany 's lead”, Welsh National Farmers ' Union ( NFU ) chairman John Lloyd Jones said on BBC radio. The European Commission said on Thursday it disagreed with German advice. Only France and Britain backed Fischler 's proposal. “What we have to be extremely careful of is how other countries are going to take Germany 's lead”, Welsh National Farmers ' Union ( NFU ) chairman John Lloyd Jones said on BBC radio. Named Entity Extraction The task: find and classify names in text, for example: The purpose: … a lot of information is really associations between named entities. … for question answering, answers are usually named entities. … the same techniques apply to other slot-filling classifications. The European Commission [ORG] said on Thursday it disagreed with German [MISC] advice. Only France [LOC] and Britain [LOC] backed Fischler [PER] 's proposal. “What we have to be extremely careful of is how other countries are going to take Germany 's lead”, Welsh National Farmers ' Union [ORG] ( NFU [ORG] ) chairman John Lloyd Jones [PER] said on BBC [ORG] radio.
 chairman John Lloyd Jones said on BBC radio. The European Commission said on Thursday it disagreed with German advice. Only France and Britain backed Fischler s proposal. What we have to be extremely careful of is how other countries are going to take Germany s lead , Welsh National Farmers Union ( NFU ) chairman John Lloyd Jones said on BBC radio. Named Entity Extraction The task: find and classify names in text, for example: The purpose: … a lot of information is really associations between named entities. … for question answering, answers are usually named entities. … the same techniques apply to other slot-filling classifications. The European Commission [ORG] said on Thursday it disagreed with German [MISC] advice. Only France [LOC] and Britain [LOC] backed Fischler [PER] s proposal. What we have to be extremely careful of is how other countries are going to take Germany s lead , Welsh National Farmers Union [ORG] ( NFU [ORG] ) chairman John Lloyd Jones [PER] said on BBC [ORG] radio..")
18
CoNLL (2003) Named Entity Recognition task Task: Predict semantic label of each word in text Foreign NNP I-NP ORG Ministry NNP I-NP ORG spokesman NN I-NP O Shen NNP I-NP PER Guofang NNP I-NP PER told VBD I-VP O Reuters NNP I-NPORG : : } Standard evaluation is per entity, not per token
 Named Entity Recognition task Task: Predict semantic label of each word in text Foreign NNP I-NP ORG Ministry NNP I-NP ORG spokesman NN I-NP O Shen NNP I-NP PER Guofang NNP I-NP PER told VBD I-VP O Reuters NNP I-NPORG : : } Standard evaluation is per entity, not per token")
19
Precision/Recall/F1 for IE Recall and precision are straightforward for tasks like IR and text categorization, where there is only one grain size (documents) The measure behaves a bit funnily for IE/NER when there are boundary errors (which are common): First Bank of Chicago announced earnings … This counts as both a fp and a fn Selecting nothing would have been better Some other systems (e.g., MUC scorer) give partial credit (according to complex rules)
 The measure behaves a bit funnily for IE/NER when there are boundary errors (which are common): First Bank of Chicago announced earnings … This counts as both a fp and a fn Selecting nothing would have been better Some other systems (e.g., MUC scorer) give partial credit (according to complex rules)")
20
Template Types Slots in template typically filled by a substring from the document. Some slots may have a fixed set of pre-specified possible fillers that may not occur in the text itself. Terrorist act: threatened, attempted, accomplished. Job type: clerical, service, custodial, etc. Company type: SEC code Some slots may allow multiple fillers. Programming language Some domains may allow multiple extracted templates per document. Multiple apartment listings in one ad

21
Task: Wrapper Induction Learning wrappers is wrapper induction Sometimes, the relations are structural. Web pages generated by a database. Tables, lists, etc. Can’t computers automatically learn the patterns a human wrapper-writer would use? Wrapper induction is usually regular relations which can be expressed by the structure of the document: the item in bold in the 3 rd column of the table is the price Wrapper induction techniques can also learn: If there is a page about a research project X and there is a link near the word ‘people’ to a page that is about a person Y then Y is a member of the project X. [e.g, Tom Mitchell’s Web->KB project]

22
Web Extraction Many web pages are generated automatically from an underlying database. Therefore, the HTML structure of pages is fairly specific and regular (semi-structured). However, output is intended for human consumption, not machine interpretation. An IE system for such generated pages allows the web site to be viewed as a structured database. An extractor for a semi-structured web site is sometimes referred to as a wrapper. Process of extracting from such pages is sometimes referred to as screen scraping.
. However, output is intended for human consumption, not machine interpretation. An IE system for such generated pages allows the web site to be viewed as a structured database. An extractor for a semi-structured web site is sometimes referred to as a wrapper. Process of extracting from such pages is sometimes referred to as screen scraping..")
23
Web Extraction using DOM Trees Web extraction may be aided by first parsing web pages into DOM trees. Extraction patterns can then be specified as paths from the root of the DOM tree to the node containing the text to extract. May still need regex patterns to identify proper portion of the final CharacterData node.

24
Sample DOM Tree Extraction HTML BODY FONTB Age of Spiritual Machines Ray Kurzweil Element Character-Data HEADER by A Title: HTML BODY B CharacterData Author: HTML BODY FONT A CharacterData

25
Wrappers: Simple Extraction Patterns Specify an item to extract for a slot using a regular expression pattern. Price pattern: “\b\$\d+(\.\d{2})?\b” May require preceding (pre-filler) pattern to identify proper context. Amazon list price: Pre-filler pattern: “ List Price: ” Filler pattern: “\ $\d+(\.\d{2})?\b ” May require succeeding (post-filler) pattern to identify the end of the filler. Amazon list price: Pre-filler pattern: “ List Price: ” Filler pattern: “.+” Post-filler pattern: “ ”
 \b May require preceding (pre-filler) pattern to identify proper context. Amazon list price: Pre-filler pattern: List Price: Filler pattern: \ $\d+(\.\d{2}) \b May require succeeding (post-filler) pattern to identify the end of the filler. Amazon list price: Pre-filler pattern: List Price: Filler pattern: .+ Post-filler pattern: .")
26
Simple Template Extraction Extract slots in order, starting the search for the filler of the n+1 slot where the filler for the nth slot ended. Assumes slots always in a fixed order. Title Author List price … Make patterns specific enough to identify each filler always starting from the beginning of the document.

27
Pre-Specified Filler Extraction If a slot has a fixed set of pre-specified possible fillers, text categorization can be used to fill the slot. Job category Company type Treat each of the possible values of the slot as a category, and classify the entire document to determine the correct filler.

28
Wrapper induction Highly regular source documents Relatively simple extraction patterns Efficient learning algorithm Writing accurate patterns for each slot for each domain (e.g. each web site) requires laborious software engineering. Alternative is to use machine learning: Build a training set of documents paired with human-produced filled extraction templates. Learn extraction patterns for each slot using an appropriate machine learning algorithm.
 requires laborious software engineering. Alternative is to use machine learning: Build a training set of documents paired with human-produced filled extraction templates. Learn extraction patterns for each slot using an appropriate machine learning algorithm..")
29
Learning for IE Writing accurate patterns for each slot for each domain (e.g. each web site) requires laborious software engineering. Alternative is to use machine learning: Build a training set of documents paired with human-produced filled extraction templates. Learn extraction patterns for each slot using an appropriate machine learning algorithm.
 requires laborious software engineering. Alternative is to use machine learning: Build a training set of documents paired with human-produced filled extraction templates. Learn extraction patterns for each slot using an appropriate machine learning algorithm..")
30
Use,,, for extraction Some Country Codes Congo 242 Egypt 20 Belize 501 Spain 34 Wrapper induction: Delimiter-based extraction

31
l1, r1, …, lK, rKl1, r1, …, lK, rK Example: Find 4 strings ,,, l 1, r 1, l 2, r 2 labeled pages wrapper Some Country Codes Congo 242 Egypt 20 Belize 501 Spain 34 Learning LR wrappers

32
LR: Finding r 1 Some Country Codes Congo 242 Egypt 20 Belize 501 Spain 34 r 1 can be any prefix eg

33
LR: Finding l 1, l 2 and r 2 Some Country Codes Congo 242 Egypt 20 Belize 501 Spain 34 r 2 can be any prefix eg l 2 can be any suffix eg l 1 can be any suffix eg

34
Distracting text in head and tail Some Country Codes Some Country Codes Congo 242 Egypt 20 Belize 501 Spain 34 End A problem with LR wrappers

35
Ignore page’s head and tail Some Country Codes Some Country Codes Congo 242 Egypt 20 Belize 501 Spain 34 End head body tail } } } start of tail end of head Head-Left-Right-Tail wrappers One (of many) solutions: HLRT
 solutions: HLRT")
36
More sophisticated wrappers LR and HLRT wrappers are extremely simple Though applicable to many tabular patterns Recent wrapper induction research has explored more expressive wrapper classes [Muslea et al, Agents-98; Hsu et al, JIS-98; Kushmerick, AAAI-1999; Cohen, AAAI-1999; Minton et al, AAAI- 2000] Disjunctive delimiters Multiple attribute orderings Missing attributes Multiple-valued attributes Hierarchically nested data Wrapper verification and maintenance
![More sophisticated wrappers LR and HLRT wrappers are extremely simple Though applicable to many tabular patterns Recent wrapper induction research has explored more expressive wrapper classes [Muslea et al, Agents-98; Hsu et al, JIS-98; Kushmerick, AAAI-1999; Cohen, AAAI-1999; Minton et al, AAAI- 2000] Disjunctive delimiters Multiple attribute orderings Missing attributes Multiple-valued attributes Hierarchically nested data Wrapper verification and maintenance](http://images.slideplayer.com/19/5834313/slides/slide_36.jpg "More sophisticated wrappers LR and HLRT wrappers are extremely simple Though applicable to many tabular patterns Recent wrapper induction research has explored more expressive wrapper classes [Muslea et al, Agents-98; Hsu et al, JIS-98; Kushmerick, AAAI-1999; Cohen, AAAI-1999; Minton et al, AAAI- 2000] Disjunctive delimiters Multiple attribute orderings Missing attributes Multiple-valued attributes Hierarchically nested data Wrapper verification and maintenance")
37
Boosted wrapper induction Wrapper induction is only ideal for rigidly-structured machine-generated HTML… … or is it?! Can we use simple patterns to extract from natural language documents? … Name: Dr. Jeffrey D. Hermes … … Who: Professor Manfred Paul …... will be given by Dr. R. J. Pangborn … … Ms. Scott will be speaking … … Karen Shriver, Dept. of... … Maria Klawe, University of...

38
BWI: The basic idea Learn “wrapper-like” patterns for texts pattern = exact token sequence Learn many such “weak” patterns Combine with boosting to build “strong” ensemble pattern Boosting is a popular recent machine learning method where many weak learners are combined Demo: http://www.smi.ucd.ie/bwi Not all natural text is sufficiently regular for exact string matching to work well!!

39
Natural Language Processing-based Information Extraction If extracting from automatically generated web pages, simple regex patterns usually work. If extracting from more natural, unstructured, human-written text, some NLP may help. Part-of-speech (POS) tagging Mark each word as a noun, verb, preposition, etc. Syntactic parsing Identify phrases: NP, VP, PP Semantic word categories (e.g. from WordNet) KILL: kill, murder, assassinate, strangle, suffocate Extraction patterns can use POS or phrase tags. Crime victim: Prefiller: [POS: V, Hypernym: KILL] Filler: [Phrase: NP]
 tagging Mark each word as a noun, verb, preposition, etc. Syntactic parsing Identify phrases: NP, VP, PP Semantic word categories (e.g. from WordNet) KILL: kill, murder, assassinate, strangle, suffocate Extraction patterns can use POS or phrase tags. Crime victim: Prefiller: [POS: V, Hypernym: KILL] Filler: [Phrase: NP].")
40
Stalker: A wrapper induction system (Muslea et al. Agents-99) E1:513 Pico, Venice, Phone 1- 800 -555-1515 E2:90 Colfax, Palms, Phone (800) 508-1570 E3: 523 1 st St., LA, Phone 1- 800 -578-2293 E4: 403 La Tijera, Watts, Phone: (310) 798-0008 We want to extract area code. Start rules: R1: SkipTo(() R2: SkipTo(- ) End rules: R3: SkipTo()) R4: SkipTo( )
 E1:513 Pico, Venice, Phone E2:90 Colfax, Palms, Phone (800) E3: st St., LA, Phone E4: 403 La Tijera, Watts, Phone: (310) We want to extract area code. Start rules: R1: SkipTo(() R2: SkipTo(- ) End rules: R3: SkipTo()) R4: SkipTo( ).")
41
Learning extraction rules Stalker uses sequential covering to learn extraction rules for each target item. In each iteration, it learns a perfect rule that covers as many positive items as possible without covering any negative items. Once a positive item is covered by a rule, the whole example is removed. The algorithm ends when all the positive items are covered. The result is an ordered list of all learned rules.

42
Rule induction through an example Training examples: E1:513 Pico, Venice, Phone 1- 800 -555-1515 E2:90 Colfax, Palms, Phone (800) 508-1570 E3: 523 1 st St., LA, Phone 1- 800 -578-2293 E4: 403 La Tijera, Watts, Phone: (310) 798-0008 We learn start rule for area code. Assume the algorithm starts with E2. It creates three initial candidate rules with first prefix symbol and two wildcards: R1: SkipTo(() R2: SkipTo(Punctuation) R3: SkipTo(Anything) R1 is perfect. It covers two positive examples but no negative example.
 R2: SkipTo(Punctuation) R3: SkipTo(Anything) R1 is perfect. It covers two positive examples but no negative example..")
43
Rule induction (cont …) E1:513 Pico, Venice, Phone 1- 800 -555-1515 E2:90 Colfax, Palms, Phone (800) 508-1570 E3: 523 1 st St., LA, Phone 1- 800 -578-2293 E4: 403 La Tijera, Watts, Phone: (310) 798-0008 R1 covers E2 and E4, which are removed. E1 and E3 need additional rules. Three candidates are created: R4: SkiptTo( ) R5: SkipTo(HtmlTag) R6: SkipTo(Anything) None is good. Refinement is needed. Stalker chooses R4 to refine, i.e., to add additional symbols, to specialize it. It will find R7: SkipTo(- ), which is perfect.
 R5: SkipTo(HtmlTag) R6: SkipTo(Anything) None is good. Refinement is needed. Stalker chooses R4 to refine, i.e., to add additional symbols, to specialize it. It will find R7: SkipTo(- ), which is perfect..")
44
Limitations of Supervised Learning Manual Labeling is labor intensive and time consuming, especially if one wants to extract data from a huge number of sites. Wrapper maintenance is very costly: If Web sites change frequently It is necessary to detect when a wrapper stops to work properly. Any change may make existing extraction rules invalid. Re-learning is needed, and most likely manual re- labeling as well.

45
Road map Structured data extraction Wrapper induction Automatic extraction Information integration Summary

46
The RoadRunner System (Crescenzi et al. VLDB-01) Given a set of positive examples (multiple sample pages). Each contains one or more data records. From these pages, generate a wrapper as a union-free regular expression (i.e., no disjunction). The approach To start, a sample page is taken as the wrapper. The wrapper is then refined by solving mismatches between the wrapper and each sample page, which generalizes the wrapper.
 Given a set of positive examples (multiple sample pages). Each contains one or more data records. From these pages, generate a wrapper as a union-free regular expression (i.e., no disjunction). The approach To start, a sample page is taken as the wrapper. The wrapper is then refined by solving mismatches between the wrapper and each sample page, which generalizes the wrapper..")
48
Compare with wrapper induction No manual labeling, but need a set of positive pages of the same template which is not necessary for a page with multiple data records not wrapper for data records, but pages. A Web page can have many pieces of irrelevant information. Issues of automatic extraction Hard to handle disjunctions Hard to generate attribute names for the extracted data. extracted data from multiple sites need integration, manual or automatic.

49
The DEPTA system (Zhai & Liu WWW- 05) Data region1 Data region2 A data record
 Data region1 Data region2 A data record")
50
Align and extract data items (e.g., region1) image1 EN7410 17- inch LCD Monitor Black/Dark charcoal $299.99Add to Cart (Delivery / Pick-Up ) Penny Shopping Compare image2 17-inch LCD Monitor $249.99Add to Cart (Delivery / Pick-Up ) Penny Shopping Compare image3 AL1714 17- inch LCD Monitor, Black $269.99Add to Cart (Delivery / Pick-Up ) Penny Shopping Compare image4 SyncMaster 712n 17-inch LCD Monitor, Black Was: $369.99 $299.99Save $70 After: $70 mail-in- rebate(s) Add to Cart (Delivery / Pick-Up ) Penny Shopping Compare
 image1 EN inch LCD Monitor Black/Dark charcoal $299.99Add to Cart (Delivery / Pick-Up ) Penny Shopping Compare image2 17-inch LCD Monitor $249.99Add to Cart (Delivery / Pick-Up ) Penny Shopping Compare image3 AL inch LCD Monitor, Black $269.99Add to Cart (Delivery / Pick-Up ) Penny Shopping Compare image4 SyncMaster 712n 17-inch LCD Monitor, Black Was: $ $299.99Save $70 After: $70 mail-in- rebate(s) Add to Cart (Delivery / Pick-Up ) Penny Shopping Compare")
51
1. Mining Data Records (Liu et al, KDD-03; Zhai and Liu, WWW-05) Given a single page with multiple data records (a list page), it extracts data records. The algorithm is based on two observations about data records in a Web page a string matching algorithm (tree matching ok too) Considered both contiguous non-contiguous data records
 Given a single page with multiple data records (a list page), it extracts data records. The algorithm is based on two observations about data records in a Web page a string matching algorithm (tree matching ok too) Considered both contiguous non-contiguous data records.")
52
The Approach Given a page, three steps: Building the HTML Tag Tree Erroneous tags, unbalanced tags, etc Some problems are hard to fix Mining Data Regions Spring matching or tree matching Identifying Data Records Rendering (or visual) information is very useful in the whole process
 information is very useful in the whole process")
53
Building tree based on visual cues 1 2 3 … 4 … 5 6 7 … 8 … 9 10 left righttopbottom 100300200400 100300200300 100200200300 200300200300 100300300400 100200300400 200300300400 tr td td td The tag tree table

54
Mining Data Regions 1 3 10 2 78 9 Region 2 5 6 4 11 12 1415 1617 1918 13 20 Region 1 Region 3

55
Identify Data Records A generalized node may not be a data record. Extra mechanisms are needed to identify true atomic objects (see the papers). Some highlights: Contiguous non-contiguous data records. Name 1 Description of object 1 Name 2 Description of object 2 Name 3 Description of object 3 Name 4 Description of object 4 Name 1Name 2 Description of object 1 Description of object 2 Name 3Name 4 Description of object 3 Description of object 4
. Some highlights: Contiguous non-contiguous data records. Name 1 Description of object 1 Name 2 Description of object 2 Name 3 Description of object 3 Name 4 Description of object 4 Name 1Name 2 Description of object 1 Description of object 2 Name 3Name 4 Description of object 3 Description of object 4.")
56
2. Extract Data from Data Records Once a list of data records are identified, we can align and extract data items in them. Approaches (align multiple data records): Multiple string alignment Many ambiguities due to pervasive use of table related tags. Multiple tree alignment (partial tree alignment) Together with visual information is effective Most multiple alignment methods work like hierarchical clustering, Not effective, and very expensive
: Multiple string alignment Many ambiguities due to pervasive use of table related tags. Multiple tree alignment (partial tree alignment) Together with visual information is effective Most multiple alignment methods work like hierarchical clustering, Not effective, and very expensive.")
57
Tree Matching (tree edit distance) Intuitively, in the mapping each node can appear no more than once in a mapping, the order between sibling nodes are preserved, and the hierarchical relation between nodes are also preserved. c b a p c h e p da d AB

58
The Partial Tree Alignment approach Choose a seed tree: A seed tree, denoted by Ts, is picked with the maximum number of data items. Tree matching: For each unmatched tree Ti (i ≠ s), match Ts and Ti. Each pair of matched nodes are linked (aligned). For each unmatched node nj in Ti do expand Ts by inserting nj into Ts if a position for insertion can be uniquely determined in Ts. The expanded seed tree Ts is then used in subsequent matching.
, match Ts and Ti. Each pair of matched nodes are linked (aligned). For each unmatched node nj in Ti do expand Ts by inserting nj into Ts if a position for insertion can be uniquely determined in Ts. The expanded seed tree Ts is then used in subsequent matching..")
59
p p a b e d c e b d c e p New part of T s e a b x p p TsTs TiTi a e b a TsTs TiTi Insertion is possible Insertion is not possible Illustration of partial tree alignment

60
d x … b p c k g n p b dx … b p k c x … b p dh c k g n p b n x … b p cdhk No node inserted T2T2 T3T3 T2T2 g TsTs New T s d hk c p b c, h, and k inserted T s = T 1 T 2 is matched again A complete example

61
Output Data Table … xbncdhkg T1T1 … 111 T2T2 11111 T3T3 11111 DEPTA does not work with nested data records. NET (Liu & Zhai, WISE-05)extracts data from both flat and nested data records.
extracts data from both flat and nested data records..")
62
Some other systems and techniques IEPAD (Chang & Lui WWW-01), DeLa (Wang & Lochovsky WWW- 03) These systems treat a page as a long string, and find repeated substring patterns. They often produce multiple patterns (rules). Hard to decide which is correct. EXALG(Arasu & Garcia-Molina SIGMOD-03), (Lerman et al, SIGMOD-04). Require multiple pages to find patterns. Which is not necessary for pages with multiple records. (Zhao et al, WWW-04) It extracts data records in one area of a page.
. Hard to decide which is correct. EXALG(Arasu & Garcia-Molina SIGMOD-03), (Lerman et al, SIGMOD-04). Require multiple pages to find patterns. Which is not necessary for pages with multiple records. (Zhao et al, WWW-04) It extracts data records in one area of a page..")
63
Limitations and issues Not for a page with only a single data record Does not generate attribute names for the extracted data (yet!) extracted data from multiple sites need integration. It is possible in each specific application domain, e.g., products sold online. need “product name”, “image”, and “price”. identify only these three fields may not be too hard. Job postings, publications, etc …

64
Road map Structured data extraction Wrapper induction Automatic extraction Information integration Summary

65
Web query interface integration Many integration tasks, Integrating Web query interfaces (search forms) Integrating extracted data Integrating textual information Integrating ontologies (taxonomy) … We only introduce integration of query interfaces. Many web sites provide forms to query deep web Applications: meta-search and meta-query

66
Global Query Interface united.comairtravel.comdelta.comhotwire.com

67
Synonym Discovery ( He and Chang, KDD-04 ) Discover synonym attributes Author – Writer, Subject – Category Holistic Model Discovery authornamesubject category writer S2: writer title category format S3: name title keyword binding S1: author title subject ISBN Pairwise Attribute Correspondence S2: writer title category format S3: name title keyword binding S1: author title subject ISBN S1.author S3.name S1.subject S2.category V.S.
 Discover synonym attributes Author – Writer, Subject – Category Holistic Model Discovery authornamesubject category writer S2: writer title category format S3: name title keyword binding S1: author title subject ISBN Pairwise Attribute Correspondence S2: writer title category format S3: name title keyword binding S1: author title subject ISBN S1.author S3.name S1.subject S2.category V.S.")
68
Schema matching as correlation mining Across many sources: Synonym attributes are negatively correlated synonym attributes are semantically alternatives. thus, rarely co-occur in query interfaces Grouping attributes with positive correlation grouping attributes semantically complement thus, often co-occur in query interfaces

69
1. Positive correlation mining as potential groups 2. Negative correlation mining as potential matchings Mining positive correlations Last Name, First Name Mining negative correlations Author = {Last Name, First Name} 3. Matching selection as model construction Author (any) = {Last Name, First Name} Subject = Category Format = Binding
 = {Last Name, First Name} Subject = Category Format = Binding.")
70
A clustering approach to schema matching (Wu et al. SIGMOD-04) 1:1 mapping by clustering Bridging effect “a2” and “c2” might not look similar themselves but they might both be similar to “b3” 1:m mappings Aggregate and is-a types User interaction helps in: learning of matching thresholds resolution of uncertain mappings X
 1:1 mapping by clustering Bridging effect a2 and c2 might not look similar themselves but they might both be similar to b3 1:m mappings Aggregate and is-a types User interaction helps in: learning of matching thresholds resolution of uncertain mappings X.")
71
Find 1:1 Mappings via Clustering Interfaces: After one merge: …, final clusters: {{a1,b1,c1}, {b2,c2},{a2},{b3}} Initial similarity matrix: Similarity functions linguistic similarity domain similarity

72
Find 1:m Complex Mappings Aggregate type – contents of fields on the many side are part of the content of field on the one side Commonalities – (1) field proximity, (2) parent label similarity, and (3) value characteristics
 field proximity, (2) parent label similarity, and (3) value characteristics")
73
Complex Mappings (Cont’d) Is-a type – contents of fields on the many side are sum/union of the content of field on the one side Commonalities – (1) field proximity, (2) parent label similarity, and (3) value characteristics
 Is-a type – contents of fields on the many side are sum/union of the content of field on the one side Commonalities – (1) field proximity, (2) parent label similarity, and (3) value characteristics")
74
Instance-based matching via query probing (Wang et al. VLDB-04) Both query interfaces and returned results (called instances) are considered in matching. It assumes a global schema (GS) is given and a set of instances are also given. Uses each instance value (V) in GS to probe the underlying database to obtain the count of V appeared in the returned results. These counts are used to help matching.
 Both query interfaces and returned results (called instances) are considered in matching. It assumes a global schema (GS) is given and a set of instances are also given. Uses each instance value (V) in GS to probe the underlying database to obtain the count of V appeared in the returned results. These counts are used to help matching..")
75
Query interface and result page Search Interface Result Page … Format ISBN Publish Date Publisher Author Title Data Attributes

76
Road map Structured data extraction Wrapper Induction Automatic extraction Information integration Summary

77
Summary Give an overview of two topics Structured data extraction Information integration Some technologies are ready for industrial exploitation, e.g., data extraction. Simple integration is do-able, complex integration still needs further research.

Similar presentations

 Module Website: Practical this week:>")


 Identify specific pieces of information (data) in a unstructured or semi-structured textual document.>")




 January 2009>")






 Tom Mitchell (CMU & WhizBang! Labs) Ellen Riloff (University.>")



